【数据挖掘】1、综述:背景、数据的特征、数据挖掘的六大应用方向、有趣的案例
目录
- 一、背景
- 1.1 学习资料
- 1.2 数据的特征
- 1.3 数据挖掘的应用案例
- 1.4 获取数据集
- 1.5 数据挖掘的定义
- 二、分类
- 三、聚类
- 四、关联分析
- 五、回归
- 六、可视化
- 七、数据预处理
- 八、有趣的案例
- 8.1 隐私保护
- 8.2 云计算的弹性资源
- 8.3 并行计算
- 九、总结
一、背景
1.1 学习资料
推荐书籍如下:

Google Scholar:搜学术期刊
开源数据集:UCI Machine Learing Repository
开源 GUI 工具,方便快速上手:WEKA
KDD nuggets: 数据挖掘网站

1.2 数据的特征
数据是最底层的概念,其中有价值的才能称作信息。
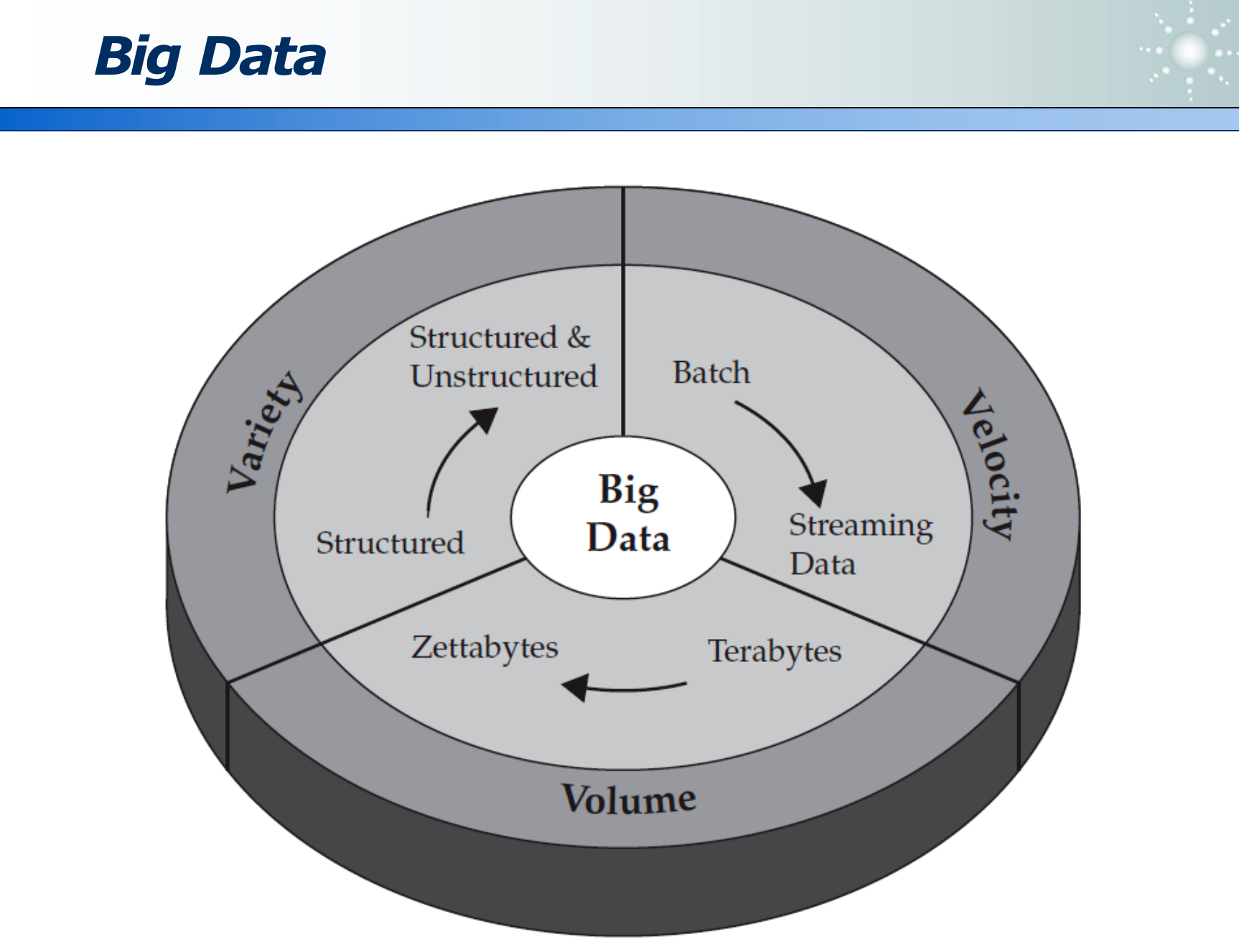
大数据有三个特征:
- Volumn:容量够大,TB 变为 ZB 等。
- Variety:多样:从结构化的二维 excel 表格,到非结构化的文字、声音、图像、视频等待加工的数据。
- Velocity:速度:从静态数据集,到动态高 QPS 的流式数据处理,对算法有很高要求。
1.3 数据挖掘的应用案例
大数据的应用场景:
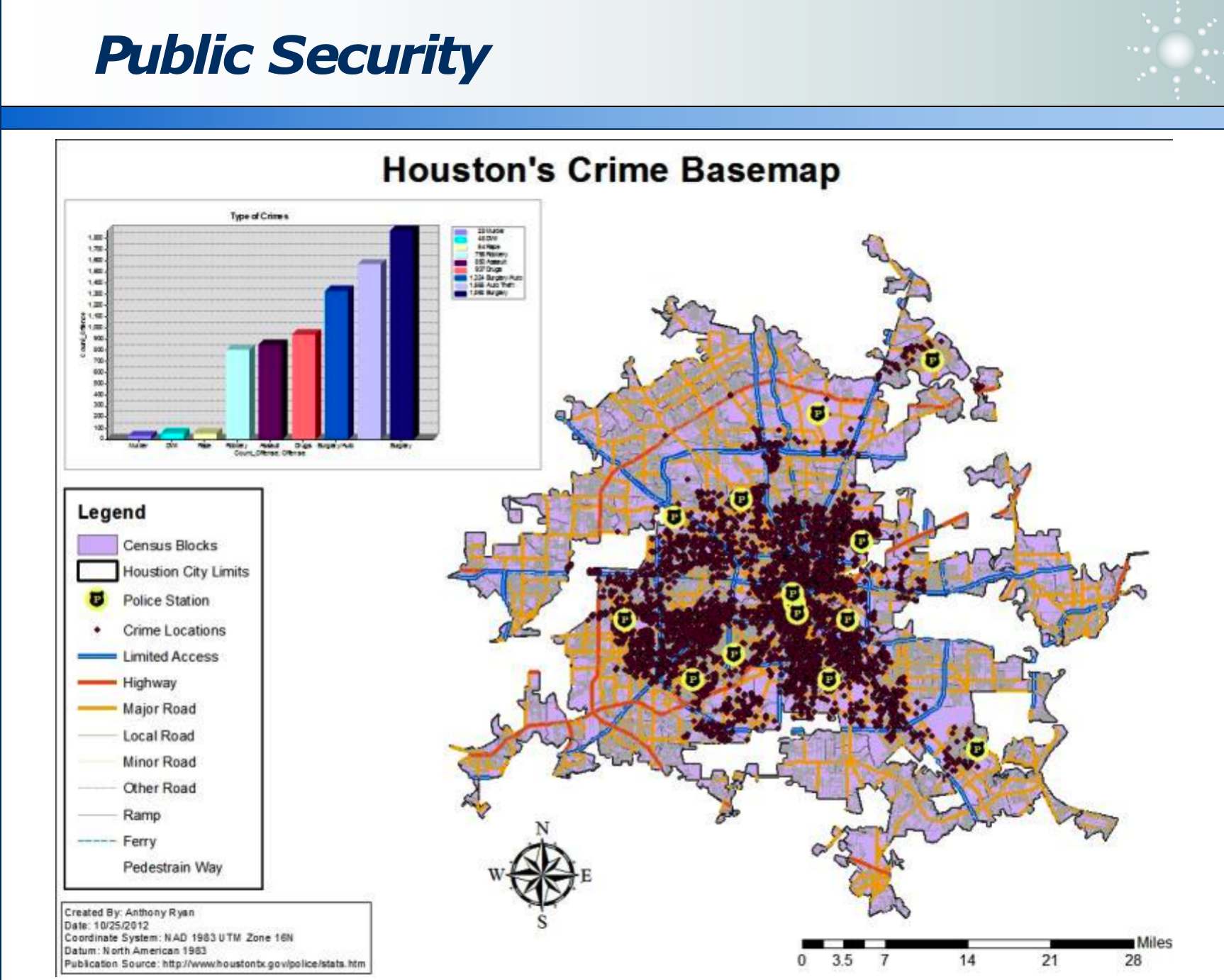
- 安防预测:预测疑犯行为,提前防火,而不是事后疲于救火。
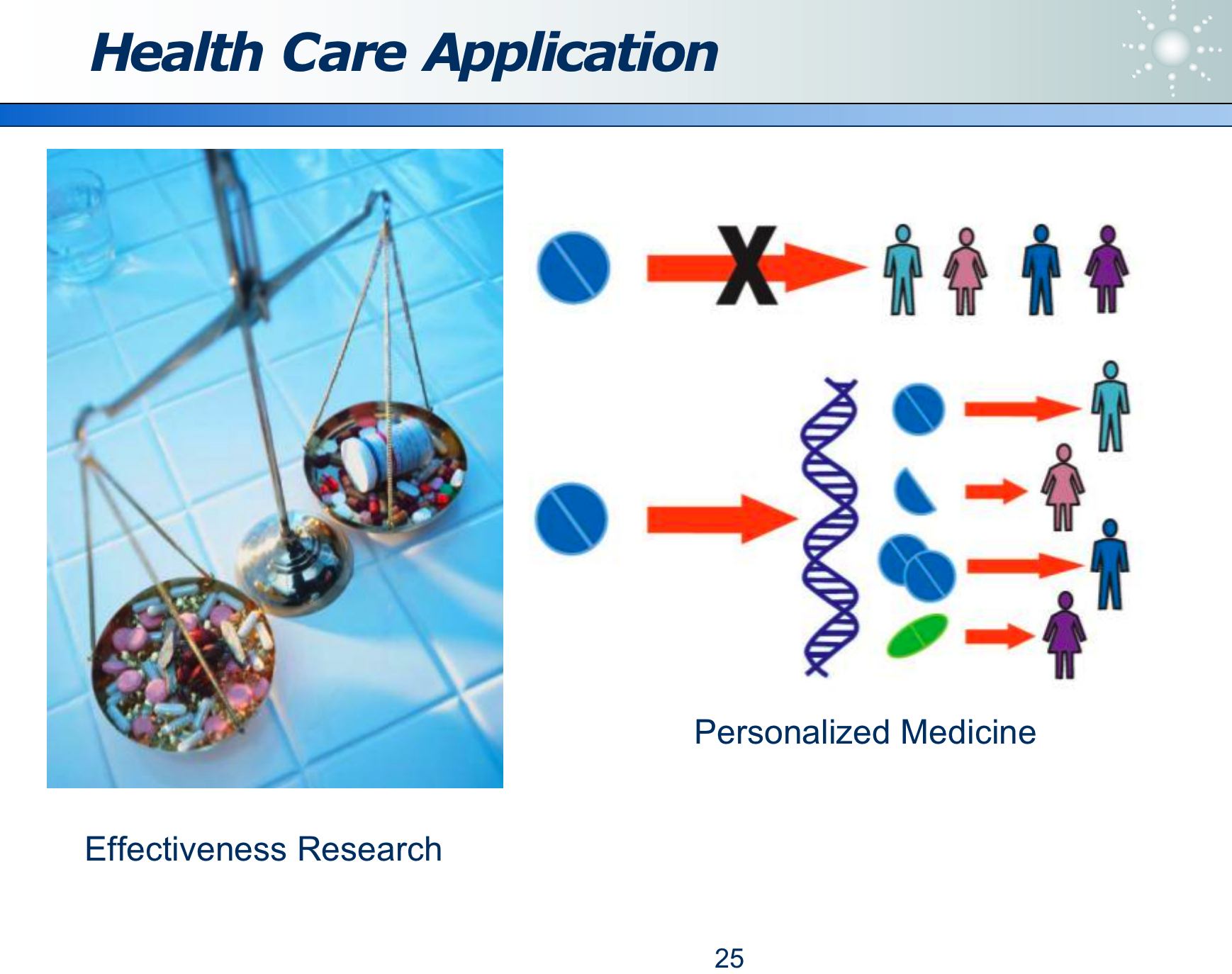
- 对症下药:
- APP 地理位置可视化:
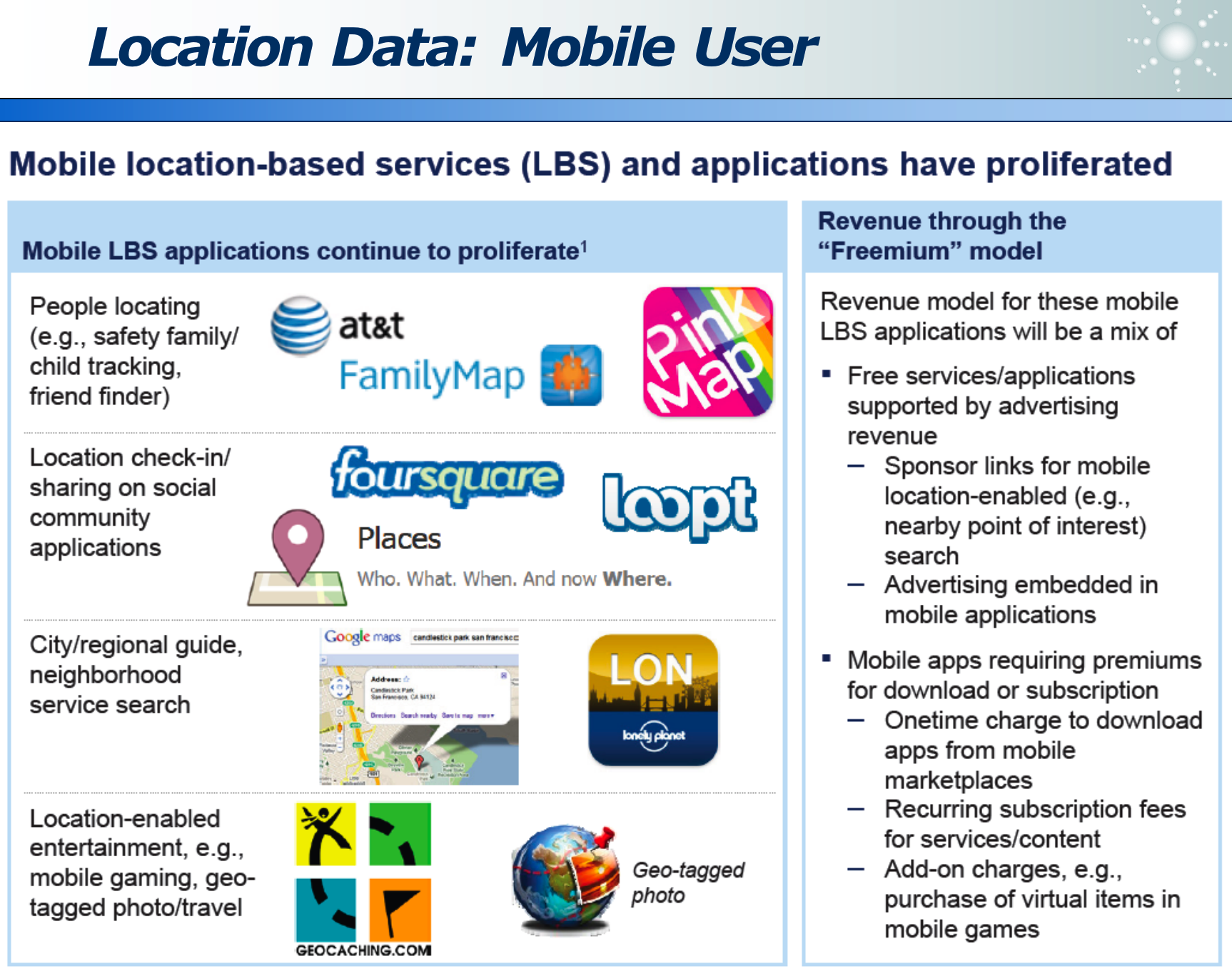
- 商店购物:区域热力图、人员轨迹、停留时间 =》 精准营销(推荐商品)

- 情感分析:文字识别,分析情感

- 体育数据分析:2000 年左右国外真实案例,小牌球队,利用数据挖掘分析各球员的特点,组织球队布阵,取得商业成功,也将此真实故事拍成了电影《点球成金》。
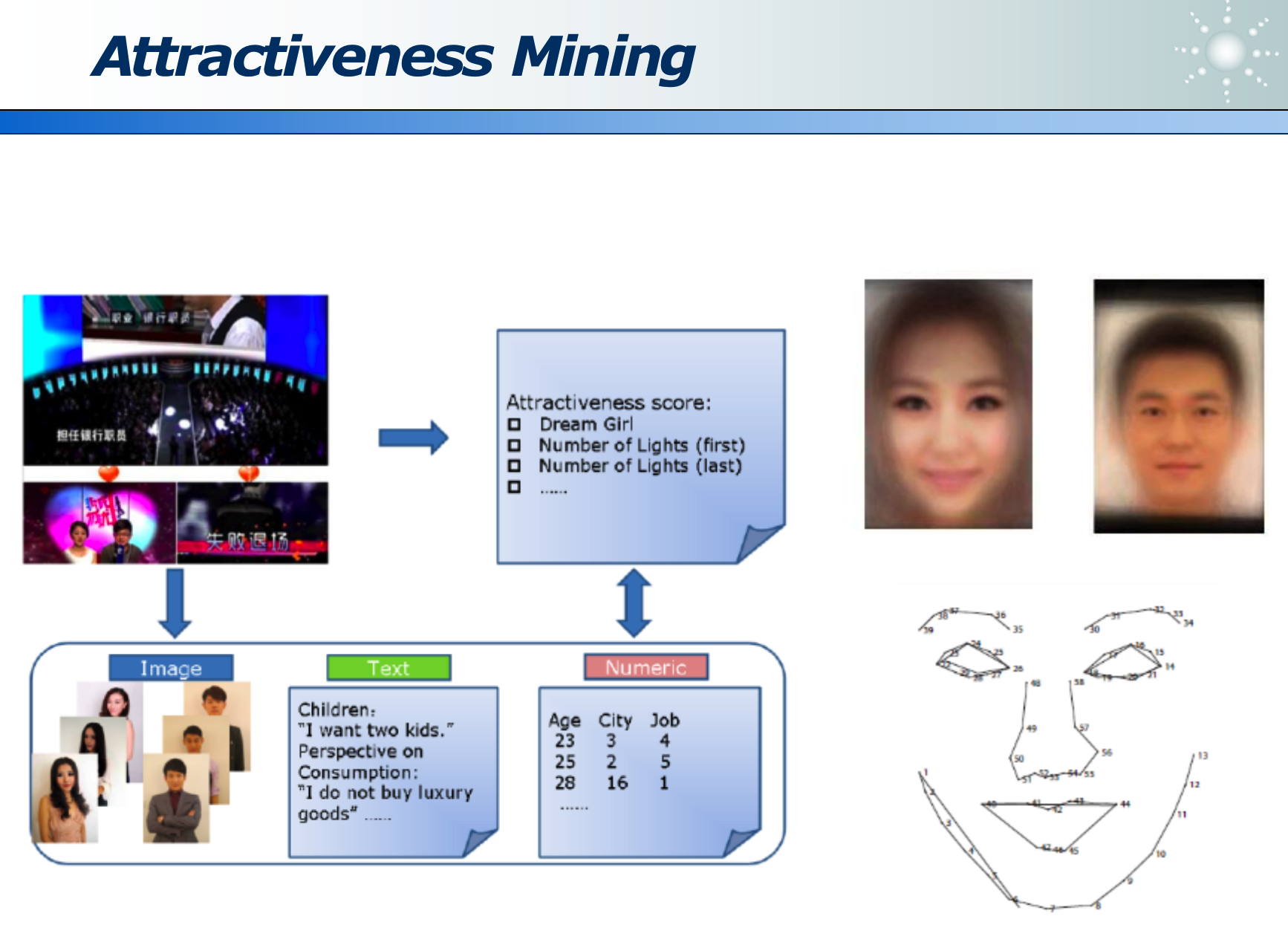
- 美女挖掘:通过非诚勿扰各女嘉宾的信息(包括身高、面部关键点度量、家庭背景、对心动男生的期待等),挖掘大众心中的心动女生有何特征。
1.4 获取数据集
越来越多公开数据集出现:法律公开(允许自由使用),技术容易获取(易结构化,易清洗)。下面是一些公开数据集网址,可以多多使用。

政府其实有极多数据,其也会开放很多数据,如下,方便大家做多维数据融合挖掘:
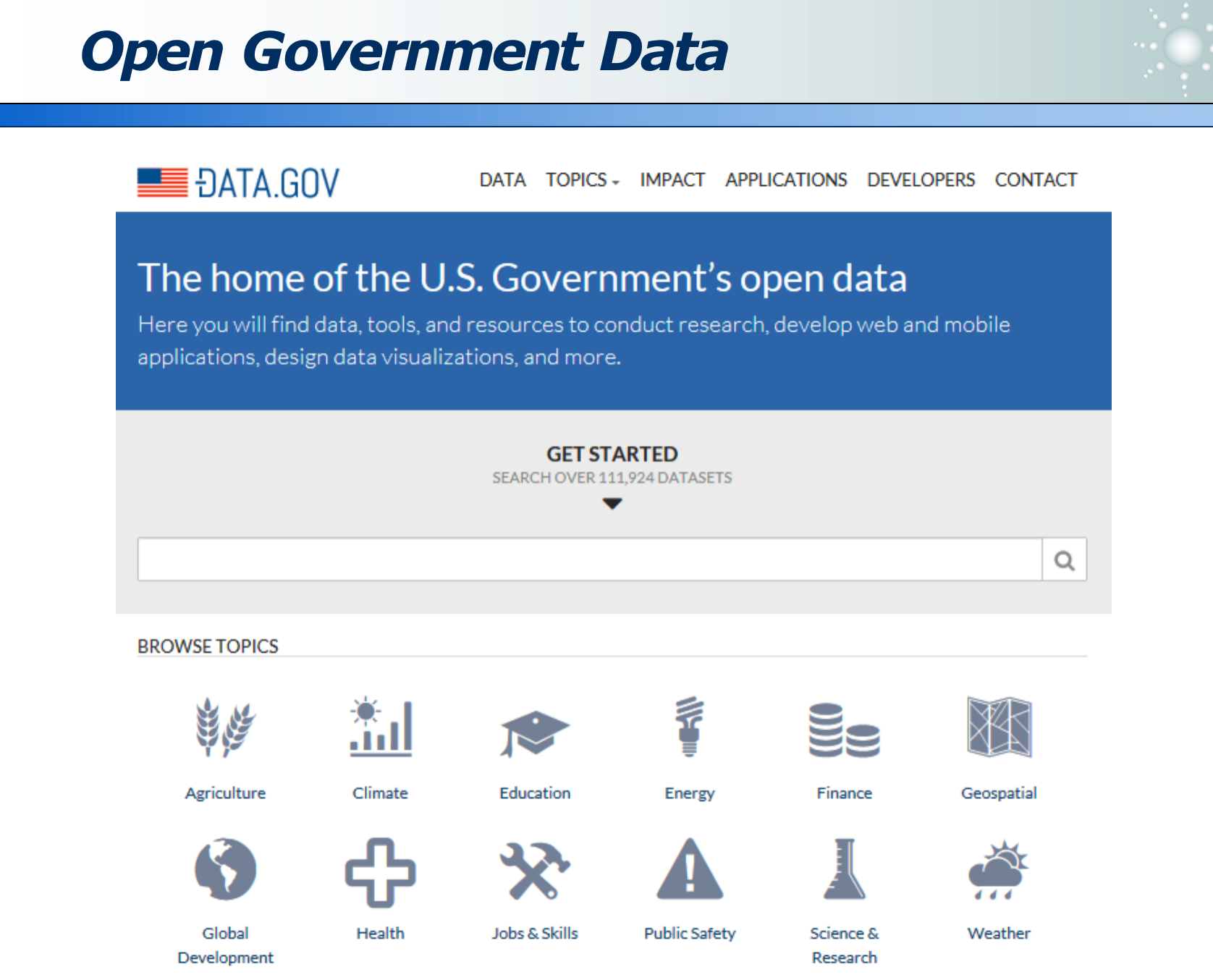
1.5 数据挖掘的定义
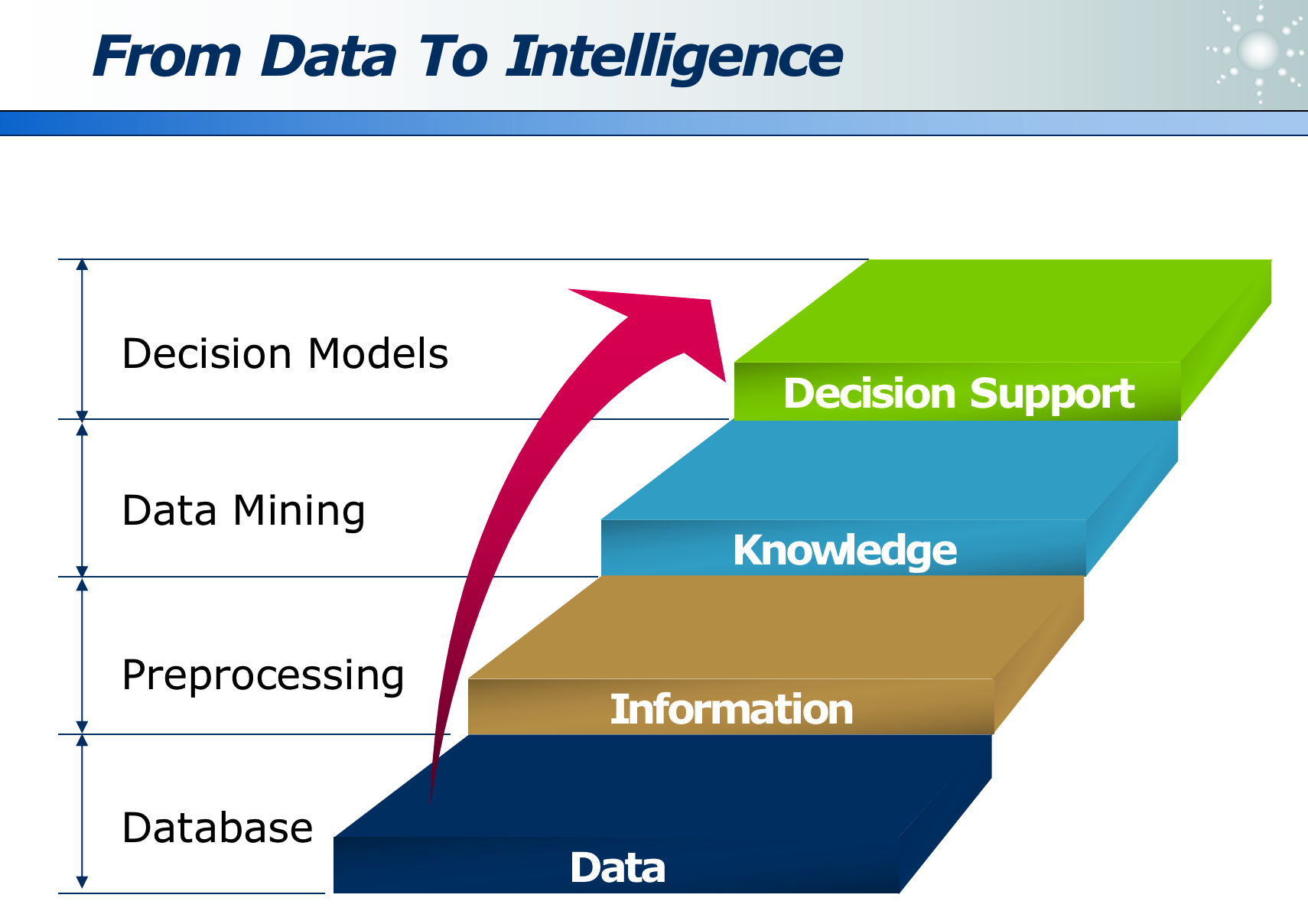
不同于以往的数据处理,而是针对大量数据,发掘出有趣、有用、隐含的信息。

数据清洗后变为信息,信息挖掘得到知识,知识通过领域模型得到有用的决策。
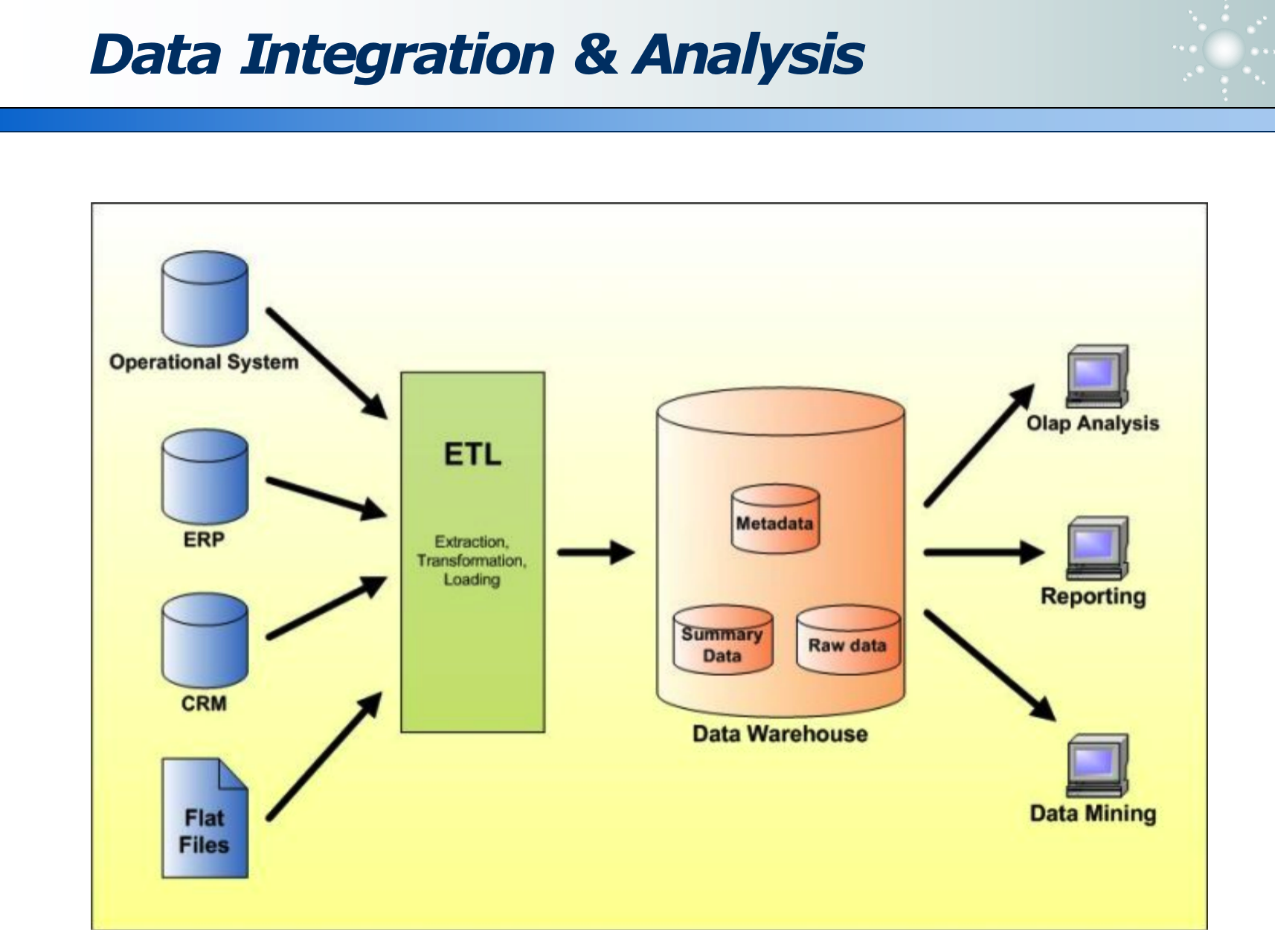
ETL 如下:
工业界数据挖掘和可视化软件有很多:
二、分类
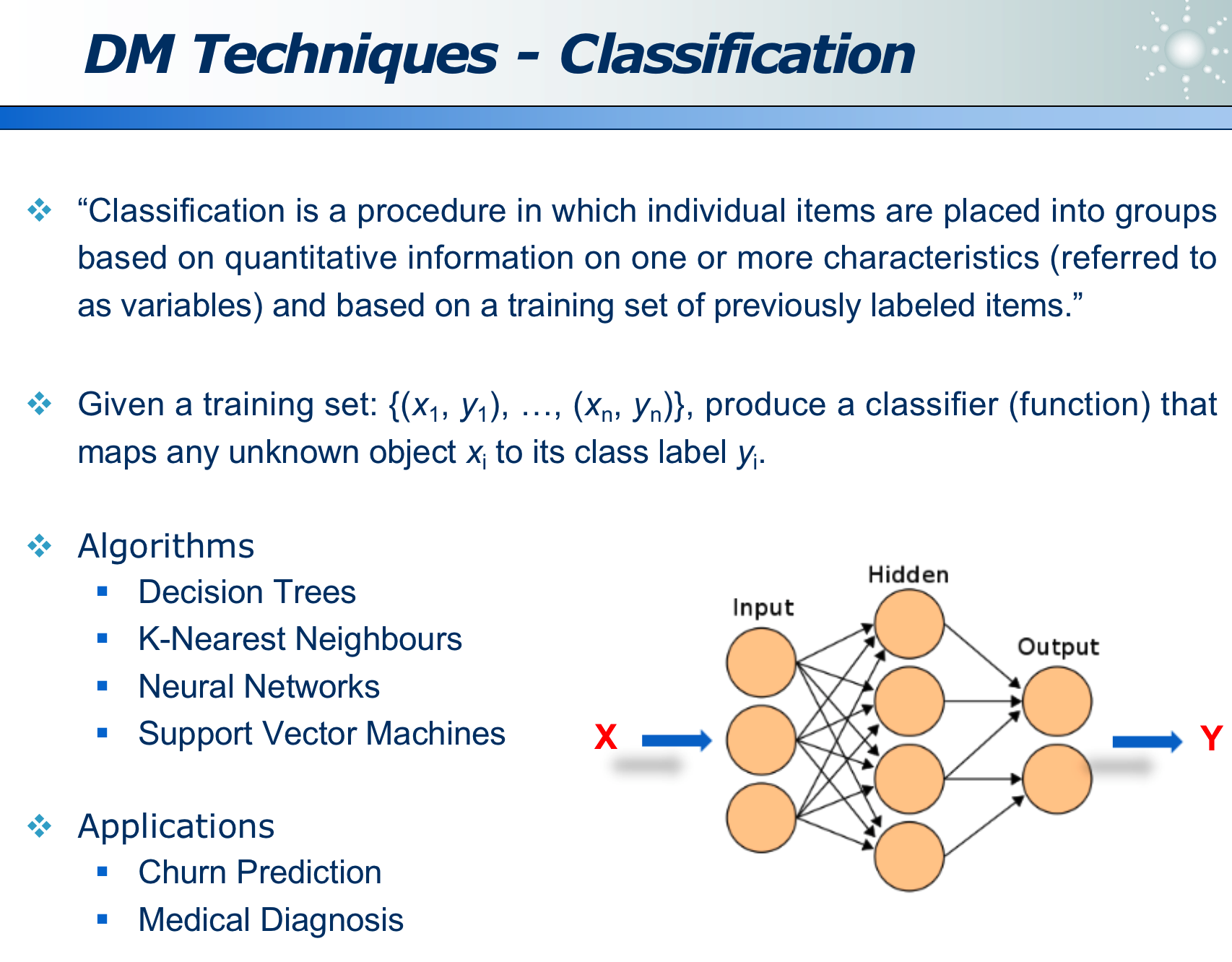
分类任务是通过给定一些训练集,训练后得到分类模型模型,下面几种模型是常用的分类模型:
- 决策树
- K 近临
- 神经网络
- SVM
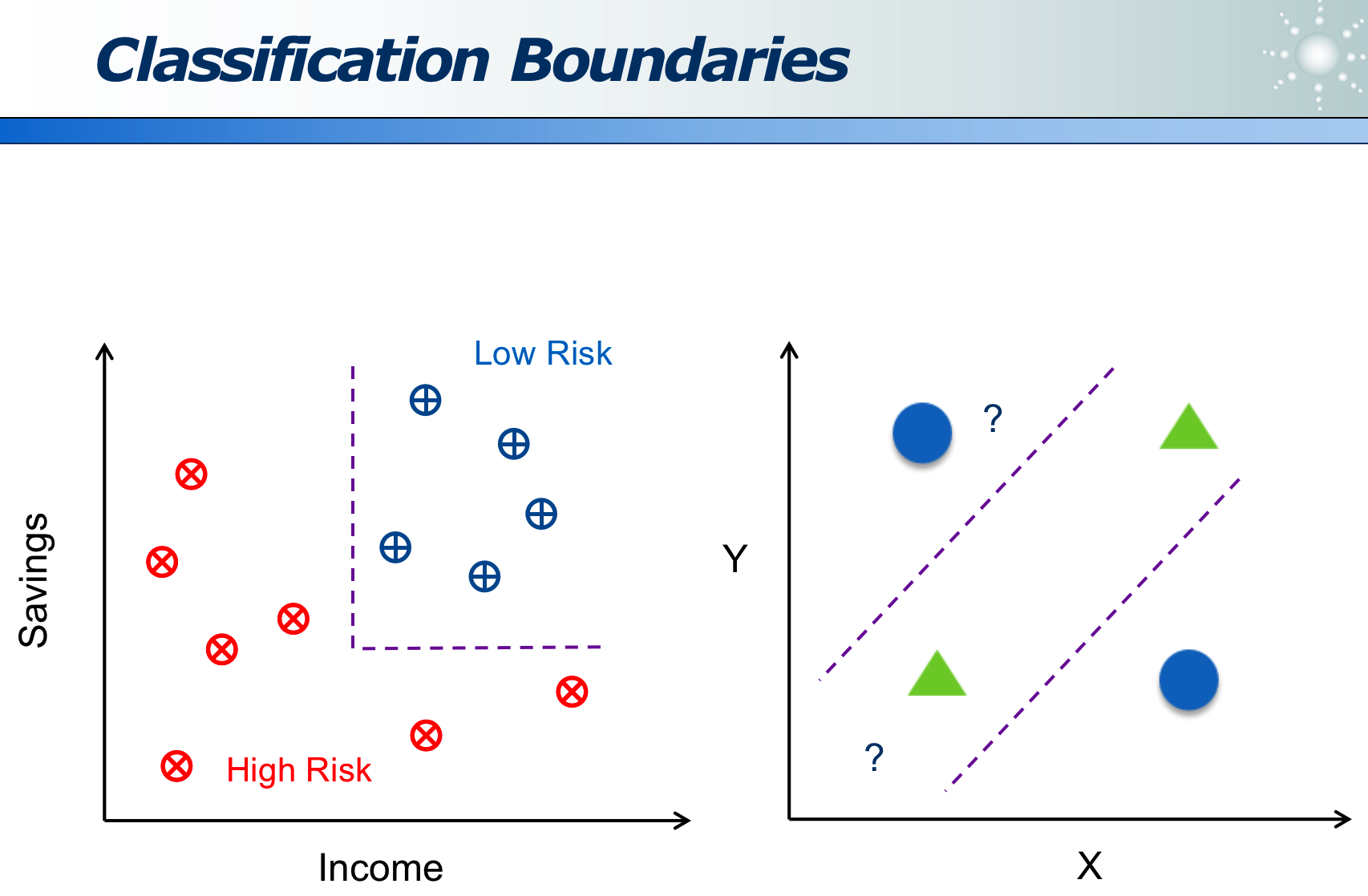
分类的本质其实是,得到分界面:
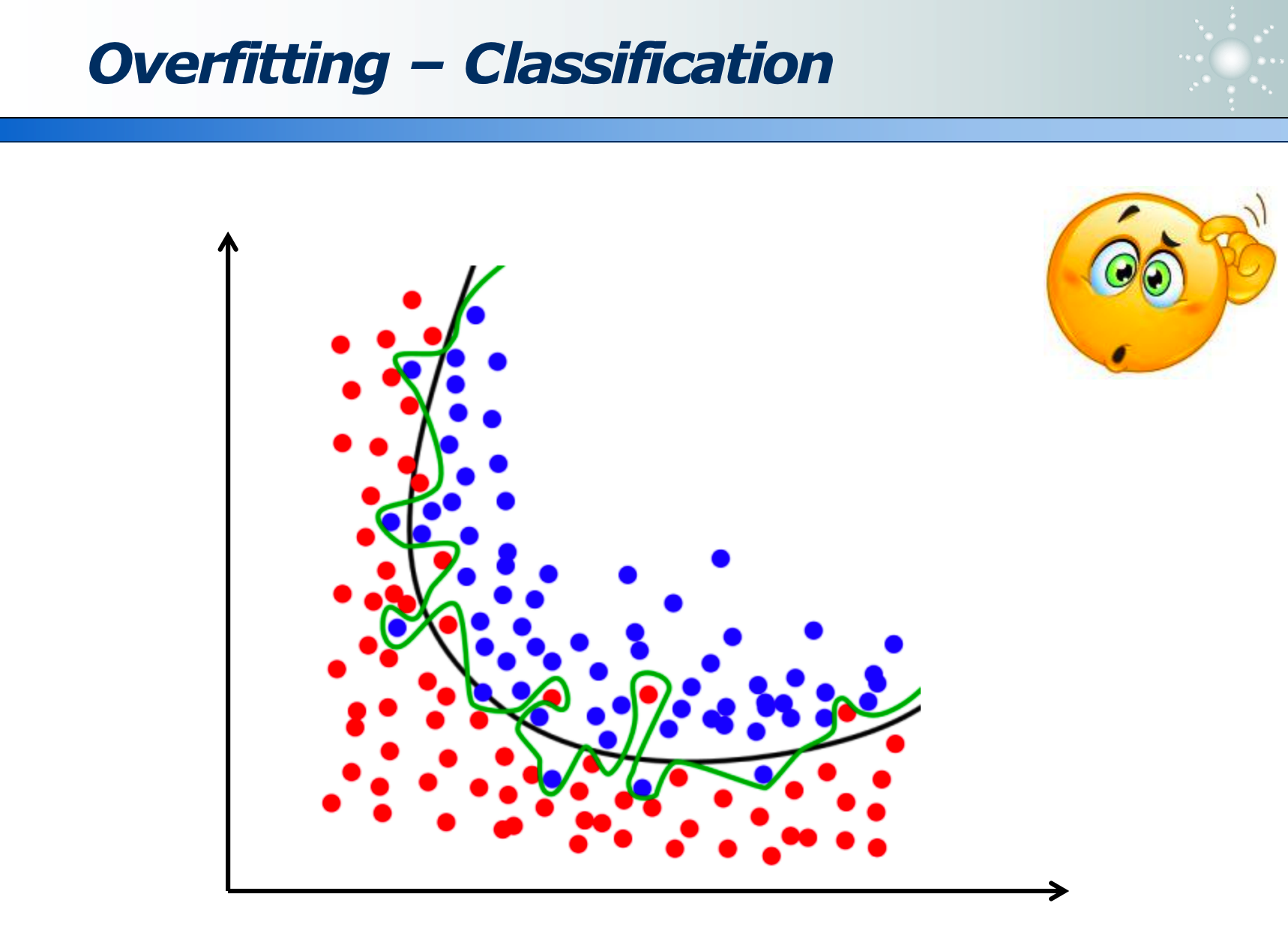
我们需要的是黑色的线(因为是平滑的),因为绿色的线是过拟合(即死记硬背的模型,并未东西出数据规律)
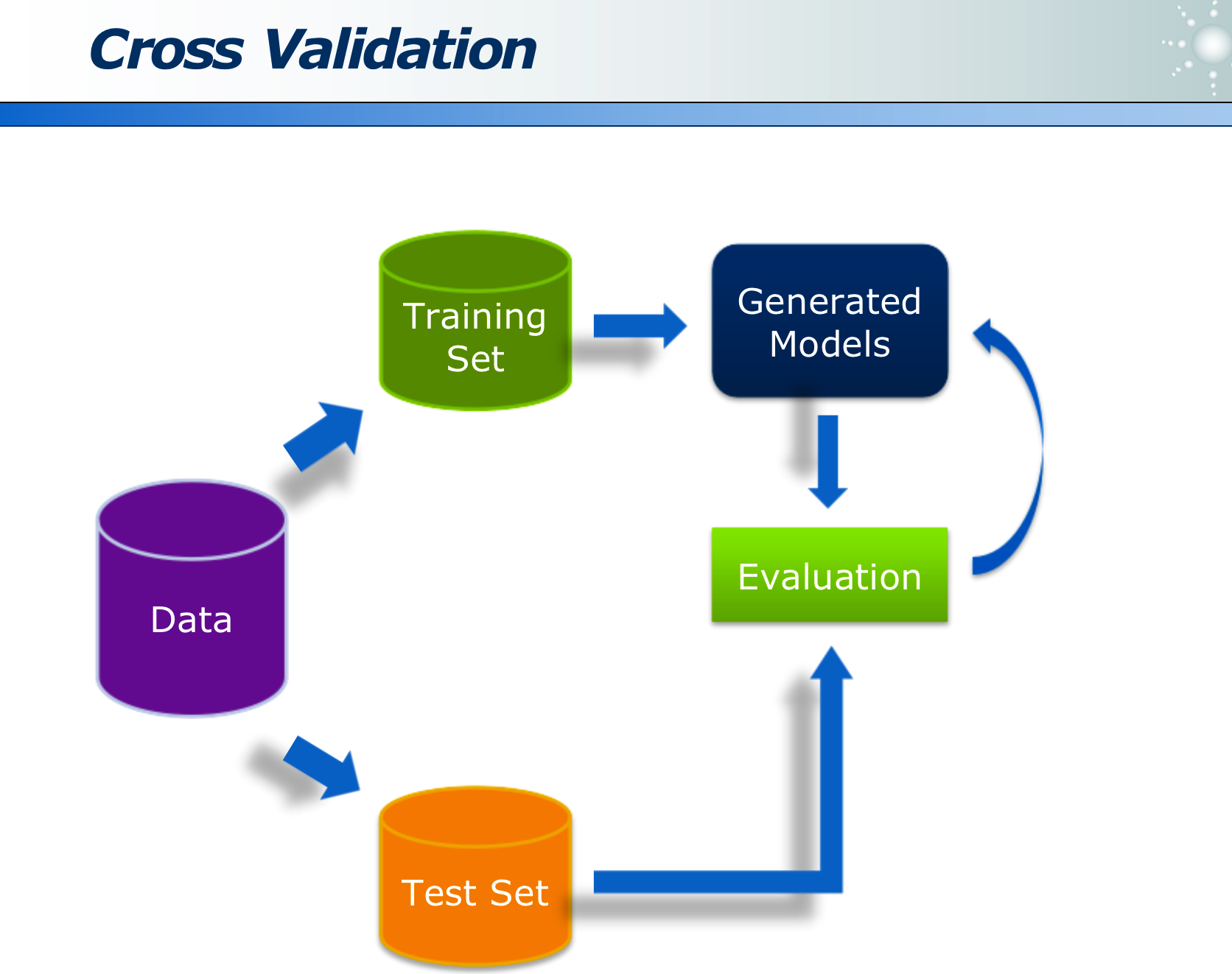
数据的训练集和预测集需要不同,才能体现模型的有效性。
混淆矩阵,是各种模型指标的定义根基:
- TP:即数据本身的ActualValue即为 Positive,且其预测得到的 PredictedValue 也 Truely 预测为 Positive,即预测对了。
- TN:即数据本身的ActualValue即为 Negative,且其预测得到的 PredictedValue 也 Truely 预测为 Negative,即预测对了。
- FP:即数据本身的ActualValue即为 Negative,且其预测得到的 PredictedValue 却 Falsely 预测为 Positive,即预测错了。
- FN:即数据本身的ActualValue即为 Positive,且其预测得到的 PredictedValue 也 Falsely 预测为 Negative,即预测错了。
基于这些概念:又衍生了最常用的两个呈反比的指标:例如预测集共 500 个,其中 200 个为 A 类,300 个为 B 类。模型预测出其中 50 个为 A 类(其中预测对的是 30 个)。
- Precision准确率:模型真正预测对的数量 / 「模型预测」「出的」数量。即 30 / 50。
- Recall查全率: 模型真正预测对的数量 / 「总预测集」的「对的」数量。即 30 / 200。
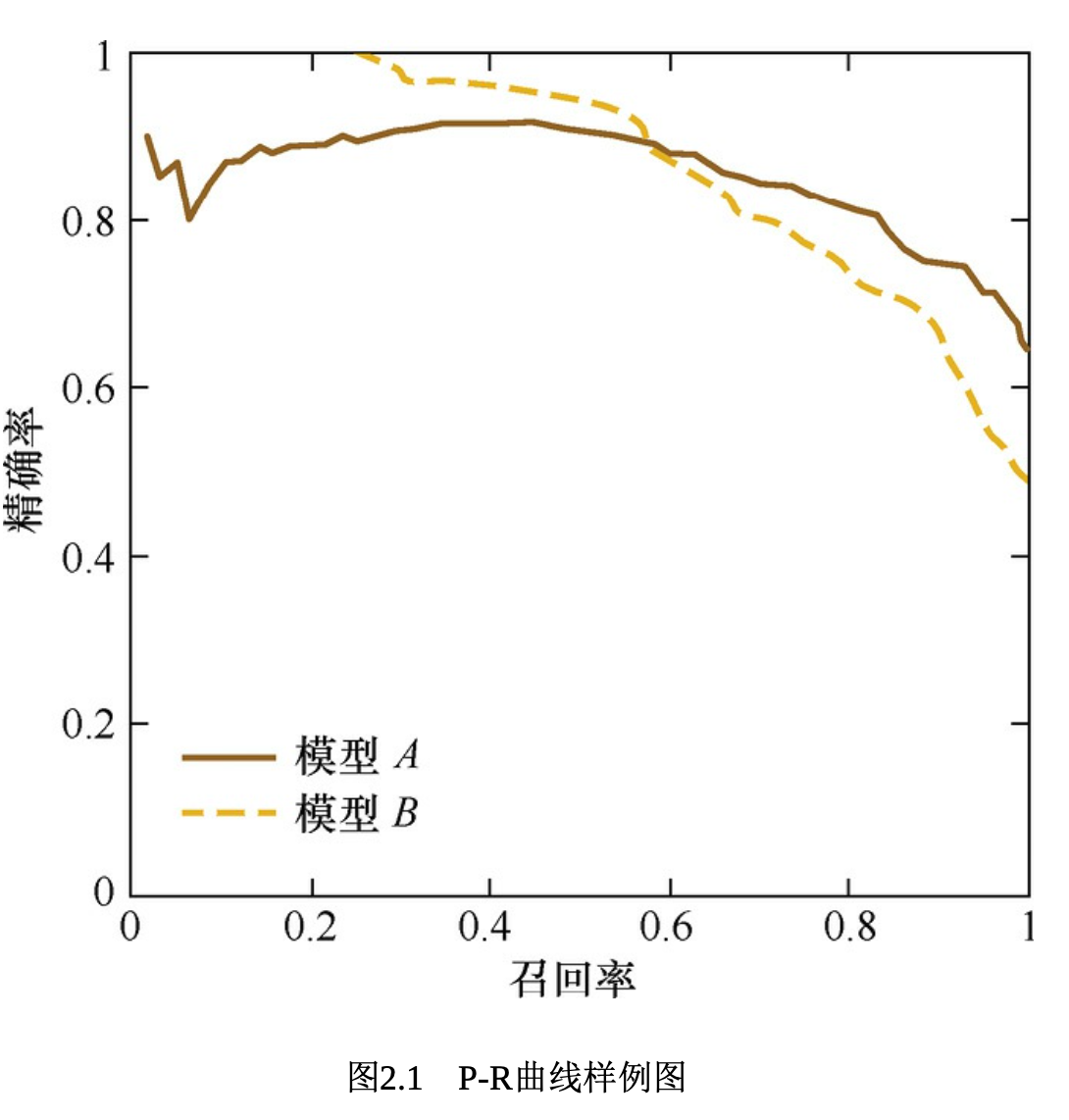
P - R 曲线如下:
- Precision 和 Recall 二者的「PR曲线呈反比关系」(纵轴为 Precision,横轴为 Recall,每个点位不同的业务阈值。因为二者呈反比关系,故一般选「适中」的业务阈值来使得 P 和 R 可以「兼顾」):
- 因为模型输出都是介于 0 到 1 的得分,如 0.7,标识有 70%的概率是 A类。
- 而应用层可以定义阈值,若高于阈值则视为「业务视为:输出 A 类」,反之若低于阈值则视为「业务视为:输出非 A 类」。
- 如果业务把阈值定的很高(例如 0.999)那么输出结果很少但很准确, 即「Recall低(漏了很多结果)」而「Precision高(判断很准确,很严格)」。
- 如果业务把阈值定的很低(例如 0.001)那么输出结果很多但很多误报,即「Recall高(一个结果都没漏)」而「Precision低(判断很不准,都在误报)」。
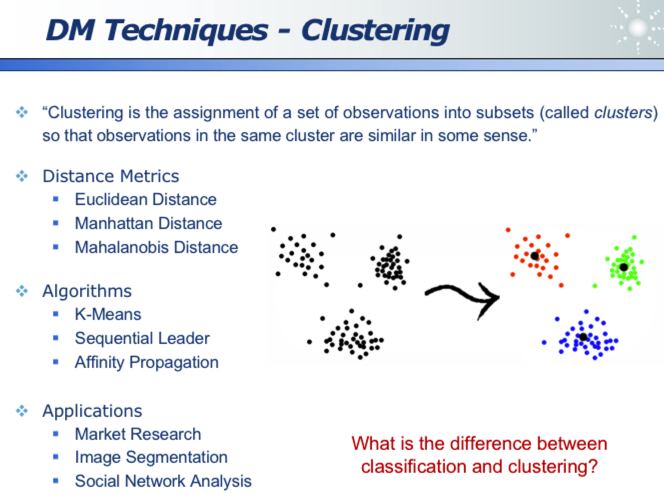
三、聚类
聚类不同于分类(并没有「事先人为定义的标签」,而是根据各点之间的「距离」度量的),其只是将一批数据集聚为不同的堆。
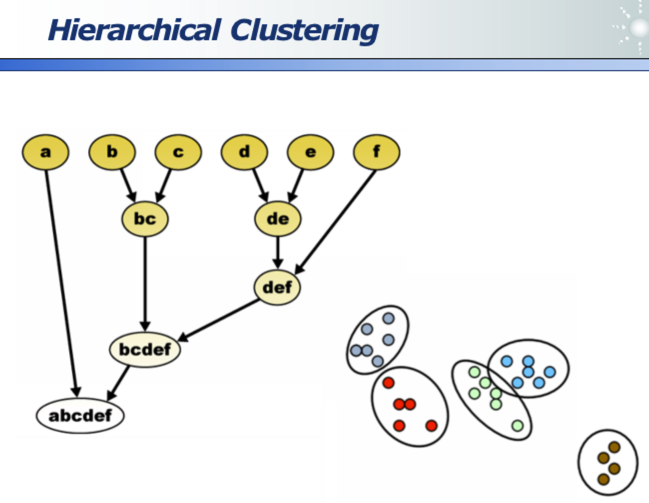
聚类分为平铺聚类和层次型聚类,如下图:
- 比如:都是中国人类,但又细分为南方人+北方人、其中北方人又分为东北、中原、西北人等。
四、关联分析
商店购买记录,分析各商品的关联性。

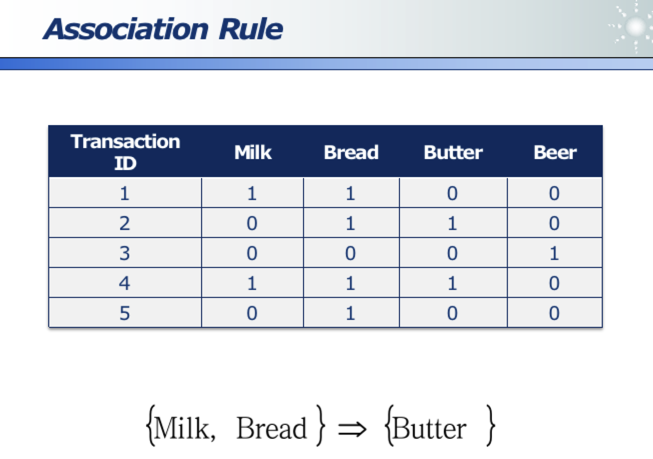
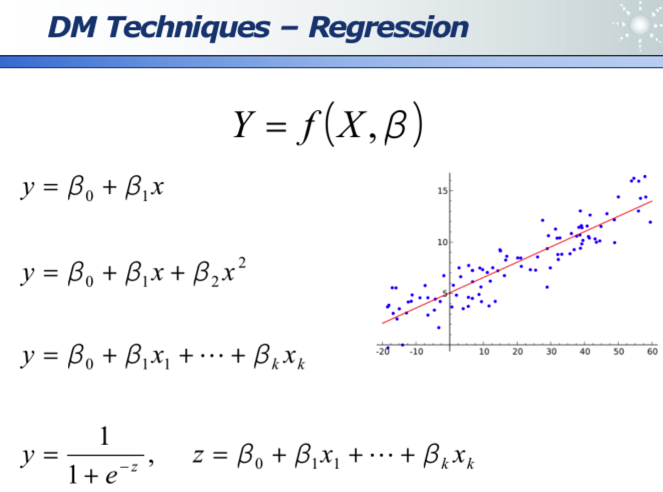
五、回归
线性回归:其实可以拟合出线性方程、二元方程、多项式方程等。其「线性」二字的含义是参数和自变量之间是线性关系(即下图中的 beta 和 x)
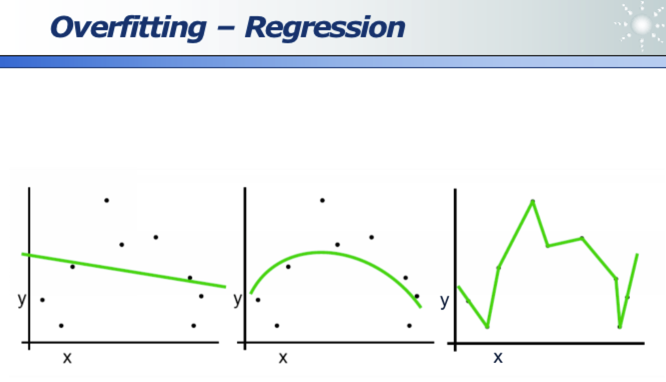
回归同样存在过拟合问题(下图一是欠拟合太简单了,下图三是过拟合死记硬背所有训练数据不具备扩展性,下图二是适中的也是最好的模型):
六、可视化
通过所见即所得,充分展示出数据,更容易发挥人的分析能力:拿到数据后,先做可视化大概估计数据分布,再确定详细挖掘算法。
同样数据挖掘后,再把结果可视化,让人为评判效果。来确定下一步挖掘方向。
可视化需要以受众易理解的语言、图表形式(如右下图的驾驶舱)进行:
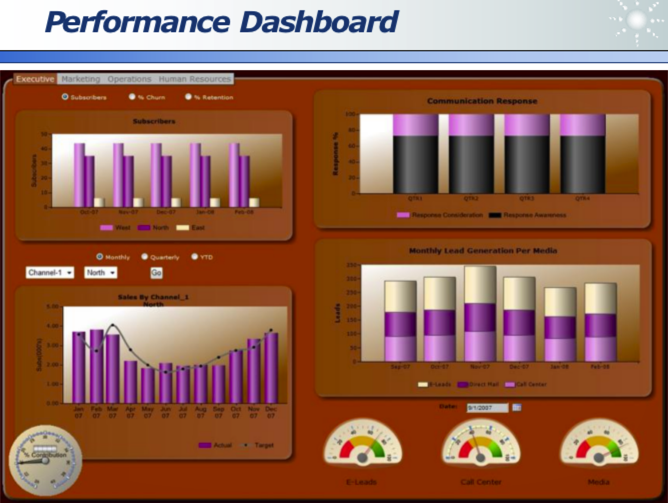
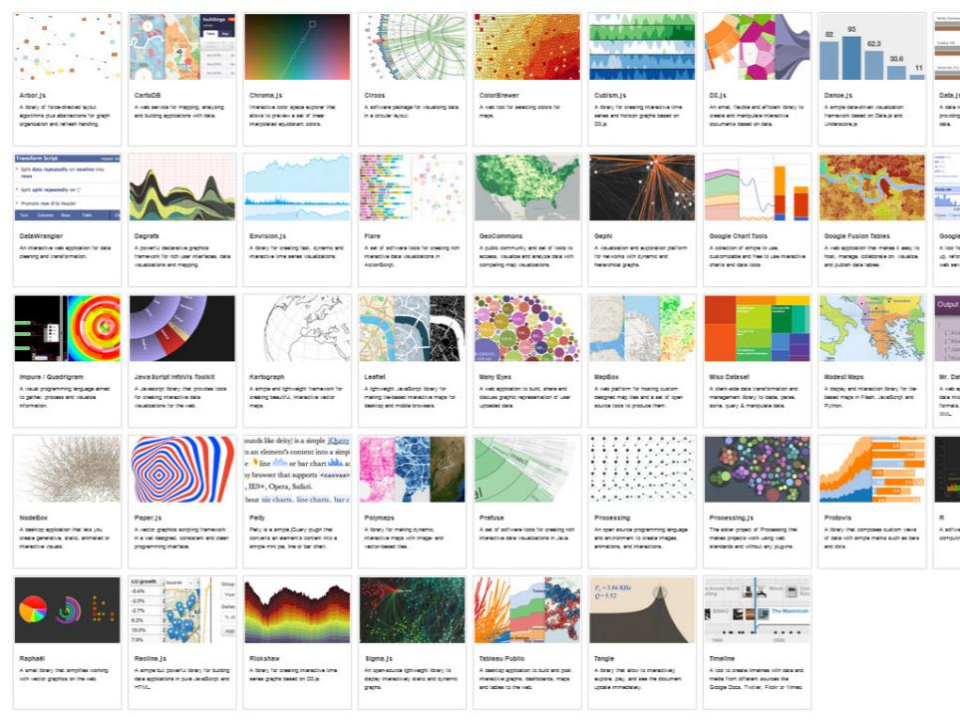
有很多图表,可以酷炫地展示结果,让人更易理解挖掘的价值。
七、数据预处理
我们拿到的通常是脏数据:其可能缺失(如未填写年龄)或错误(如年龄填写为负数),因此需要清洗

数据清洗通常很累,但缺必不可少的地基工作:

八、有趣的案例
8.1 隐私保护
1990 年互联网兴起时,隐私性很好,你并不知道互联网对面是谁在操作键盘。
但现在 21 世纪,隐私性已经完全没有了,所有的时间、空间、身份、行为习惯均被记录并分析。

基于隐私保护的数据挖掘,是目前很新兴的研究领域:即收集数据、又保护用户隐私。

下图即为有隐私保护的数据挖掘,让挖掘者并不知道个体的数据,但可以获得宏观的数据,且保证获得的数据是真实的:

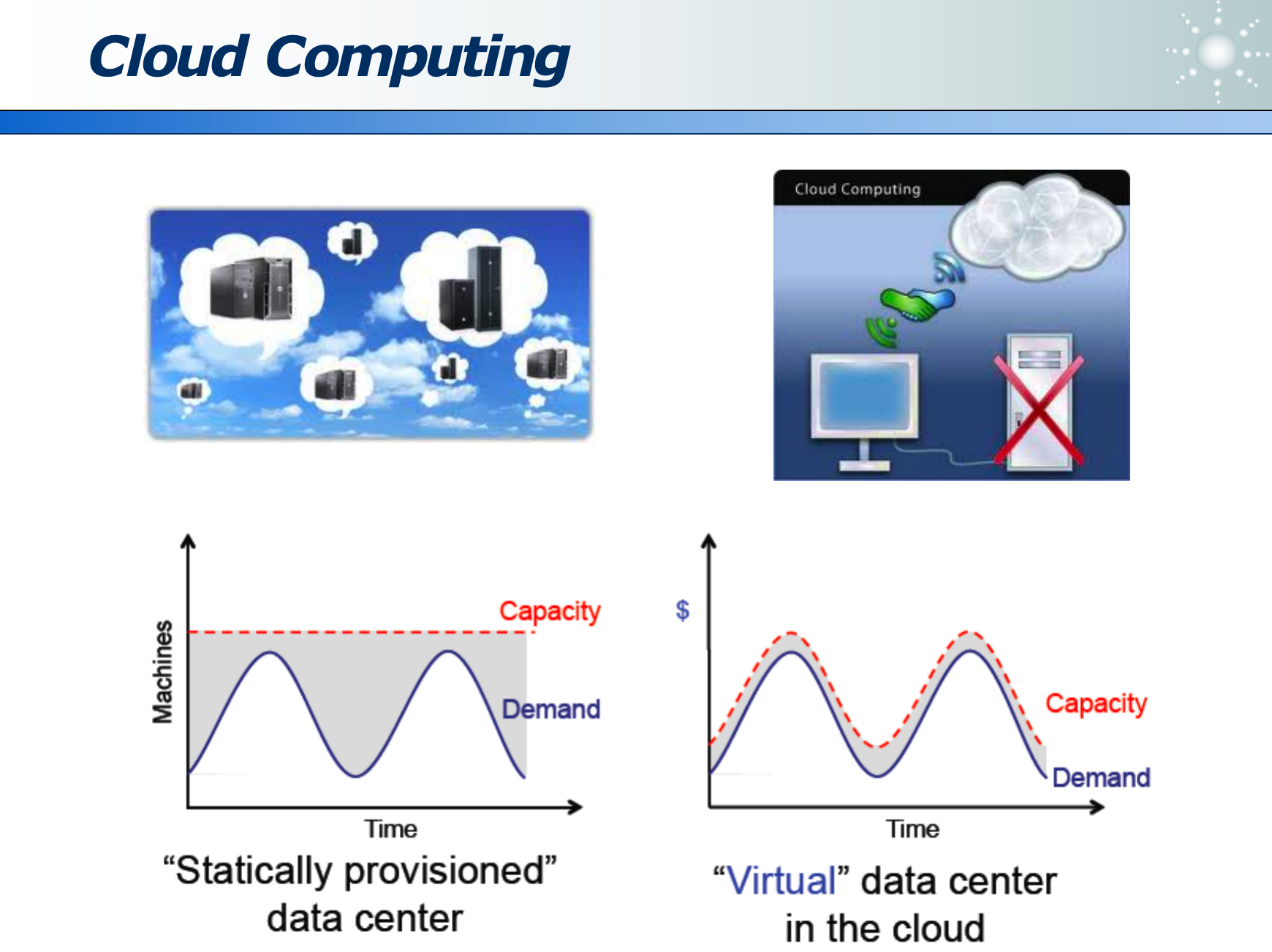
8.2 云计算的弹性资源
根据客户的实际需求,动态扩缩容资源。
8.3 并行计算
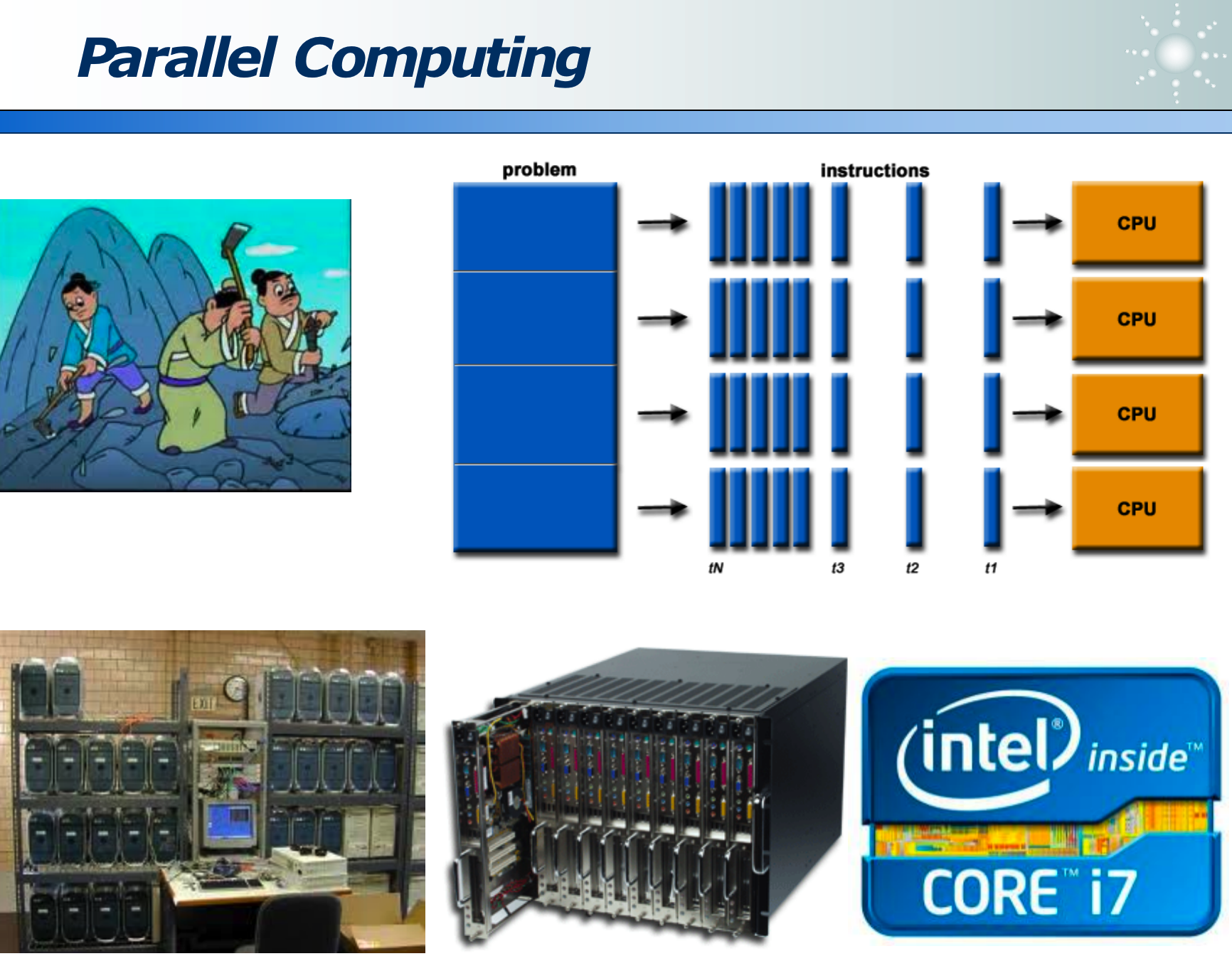


Nvidia 的 TK1 尺寸很小,但计算性能是家用电脑的 10 倍以上。


九、总结
数据挖掘的必备元素:数据、算法、算力

没有银弹算法、没有银弹参数:通常先用简单算法验证效果(降低心智负担),后期再用复杂算法优化。

不能总是宏观看待问题,也要结合微观,才能详细挖掘数据规律:
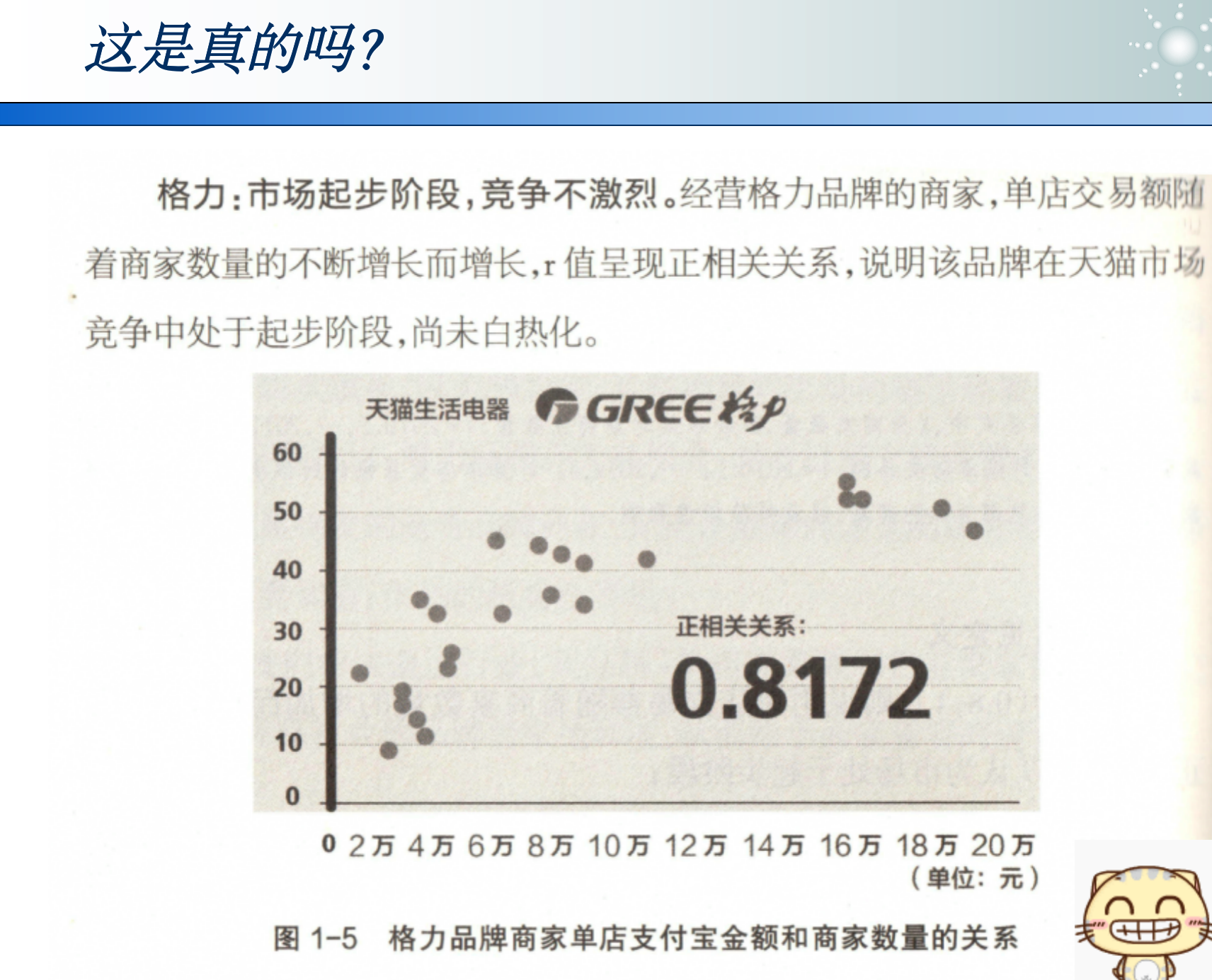
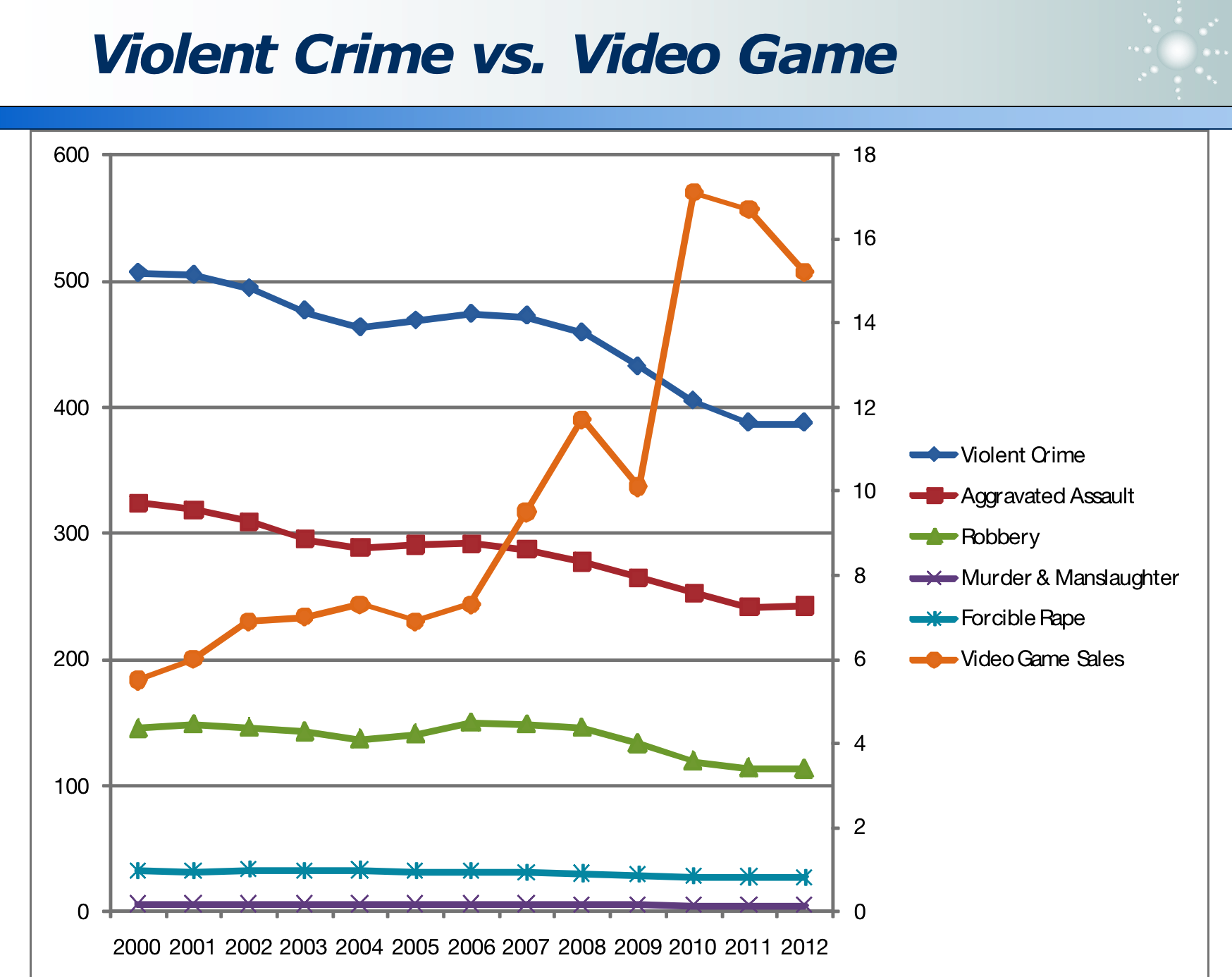
两条曲线有关系,但不一定有因果关系:
避免幸存者偏差,来误解数据:

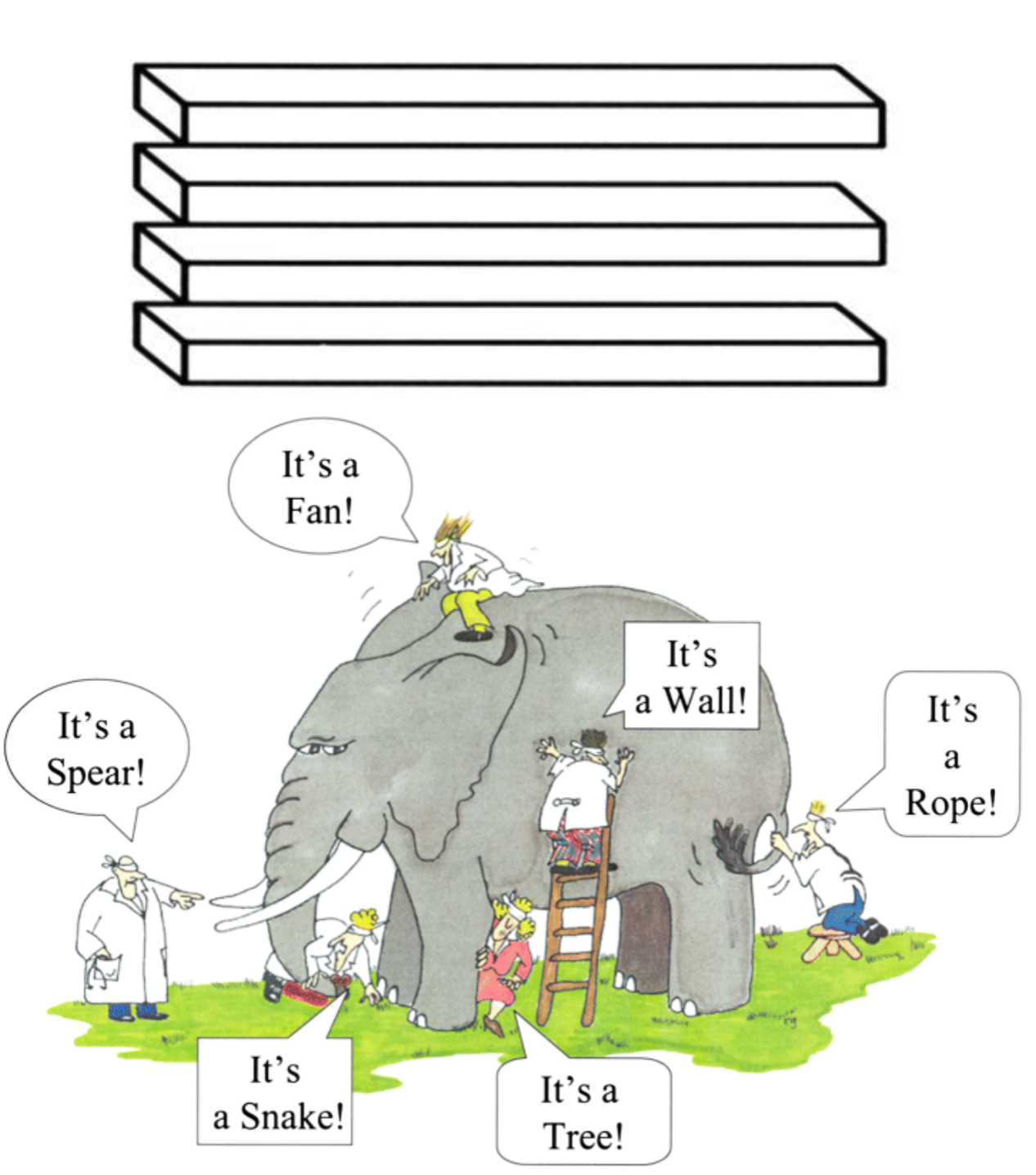
避免片面理解数据,避免以偏概全: