ChatGLM系列二:ChatGLM2的介绍及代码实践
一、介绍
2023年06月25日,清华大学开源了 ChatGLM2-6B 模型,是 ChatGLM 模型的升级版本。ChatGLM2-6B 在多个方面有显著提升:模型性能更强,在各种测试集上的表现更好;支持更长的上下文,最大上下文长度提升到 32k;推理速度提高42%,能支持更长的生成;开源许可更加开放,允许商业使用。ChatGLM2-6B在多个维度的能力上取得了巨大提升,包括数理逻辑、知识推理和长文档理解。
模型性能提升主要来自升级的基座模型、混合了 GLM 目标函数、使用 FlashAttention 和Multi-Query Attention 技术。它整合了最新技术,在推理速度、生成长度、知识涵盖等方面取得突破,使人机对话能力更强大。
ChatGLM2-6B(GitHub项目地址、HuggingFace地址)是开源中英双语对话模型 ,相比第一代,第二点引入了如下新特性:
-
数据集上
经过了 1.4T 中英标识符的预训练与人类偏好对齐训练
-
更长的上下文
基于 FlashAttention 技术,将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话
(当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,会在后续迭代升级中着重进行优化) -
更高效的推理
基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K
-
模型架构上变成了decoder only的架构
chatglm还是encoder架构,但是到了chatglm2 变成了decoder only的架构(这点很少有资料会提及到),何以见得呢?
chatglm2仓库的modeling用了新版pytorch的这个函数:context_layercontext_layer 这个函数实现了attention机制的计算,入参 is_causal=True 表示遮后看前的mask(这种类型的注意力通常用在transformer的decoder部分,以确保当前位置只能关注到之前的位置,俗称“看不见未来”,从而使模型可以进行自回归预测 )
-
允许商业使用
-
准确性不足
尽管模型在训练的各个阶段都尽力确保数据的合规性和准确性,但由于 ChatGLM2-6B 模型规模较小,且模型受概率随机性因素影响,无法保证输出内容的准确性,且模型易被误导
对比:ChatGLM-6B、ChatGLM2-6B
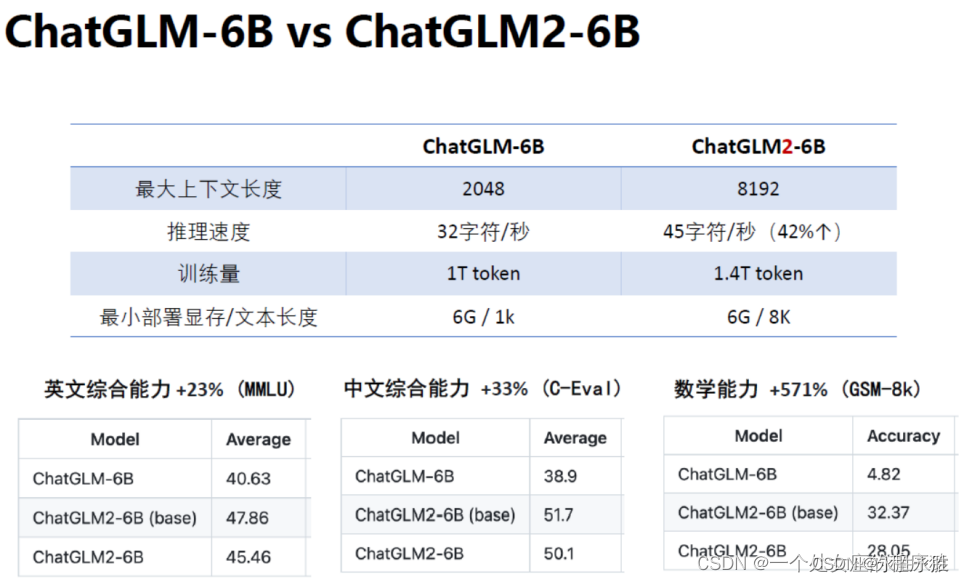
- 充分的中英双语预训练: ChatGLM2-6B 在 1:1 比例的中英语料上训练了 1.4T的token 量(*4倍≈5G的语料),兼具双语能力,相比于ChatGLM-6B初代模型,性能大幅提升。
- 较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到10GB(INT8)和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
- 更长的序列长度: 相比GLM-10B(序列长度1024), ChatGLM-6B序列长度达 2048,ChatGLM2-6B序列 长度达8192(≈1万多的文字),支持更长对话和应用。
- 人类意图对齐训练: 使用了监督微调、反馈自助、人类反馈强化学习等方式,使模型初具理解人类指令意图的能力。
二、模型部署
1、拉取代码
git clone https://github.com/THUDM/ChatGLM2-6Bcd ChatGLM2-6Bpip install -r requirements.txt
2、代码调用
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, device='cuda')
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
>>> response, history = model.chat(tokenizer, "请问钓鱼有什么技巧", history=history)
>>> print(response)
3、web部署
pip install gradio
python web_demo.py
#默认使用了 share=False 启动,不会生成公网链接。如有需要公网访问的需求,可以修改为 share=True 启动
#基于 Streamlit 的网页版 Demo web_demo2.py
pip install streamlit streamlit-chat
streamlit run web_demo2.py
4、命令行
python cli_demo.py
#程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序。
5、api部署
pip install fastapi uvicorn
python api.py
默认部署在本地的 8000 端口,通过 POST 方法进行调用
curl -X POST "http://127.0.0.1:8000" \-H 'Content-Type: application/json' \-d '{"prompt": "你好", "history": []}'
{"response":"你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。","history":[["你好","你好👋!我是人工智能助手 ChatGLM2-6B,很高兴见到你,欢迎问我任何问题。"]],"status":200,"time":"2023-03-23 21:38:40"
}