spark第一章:环境安装
系列文章目录
spark第一章:环境安装
文章目录
- 系列文章目录
- 前言
- 一、文件准备
- 1.文件上传
- 2.文件解压
- 3.修改配置
- 4.启动环境
- 二、历史服务器
- 1.修改配置
- 2.启动历史服务器
- 总结
前言
spark在大数据环境的重要程度就不必细说了,直接开始吧。
一、文件准备
1.文件上传
spark3.2.3官网下载地址。

本次学习spark使用稳定版3.2.3.
spark一般有3种部署模式。
Local一般用于测试。
Standalone用于学习
Yarn生产环境常用部署。
我们直接模拟生产环境。
2.文件解压
tar -xvf spark-3.3.2-bin-hadoop3.tgz -C /opt/module/
cd /opt/module/
mv spark-3.3.2-bin-hadoop3/ spark-yarn
3.修改配置
spark是基于hadoop允许的,所以我们要修改hadoop的配置文件。
vim /opt/module/hadoop-3.2.3/etc/hadoop/yarn-site.xml
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value>
</property><!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是 true -->
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>
将这个文件分发到集群
xsync hadoop-3.2.3/etc/hadoop/
修改spark的conf文件

mv spark-env.sh.template spark-env.sh
在最后边追加两行内容
export JAVA_HOME=/opt/module/jdk8u282-b08
YARN_CONF_DIR=/opt/module/hadoop-3.2.3/etc/hadoop

4.启动环境
先启动hadoop
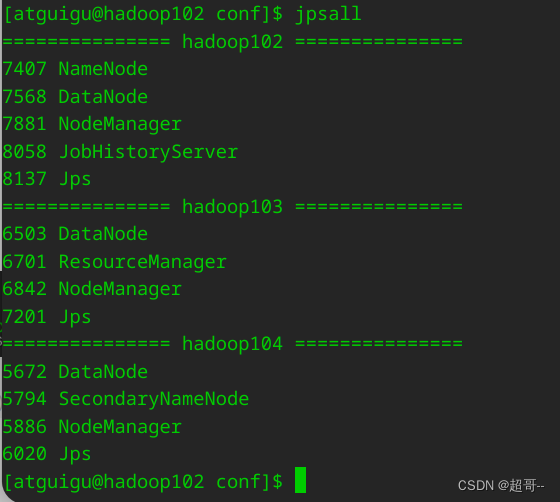
提交spark任务。
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster ./examples/jars/spark-examples_2.12-3.3.2.jar 10
在浏览器查看结果
hadoop103:8088
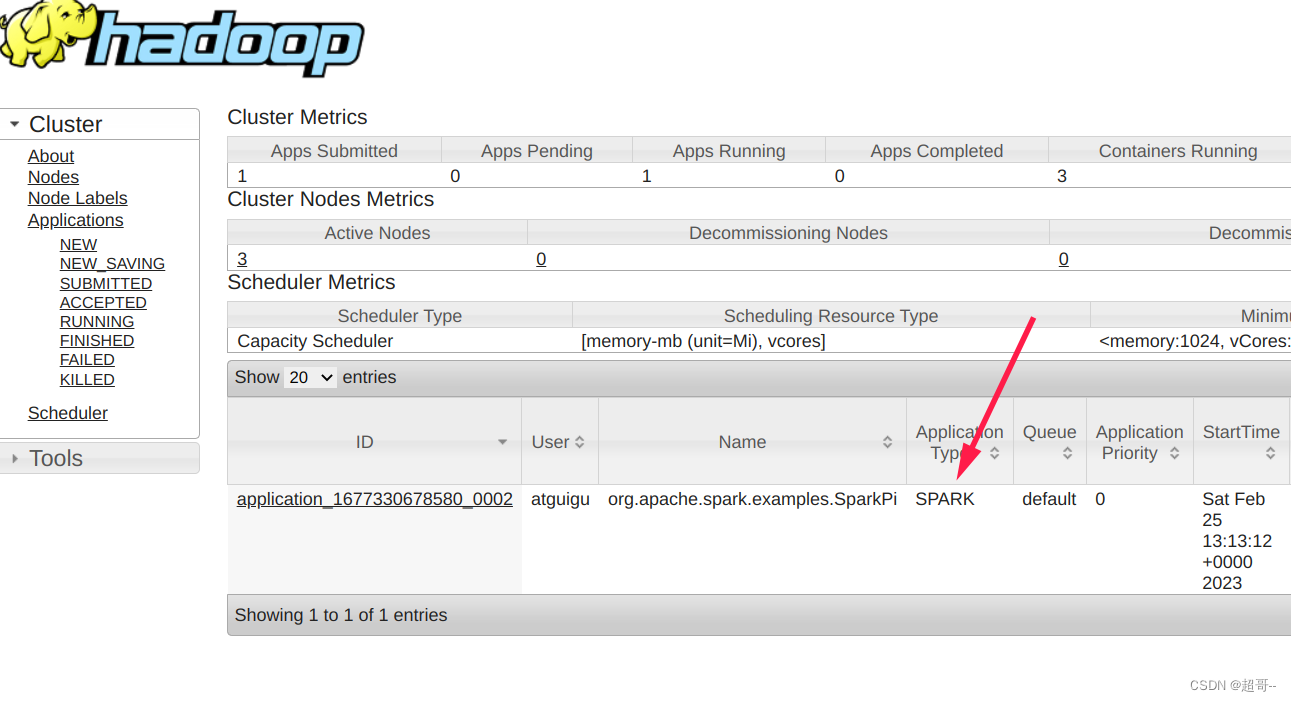
二、历史服务器
1.修改配置
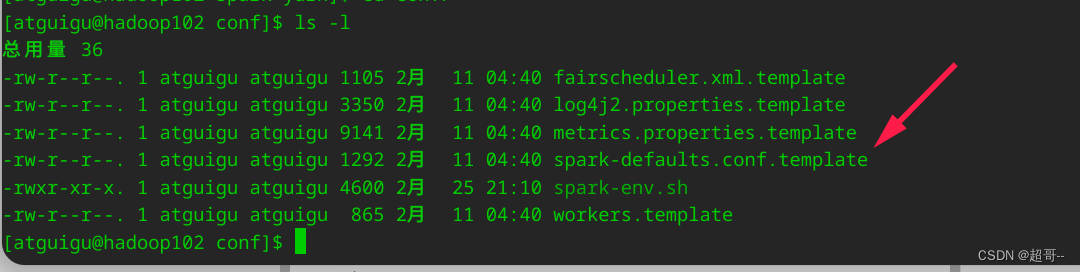
mv spark-defaults.conf.template spark-defaults.conf
在文件后边追加。
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/directory
在集群上创建需要的目录
hadoop fs -mkdir /directory
修改spark-env.sh
在后边追加如下内容
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory
-Dspark.history.retainedApplications=30"
修改 spark-defaults.conf
继续追加
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=18080
2.启动历史服务器
sbin/start-history-server.sh
再次提交应用
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client ./examples/jars/spark-examples_2.12-3.3.2.jar 10
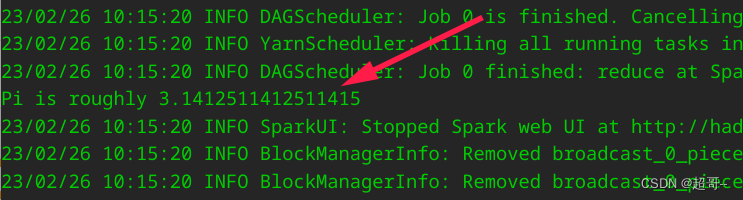
继续在hadoop103上查看结果。
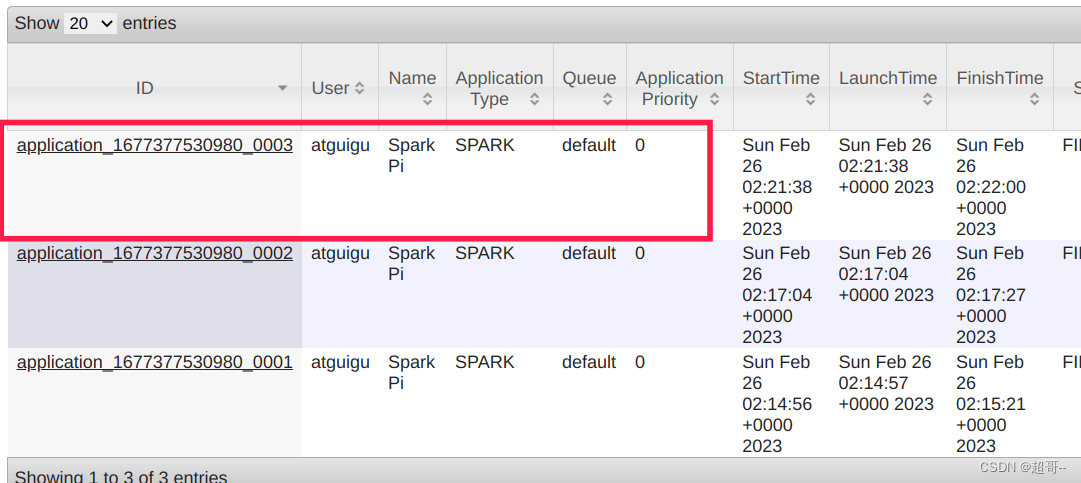
最后边点击history
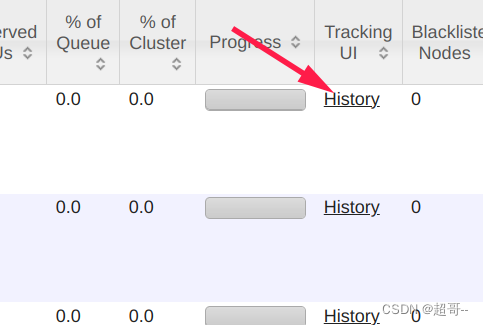
自动跳转到历史服务器。
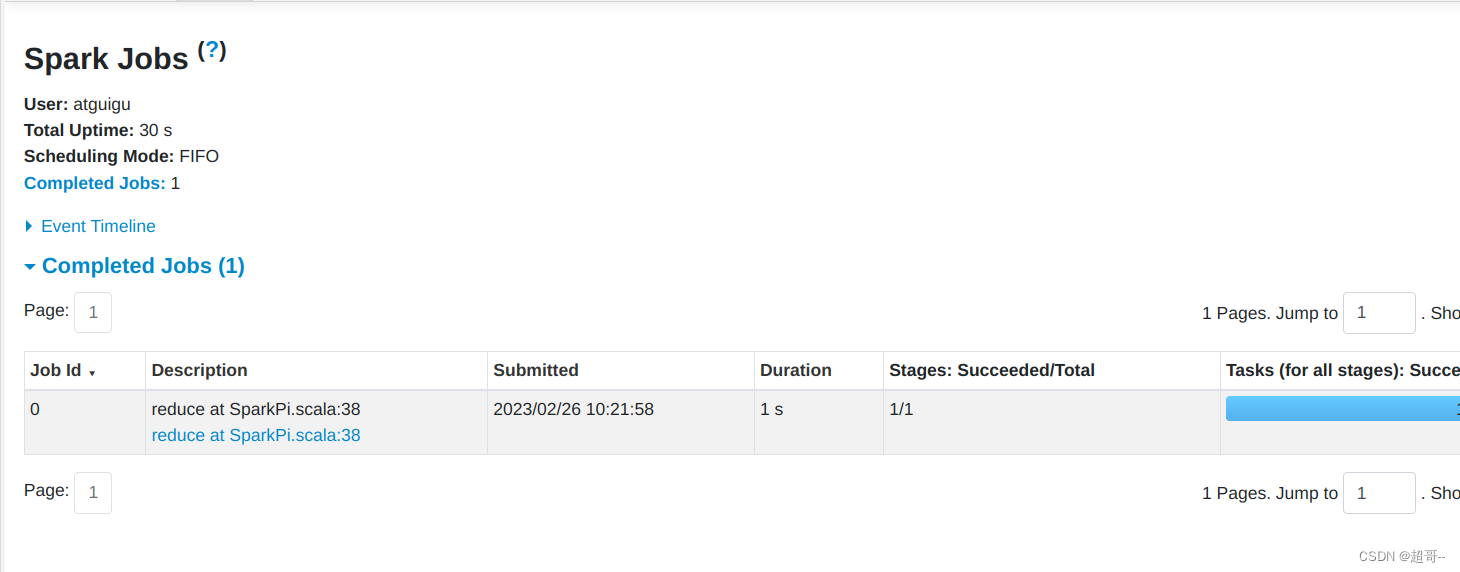
总结
spark第一章的环境搭建就到这里,现在可以将3个虚拟机保存快照。