unordered_map/unordered_set的学习[unordered系列]
文章目录
- 1.老生常谈_遍历
- 2.性能测试
- 3.OJ训练
- 3.1存在重复元素
- 3.2两个数组的交集Ⅱ
- 3.3两句话中的不常见单词
- 3.4两个数组的交集
- 3.5在长度2N的数组中找出重复N次的元素
1.老生常谈_遍历
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <list>
#include <vector>
#include <algorithm>
#include <array>
#include <time.h>
#include <queue>
#include <stack>
#include <string>
#include <set>
#include <map>
#include <unordered_set>
#include <unordered_map>
#include <functional>
#include <assert.h>
using namespace std;void test_unordered_set1()
{unordered_set<int> us;us.insert(1);us.insert(3);us.insert(2);us.insert(7);us.insert(2);unordered_set<int>::iterator it = us.begin();while (it != us.end()){cout << *it << " ";++it;}cout << endl;for (auto e : us){cout << e << " ";}cout << endl;
}void test_unordered_map()
{string s[] = { "陀螺", "陀螺", "洋娃娃", "陀螺", "洋娃娃", "洋娃娃", "陀螺","洋娃娃", "悠悠球", "洋娃娃", "悠悠球", "乐高" }; unordered_map<string, int> um;for (auto& e : s){um[e]++;}for (auto& e : um){cout << e.first << ":" << e.second << endl;}
}int main()
{const size_t N = 1000000;unordered_set<int> us;set<int> s;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){//v.push_back(rand()); //v.push_back(rand()+i); v.push_back(i); }cout << "插入" << endl;//set插入size_t begin1 = clock();for (auto e : v){s.insert(e);}size_t end1 = clock();cout << " set insert:" << end1 - begin1 << endl;//unordered_set插入size_t begin2 = clock();for (auto e : v){us.insert(e);}size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;cout << endl;//存入数据cout << "存入数据量[初始值100w--去重后]" << endl;cout << " set:" << s.size() << endl;cout << "unordered_set:" << us.size() << endl;cout << endl;cout << "查找" << endl;//set查找size_t begin3 = clock();for (auto e : v){s.find(e);}size_t end3 = clock();cout << " set find:" << end3 - begin3 << endl;//unordered_set查找size_t begin4 = clock();for (auto e : v){us.find(e);}size_t end4 = clock();cout << "unordered_set find:" << end4 - begin4 << endl ;cout << endl;cout << "删除" << endl;//set删除size_t begin5 = clock();for (auto e : v){s.erase(e);}size_t end5 = clock();cout << " set erase:" << end5 - begin5 << endl;//unordered_set删除size_t begin6 = clock();for (auto e : v){us.erase(e);}size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl << endl;cout << endl;return 0;
}2.性能测试

3.OJ训练
3.1存在重复元素
存在重复元素

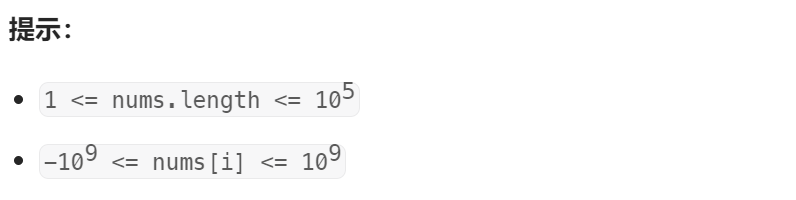
class Solution
{
public:bool containsDuplicate(vector<int>& nums) {unordered_set<int> us;for (auto x : nums) {//找不到x 插入usif (us.find(x) == us.end())us.insert(x);//找到了--存在重复值elsereturn true;}return false;}
};
3.2两个数组的交集Ⅱ
两个数组的交集Ⅱ

class Solution
{
public:vector<int> intersect(vector<int>& nums1, vector<int>& nums2){//假定nums1数据个数少:不写也ok // 作用在于到时用count遍历查找时次数少一些if (nums1.size() > nums2.size())return intersect(nums2, nums1);//插入到hashmapunordered_map <int, int> um;for (auto e : nums1){//um中有e e.second++//um中无e 插入e e.second++//insert当插入相同key时--插入失败++um[e];}//遍历第二个数组 vector<int> v;for (auto e : nums2){//若在数组1中也有--即是交集if (um.count(e)){//是交集--插入v.push_back(e);//下面三行的意义://数组一中假设x出现2次 数组二x出现2次 // 每匹配一个 插入v中后 x次数----um[e];if (um[e] == 0)um.erase(e);}}return v;}
};
3.3两句话中的不常见单词
两句话中的不常见单词

class Solution
{
public:vector<string> uncommonFromSentences(string s1, string s2){unordered_map<string, int> um;//遍历字符串每一个字符 是字母保存 // 遇空格时 str定为一个单词 单词作为key插入 value值++//到最后value是1的即为objstring str = "";for (auto& e : s1){if (e != ' ')str += e;else{um[str]++;str = "";}}um[str]++;str = "";for (auto& e : s2){if (e == ' '){um[str]++;str = "";}elsestr += e;}um[str]++;str = "";vector<string> v;for (auto& e : um){if (e.second == 1)v.push_back(e.first);}return v;}
};
3.4两个数组的交集
两个数组的交集

class Solution
{
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {unordered_set<int> us1, us2;for (auto& e : nums1)us1.insert(e);for (auto& e : nums2)us2.insert(e);return get(us1, us2);}vector<int> get(unordered_set<int>& us1, unordered_set<int>& us2) {if (us1.size() > us2.size())return get(us2, us1);vector<int> v;for (auto& e : us1){if (us2.count(e))v.push_back(e);}return v;}
};3.5在长度2N的数组中找出重复N次的元素
在长度2N的数组中找出重复N次的元素


class Solution
{
public:int repeatedNTimes(vector<int>& nums) {unordered_set<int> us;for (auto& e : nums) {if (us.count(e)) return e;us.insert(e);}return -1;}
};