java入坑之国际化编程
一、字符编码
1.1概述
字符编码
--字符:0,a,我,①,,…
--计算机只用0和1,1bit(0或者1)
--ASCIL码(American Standard Code for Information Interchange)
- ·美国信息交换标准代码,奠定计算机编码基础
- ·用一个字节(1Byte=8bits)来存储a-z,A-Z,0-9和一些常用符号
- ·用于显示英语及西欧语言
- ·回车键(13,00001101),0(48,00110000),A(65,01000001),a(97,01100001)

package org.example;import java.io.UnsupportedEncodingException;public class StringTest {public static void main(String[] args) throws UnsupportedEncodingException {String a = "我是中国人";String b = new String(a.getBytes("UTF-8"), "GBK");System.out.println(b);String c = new String(b.getBytes("GBK"), "UTF-8");System.out.println(c);}
}
1.2中文编码

字符集 包括哪些字符元素;
编码 每个字符元素用多少号码 (0和1的组合)来表示
1.3Unicode(字符集)
Unicode(字符集)
一目标:不断扩充,存储全世界所有的字符
·编码方案
- UTF-8,兼容ASCⅡ,变长(1-4个字节存储字符),经济,方便传输
- UTF-16,用变长(2-4个字节)来存储所有字符
- UTF-32,用32bits(4个字节)存储所有字符
写文件
package org.example;import java.io.*;public class Main {public static void main(String[] args) {writeFile1();}public static void writeFile1() {FileOutputStream fos = null;OutputStreamWriter osw = null;BufferedWriter bw = null;String charset = "UTF-8";try {fos = new FileOutputStream("c:/temp/abc.txt"); // 节点类osw = new OutputStreamWriter(fos, charset); // 转化类
//osw = new OutputStreamWriter(fos); // 转化类 采用操作系统默认编码bw = new BufferedWriter(osw); // 装饰类
// br = new BufferedWriter(new OutputStreamWriter(newFileOutputStream("c:/temp/abc.txt")))bw.write("我们是");bw.newLine();bw.write("Ecnuers.^^");bw.newLine();} catch (Exception ex) {ex.printStackTrace();} finally {try {bw.close();// 关闭最后一个类,会将所有的底层流都关闭} catch (Exception ex) {ex.printStackTrace();}}}
}读文件
package org.example;import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.InputStreamReader;public class Main {public static void main(String[] args) {readFile1();}public static void readFile1(){FileInputStream fis=null;InputStreamReader isr=null;BufferedReader br=null;String charset="UTF-8";try{fis=new FileInputStream("c:/temp/abc.txt"); // 节点类isr=new InputStreamReader(fis,charset); // 转化类
//isr = new InputStreamReader(fis); //采用操作系统默认编码br=new BufferedReader(isr); // 装饰类
// br = new BufferedReader(new InputStreamReader(newFileInputStream("c:/temp/abc.txt")))String line;while((line=br.readLine())!=null) // 每次读取一行{System.out.println(line);}}catch(Exception ex){ex.printStackTrace();}finally{try{br.close();// 关闭最后一个类,会将所有的底层流都关闭}catch(Exception ex){ex.printStackTrace();}}}
}1.4ANSI编码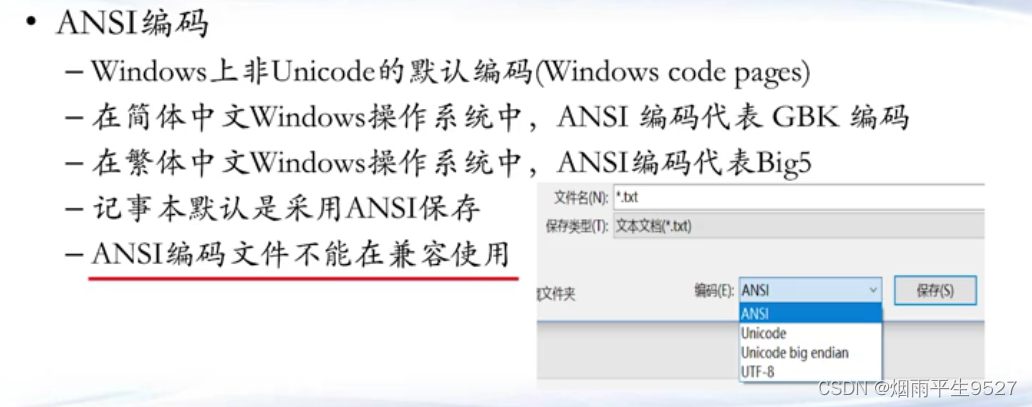
1.5Java的字符编码

package org.example;import java.nio.charset.Charset;
import java.util.Set;
import java.util.SortedMap;
public class Main {public static void main(String[] args) {
//默认字符集 GBKCharset c = Charset.defaultCharset();System.out.println(c.name());
//输出所有的支持字符集SortedMap<String, Charset> sm = Charset.availableCharsets();Set<String> keyset = sm.keySet();System.out.println("Java 支持的所有字符集");for (String s : keyset) {System.out.println(s);}}
}java charset类是一个用于表示字符编码集的类,它可以用于将字符序列和字节序列之间进行转换和处理。字符编码集是一种将字符和数字之间进行映射的规则,例如ASCII、UTF-8、GBK等。不同的字符编码集可能支持不同的字符集合,因此在不同的编码之间转换时可能会出现乱码或丢失信息的情况。java charset类提供了一些方法和工具,用于检测、创建和管理不同的字符编码集
java charset类的主要方法有:
- static Charset forName(String charsetName):根据给定的字符编码集名称,返回一个Charset对象,如果不存在或不支持该名称,则抛出异常。
- static Charset defaultCharset():返回当前Java虚拟机的默认字符编码集,它通常取决于底层操作系统的语言环境和字符编码。
- static SortedMap<String,Charset> availableCharsets():返回一个包含当前Java虚拟机支持的所有字符编码集的映射,其中键是规范名称,值是Charset对象。
- String name():返回该字符编码集的规范名称。
- Set<String> aliases():返回该字符编码集的别名集合,别名是除了规范名称之外的其他有效名称。
- boolean isRegistered():返回该字符编码集是否在IANA Charset Registry中注册,如果没有注册,则其规范名称必须以"X-"或"x-"开头。
- boolean canEncode():返回该字符编码集是否可以对任意Unicode字符进行编码12。
- boolean contains(Charset cs):返回该字符编码集是否包含给定的字符编码集,即该字符编码集可以表示给定字符编码集中的所有字符。
- CharsetEncoder newEncoder():返回一个新的CharsetEncoder对象,用于将字符序列转换为字节序列。
- CharsetDecoder newDecoder():返回一个新的CharsetDecoder对象,用于将字节序列转换为字符序列
package org.example;import java.nio.charset.Charset;
import java.nio.charset.CharsetEncoder;
import java.nio.charset.CharsetDecoder;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;public class CharsetDemo {public static void main(String[] args) throws Exception {// 获取默认字符编码集Charset cs = Charset.defaultCharset();System.out.println("默认字符编码集:" + cs.name());// 获取UTF-8字符编码集cs = Charset.forName("UTF-8");System.out.println("UTF-8字符编码集:" + cs.name());// 创建一个UTF-8编码器CharsetEncoder encoder = cs.newEncoder();// 创建一个UTF-8解码器CharsetDecoder decoder = cs.newDecoder();// 定义一个要转换的字符串String str = "你好,世界!";// 将字符串转换为字节缓冲区ByteBuffer bb = encoder.encode(CharBuffer.wrap(str));System.out.println("转换后的字节缓冲区:" + bb);// 将字节缓冲区转换为字符串CharBuffer cb = decoder.decode(bb);System.out.println("转换后的字符串:" + cb);}
}
二、国际化编程

 2.1格式化相关类
2.1格式化相关类

数字格式化
import java.text.DecimalFormat;public class DecimalFormaterRuleTest {public static void main(String[] args) {DecimalFormat df1, df2;System.out.println("整数部分为0的情况,0/#的区别");// 整数部分为0 ,#认为整数不存在,可不写; 0认为没有,但至少写一位,写0df1 = new DecimalFormat("#.00");df2 = new DecimalFormat("0.00");System.out.println(df1.format(0.1)); // 0.10System.out.println(df2.format(0.1)); // 0.10System.out.println("小数部分0/#的区别");// # 代表最多有几位,0代表必须有且只能有几位df1 = new DecimalFormat("0.00");df2 = new DecimalFormat("0.##");System.out.println(df1.format(0.1)); // 0.10System.out.println(df2.format(0.1)); // 0.1System.out.println(df1.format(0.006)); // 0.01System.out.println(df2.format(0.006)); // 0.01System.out.println("整数部分有多位");// 0和#对整数部分多位时的处理是一致的 就是有几位写多少位df1 = new DecimalFormat("0.00");df2 = new DecimalFormat("#.00");System.out.println(df1.format(2)); // 2.00System.out.println(df2.format(2)); // 2.00System.out.println(df1.format(20)); // 20.00System.out.println(df2.format(20)); // 20.00System.out.println(df1.format(200)); // 200.00System.out.println(df2.format(200)); // 200.00}
}
package org.example;import java.text.DecimalFormat;public class DecimalFormatTest {public static void main(String[] args) {DecimalFormat df1 = new DecimalFormat("0.0");DecimalFormat df2 = new DecimalFormat("#.#");DecimalFormat df3 = new DecimalFormat("000.000");DecimalFormat df4 = new DecimalFormat("###.###");System.out.println(df1.format(12.34)); // 12.3System.out.println(df2.format(12.34)); // 12.3System.out.println(df3.format(12.34)); // 012.340System.out.println(df4.format(12.34)); // 12.34DecimalFormat df5 = new DecimalFormat("0.00");// 保留2位小数double d1 = 123456789.123456789;double d2 = 987654321.987654321;System.out.println("format1 d1=" + df5.format(d1));// 输出: format1 d1=123456789.12System.out.println("format1 d2=" + df5.format(d2));// 输出: format1 d2=987654321.99DecimalFormat df6 = new DecimalFormat("#,##0.00");System.out.println("format2 d1=" + df6.format(d1));// 输出: format2 d1=123,456,789.12System.out.println("format2 d2=" + df6.format(d2));// 输出: format2 d2=987,654,321.99}
}
字符串格式化
package org.example;import java.text.MessageFormat;public class MessageFormatTest {public static void main(String[] args) {String message = "{0}{1}{2}{3}{4}";Object[] array = new Object[]{"A","B","C","D","E"};String value = MessageFormat.format(message, array);System.out.println(value);message = "oh, {0,number,#.##} is a good number";array = new Object[]{new Double(3.1415)};value = MessageFormat.format(message, array);System.out.println(value);}
}
时间格式化
package org.example;import java.text.SimpleDateFormat;
import java.util.Date;public class SimpleDateTest {public static void main(String[] args) {String strDate = "2008-10-19 10:11:30.345";// 准备第一个模板,从字符串中提取出日期数字// 将毫秒部分改为大写的SString pat1 = "yyyy-MM-dd HH:mm:ss.SSS"; //修正了大小写// 准备第二个模板,将提取后的日期数字变为指定的格式String pat2 = "yyyy年MM月dd日HH时mm分ss秒SSS毫秒";SimpleDateFormat sdf1 = new SimpleDateFormat(pat1); // 实例化模板对象SimpleDateFormat sdf2 = new SimpleDateFormat(pat2); // 实例化模板对象Date d = null;try {d = sdf1.parse(strDate); // 将给定的字符串中的日期提取出来} catch (Exception e) { // 如果提供的字符串格式有错误,则进行异常处理e.printStackTrace(); // 打印异常信息}System.out.println(sdf2.format(d)); // 将日期变为新的格式}
}
package org.example;import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;public class DateFormatterTest {public static void main(String[] args) {//将字符串转化为时间String dateStr= "2016年10月25日";DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy年MM月dd日");LocalDate date= LocalDate.parse(dateStr, formatter);System.out.println(date.getYear() + "-" + date.getMonthValue() + "-" + date.getDayOfMonth());System.out.println("==========================");//将日期转换为字符串输出LocalDateTime now = LocalDateTime.now();DateTimeFormatter format = DateTimeFormatter.ofPattern("yyyy年MM月dd日HH:mm:ss");String nowStr = now.format(format);System.out.println(nowStr);}
}
2.2Locale类

package org.example;import java.util.Locale;
import java.text.DateFormat;
import java.util.Date;public class LocaleDemo {public static void main(String[] args) {// 创建一个中文简体的语言环境Locale cn = Locale.SIMPLIFIED_CHINESE;// 创建一个英文美国的语言环境Locale us = Locale.GERMAN;// 获取当前日期Date date = new Date();// 创建一个日期格式化器DateFormat df = DateFormat.getDateInstance(DateFormat.FULL, cn);// 使用不同的语言环境格式化日期System.out.println("中文简体:" + df.format(date));df = DateFormat.getDateInstance(DateFormat.FULL, us);System.out.println("英文美国:" + df.format(date));}
}
java Locale类的主要方法有:
- static Locale getDefault():返回当前Java虚拟机的默认语言环境,它通常取决于底层操作系统的设置。
- static Locale forLanguageTag(String languageTag):根据给定的语言标签,返回一个Locale对象,如果语言标签无效或不支持,则返回一个空的Locale对象。
- static String toLanguageTag():返回该Locale对象对应的语言标签,如果该Locale对象为空,则返回空字符串。
- String getLanguage():返回该Locale对象的语言代码,如果该Locale对象为空,则返回空字符串。
- String getCountry():返回该Locale对象的国家或地区代码,如果该Locale对象为空,则返回空字符串。
- String getScript():返回该Locale对象的脚本代码,如果该Locale对象为空或没有指定脚本,则返回空字符串。
- String getVariant():返回该Locale对象的变体代码,如果该Locale对象为空或没有指定变体,则返回空字符串。
- String getDisplayName():返回该Locale对象的显示名称,根据默认语言环境进行本地化,如果该Locale对象为空,则返回空字符串
2.3 ResourceBundle类
java ResourceBundle类是一个用于表示特定的地理、政治和文化地区的类。每一个ResourceBundle对象都代表了一个语言环境,可以用于执行一些与区域相关的操作,例如格式化日期、时间、数字、货币等。java ResourceBundle类还支持IETF BCP 47标准,可以使用语言标签来表示不同的语言和地区
package org.example;import java.util.Locale;
import java.util.ResourceBundle;public class ResourceBundleDemo {public static void main(String[] args) {// 创建一个英文美国的语言环境Locale us = new Locale("en", "US");// 创建一个中文简体的语言环境Locale jp = new Locale("ja", "JP");// 根据基本名称和语言环境获取ResourceBundle对象ResourceBundle bundleUS = ResourceBundle.getBundle("Message", us);ResourceBundle bundleCN = ResourceBundle.getBundle("Message", jp);// 获取不同语言环境下的消息System.out.println("message from Message_en_US.properties: " + bundleUS.getString("message"));System.out.println("message from Message_ja_JP.properties: " + bundleCN.getString("message"));}
}
语言文件

Message_en_US.properties
message=Hello!
Message_ja_JP.properties
message=こんにちは!

三、正则表达式


3.1Pattern类
java Pattern类是一个用于表示正则表达式的编译表示形式的类,它可以用于对字符串进行匹配和处理。正则表达式是一种定义字符串模式的规则,可以用于搜索、编辑或验证文本。java Pattern类支持Perl风格的正则表达式语法,也支持Unicode字符集
package org.example;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class MatcherDemo {public static void main(String[] args) {// 检查字符串里面有多少个dogString REGEX = "dog";String INPUT = "I have a dog, and my friend has a dog too.";Pattern p = Pattern.compile(REGEX);Matcher m = p.matcher(INPUT);int count = 0;while (m.find()) {count++;System.out.println("Match number: " + count);System.out.println("start(): " + m.start());System.out.println("end(): " + m.end());}System.out.println(count);}
}
3.2 Matcher类
java Matcher类是一个用于执行正则表达式匹配操作的类,它实现了MatchResult接口,可以对一个字符序列按照一个Pattern对象进行解释和处理。要使用java Matcher类,需要先调用Pattern类的静态方法compile,将一个正则表达式字符串编译为一个Pattern对象,然后调用Pattern对象的matcher方法,创建一个Matcher对象,用于对输入字符串进行匹配操作
Matcher对象提供了一些方法,用于检查匹配结果和获取匹配信息,例如:
- boolean matches():判断整个输入字符串是否与正则表达式完全匹配。
- boolean find():判断输入字符串中是否存在与正则表达式匹配的子序列。
- boolean find(int start):从指定位置开始,判断输入字符串中是否存在与正则表达式匹配的子序列。
- String group():返回与正则表达式匹配的子序列。
- String group(int group):返回与正则表达式中指定分组匹配的子序列。
- int groupCount():返回正则表达式中分组的数量。
- int start():返回与正则表达式匹配的子序列在输入字符串中的起始位置。
- int start(int group):返回与正则表达式中指定分组匹配的子序列在输入字符串中的起始位置。
- int end():返回与正则表达式匹配的子序列在输入字符串中的结束位置(不包含)。
- int end(int group):返回与正则表达式中指定分组匹配的子序列在输入字符串中的结束位置(不包含)
package org.example;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class MatchesLooking {private static final String REGEX = "foo";private static final String INPUT = "foooo";private static Pattern pattern;private static Matcher matcher;public static void main(String[] args) {// Initializepattern = Pattern.compile(REGEX);matcher = pattern.matcher(INPUT);System.out.println("Current REGEX is: " + REGEX);System.out.println("Current INPUT is: " + INPUT);System.out.println("lookingAt(): " + matcher.lookingAt()); //部分匹配System.out.println("matches(): " + matcher.matches()); //完全匹配}
}
3.3综合
Matcher对象还提供了一些方法,用于对输入字符串进行替换和追加操作,例如:
- Matcher appendReplacement(StringBuffer sb, String replacement):将与正则表达式匹配的子序列替换为给定的字符串,并将结果追加到一个StringBuffer对象中。
- StringBuffer appendTail(StringBuffer sb):将最后一次匹配操作后剩余的输入字符串追加到一个StringBuffer对象中。
- String replaceAll(String replacement):将所有与正则表达式匹配的子序列替换为给定的字符串,并返回替换后的新字符串。
- String replaceFirst(String replacement):将第一个与正则表达式匹配的子序列替换为给定的字符串,并返回替换后的新字符串
替换
package org.example; //声明包名import java.util.regex.Matcher; //导入Matcher类
import java.util.regex.Pattern; //导入Pattern类public class RegexDemo { //定义公共类private static String REGEX = "a*b"; //*表示限定前面的a可以有0或者多个。private static String INPUT = "aabfooaabfooabfoobcdd";private static String REPLACE = "-";public static void main(String[] args) { Pattern p = Pattern.compile(REGEX); //将正则表达式字符串编译为Pattern对象Matcher m = p.matcher(INPUT); //创建Matcher对象,用于对输入字符串进行匹配操作StringBuffer sb = new StringBuffer(); //创建StringBuffer对象,用于存储替换后的字符串//全部替换while(m.find()){ //循环查找与正则表达式匹配的子序列m.appendReplacement(sb,REPLACE); //将匹配的子序列替换为指定的字符串,并追加到StringBuffer对象中}//将最后的尾巴字符串附加上m.appendTail(sb); //将最后一次匹配操作后剩余的输入字符串追加到StringBuffer对象中System.out.println(sb.toString()); //输出替换后的字符串}
}
package org.example; //声明包名import java.util.regex.Matcher; //导入Matcher类
import java.util.regex.Pattern; //导入Pattern类public class ReplaceDemo2 {private static String REGEX = "a*b"; //*表示限定前面的a可以有0或者多个。private static String INPUT ="aabfooaabfooabfoob";private static String REPLACE = "-";public static void main(String[] args) {Pattern p = Pattern.compile(REGEX);// get a matcher objectMatcher m = p.matcher(INPUT);// 使用replaceAll方法替换所有匹配的子序列,并赋值给一个新的字符串变量String output = m.replaceAll(REPLACE); //修正了赋值// 输出新的字符串变量System.out.println(output); //修正了输出}
}
邮箱的判定
package org.example;import java.util.regex.Matcher;
import java.util.regex.Pattern;public class RegexTest {public static void main(String[] args) {regularExpression();}public static void regularExpression() {String REGEX_EMAIL = "^\\w+([-+.']\\w+)*@\\w+([-.]\\w+)*\\.\\w+([-.]\\w+)*$";String[] emails = new String[]{"123^@qq.com", "name_321@163.com", "+whatever*72@gmail.com"};Pattern pattern = Pattern.compile(REGEX_EMAIL);for (String email : emails) {Matcher matcher = pattern.matcher(email);if (matcher.matches()) {System.out.println(email + " is a valid email.");} else {System.out.println(email + " is not a valid email.");}}}
}