urllib之urlopen和urlretrieve的headers传入以及parse、urlparse、urlsplit的使用
urllib库是什么?
urllib库python的一个最基本的网络请求库,不需要安装任何依赖库就可以导入使用。它可以模拟浏览器想目标服务器发起请求,并可以保存服务器返回的数据。
urllib库的使用:
1、request.urlopen
(1)只能传入url的方式
from http.client import HTTPResponse
from urllib import request
from urllib.request import Requesturl = "https://www.baidu.com"headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}response = request.urlopen(url) # type: HTTPResponseprint(response.read().decode("utf-8"))(2) 传入Request对象和headers的方式
from http.client import HTTPResponse
from urllib import request
from urllib.request import Requesturl = "https://www.baidu.com"headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}req = Request(url, headers=headers)response = request.urlopen(req) # type: HTTPResponseprint(response.read().decode("utf-8"))
2、request.urlretrieve
(1)简单使用,不能传入headers,只能传入url和保存的路径的方式
from http.client import HTTPResponse
from urllib import request
from urllib.request import Requesturl = "https://www.baidu.com"headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}# req = Request(url, headers=headers)
#
# response = request.urlopen(req) # type: HTTPResponse
#
# print(response.read().decode("utf-8"))request.urlretrieve(url, "baidu.html")
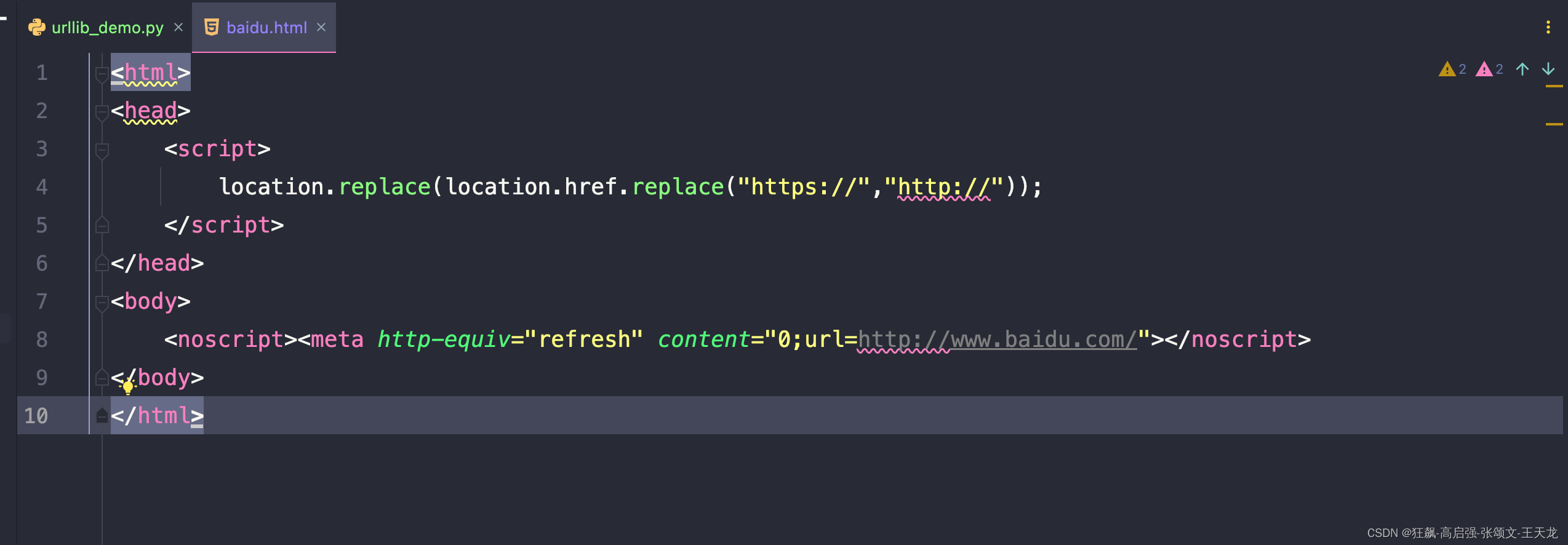
(2)复杂使用,可以传入headers,传入url和保存的路径的方式
from urllib import requesturl = "https://www.baidu.com"
opener = request.build_opener()
opener.addheaders = ([("User-Agent","Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36")])request.install_opener(opener)request.urlretrieve(url, "baidu.html")

额外的信息:
1、response的content-length
from http.client import HTTPResponse
from urllib import request
from urllib.request import Requesturl = "https://www.kuwo.cn/comment?type=get_comment&f=web&page=1&rows=5&digest=2&sid=93&uid=0&prod=newWeb&httpsStatus=1"headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}req = Request(url, headers=headers)
response = request.urlopen(req) # type: HTTPResponsemeta = response.info()
# content-type
print(meta.get_content_type())
# content_charset
print(meta.get_content_charset())
# Content-Length
print(meta.get_all("Content-Length"))
print(response.getheader("Content-Length"))
urllib之parse模块的使用:
编码和解码
from urllib import parsedata = {"name": "王五","age": 31,"sex": "男","address": "北京市昌平区"
}# 参数编码
qs = parse.urlencode(data)
print(qs)# 解码
my_data = parse.parse_qs(qs)
print(my_data)
quote
起因:
在请求的url中,如果有汉字、空格或者特殊字符的时候,浏览器默认会将该字符进行urlencode()的处理,这样就可以正常的访问了!!!
代码实现:
错误代码:
from http.client import HTTPResponse
from urllib import parse, request
from urllib.request import Requesturl = "https://www.baidu.com/s?wd=%E6%9D%8E%E4%B8%80%E6%A1%90"headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}
req = Request(url, headers=headers)
response = request.urlopen(req) # type: HTTPResponse
# print(response.read().decode("utf-8"))url = "https://www.baidu.com/s?wd=李一桐"
req = Request(url, headers=headers)
response = request.urlopen(req) # type: HTTPResponse
print(response.read().decode("utf-8"))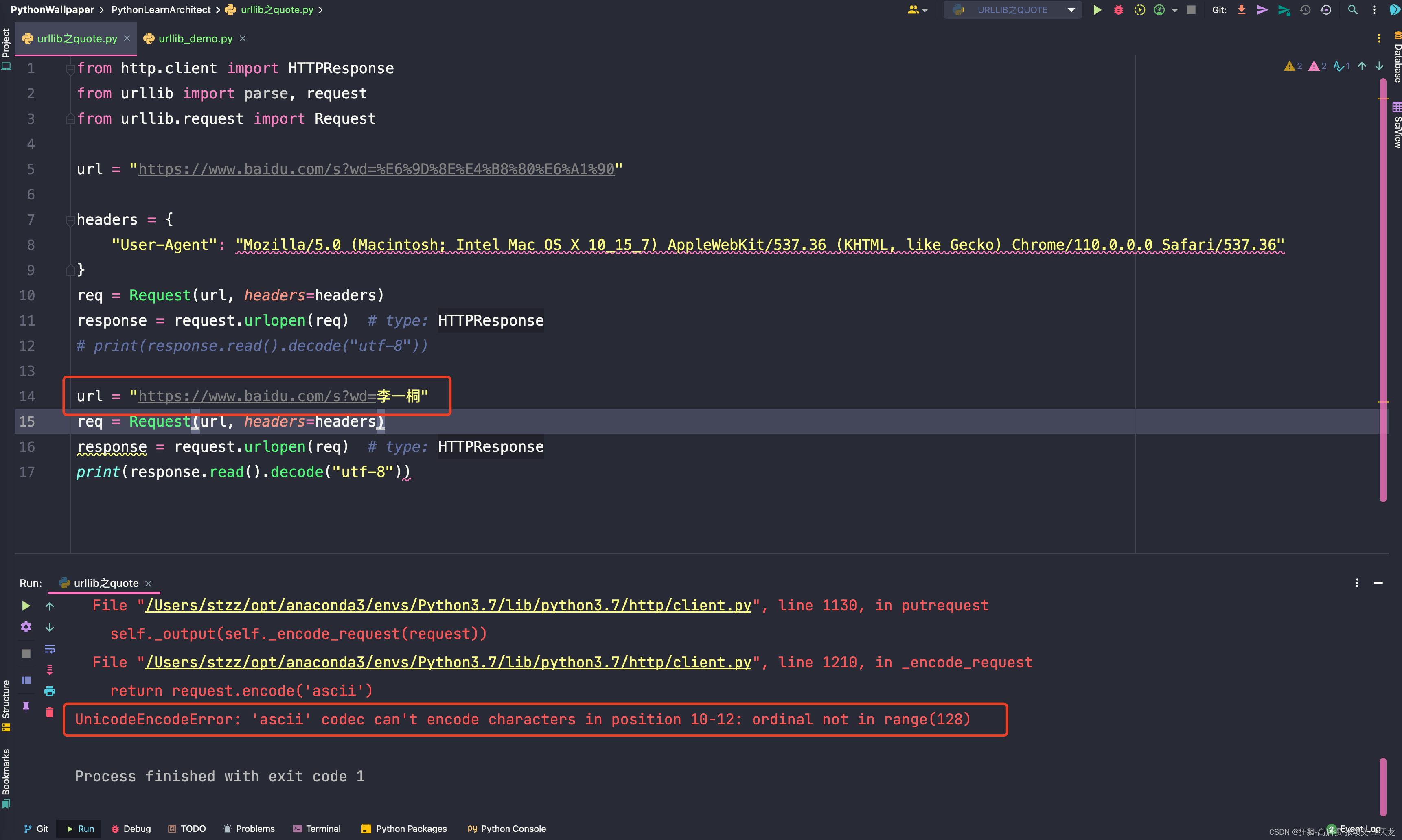
正确的代码:
from http.client import HTTPResponse
from urllib import parse, request
from urllib.request import Requesturl = "https://www.baidu.com/s?wd=%E6%9D%8E%E4%B8%80%E6%A1%90"headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36"
}
req = Request(url, headers=headers)
response = request.urlopen(req) # type: HTTPResponse
# print(response.read().decode("utf-8"))url = "https://www.baidu.com/s?wd="
url = url + parse.quote("李一桐")
req = Request(url, headers=headers)
response = request.urlopen(req) # type: HTTPResponse
print(response.read().decode("utf-8"))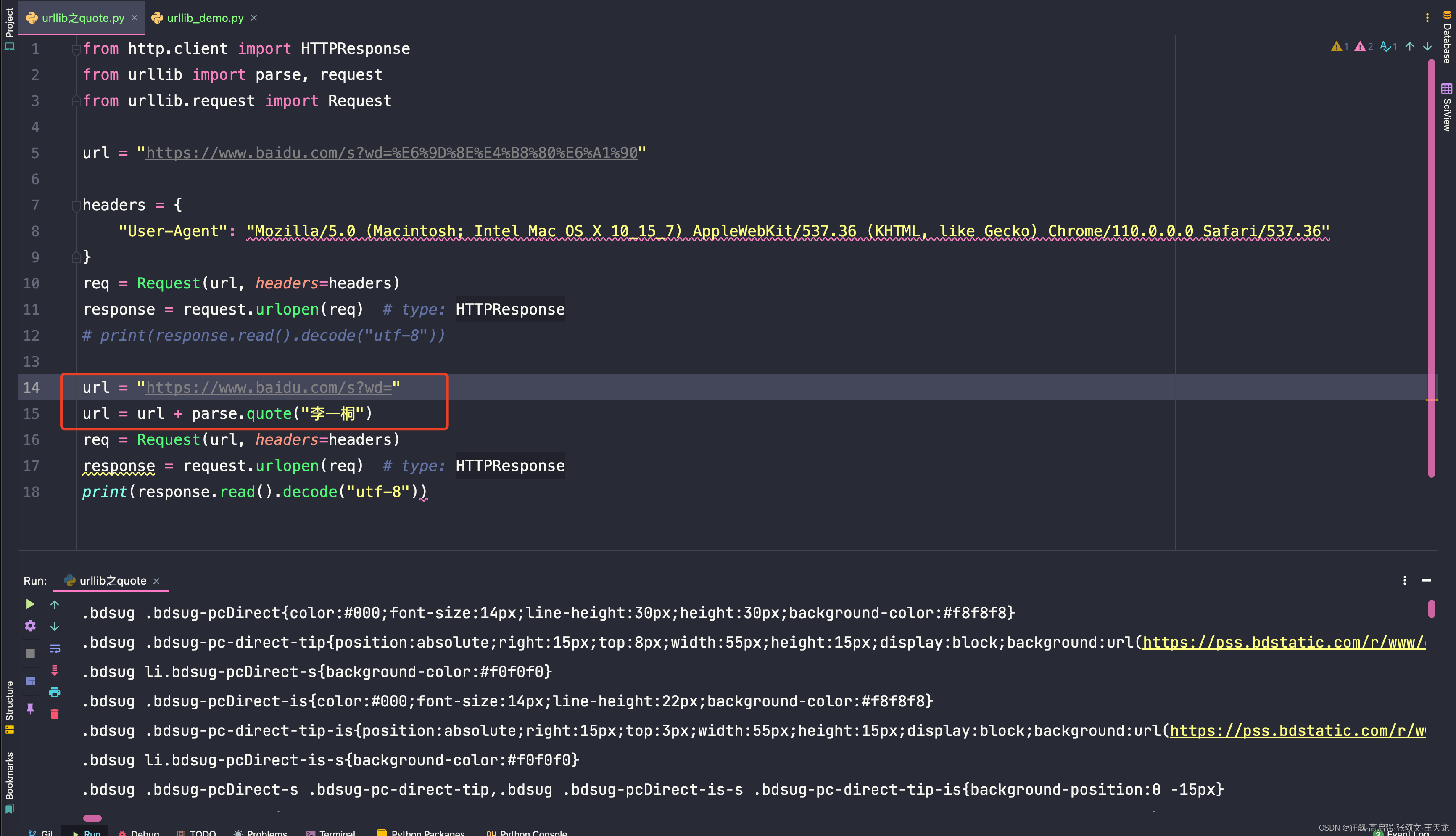
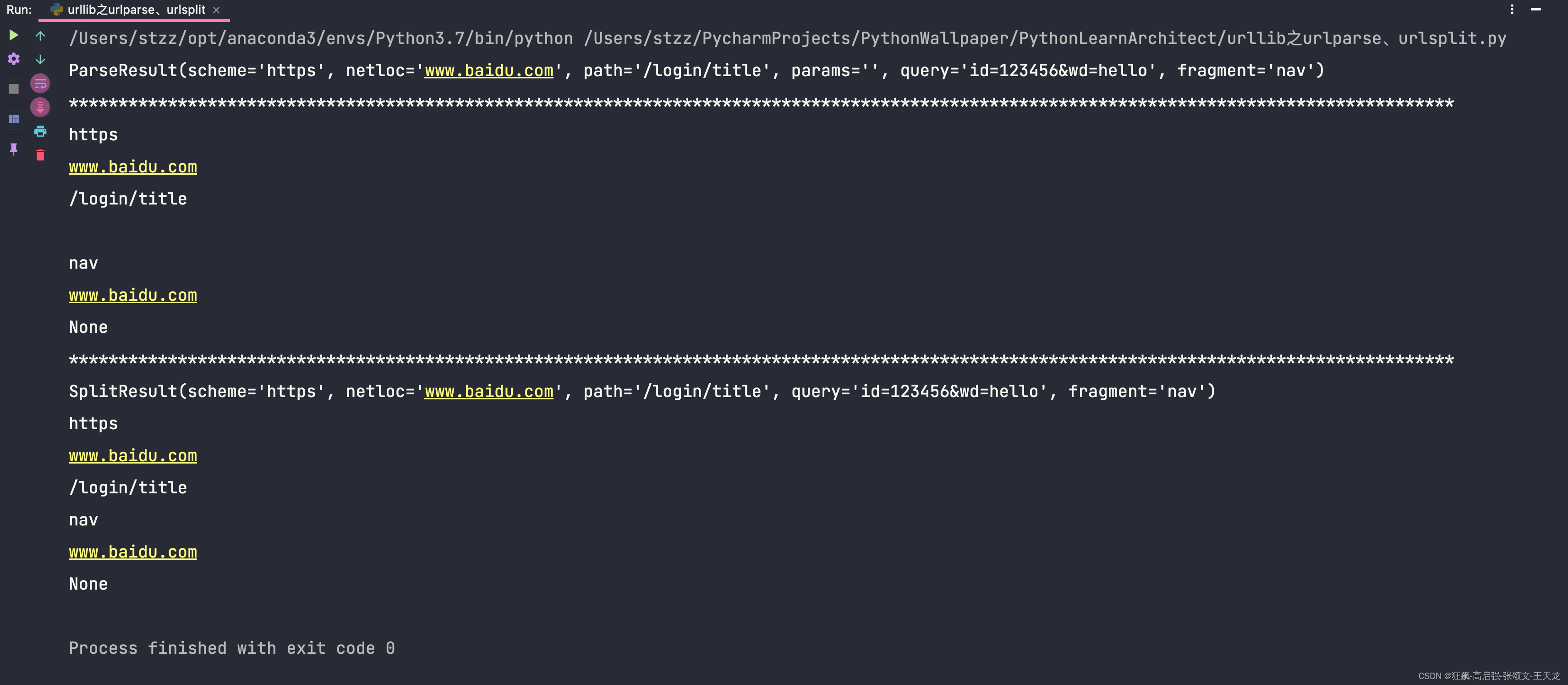
urlparse、urlsplit的使用:
from urllib import parseurl = "https://www.baidu.com/login/title?id=123456&wd=hello#nav"
result = parse.urlparse(url)
print(result)
print("*" * 140)
print(result.scheme)
print(result.netloc)
print(result.path)
print(result.params)
print(result.fragment)
print(result.hostname)
print(result.port)print("*" * 140)result = parse.urlsplit(url)
print(result.scheme)
print(result.netloc)
print(result.path)
print(result.fragment)
print(result.hostname)
print(result.port)