mysql进阶
mysql进阶
视图
视图是一个基于查询的虚拟表,封装了一条sql语句,通俗的解释,视图就是一条select查询之后的结果集,视图并不存储数据,数据仍旧存储在表中。
创建视图语句:
create view view_admin as select * from admin
使用视图语句:
select * from view_admin
一个在线代码格式化工具:http://word.wdlx.com/
存储过程
存储过程是事先经过编译并存储在数据库中的一段sql语句的集合,这段sql语句中一般包含着逻辑处理,调用存储过程可以减少应用程序与数据库的交互次数。
语法:
参数共有三种:IN 输入型 OUT 输出型 INOUT 输入输出型
创建存储过程
DELIMITER$$
CREATE
PROCEDURE`news`.`test1`(INp_accountINT,OUTp_countINT)
BEGIN
SELECTCOUNT(1) INTOp_accountFROMadminWHEREaccount=P_account;
SELECTp_account;
END$$
DELIMITER ;
CALLtest1('admin',@p_count)
declare中用来声明变量,变量赋值用default使用存储过程:@为占位符
具体使用
DELIMITER$$
CREATEPROCEDURE test(IN p_day INT)
BEGIN
CASEWHEN p_day = 0THEN
SELECT"星期天";
ELSE
SELECT"星期一";
ENDCASE;
END$$
CALL test(2);
函数
函数语法:
createfunction 函数名([参数列表]) returns 数据类型
begin
DECLARE 变量;
sql 语句;
return 值;
end;
注意:
1.参数列表包含两部分:参数名 参数类型
2.函数体:肯定会有 return 语句,如果没有会报错
3.函数体中仅有一句话,则可以省略 begin end
4.使用 delimter 语句设置结束标记
设置函数可以没有参数
SET GLOBAL log_bin_trust_function_creators=TRUE;
删除函数
DROP FUNCTION 函数名;
具体使用:
DELIMITER$$
CREATEFUNCTION checkUserType(p_type INT) RETURNSVARCHAR(4)
BEGIN
IF p_type = 0THEN
RETURN'管理员';
ELSE
RETURN'业务用户';
ENDIF;
END$$
SELECT tu.account,checkUserType(tu.type)utype FROMuser tu
触发器
触发器是一种特殊的存储过程,其特殊性在于它并不需要用户直接调用,,而是在对表进行增删改操作之前或之后就进行的存储过程。
特点:
1.与表相关联
触发器定义在特定的表上,这个表称为触发器表。
2.自动激活触发器
当对表中的数据执行 INSERT、UPDATE 或 DELETE 操作时,如果对表上的这 个特定操作定义了触发器,该触发器自动执行,这是不可撤销的。
3.不能直接调用
与存储过程不同,触发器不能被直接调用,也不能传递或接受参数
4.作为事务的一部分
触发器与激活触发器的语句一起做为对一个单一的事务来对待,可以从触发器中 的任何位置回滚。
语法:
CREATETRIGGER 触发器名称 触发时机 触发事件
ON 表名称
FOREACHROW-- 行级触发
BEGIN
语句
END;
触发时机:before以及after两种
触发事件:insert,delete,update三种
DELIMITER $$
CREATETRIGGER save_user_log AFTERINSERT
ONuser
FOREACHROW
BEGIN
INSERTINTO test(id,NAME)VALUES(new.id,new.account);
END$$;
--触发
INSERTINTOuser(account)VALUES('jim')
mysql架构
mysql架构共有四层:
连接层:最上层为客户端及连接服务,包含本地的socket通信;主要完成一些类似于连接处理,授权认证,及相关的安全方案。
服务层:这一层主要完成mysql核心服务架构,SQL接口,缓存查询以及SQL分析,优化函数执行
引擎层:存储引擎层,负责mysql数据库中数据的存储和提取
物理文件存储层:将数据存储在文件系统中,并完成与存储引擎的交互。
mysql引擎
mysql中用各种技术存储在文件中,这些技术提供了各种不同的功能和能力,用于改善应用的整体功能,这些不同的技术以及配套的相关功能称之为mysql引擎。
数据库引擎是用于存储,处理,保护数据的核心服务,利用数据库引擎可迅速控制访问权限并快速处理事务。
部分相关语法:
查看支持的引擎
SHOWENGINES;
查看表引擎
SHOWTABLESTATUSLIKE'表名'修改引擎
方式1:将mysql.ini中default-storage-engine=InnoDB,重启服务. 方式2:建表时指定CREATETABLE表名(...)ENGINE=MYISAM;
方式3:建表后修改ALTERTABLE表名ENGINE=INNODB;
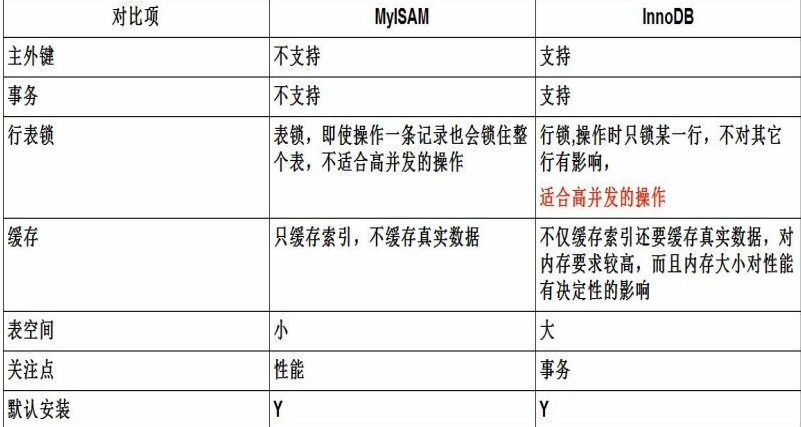
存储引擎中我们主要了解分析Innodb以及MyIsam
Innodb:mysql数据库中默认的存储引擎,Innodb是一个事务型存储引擎,支持行级锁,主外键约束以及数据缓存,不存储表的总行数。
MyIsam:MyIsam也是mysql引擎,但是没有提供对数据库事务的支持,也不支持外键约束和行级锁以及数据缓存,支持表锁,存储表的总行数
两者对比:
索引
什么是索引?
索引是一个已经排好序的快速查找的数据结构,也是帮助mysql高效获取数据的数据结构。
索引原理
索引的目的在于提高查询效率,相当于一个书籍目录,以此定位到下一个更小的查询范围。本质上都是通过不断的缩小查询范围,来筛选出最终的数据结果,将随机事件变成一个顺序事件,降低查询难度。
索引优势劣势
优势:提高数据查询的效率,减少了数据库的IO成本
劣势:维护索引需要占用内存空间,除此之外,对表进行增删改时都需要对索引进行维护,消耗了时间。
索引分类
主键索引:设定主键后,数据库会主动建立索引
ALTERTABLE 表名 addPRIMARYKEY 表名(列名);
删除建主键索引:
ALTERTABLE 表名 dropPRIMARYKEY ;
单值索引:即一个索引只包含单个列,一个表可以有多个单列索引
CREATEINDEX 索引名 ON 表名(列名);
删除索引:
DROPINDEX 索引名;
唯一索引:索引列的值必须唯一,允许为 null
CREATEUNIQUEINDEX 索引名 ON 表名(列名);
删除索引
DROPINDEX 索引名 ON 表名;
组合索引(复合索引):
即一个索引包含多个列,在数据库操作期间,复合索引比单值索引所需要的
开销更小(对于相同的多个列建索引),当表的行数远大于索引列的数目时可
以使用复合索引
创建复合索引
CREATEINDEX 索引名 ON 表名(列 1,列 2...);
删除索引:
DROPINDEX 索引名 ON 表名;
组合索引最左前缀原则
列如表中有 a,b,c 3 列,为 a,b 两列创建组合索引,那么在使用时需要满足最左
侧索引原则.在使用组合索引的列作为条件时,必须要出现最左侧列为条件,否则 组合索引不生效.
select * fromtablewhere a=’’and b=’’索引生效
select * fromtablewhere b=’’and a=’’索引生效
select * fromtablewhere a=’’and c=’’索引生效
全文索引
需要模糊查询时,一般索引无效,这时候就可以使用全文索引了
查看索引:
SHOWINDEXFROM 表名;
索引创建原则
那些情况创建索引
主键自动创建唯一索引
经常用作where字段中查询字段的应创建索引
查询中用于与其他表关联的外键关系建立索引
查询中排序的字段,排序的字段若使用索引访问,大大提升了访问的速度
那些情况不能创建索引
表记录太少时,不需要创建索引
经常增删改的表必须要创建索引,虽然提高了查询数据的速度,但是每次定增删改时都需要维护索引
where条件中用不到的字段不需要创建表
索引数据结构
Indodb引擎的索引结构由B+树实现,为什么不是二叉树以及平衡二叉树呢,因为两者存储索引后,高度过大,查询数据的效果并不明显,而B+树可以通过一个结点存储多个数据降低了高度,并且非叶子结点不存储数据可以存放更多的索引,将数据都记录在叶子结点上,并且所有叶子都通过一个链表连接。
B树与B+树的区别(为什么使用B树):
B树每一个结点都存储有索引和数据,这样就导致一个结点可以存放的索引不会太多,而B+树的只有叶子结点存储数据,其它结点可以存放更多的索引,且B+树的维护了一条链表连接叶子结点,可以更好的支持全表扫描。
聚簇索引与非聚簇索引
聚簇索引:找到索引的位置,即就找到了数据,数据与索引存储在同一个文件中。Innodb中的索引大多是聚簇索引。
非聚簇索引:数据与索引是分离的,找到了索引,还是没有找到数据,需要找到主键再次回表查询,才可以找到数据。MyIsqm中的索引大多是非聚簇索引。
分离两者的主要依据就是是否回表查询,需要会回表查询的就是非聚簇索引,反之则是聚簇索引。