解读亚马逊云科技语义搜图检索方案
图像检索(包括文搜图和图搜图)是各个行业中常见的一个应用场景。比如在电商场景中,基于以图搜图做相似商品查找;在云相册场景中,基于文搜图来找寻所需的图像素材。
传统基于标签的图像检索方式,即先使用目标检测/图像分类产品(如亚马逊云科技Amazon Rekognation)产生图片标签,再存储标签并在检索时匹配标签,存在一些局限性。第一是该方法受限于产品本身支持的标签数量,比如Amazon Rekognation支持3000个左右的标签,对于标签之外的目标无法检测并检索。第二是标签检索对动词、数量、方位等信息不敏感。诸如“两个孩子在一栋房子前面奔跑”,会出现包含“孩子,房子”标签的图像,但容易忽略“两个,前面,奔跑”等信息。
下文将将介绍两种基于语义的搜图检索方式以及部署方案,可以实际测试两种方式在特定应用场景下的搜索率以及搜索的准确性,并选择更加适合的方案使用。
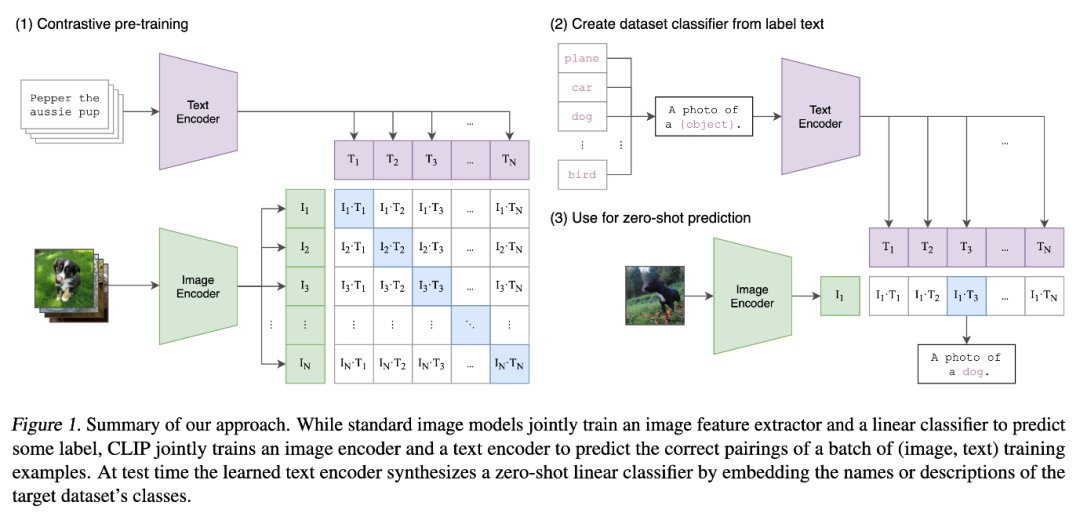
方案一:利用CLIP模型的文本编码器和图像编码器,将图像和文本放入同一维度的潜在向量空间中,找到与文本向量最相近的图像向量以实现基于语义的图像搜索。如下图所示,可以看到图像对应的Image embedding在向量空间的位置,不同文本会同样被编码至向量空间中,当图像和文字语义最相近时,其Image embedding和Text embedding的余弦距离最近。

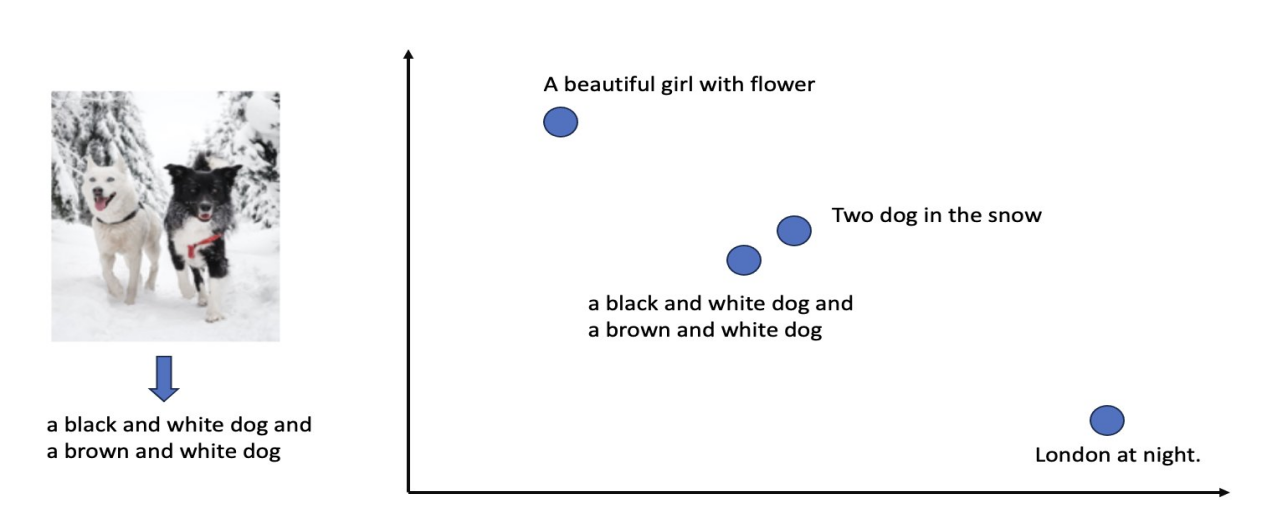
方案二:利用图生文模型(案例使用vit-gpt2-image-captioning模型,可替换)先对图像产生对应的文本描述,再将生成的图片描述文本与查询文本放入同一维度的潜在向量空间中,找到与查询文本向量最相近的描述文本向量所对应的图像,以实现基于语义的图像搜索。如下图所示,可以看到图像经过vit-gpt2-image-captioning模型后,产生“a black and white dog and a brown and white dog”的描述文本。对于语义最相近的文本,其Text embedding之间的余弦距离最近。
CLIP模型介绍
CLIP(Contrastive Language-Image Pre-Training)是由OpenAI于2021年推出的一种深度学习模型。它主要包含两个组成部分:一个用于图像编码的卷积神经网络(Convolutional Neural Network,CNN)和一个用于文本编码的Transformer模型。这两个编码器将图像和文本编码输入至相同的潜在向量空间中,并使得相似的图像和文本在潜在向量空间中的距离更近。
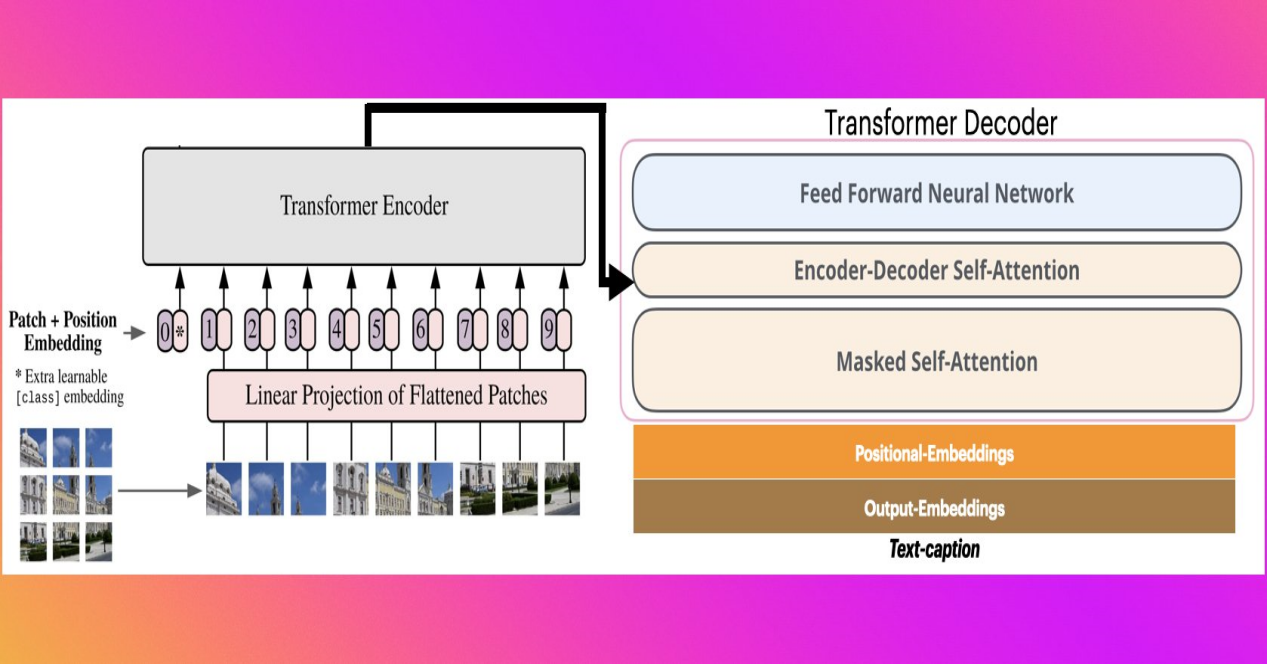
vit-gpt2-image-captioning模型介绍
vit-gpt2-image-captioning模型利用Vision Transformer(例如ViT、BEiT、DeiT、Swin)对图像进行编码,然后基于预训练的语言模型(例如RoBERTa、GPT2、BERT、DistilBERT)产生文本,从而实现“看图说话”的能力。
OpenSearch k-NN介绍
Amazon OpenSearch支持k-NN搜索,可让在向量空间中通过欧几里得距离或余弦距离查找点之间的“最近邻”。在语义搜图检索方案中,主要包括两个阶段:
-
构建k-NN index——在此阶段,将产生的图像向量,或描述文本向量,保存到OpenSearch服务中的k-NN index中。k-NN的基本概念是相似数据点存在于嵌入空间中非常接近的位置。例如,文本“一朵红花”、文本“红玫瑰”和“红玫瑰”图像语义相似,因此这些文本和图像在潜在向量空间的位置是彼此接近的。
-
查询k-NN index——在此阶段,通过实时机器学习模型对查询文本或者图像进行编码,形成向量。随后使用该文本向量来查询存储在OpenSearch服务中的k-NN index,k-NN index从潜在向量空间返回相似的向量。例如,如果您的查询文本是“一朵红花”,它将返回红玫瑰图像的向量作为类似的项目。
方案架构
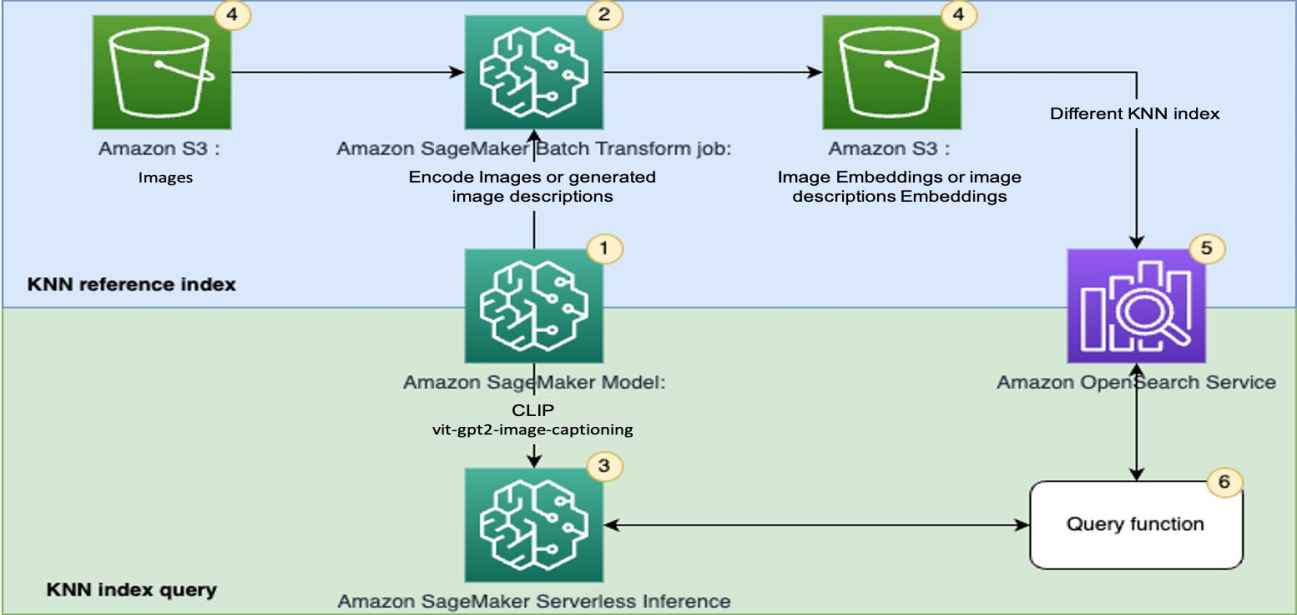
整体方案架构及介绍如下:
-
通过预训练的CLIP模型和vit-gpt2-image-captioning模型创建一个用来进行批量和实时推理的SageMaker模型。
-
使用SageMaker批量转换作业生成图像Embedding或图像描述文本Embedding。
-
使用SageMaker实时推理(或无服务器推理)来将图像和文本进行实时编码,产生图像Embedding或图像描述文本Embedding。
-
使用Amazon Simple Storage Service(Amazon S3)作为主要存储服务,存储原始图像以及SageMaker批量转换作业产生的Embedding文件。
-
使用OpenSearch服务来存储向量并查找相关的向量。
-
使用一个查询函数来编排查询编码并执行k-NN搜索。
该方案具有以下优势:
-
灵活构建。可以非常方便的替换CLIP模型或vit-gpt2-image-captioning模型至其他模型,只需要在SageMaker上创建相关模型并部署终端节点即可;也可以替换OpenSearch使用其他的向量数据库。
-
可快速构建大规模生产应用。该方案基于SageMaker,OpenSearch,S3等服务构建,生产应用时无需过多担心资源限制及拓展,帮助您在快速进行场景测试后进入大规模生产应用。
结语
综上所诉,探究了基于CLIP模型和图生文模型的语义搜图检索方案,适用于以图搜图做相似商品查找、基于文搜图来找寻所需的图像素材等众多场景。并且此方案具有灵活构建的特性,并可以快速构建大规模生产应用的优势,有助于客户提高生产效率。