记录第一次接口上线过程
新入职一家公司后,前三天一直在学习公司内部各种制度文化以及考试。
一直到第三天组长突然叫我过去,给了一个需求的思维导图,按照这个需求写这样一个接口,
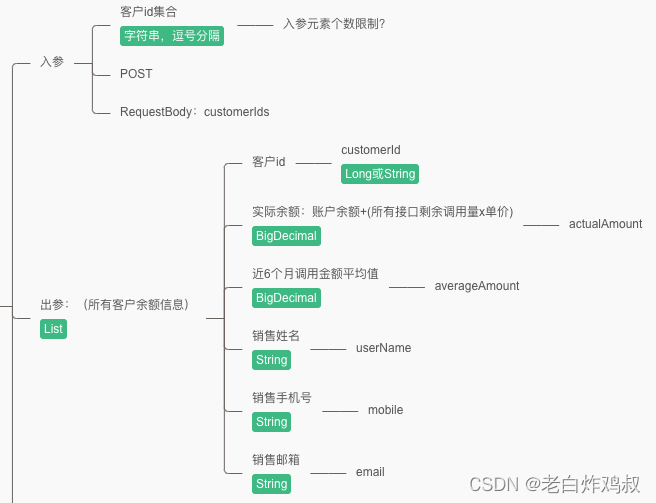
其实还不错,不用自己去分析需求,按照这上面直接开写。还有基本sql语句也给我了,存粹是让我练手的。
接下来就是各种环境配置,账号申请。
版本控制工具使用的是Gitlab
第一次代码提交
毫无悬念被打回来啦,
原因
没有使用缓存,公司项目还是一个多年的大项目,有着自己的缓存技术和体系,所有查询一般都是先走缓存,因为我的那个入参ids是多个客户id按逗号拼接而来的。所以可能在全量测试的时候根本扛不住。
解决
请教同事和组长,公司项目的缓存规范以及如何使用。
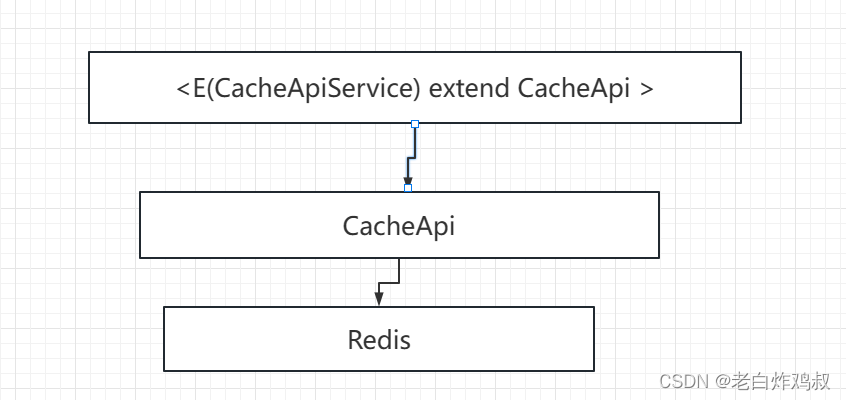
接下来就是查找自己所有需要的API接口啦结合同事的使用方法,自己去调用实现自己业务。
第二次代码提交
代码提交通过,但是测试不通过
原因
全量测试时,无反应,部分ID报空指针异常。
解决
对所有的可能出现的空指针对象进行校验,
针对无反应现象做了如下优化
原来的sql
SELECT id, SUM( price* call_count) / 6
FROM table_name
WHERE statistics_date >= DATE_FORMAT( DATE_SUB( NOW(
),
INTERVAL 180 DAY),
'%Y-%m-%d %H:%i:%s'
)
AND id in( 156)
GROUP BY id
原来的sql
优化后的sql
SELECTid, SUM( price* call_count) / 6 AS averageAmountFROMtable_nameWHEREid > (SELECTMIN( id)FROMtable_nameWHEREstatistics_date = DATE_FORMAT( DATE_SUB( NOW(),INTERVAL 180 DAY),'%Y-%m-%d'))AND id in( 156) GROUP BY id
这段sql一开始确实不理解什么意思,因为是组长优化后直接发给我的,先叫我看看为什么这么做。仔细一看我以为组长写错啦。因为我们要计算的是6个月的平均值 你们statistics_date 后应该是大于等于,不应该是等于。
于是怕到时候数据出错我又去问了问组长,终于明白
SELECTMIN( id)FROMtable_nameWHEREstatistics_date = DATE_FORMAT( DATE_SUB( NOW(),INTERVAL 180 DAY),'%Y-%m-%d')
这段sql是查询6个月前的那一天数据,找到这天当中id最小的,然后在外面的查询中查询id大于这个最小id的就是近6个月的数据,因为ID是只增的,且id作为主键索引查询效率肯定大于我之前写的sql。
继续优化sql
in函数的性能问题
当传递过来的参数长度较小时,使用in语句查询效率还是比较高的,当测试做全量测试时(参数长度在1000-2000之间)
那么就要考虑使用exists
为什么?
- exists与in的区别一:exists先执行外层的sql,in是先执行内层的子查询。
- exists与in的区别二:exists使用的是内层的索引,in使用的是外层的索引。
所以当in里面的数据量不大时,使用in效率大于exists。当子查询数据量大于外层查询时,使用exists效率大于in
第三次提交
性能测试通过,但是数据对不上
原因
通过接口查询出来的数据和给测试的sql查出来数据不一致。
解决
这种问题有些棘手。为什么呢?因为计算数据走缓存,猜想:可能是缓存里面数据不一致问题。
当然前提是保证所有代码计算逻辑没问题。
查缓存,将缓存里面的数据和数据库里面查出来数据做对比。经过一番对比排查。
果然是数据不一致问题。
虽然数据不一致问题在缓存架构里面是比较常见的问题。但是公司那么久的项目肯定不会出现这么低级的错误。
请教了组长,果然揪出端倪。
原来是sql语句里面少啦一些状态为不可用的条件。
最后做数据对比完全一致。
关于组长给我代码做的一些优化
我的思路
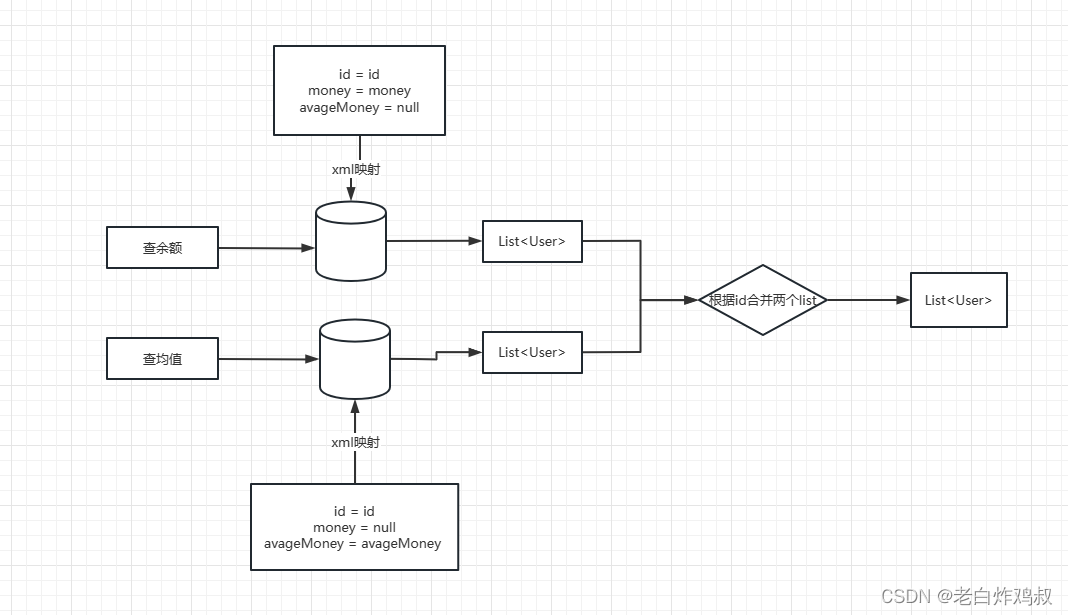
在此之前因为保证数据准确性还要先遍历一次参数ids,然后取出参数id对应的值
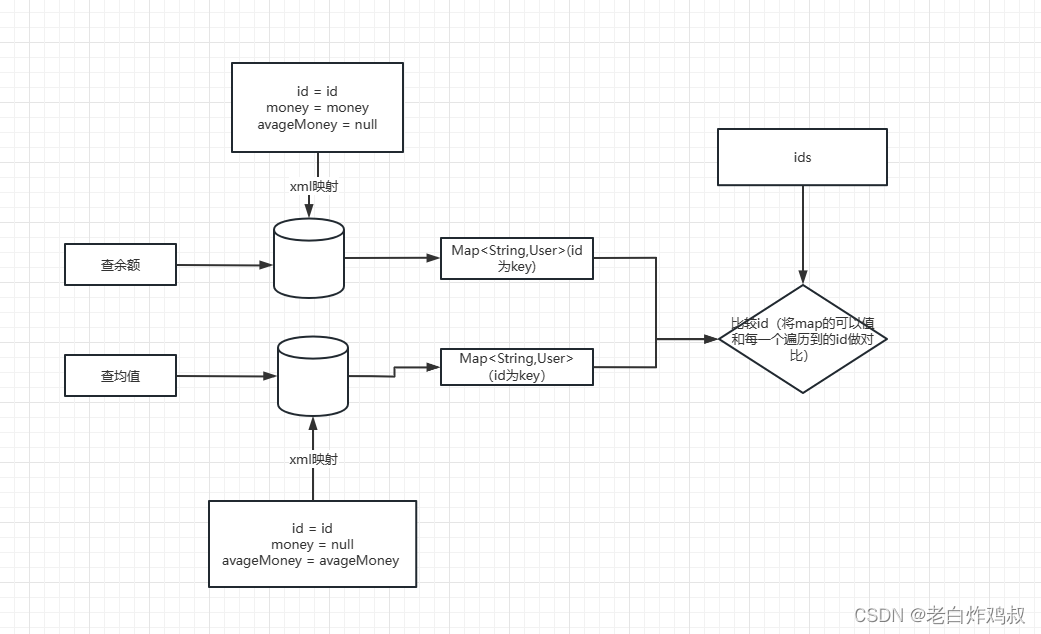
这样减少两次循环,在代码层面也做了一些优化。