ES-组合与聚合
ES组合查询
1 must
满足两个match才会被命中
GET /mergeindex/_search
{"query": {"bool": {"must": [{"match": {"name": "liyong"}},{"match_phrase": {"desc": "liyong"}}]}}
}
2 must 可以换成filter,这样可以不用计算score 这样性能更好。
GET /mergeindex/_search
{"query": {"bool": {"filter": [{"match": {"name": "liyong"}},{"match_phrase": {"desc": "liyong"}}]}}
}
3 should 类似于SQL中的 or
GET /mergeindex/_search
{"query": {"bool": {"should": [{"match": {"name": "liyong"}},{"match_phrase": {"desc": "liyong"}}]}}
}
bool 支持嵌套但是不推荐。
4 must 与 filter 组合使用
这个时候会限制性filter然后再执行must,也就是预处理,先过滤掉一部分数据。
GET /mergeindex/_search
{"query": {"bool": {"must": [{"match": {"name": "liyong"}},{"match_phrase": {"desc": "liyong"}}],"filter": [{"range": {"salary": {"gte": 0,"lte": 190000}}}]}}
}
5 filter 和 should 一起使用
有可能会有一个问题,就是should不工作,需要加上一个兜底条件minimum_should_match : 1 最好是加上。
GET /mergeindex/_search
{"query": {"bool": {#should 至少要匹配一个"minimum_should_match" : 1, "should": [{"match": {"name": "liyong"}},{"match_phrase": {"desc": "liyong"}}]}}
}
ES聚合
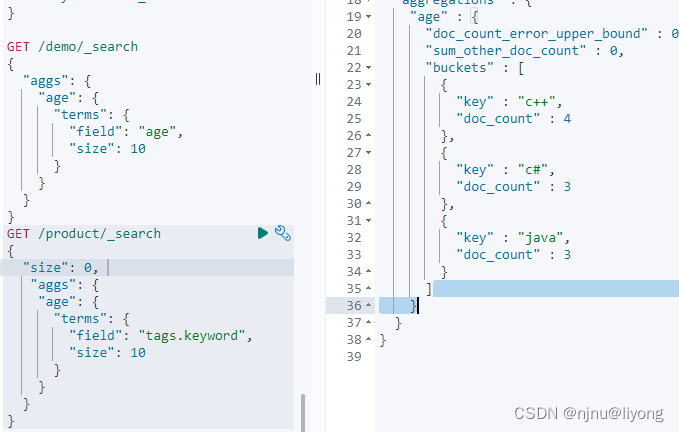
GET /demo/_search
{"size" : 0, #不返回hints 减少数据量"aggs": { #固定语法"age": { #自定义名字"terms": {"field": "age", #根据年龄进行聚合"size": 10}}}
}

需要注意点是如果是文本则不能直接聚合,需要使用keyworkd
GET /product/_search
{"size": 0, "aggs": {"age": {"terms": {"field": "tags.keyword", # 这里不能填 tags 因为默认会被拆分,然后每个元素都是text类型"size": 10 #限制桶的数量 如果填1 就只返回一个聚合结果}}}
}
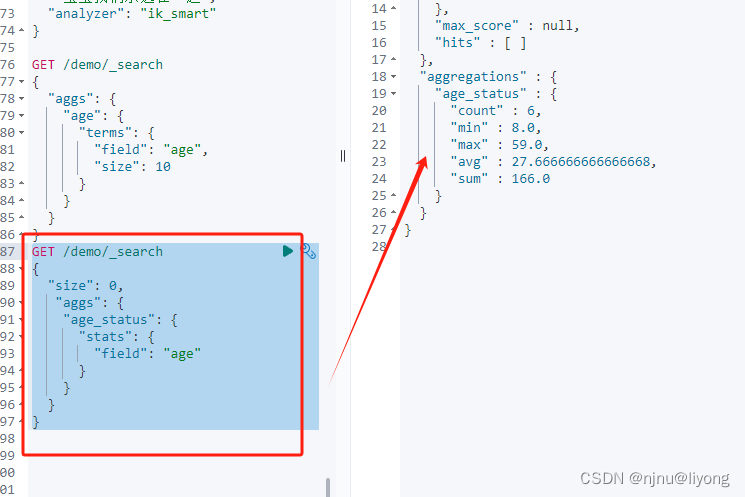
status 可以一下统计常见的数值
GET /demo/_search
{"size": 0, "aggs": {"age_status": {"stats": {"field": "age"}}}
}
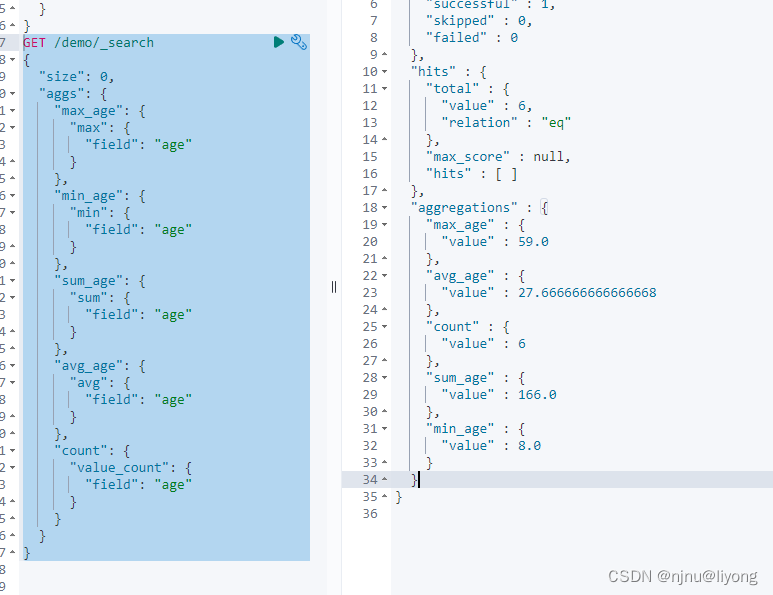
也可以分开来写
GET /demo/_search
{"size": 0,"aggs": {"max_age": {"max": {"field": "age"}},"min_age": {"min": {"field": "age"}},"sum_age": {"sum": {"field": "age"}},"avg_age": {"avg": {"field": "age"}},"count": {"value_count": {"field": "age"}}}
}
去重
GET /demo/_search
{"size": 0,"aggs": {"distinct_name" : {"cardinality": {"field": "age" #去除重复的年龄有几个种类}}}
}
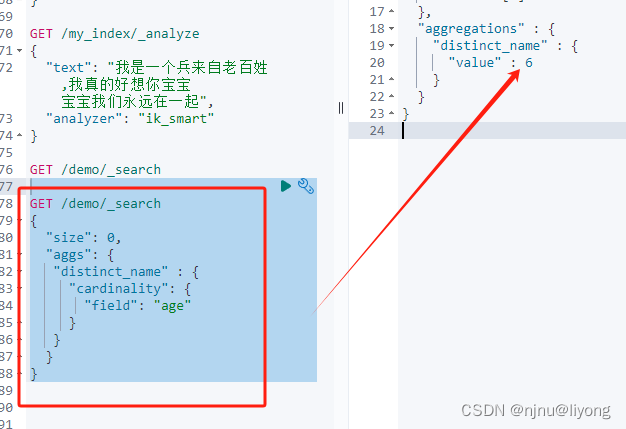
聚合嵌套
GET demo/_search
{"size": 0,"aggs": {"age_bucket": {"terms": {"field": "name.keyword"},"aggs": { #这个案例演示aggs是可以嵌套的"age_bulk": {"avg": {"field": "age"}}}},"min_bucket": {"min_bucket": {"buckets_path": "age_bucket>age_bulk" #固定语法 直接筛选出了 年龄最小的}}}
}
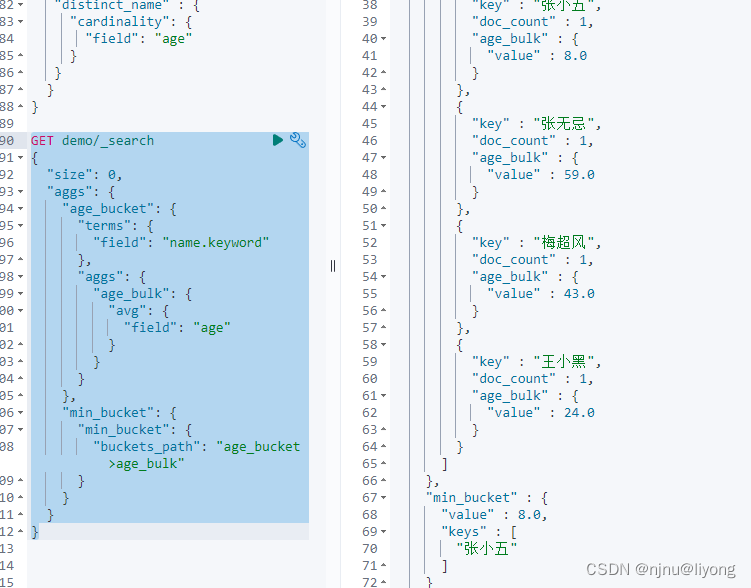
先筛选再聚合
GET product/_search
{"query": {"range": {"price": {"gte": 1000}}}, # 先筛选出数据 在进行聚合"aggs": {"type_bucket": {"terms": {"field": "type.keyword" #根据type进行分组}}}
}
排序
GET /product/_search?size=0
{"aggs": {"tags_aggs": {"terms": {"field": "tags.keyword","size": 10,"order": {"_key": "asc" #根据_count来排序 通过数量来排序}}}}
}嵌套排序
#不返回hits中的数据
GET /product/_search?size=0
{"aggs": {"first_sort": {"terms": {"field": "tags.keyword","order": {"_count": "desc"}},"aggs": {"second_sort": {"terms": {"field": "type.keyword","order": {"_count": "desc"}}}}}}
}自定义排序
GET /product/_search?size=0 #指定不返回hints
{"aggs": {"type_price": {"terms": {"field": "type.keyword","order": {#过滤的名字 第二个过滤器有多个止值可以用.来指定#指定聚合那个字段排在前面"agg_stats>stats.min": "asc" }},"aggs": {"agg_stats": {"filter": {"terms": {"tags.keyword": ["88vip","tmall"]}},"aggs": {"stats": {"stats": {"field": "price"}}}}}}}
}
#先根据type分类然后 根据tags 筛选 再 根据最小值进行排序
直方图
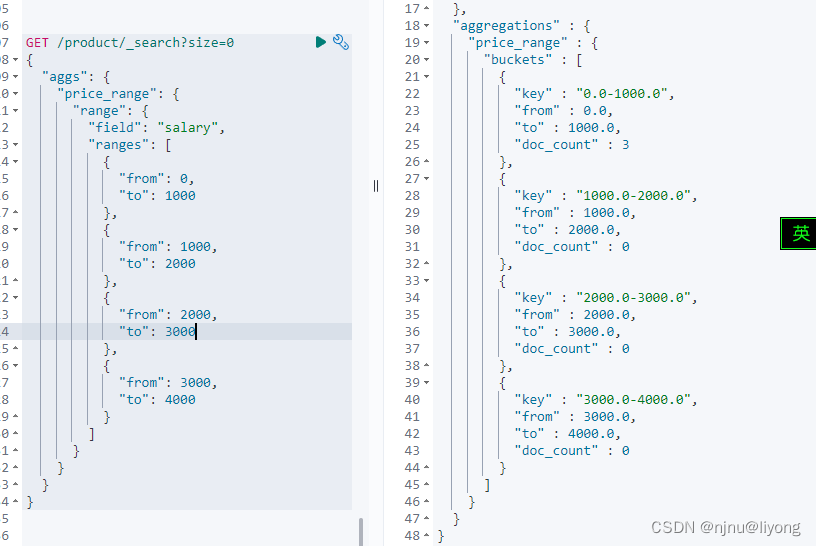
首先来看这样一个例子
GET /product/_search?size=0
{"aggs": {"price_range": {"range": {"field": "salary","ranges": [{"from": 0,"to": 1000},{"from": 1000,"to": 2000},{"from": 2000,"to": 3000},{"from": 3000,"to": 4000}]}}}
}
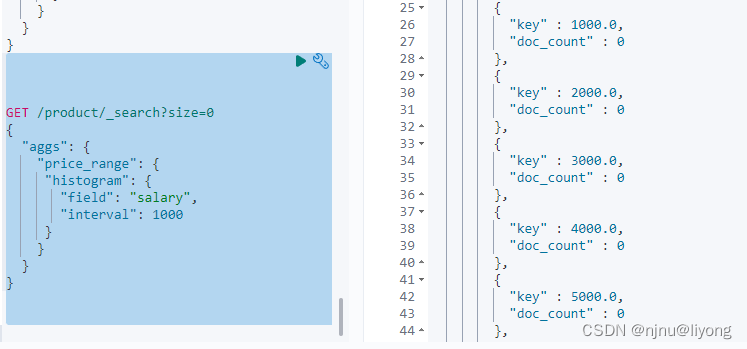
这里相当于做一个统计,但是需要一个一个定义,类似于坐标轴x,可以有更简单的写法
GET /product/_search?size=0
{"aggs": {"price_range": {"histogram": {"field": "salary","interval": 1000 #坐标间距}}}
}GET /product/_search?size=0
{"aggs": {"price_range": {"histogram": {"field": "salary","interval": 1000,"missing": 0, #如果为空值就为0"min_doc_count": 1 #小于1的不展示 依据doc_count属性}}}
}
时间直方图
GET /product/_search
{"aggs": {"price_range": {"date_histogram": {"field": "date",#看月度数据"calendar_interval": "month", #year day#看2023-01 - 06的数据"extended_bounds": {"min": "2023-01","max": "2023-06"}}}}
}
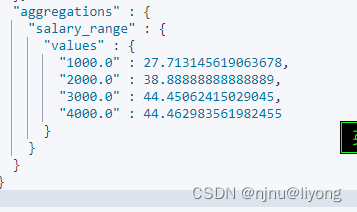
水位
GET /product/_search
{"size" : 0,"aggs": {"salary_range": {"percentile_ranks": {"field": "salary","values": [1000,2000,3000,4000]}}}
}它的意思是,有27%的数据薪水不超过1000, 有38%的薪水不超过2000,以此类推吧