LLM - Make Causal Mask 构造因果关系掩码

目录
一.引言
二.make_causal_mask
1.完整代码
2.Torch.full
3.torch.view
4.torch.masked_fill_
5.past_key_values_length
6.Test Main
三.总结
一.引言
Causal Mask 主要用于限定模型的可视范围,防止模型看到未来的数据。在具体应用中,Causal Mask 可将所有未来的 token 设置为零,从注意力机制中屏蔽掉这些令牌,使得模型在进行预测时只能关注过去和当前的 token,并确保模型仅基于每个时间步骤可用的信息进行预测。
在 Transformer 模型中,Multihead Attention 中的 Causal Mask 就是用于解决这个问题,以实现模型对于输入序列的正确处理。下面是 Causal 的可视化示例,在实践中其呈现倒三角形状:
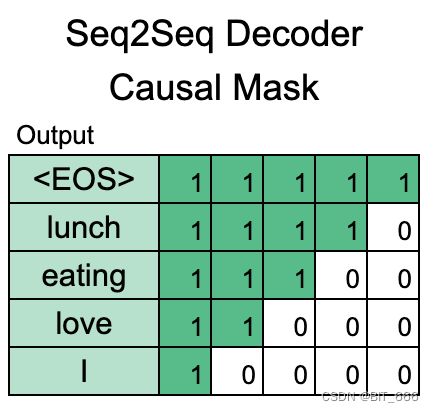
全文为 'I love eating lunch.' ,对于 'love' 而言其只能看到 'I',不能看到未来的 'eating'、'lunch'。
二.make_causal_mask
为了方便后续示例的展示,这里选择较小的参数,batch_size = 2,target_length = 4。
1.完整代码
# Copied from transformers.models.bart.modeling_bart._make_causal_mask
def _make_causal_mask(input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0
):"""Make causal mask used for bi-directional self-attention."""bsz, tgt_len = input_ids_shapemask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min, device=device), device=device)mask_cond = torch.arange(mask.size(-1), device=device)mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)mask = mask.to(dtype)if past_key_values_length > 0:mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)代码的 Input 主要就是一个二维的 input_ids_shape,分别为 batch_size 和 target_length,dtype 和 device 在这里比较好理解,还有就是最后的 past_key_values_length,用于补齐,这个也比较简单。Output 则是 (batch_size, 1, target_length, target_length) 的 Causal Mask,其中 Msak 的矩阵 target_length x target_length 就是上面所示的倒三角形状。

2.Torch.full
◆ 函数介绍
该函数用于创建一个具有指定填充值的新张量。该函数的语法如下:
torch.full(size, fill_value, *, dtype=None, device=None, requires_grad=False)参数说明:
size:张量的形状,可以是一个整数或者一个元组,例如:(3, 3) 或 3。fill_value:张量的填充值。dtype:张量的数据类型,默认为None,即根据输入的数据类型推断。device:张量所在的设备,默认为None,即根据输入的设备推断。requires_grad:是否需要计算梯度,默认为False。
该函数返回一个与指定形状相同且所有元素都被设置为指定填充值的新张量。
◆ 函数使用
mask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min))
这里 torch.finfo(dtype).min 为对应 torch.dtype 类型的最小值,以 bfloat16 为例:
print(torch.tensor(torch.finfo(dtype).min))
=> tensor(-3.3895e+38)而这一步 mask 的操作就是生成一个 tgt_len x tgt_len 的充满 min 元素的方阵:

3.torch.view
◆ 函数介绍
在 PyTorch 库中,view 函数用于改变一个张量(Tensor)的形状(shape)。它返回一个新的张量,其元素与原始张量相同,但形状(shape)已被改变。view 函数的行为非常类似于 NumPy的 reshape 函数。它会返回一个与原始张量共享数据但具有不同形状的新的张量。如果给定的形状与原始张量的元素总数不匹配,则会引发错误。
import torch x = torch.randn(4, 5) # 创建一个4x5的随机张量
y = x.view(20) # 改变形状为20的一维张量
z = x.view(-1, 10) # 改变形状为10的一维张量,第一维度由其他维度决定◆ 函数使用
mask_cond = torch.arange(mask.size(-1))mask_cond 是一个1维向量:
![]()
(mask_cond + 1).view(mask.size(-1), 1)这一步相当于在 mask_cond 基础上先加常量再 reshape:

4.torch.masked_fill_
◆ 函数介绍
在 PyTorch 库中,masked_fill_() 函数是一个张量(Tensor)方法,用于将张量中的指定区域填充为特定值。此函数需要一个掩码(mask)作为输入,该掩码应与原张量具有相同的形状。掩码中的 True 值表示需要填充的区域,False 值表示需要保留的原始值。
torch.Tensor.masked_fill_(mask, value)
参数说明:
mask(Bool tensor) - 掩码张量,用于指定需要填充的区域。value(float) - 填充的值。
◆ 示例
假设我们有一个 3x3 的张量,我们想要将所有大于 5 的元素替换为 -1。我们可以使用该函数来实现这个目标。
import torch # 创建一个3x3的张量
x = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 创建一个掩码,其中大于5的元素为True,其余为False
mask = x > 5 # 使用masked_fill_函数将大于5的元素替换为-1
x.masked_fill_(mask, -1) print(x)输出:
tensor([[ 1, 2, 3], [ 4, 5, 6], [-1, -1, -1]])◆ 函数使用
mask_cond < (mask_cond + 1).view(mask.size(-1), 1)传入函数的 mask 如下,呈倒三角形态,其中 True 的部分填充新值,False 部分保持不变:

mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
根据 mask 对 target x target 的方阵进行填充 0 得到我们上面提到的倒三角:

5.past_key_values_length
在 PyTorch 中,past_key_values_length 是一个参数,用于指定在使用 Transformer 模型时,过去键值缓存(past key-value cache)的长度。该参数通常与 Transformer 模型中的自注意力机制(self-attention mechanism)一起使用。在过去键值缓存中,模型保存了过去的键和值向量,以便在生成序列时重复使用它们。这些过去的键和值向量可以用于计算自注意力分数,从而提高生成序列的效率。较大的past_key_values_length可以增加模型的表现力,但也会增加计算量和内存消耗。因此,需要根据具体任务和资源限制来选择合适的值。
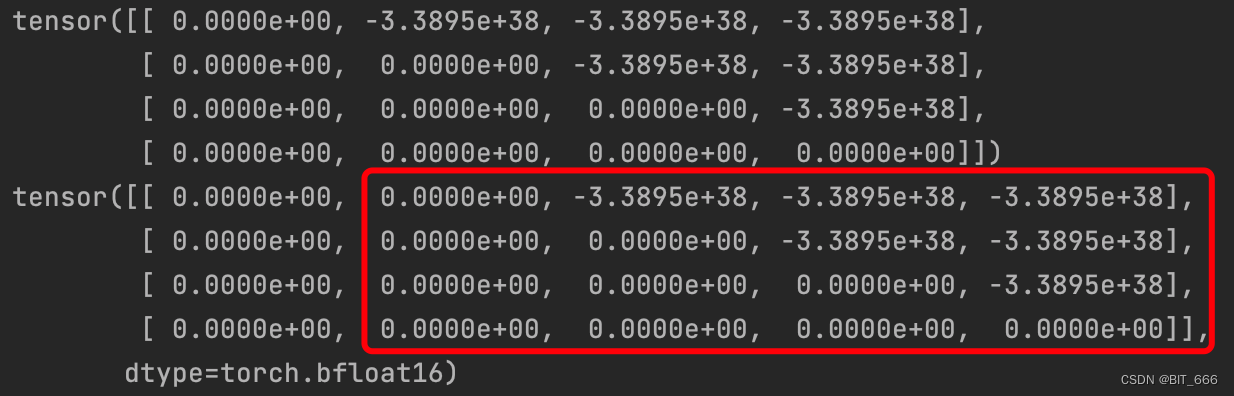
if past_key_values_length > 0:mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype), mask], dim=-1)这里定义 past_key_values_length = 1,代码逻辑就是在原有的 tgt x tgt 方阵前补 past_key_values_length 个 0:
6.Test Main
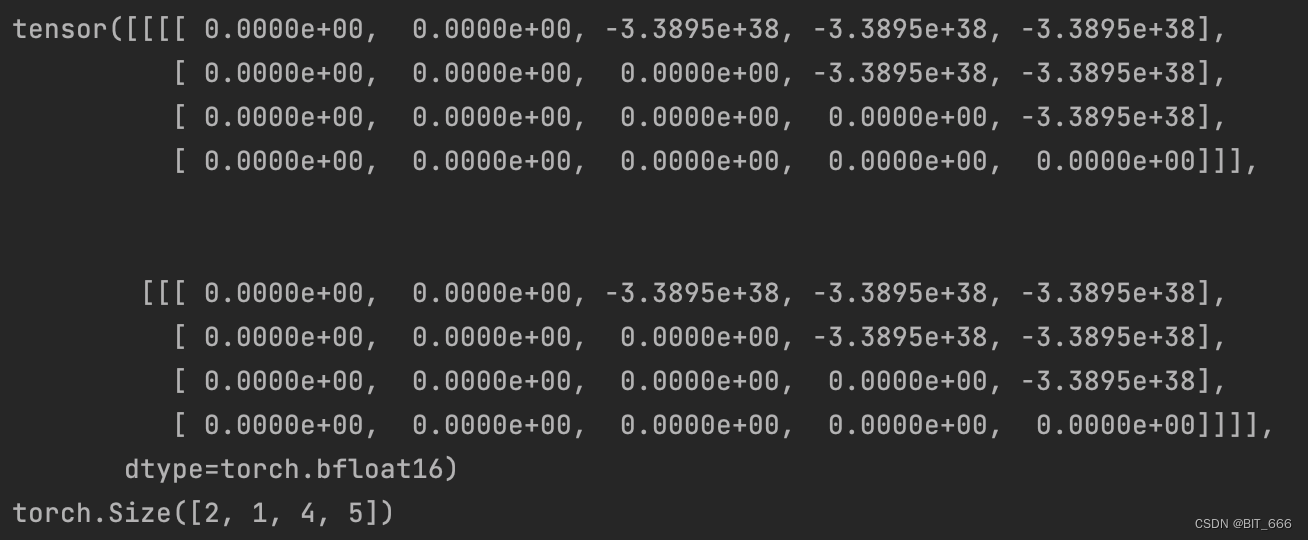
mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)if __name__ == '__main__':batch_size = 2target_length = 4input_shape = (batch_size, target_length)data_type = torch.bfloat16causal_mask = _make_causal_mask(input_shape, data_type, 1)print(causal_mask)print(causal_mask.shape)=> pask_key_length = 1填充后,tgt x tgt 变为 tgt x (1 + tgt)
=> 通过 None + expand 的组合,tgt x (1 + tgt) 变为 bsz x 1 x tgt x (1 + tgt)
三.总结
新系列博文一方面是阅读 HF 上 LLM 模型实现的源码,了解对应知识的实现过程。另一方面是之前很多同学主要接触 TF 1.x、TF 2.x 以及 Estimator 和 Keras 这一类深度学习工具,趁此机会也能熟悉 Torch 的使用方法。