MYSQL的存储过程
存储过程
存储过程是事先经过编译并存储在数据库中的一段 SQL 语句的集合,调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务器之间的传输,对于提高数据处理的效率是有好处的。存储过程思想上很简单,就是数据库 SQL 语言层面的代码封装与重用
- 封装,复用, 可以把某一业务SQL封装在存储过程中,需要用到的时候直接调用即可。
- 可以接收参数,也可以返回数据,再存储过程中,可以传递参数,也可以接收返回值。
- 减少网络交互,效率提升,如果涉及到多条SQL,每执行一次都是一次网络传输。 而如果封装在存储过程中,我们只需要网络交互一次可能就可以了。
基本语法
创建
CREATE PROCEDURE 存储过程名称 ([ 参数列表 ])BEGIN-- SQL 语句END ;
-- 创建DELIMITER $ #将语句的结束符号从分号;临时改为两个$(可以是自定义)CREATE PROCEDURE p1()
BEGINselect count(*) from stu;
END $DELIMITER ; #将语句的结束符号恢复为分号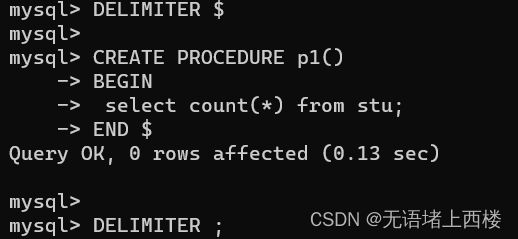
调用
call p1();
查看
show create procedure p1;删除
drop procedure if exists p1;带参数
MySQL存储过程的参数用在存储过程的定义,共有三种参数类型,IN,OUT,INOUT,形式
- IN 输入参数:表示调用者向过程传入值(传入值可以是字面量或变量)
- OUT 输出参数:表示过程向调用者传出值(可以返回多个值)(传出值只能是变量)
- INOUT 输入输出参数:既表示调用者向过程传入值,又表示过程向调用者传出值(值只能是变量)
in类型
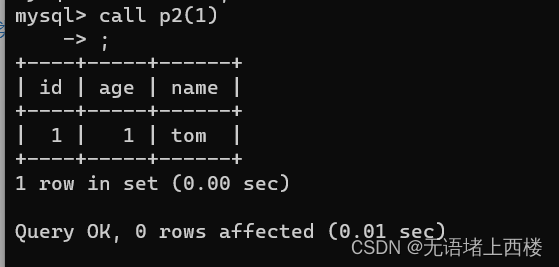
DELIMITER $CREATE PROCEDURE p2(in myid int)
BEGINselect * from stu where id=myid;
END $DELIMITER ;调用call p2(1);
char类型的参数
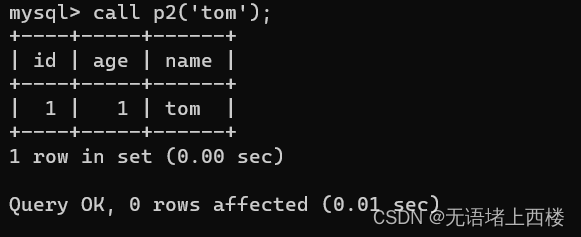
DELIMITER $CREATE PROCEDURE p2(in myname VARCHAR(255))
BEGINset @sql = 'select * from stu where name = ?'; -- 拼接查询总记录的SQL语句 prepare stmt from @sql; -- 预定义一个语句,并将它赋给 stmtset @a=myname;execute stmt using @a; -- 执行语句带参数,有其他参数加,分开deallocate prepare stmt;-- 要释放一个预定义语句的资源
END $DELIMITER ;调用
out类型
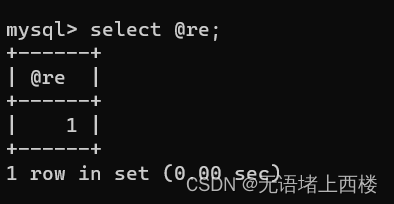
DELIMITER $CREATE PROCEDURE p3(out result int)
BEGINset result=1;
END $DELIMITER ;调用,传入一个无初始化的变量

结果
inout类型
DELIMITER $CREATE PROCEDURE p4(inout result int)
BEGINset result:=result+1;
END $DELIMITER ;调用,传入一个初始化的变量result,查看输出结果result

存储函数
存储函数是有返回值的存储过程,存储函数的参数只能是IN类型的。具体语法如下
CREATE FUNCTION 存储函数名称 ([ 参数列表 ])
RETURNS type [characteristic ...]
BEGIN-- SQL语句RETURN ...;
END ;characteristic说明
- DETERMINISTIC:相同的输入参数总是产生相同的结果
- NO SQL :不包含 SQL 语句。
- READS SQL DATA:包含读取数据的语句,但不包含写入数据的语句。
DETERMINISTIC的存储过程
create function fun1(n int)
returns int deterministicbegindeclare total int default 0;while n>0 doset total := total + n;set n := n - 1;end while;return total;end;
select fun1(50);READS SQL DATA的存储过程
create function fun2(id int(5))
returns varchar(50) reads sql data
beginDECLARE result VARCHAR(250);set result=CONCAT('SELECT * FROM stu WHERE stu.id=', id);return result;
end;select fun2(1)NO SQL的存储过程
CREATE FUNCTION fun3()
RETURNS VARCHAR(50) NO SQL
BEGINDECLARE result VARCHAR(50);SET result = 'Function';RETURN result;
END;
select fun3()