【JDK8新特性之Stream流-Stream结果收集案例实操】
一.JDK8新特性之Stream流-Stream结果收集以及案例实操

二.Stream结果收集(collect函数)-实例实操
2.1 结果收集到集合中
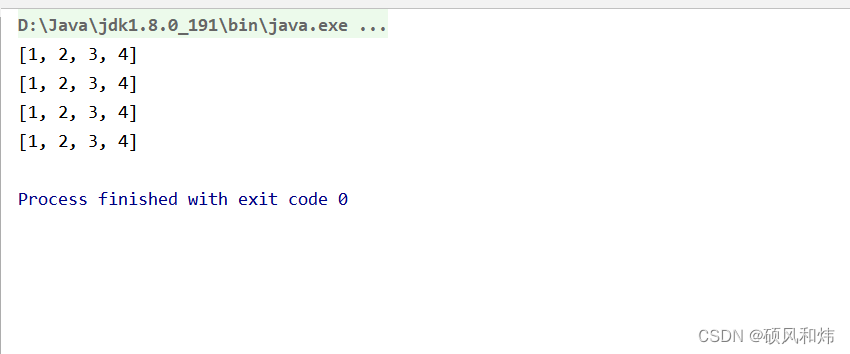
/*** Stream将结果收集到集合中以及具体的实现 collect*/@Testpublic void test01(){// 收集到List中 接口List<Integer> list = Stream.of(1, 2, 3,4).collect(Collectors.toList());System.out.println(list);// 收集到 Set集合中 接口Set<Integer> set = Stream.of(1, 2, 3,4).collect(Collectors.toSet());System.out.println(set);// 如果需要获取的类型为具体的实现,ArrayList HashSetArrayList<Integer> list1 = Stream.of(1, 2, 3,4)//.collect(Collectors.toCollection(() -> new ArrayList<>()));.collect(Collectors.toCollection(ArrayList::new));System.out.println(list1);//如果需要获取的类型为具体的实现,HashSetHashSet<Integer> set1 = Stream.of(1, 2, 3,4).collect(Collectors.toCollection(HashSet::new));System.out.println(set1);}
输出结果
2.2 结果收集到数组中
Stream中提供了toArray方法来将结果放到一个数组中,返回值类型是Object[],如果我们要指定返回的类型,那么可以使用另一个重载的toArray(IntFunction f)方法
/*** Stream结果收集到数组中*/@Testpublic void test02(){// 返回的数组中的元素是 Object类型Object[] objects = Stream.of("s1", "s2", "s3").toArray(); System.out.println(Arrays.toString(objects));// 如果我们需要指定返回的数组中的元素类型// 需要我们在toArray()方法中传入数组类型String[] strings = Stream.of("s1", "s2", "s3").toArray(String[]::new);System.out.println(Arrays.toString(strings));}
结果展示:

2.3 对流中的数据做聚合计算
当我们使用Stream流处理数据后,可以像数据库的聚合函数一样对某个字段进行操作,比如获得最大值,最小值,求和,平均值,统计数量。
/*** Stream流中数据的聚合计算(最大值、最小值、求和、求平均值、满足条件的结果个数)*/@Testpublic void test03(){// 获取员工薪资的最大值Optional<Person> maxSalary = Stream.of(new Person("Jack", 3445), new Person("Tom", 4324), new Person("Meisi", 14353), new Person("Coroergo", 13425)).collect(Collectors.maxBy((p1, p2) -> p1.getSalary() - p2.getSalary()));System.out.println("最多薪资:" + maxSalary.get());// 获取员工薪资的最小值Optional<Person> minSalary = Stream.of(new Person("Jack", 3445), new Person("Tom", 4324), new Person("Meisi", 14353), new Person("Coroergo", 13425)).collect(Collectors.minBy((p1, p2) -> p1.getSalary() - p2.getSalary()));System.out.println("最少薪资:" + minSalary.get());// 求所有人员工薪资之和Integer sumSalary = Stream.of(new Person("Jack", 3445), new Person("Tom", 4324), new Person("Meisi", 14353), new Person("Coroergo", 13425)).collect(Collectors.summingInt(Person::getSalary));System.out.println("薪资总和:" + sumSalary);// 员工薪资的平均值Double avgSalary = Stream.of(new Person("Jack", 3445), new Person("Tom", 4324), new Person("Meisi", 14353), new Person("Coroergo", 13425)).collect(Collectors.averagingInt(Person::getSalary));System.out.println("薪资的平均值:" + avgSalary);// 员工薪资统计数量Long count = Stream.of(new Person("Jack", 3445), new Person("Tom", 4324), new Person("Meisi", 14353), new Person("Coroergo", 13425)).filter(p->p.getSalary() > 4000).collect(Collectors.counting());System.out.println("满足条件的记录数:" + count);}
结果展示

2.4 对流中数据做分组操作
当我们使用Stream流处理数据后,可以根据某个属性将数据分组
/*** 分组计算:按照我们是收入进行分组,分组的高收入组和低收入组*/@Testpublic void test04(){Map<String, List<Person>> map = Stream.of(new Person("Jack", 3445), new Person("Tom", 4324), new Person("Meisi", 14353), new Person("Coroergo", 13425)).collect(Collectors.groupingBy(p -> p.getSalary() >= 4000 ? "高收入" : "低收入"));map.forEach((k,v)-> System.out.println("k=" + k +"\t"+ "v=" + v));}
输出结果:

多级分组: 先根据name分组然后根据年龄分组
/*** 分组计算--多级分组(先按照姓名分组,然后再按照年龄分组)*/@Testpublic void test05(){Map<String,Map<Object,List<Person>>> map = Stream.of(new Person("张三", 18, 175), new Person("李四", 22, 177), new Person("张三", 14, 165), new Person("李四", 15, 166), new Person("张三", 19, 182)).collect(Collectors.groupingBy(Person::getName,Collectors.groupingBy(p->p.getAge()>=18?"成年":"未成年")));map.forEach((k,v)->{System.out.println(k);v.forEach((k1,v1)->{System.out.println("\t"+k1 + "=" + v1);});});}
输出结果:

2.5 对流中的数据做分区操作
Collectors.partitioningBy会根据值是否为true,把集合中的数据分割为两个列表,一个true列表,一个false列表
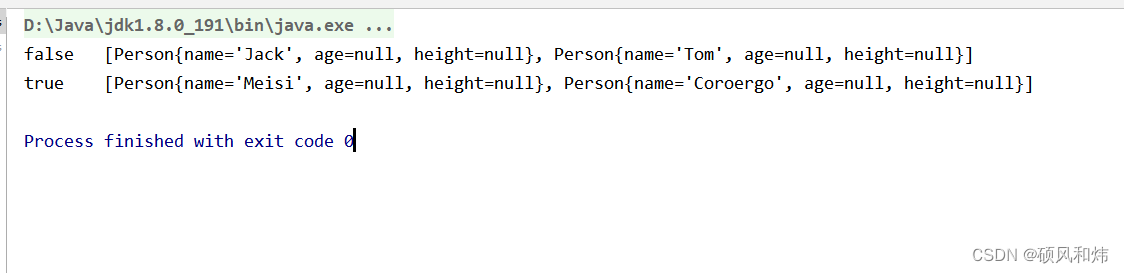
/*** 分区操作*/@Testpublic void test06(){Map<Boolean, List<Person>> map = Stream.of(new Person("Jack", 3445), new Person("Tom", 4324), new Person("Meisi", 14353), new Person("Coroergo", 13425)).collect(Collectors.partitioningBy(p -> p.getSalary() > 6000));map.forEach((k,v)-> System.out.println(k+"\t" + v));}
输出结果:
2.6 对流中的数据做拼接
Collectors.joining会根据指定的连接符,将所有的元素连接成一个字符串
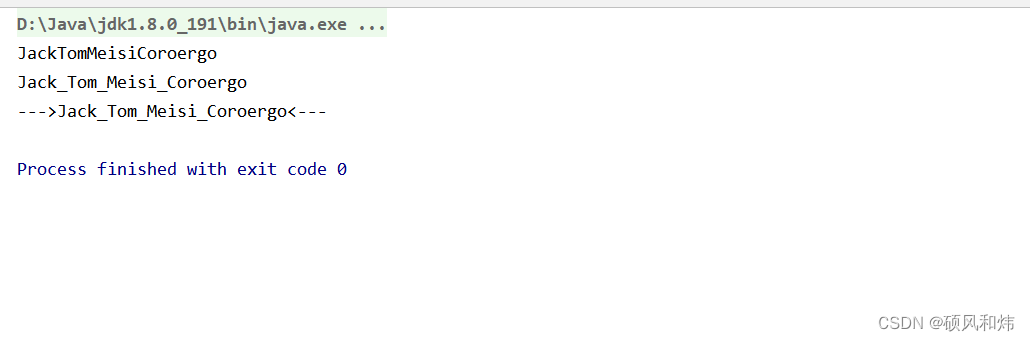
/*** 对流中的数据做拼接操作(对应着三种重载方法)*/@Testpublic void test07(){// 第一种拼接:直接拼接String s1 = Stream.of(new Person("Jack", 3445), new Person("Tom", 4324), new Person("Meisi", 14353), new Person("Coroergo", 13425)).map(Person::getName).collect(Collectors.joining());System.out.println(s1);// 第二种拼接:每个拼接中加"_"来进行连接String s2 = Stream.of(new Person("Jack", 3445), new Person("Tom", 4324), new Person("Meisi", 14353), new Person("Coroergo", 13425)).map(Person::getName).collect(Collectors.joining("_"));System.out.println(s2);// 第三种拼接:前后拼接加上"_",拼接的开始加上"--->",结束加上"<---"String s3 = Stream.of(new Person("Jack", 3445), new Person("Tom", 4324), new Person("Meisi", 14353), new Person("Coroergo", 13425)).map(Person::getName).collect(Collectors.joining("_", "--->", "<---"));System.out.println(s3);}
结果展示:
三.总结
人活着就在不停的做选择题,无论你做出了什么样的选择,我觉得都是你深思熟虑过后的答案,结果固然重要,但过程同样精彩,我是硕风和炜,我们下篇文章见哦!