Kafka客户端核心参数详解
这一部分主要是从客户端使用的角度来理解 Kakfa 的重要机制。重点依然是要建立自己脑海中的 Kafka 消费模型。Kafka 的 HighLevel API 使用是非常简单的,所以梳理模型时也要尽量简单化,主线清晰,细节慢慢扩展。

一、从基础的客户端说起
Kafka 提供了非常简单的客户端 API 。只需要引入一个 Maven 依赖即可:

1 、消息发送者主流程
然后可以使用 Kafka 提供的 Producer 类,快速发送消息。

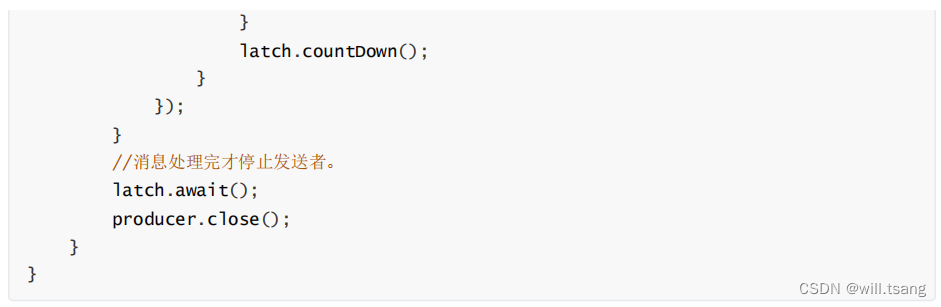
整体来说,构建 Producer 分为三个步骤:
1. 设置 Producer 核心属性 : Producer 可选的属性都可以由 ProducerConfig 类管理。比如
ProducerConfig.BOOTSTRAP_SERVERS_CONFIG 属性,显然就是指发送者要将消息发到哪个 Kafka 集群上。这是每个Producer 必选的属性。在 ProducerConfig 中,对于大部分比较重要的属性,都配置了对应的DOC 属性进行描述。
2. 构建消息 : Kafka 的消息是一个 Key-Value 结构的消息。其中, key 和 value 都可以是任意对象类型。其中,key 主要是用来进行 Partition 分区的,业务上更关心的是 value 。
3. 使用 Producer 发送消息。 :通常用到的就是单向发送、同步发送和异步发送者三种发送方式。
2 、消息消费者主流程
接下来可以使用 Kafka 提供的 Consumer 类,快速消费消息。

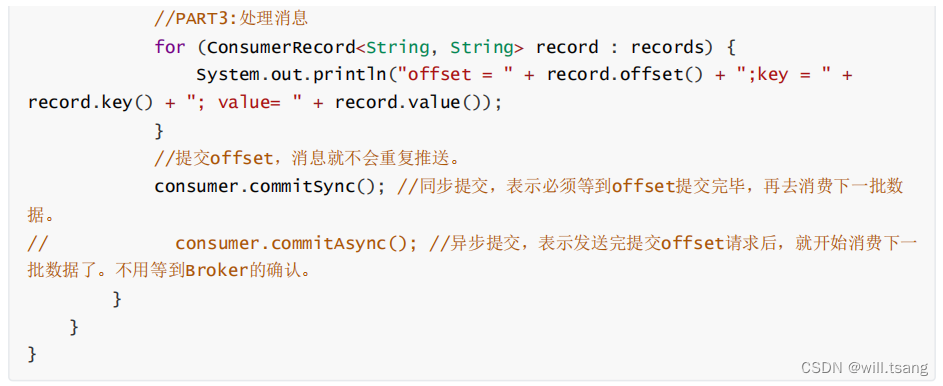
整体来说, Consumer 同样是分为三个步骤:
1. 设置 Consumer 核心属性 :可选的属性都可以由 ConsumerConfig 类管理。在这个类中,同样对于大部分比较重要的属性,都配置了对应的DOC 属性进行描述。同样 BOOTSTRAP_SERVERS_CONFIG 是必须设置的属性。
2. 拉取消息 : Kafka 采用 Consumer 主动拉取消息的 Pull 模式。 consumer 主动从 Broker 上拉取一批感兴趣的消息。
3. 处理消息,提交位点 :消费者将消息拉取完成后,就可以交由业务自行处理对应的这一批消息了。只是消费者需要向Broker 提交偏移量 offset 。如果不提交 Offset , Broker 会认为消费者端消息处理失败了,还会重复进行推送。
Kafka 的客户端基本就是固定的按照这三个大的步骤运行。在具体使用过程中,最大的变数基本上就是给生产者和消费者的设定合适的属性。这些属性极大的影响了客户端程序的执行方式。