C++深度优化——cacheline测试
cacheline是内存调度的基本结构,其大小一般为32B或者64B。关于本机具体的配置信息可以在配置文件中看到:
![]()
这里可以看到我的这台机器的cacheline大小是64B。对于cacheline在多核处理器中有一个伪共享的状态,具体可以参考以下博客:高速缓存伪共享 - 知乎(这个大佬写了1K多篇文章,我感觉需要好好消化消化。)
所谓“伪共享”实际上是主存中的一个cacheline中的内容,在同一时刻只能被多核中的一个捕获处理。
程序如下:
#include <unistd.h>
#include <stdio.h>
#include <string>
#include <vector>
#include <string.h>
#include <thread>
#include <chrono>
#include <iostream>
#include <atomic>struct common
{volatile unsigned long a;volatile unsigned long b;
};
struct common_fulfill
{volatile unsigned long a;unsigned long az[7];volatile unsigned long b;unsigned long bz[7];
};using namespace std;
int main(int argc, char** argv)
{cout << "no-fulfill" << endl;do{common c;c.a = 0;c.b=0;volatile bool brun = true;thread t1([&c,&brun](){while(brun)c.a+=1;});thread t2([&c,&brun](){while(brun)c.b+=1;});std::this_thread::sleep_for(std::chrono::seconds(1));brun=false;//std::atomic_thread_fence(std::memory_order_seq_cst);t1.join();t2.join();cout << "a:" << c.a << "\t b:" << c.b << endl;}while(0);cout << "fulfill" << endl;do{common_fulfill c;c.a = 0;c.b=0;volatile bool brun = true;thread t1([&c,&brun](){while(brun)c.a+=1;});thread t2([&c,&brun](){while(brun)c.b+=1;});std::this_thread::sleep_for(std::chrono::seconds(1));brun=false;//std::atomic_thread_fence(std::memory_order_seq_cst);t1.join();t2.join();cout << "a:" << c.a << "\t b:" << c.b << endl;}while(0);cout << "add-per-second" << endl;do{common_fulfill c;c.a = 0;c.b=0;volatile bool brun = true;thread t1([&c,&brun](){while(brun)c.a+=1;});std::this_thread::sleep_for(std::chrono::seconds(1));brun=false;//std::atomic_thread_fence(std::memory_order_seq_cst);t1.join();cout << "a:" << c.a << endl;}while(0);return 0;
}注意,我在struct c中的a和b都增加了volatile关键字,这个关键字的作用在于将缓存和主存硬绑定,有点同步打开文件描述符的意思。这样,可以预期到内存会被以cacheline为单位上锁。然后进行编译。
![]()
这里用的是O2进行优化,然后执行,结果如下:
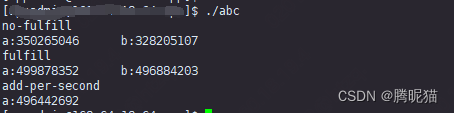
这个地方可以发现,在没有填充的情况下,1秒内访问的速度是3.5*10^8;而将struct c填充到128字节的访问次数是4.9*10^8。几乎同样的代码,将最后的单CPU每秒能进行加法数量的统计去掉之后,结果如下:
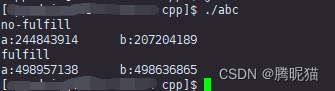
可以看到,两次的情况,不填充的速度总是要远远逊色于填充的情况。我们在做服务器程序深度优化的时候,要注意这个硬件细节,有时候能够极大地加快程序的运行速度。可以注意到,伪共享状态只是影响了CPU的运行时间,服务器的大量CPU时间会在等待锁中消耗,所以现在无锁代码非常流行。另外为什么增加或者修改代码的大小就会影响CPU的执行效率呢?这个问题还是没有得到答案。