[Flink]部署模式(看pdf上的放上面)
运行一个wordcount
val dataStream: DataStream[String] = environment.socketTextStream("hadoop1", 7777)
//流式数据不能进行groupBy,流式数据要来一条处理一次.0表示第一个元素,1表示第二个元素
//keyBy(0)根据第一个元素进行分组
val out: DataStream[(String, Int)] = dataStream.flatMap(line => line.split("\\s+")).map(word => (word, 1)).keyBy(0).sum(1)
out.print()一、StandAlone部署模式
并行度
1)设置并行度为1:
wordcount一共有两个任务(可以看到任务大概是由shuffle划分的)。在第一个job中,3个操作连在一起,是一个操作器链。
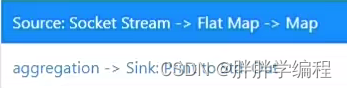
当并行度为1时,个Task的subTask只有一个,只占用了一个slot。

2)设置并行度为2。
此时有3个Task。占用了2个slot。第一个Task的subTask个数为1(这个是读数据的只有一个nc),其他的两个Task,subTask的个数为2.

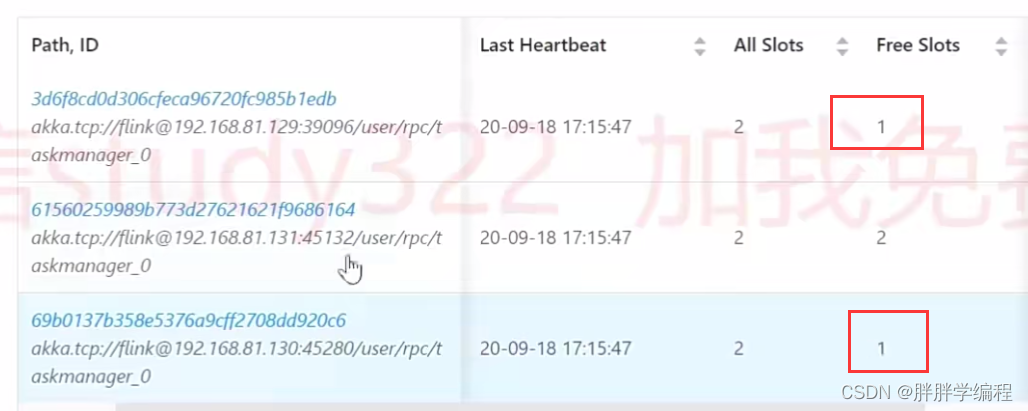

仅看第2个Task,它有2个subTask,这两个subTask分别在2个不同的slot中运行。
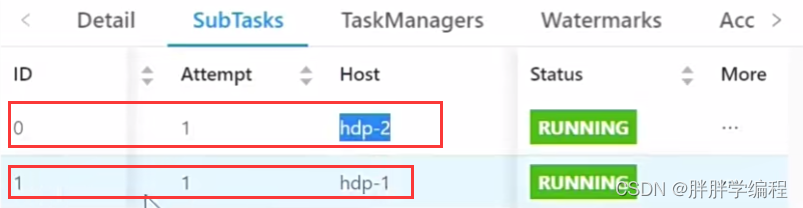
仅看第3个Task,也是有2个subTask,也是分别在2个slot中,和Task2共用那2个slot。
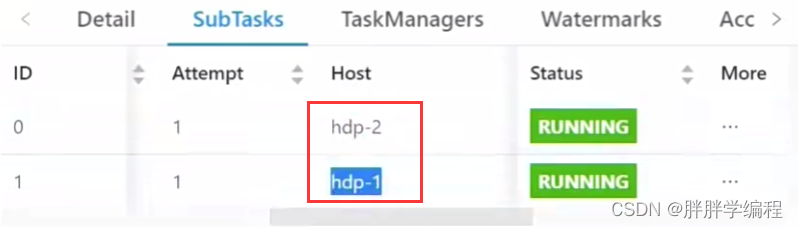
此时输出的结果,一部分在第一个slot所在节点,一部分在第二个slot所在节点。
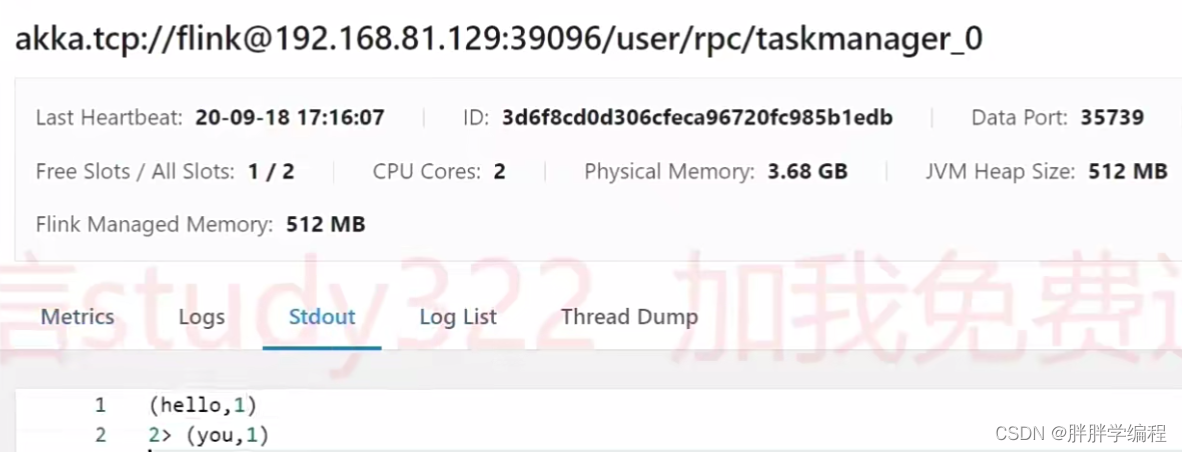
3)在webUI提交任务
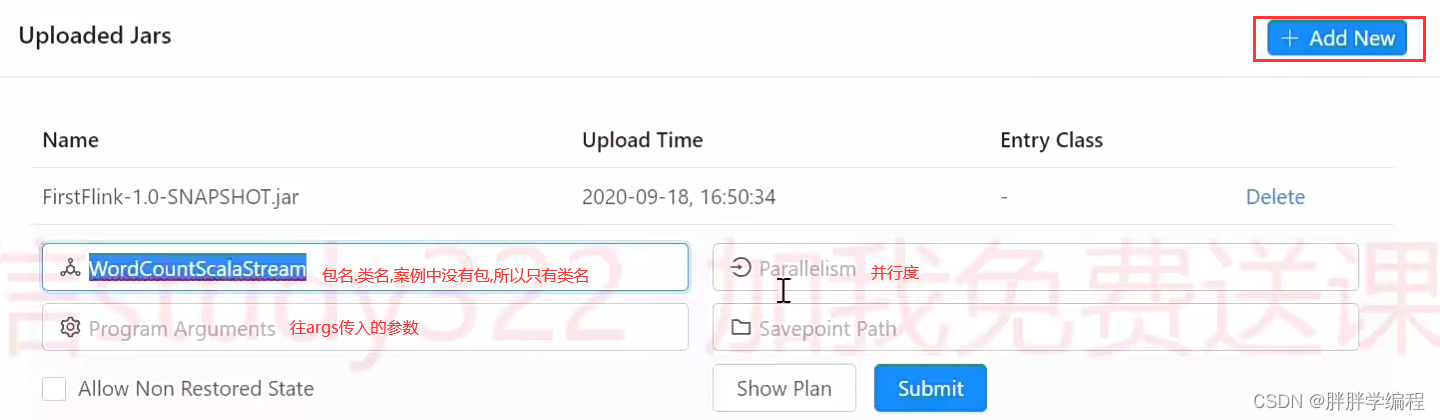
4)用命令行提交
bin/flink run \
-c #包名.类名 \
-p 2 #并行度 \
/jar的位置/jar的名字提交完会显示一个jobId,杀死job
bin/flink cancel jobId二、Yarn部署模式
1启动一个yarn session
2直接在yarn上提交运行flink作业(run a flink job on yarn)
四、Yarn模式部署
启动:
启动一个YARN session(Start a long-running Flink cluster on YARN);
#申请2个CPU、1600M内存::bin/yarn-session.sh -n 2 -tm 800 -s 1 -d
# -n 表示申请2个容器,这里指的就是多少个taskmanager
# -s 表示每个TaskManager的slots数量
# -tm 表示每个TaskManager的内存大小
# -d 表示以后台程序方式运行