数据分析三剑客之Pandas
1.引入
前面一篇文章我们介绍了numpy,但numpy的特长并不是在于数据处理,而是在它能非常方便地实现科学计算,所以我们日常对数据进行处理时用的numpy情况并不是很多,我们需要处理的数据一般都是带有列标签和index索引的,而numpy并不支持这些,这时我们就需要pandas上场啦!
2.WHAT?
Pandas是基于Numpy构建的库,在数据处理方面可以把它理解为numpy加强版,同时Pandas也是一项开源项目 。不同于numpy的是,pandas拥有种数据结构:Series和DataFrame:

下面我们就来生成一个简单的series对象来方便理解:
In [1]: from pandas import Series,DataFrame
In [2]: import pandas as pd
In [3]: data = Series([1,2,3,4],index = ['a','b','c','d'])
In [4]: data
Out[4]:
a 1
b 2
c 3
d 4
dtype: int64Series是一种类似一维数组的数据结构,由一组数据和与之相关的index组成,这个结构一看似乎与dict字典差不多,我们知道字典是一种无序的数据结构,而pandas中的Series的数据结构不一样,它相当于定长有序的字典,并且它的index和value之间是独立的,两者的索引还是有区别的,Series的index是可变的,而dict字典的key值是不可变的。
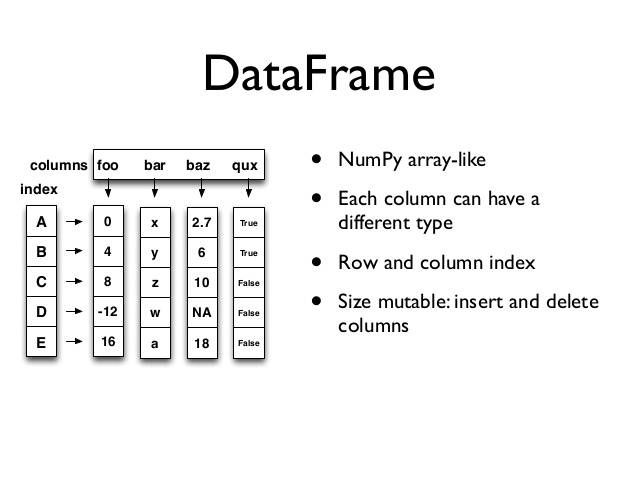
下面照例生成一个简单的DataFrame对象:
In [8]: data = {'a':[1,2,3],'b':['we','you','they'],'c':['btc','eos','ae']}
In [9]: df = DataFrame(data)
In [10]: df
Out[10]:a b c
0 1 we btc
1 2 you eos
2 3 they aeDataFrame这种数据结构我们可以把它看作是一张二维表,DataFrame长得跟我们平时使用的Excel表格差不多,DataFrame的横行称为columns,竖列和Series一样称为index,DataFrame每一列可以是不同类型的值集合,所以DataFrame你也可以把它视为不同数据类型同一index的Series集合。
3.WHY?
科学计算方面numpy是优势,但在数据处理方面DataFrame就更胜一筹了,事实上DataFrame已经覆盖了一部分的数据操作了,对于数据挖掘来说,工作可大概分为读取数据-数据清洗-分析建模-结果展示:
先说说读取数据,Pandas提供强大的IO读取工具,csv格式、Excel文件、数据库等都可以非常简便地读取,对于大数据,pandas也支持大文件的分块读取;
接下来就是数据清洗,面对数据集,我们遇到最多的情况就是存在缺失值,Pandas把各种类型数据类型的缺失值统一称为NaN(这里要多说几句,None==None这个结果是true,但np.nan==np.nan这个结果是false,NaN在官方文档中定义的是float类型,有关于NaN和None的区别以及使用,有位博主已经做好整理:None vs NaN),Pandas提供许多方便快捷的方法来处理这些缺失值NaN。
最重要的分析建模阶段,Pandas自动且明确的数据对齐特性,非常方便地使新的对象可以正确地与一组标签对齐,有了这个特性,Pandas就可以非常方便地将数据集进行拆分-重组操作。
最后就是结果展示阶段了,我们都知道Matplotlib是个数据视图化的好工具,Pandas与Matplotlib搭配,不用复杂的代码,就可以生成多种多样的数据视图。
4.HOW?
Series
Series的两种生成方式:
In [19]: data = Series([222,'btc',234,'eos'])
In [20]: data
Out[20]:
0 222
1 btc
2 234
3 eos
dtype: object虽然我们在生成的时候没有设置index值,但Series还是会自动帮我们生成index,这种方式生成的Series结构跟list列表差不多,可以把这种形式的Series理解为竖起来的list列表。
In [21]: data = Series([1,2,3,4],index = ['a','b','c','d'])
In [22]: data
Out[22]:
a 1
b 2
c 3
d 4
dtype: int64这种形式的Series可以理解为numpy的array外面披了一件index的马甲,所以array的相关操作,Series同样也是支持的。结构非常相似的dict字典同样也是可以转化为Series格式的:
In [29]: dic = {'a':1,'b':2,'c':'as'}
In [30]: dicSeries = Series(dic)查看Series的相关信息:
In [32]: data.index
Out[32]: Index(['a', 'b', 'c', 'd'], dtype='object')In [33]: data.values
Out[33]: array([1, 2, 3, 4], dtype=int64)In [35]: 'a' in data #in方法默认判断的是index值
Out[35]: TrueSeries的NaN生成:
In [46]: index1 = [ 'a','b','c','d']
In [47]: dic = {'b':1,'c':1,'d':1}
In [48]: data2 = Series(dic,index=index1)
In [49]: data2
Out[49]:
a NaN
b 1.0
c 1.0
d 1.0
dtype: float64从这里我们可以看出Series的生成依据的是index值,index‘a’在字典dic的key中并不存在,Series自然也找不到’a’的对应value值,这种情况下Pandas就会自动生成NaN(not a number)来填补缺失值,这里还有个有趣的现象,原本dtype是int类型,生成NaN后就变成了float类型了,因为NaN的官方定义就是float类型。
NaN的相关查询:
In [58]: data2.isnull()
Out[58]:
a True
b False
c False
d False
dtype: boolIn [59]: data2.notnull()
Out[59]:
a False
b True
c True
d True
dtype: boolIn [60]: data2[data2.isnull()==True] #嵌套查询NaN
Out[60]:
a NaN
dtype: float64In [64]: data2.count() #统计非NaN个数
Out[64]: 3切记切记,查询NaN值切记不要使用np.nan==np.nan这种形式来作为判断条件,结果永远是False,==是用作值判断的,而NaN并没有值,如果你不想使用上方的判断方法,你可以使用is作为判断方法,is是对象引用判断,np.nan is np.nan,结果就是你要的True。
Series自动对齐:
In [72]: data1
Out[72]:
a 1
asd 1
b 1
dtype: int64In [73]: data
Out[73]:
a 1
b 2
c 3
d 4
dtype: int64In [74]: data+data1
Out[74]:
a 2.0
asd NaN
b 3.0
c NaN
d NaN
dtype: float64从上面两个Series中不难看出各自的index所处位置并不完全相同,这时Series的自动对齐特性就发挥作用了,在算术运算中,Series会自动寻找匹配的index值进行运算,如果index不存在匹配则自动赋予NaN,值得注意的是,任何数+NaN=NaN,你可以把NaN理解为吸收一切的黑洞。
Series的name属性:
In [84]: data.index.name = 'abc'
In [85]: data.name = 'test'
In [86]: data
Out[86]:
abc
a 1
b 2
c 3
d 4
Name: test, dtype: int64Series对象本身及其索引index都有一个name属性,name属性主要发挥作用是在DataFrame中,当我们把一个Series对象放进DataFrame中,新的列将根据我们的name属性对该列进行命名,如果我们没有给Series命名,DataFrame则会自动帮我们命名为0。
5.DataFrame
DataFrame的生成:
In [87]: data = {'name': ['BTC', 'ETH', 'EOS'], 'price':[50000, 4000, 150]}
In [88]: data = DataFrame(data)
In [89]: data
Out[89]:name price
0 BTC 50000
1 ETH 4000
2 EOS 150DataFrame的生成与Series差不多,你可以自己指定index,也可不指定,DataFrame会自动帮你补上。
查看DataFrame的相关信息:
In [95]: data.index
Out[95]: RangeIndex(start=0, stop=3, step=1)In [96]: data.values
Out[96]:
array([['BTC', 50000],['ETH', 4000],['EOS', 150]], dtype=object)In [97]: data.columns #DataFrame的列标签
Out[97]: Index(['name', 'price'], dtype='object')DataFrame的索引:
In [92]: data.name
Out[92]:
0 BTC
1 ETH
2 EOS
Name: name, dtype: objectIn [93]: data['name']
Out[93]:
0 BTC
1 ETH
2 EOS
Name: name, dtype: objectIn [94]: data.iloc[1] #loc['name']查询的是行标签
Out[94]:
name ETH
price 4000
Name: 1, dtype: object其实行索引,除了iloc,loc还有个ix,ix既可以进行行标签索引,也可以进行行号索引,但这也大大增加了它的不确定性,有时会出现一些奇怪的问题,所以pandas在0.20.0版本的时候就把ix给弃用了。
6.DataFrame的常用操作
简单地增加行、列:
In [105]: data['type'] = 'token' #增加列In [106]: data
Out[106]:name price type
0 BTC 50000 token
1 ETH 4000 token
2 EOS 150 token
In [109]: data.loc['3'] = ['ae',200,'token'] #增加行In [110]: data
Out[110]:name price type
0 BTC 50000 token
1 ETH 4000 token
2 EOS 150 token
3 ae 200 token删除行、列操作:
In [117]: del data['type'] #删除列In [118]: data
Out[118]:name price
0 BTC 50000
1 ETH 4000
2 EOS 150
3 ae 200
In [120]: data.drop([2]) #删除行
Out[120]:name price
0 BTC 50000
1 ETH 4000
3 ae 200In [121]: data
Out[121]:name price
0 BTC 50000
1 ETH 4000
2 EOS 150
3 ae 200这里需要注意的是,使用drop()方法返回的是Copy而不是视图,要想真正在原数据里删除行,就要设置inplace=True:
In [125]: data.drop([2],inplace=True)In [126]: data
Out[126]:name price
0 BTC 50000
1 ETH 4000
3 ae 200设置某一列为index:
In [131]: data.set_index(['name'],inplace=True)In [132]: data
Out[132]:price
name
BTC 50000
ETH 4000
ae 200In [133]: data.reset_index(inplace=True) #将index返回回dataframe中In [134]: data
Out[134]:name price
0 BTC 50000
1 ETH 4000
2 ae 200处理缺失值:
In [149]: data
Out[149]:name price
0 BTC 50000.0
1 ETH 4000.0
2 ae 200.0
3 eos NaNIn [150]: data.dropna() #丢弃含有缺失值的行
Out[150]:name price
0 BTC 50000.0
1 ETH 4000.0
2 ae 200.0In [151]: data.fillna(0) #填充缺失值数据为0
Out[151]:name price
0 BTC 50000.0
1 ETH 4000.0
2 ae 200.0
3 eos 0.0还是需要注意:这些方法返回的是copy而不是视图,如果想在原数据上改变,别忘了inplace=True。
数据合并:
In [160]: data
Out[160]:name price
0 BTC 50000.0
1 ETH 4000.0
2 ae 200.0
3 eos NaNIn [161]: data1
Out[161]:name other
0 BTC 50000
1 BTC 4000
2 EOS 150In [162]: pd.merge(data,data1,on='name',how='left') #以name为key进行左连接
Out[162]:name price other
0 BTC 50000.0 50000.0
1 BTC 50000.0 4000.0
2 ETH 4000.0 NaN
3 ae 200.0 NaN
4 eos NaN NaN平时进行数据合并操作,更多的会出一种情况,那就是出现重复值,DataFrame也为我们提供了简便的方法:
data.drop_duplicates(inplace=True)
数据的简单保存与读取:
In [165]: data.to_csv('test.csv')In [166]: pd.read_csv('test.csv')
Out[166]:Unnamed: 0 name price
0 0 BTC 50000.0
1 1 ETH 4000.0
2 2 ae 200.0
3 3 eos NaN为什么会出现这种情况呢,从头看到尾的同学可能就看出来了,增加第三行时,我用的是loc[‘3’]行标签来增加的,而read_csv方法是默认index是从0开始增长的,此时只需要我们设置下index参数就ok了:
In [167]: data.to_csv('test.csv',index=None) #不保存行索引
In [168]: pd.read_csv('test.csv')
Out[168]:name price
0 BTC 50000.0
1 ETH 4000.0
2 ae 200.0
3 eos NaN其他的还有header参数, 这些参数都是我们在保存数据时需要注意的。