6.s081/6.1810(Fall 2022)Lab5: Copy-on-Write Fork for xv6
前言
本来往年这里还有个Lazy Allocation的,今年不知道为啥直接给跳过去了。.
其他篇章
环境搭建
Lab1: Utilities
Lab2: System calls
Lab3: Page tables
Lab4: Traps
Lab5: Copy-on-Write Fork for xv6
参考链接
官网链接
xv6手册链接,这个挺重要的,建议做lab之前最好读一读。
xv6手册中文版,这是几位先辈们的辛勤奉献来的呀!再习惯英文文档阅读我还是更喜欢中文一点,开源无敌!
个人代码仓库
官方文档
1. 简单分析
写时拷贝(Copy On Write)技术之前在15445也写过了,这里再简单介绍一下。我们知道,fork的过程有一条就是子进程会拷贝父进程的内存空间,但是这个拷贝是有一定开销的,尤其是在需要拷贝的东西多的时候更明显。但是这就引出了一个问题——我们真的需要去拷贝吗?很显然,从逻辑上来看,只有父进程或子进程对内存空间有修改时,这种拷贝才是有意义的,否则只是徒增开销而已。依此便提出了COW思想——我们将拷贝的时机推迟到某个进程修改内存的时候,这样就可以优化掉很多无必要的开销。
落实到实现策略上,Lab文档为我们描述了一种方案——平时fork我们只需要为父子进程添加一个指向原始页面的指针即可,这个页面将被标记为只读。这样当父进程或子进程尝试写入页面时,就会触发page fault(这应该算异常吧),这个时候再由内核去重新分配内存空间,为进程提供一个可写的页面,处理结束,至此我们就基本实现了这个COW。
不过这么写产生了一个问题,即是内存释放,本来我们页面的释放是随着进程释放同步进行的,但是上面描述的策略中的进程不再持有真实的内存页面,而仅仅是一个引用,为了处理释放,我们可以采用引用计数的方法——我们可以在内存页的元信息(meta data)中单独保存一个值用于计数,当我们的进程释放时,递减引用计数,然后当计数为0时再调用内存的释放。
需要注意的是,这个过程描述起来非常简单,在xv6上的实现也不太困难,但是在实际的大型内核中总会有各种各样的细节问题,Lab提供了一个探讨COW存在的问题的链接,可以参考一下。

根据上面的分析,我们可以将这个Lab分为三个部分做:
- 在fork时造成内存复制的假象
- 处理page fault,在写时真实复制内存
- 使用引用计数管理内存释放
下面我们就来实现吧!
2. 在fork时实现页面复用而非复制
根据我们之前lab的经验以及lab中的hint,fork中执行页面复制的操作是在vm.c下的uvmcopy完成的:
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{pte_t *pte;uint64 pa, i;uint flags;char *mem;for(i = 0; i < sz; i += PGSIZE){// 检查页表合法性if((pte = walk(old, i, 0)) == 0)panic("uvmcopy: pte should exist");if((*pte & PTE_V) == 0)panic("uvmcopy: page not present");pa = PTE2PA(*pte);flags = PTE_FLAGS(*pte);if((mem = kalloc()) == 0) // 没有空闲内存goto err;memmove(mem, (char*)pa, PGSIZE); // 拷贝内存if(mappages(new, i, PGSIZE, (uint64)mem, flags) != 0){kfree(mem);goto err;}}return 0;err:uvmunmap(new, 0, i / PGSIZE, 1);return -1;
}
可以看到,整体的流程是先分配一个mem,然后将父进程的pa拷贝到mem中去,然后把这个mem映射到子进程上,因此我们可以直接把pa映射过去即可:
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{pte_t *pte;uint64 pa, i;uint flags;for(i = 0; i < sz; i += PGSIZE){// 检查页表合法性if((pte = walk(old, i, 0)) == 0)panic("uvmcopy: pte should exist");if((*pte & PTE_V) == 0)panic("uvmcopy: page not present");*pte &= ~PTE_W; // 取消写权限pa = PTE2PA(*pte);flags = PTE_FLAGS(*pte);if(mappages(new, i, PGSIZE, pa, flags) != 0){goto err;}}return 0;err:uvmunmap(new, 0, i / PGSIZE, 1);return -1;
}
3. 处理page fault
触发page fault就会trap,而trap我们知道是在trap.c下的usertrap完成,而处理fault需要判断fault的类型,这在xv6里面是一个选择结构,通过r_scause()的值来判断,在去年其实有一个Lazy Allocation的Lab的,里面有告诉我们r_scause()值为13或15为页面错误,其中13为读错误,15为写错误,因此此处我们只需要处理值为15时的情况:
else if (r_scause() == 15) {uint64 stval = r_stval();if (is_cow_fault(p->pagetable, stval)) {if (handle_cow_fault(p->pagetable, stval) < 0) {printf("usertrap(): alloc failed!\n"); p->killed = 1; // 当内存分配完,直接kill}}else {goto unexpected;}}else {
unexpected:printf("usertrap(): unexpected scause %p pid=%d\n", r_scause(), p->pid);printf(" sepc=%p stval=%p\n", r_sepc(), r_stval());setkilled(p);}
框架有了,我们怎么来判断一个fault是不是cow导致的呢?我们可以在PTE中用一位标记一下:
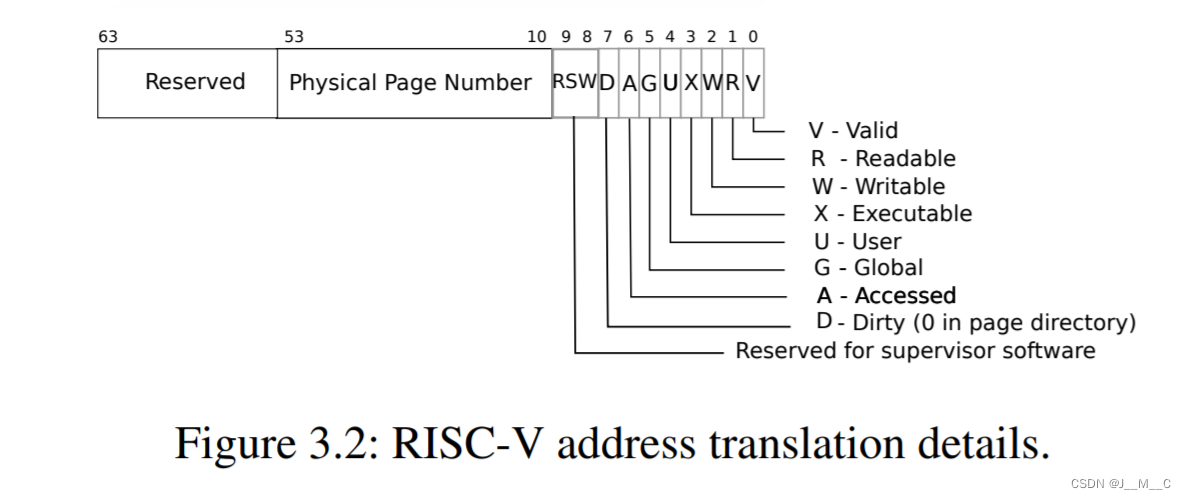
查看参考手册,我们可以看到8-9位是保留位,因此我们可以把第八位用于保存COW:
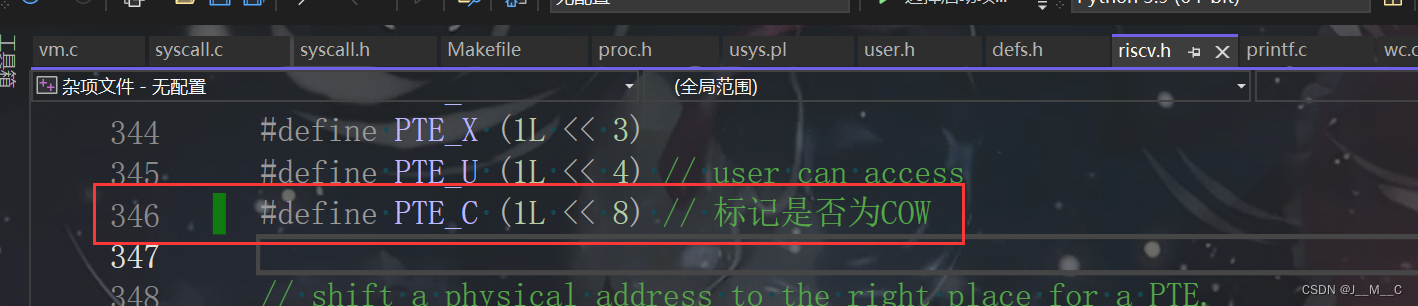
并在uvmcopy处置位
*pte |= PTE_C; // 设置写时复制标志
然后我们在vm.c实现上面两个函数:
int
is_cow_fault(pagetable_t pagetable, uint64 va)
{if (va >= MAXVA)return 0;pte_t* pte = walk(pagetable, PGROUNDDOWN(va), 0);return pte && (*pte & (PTE_V | PTE_U | PTE_C));
}int
handle_cow_fault(pagetable_t pagetable, uint64 va)
{va = PGROUNDDOWN(va);pte_t* pte = walk(pagetable, va, 0);if (!pte) {return -1;}uint64 pa = PTE2PA(*pte);uint flags = (PTE_FLAGS(*pte) & ~PTE_C) | PTE_W; // 取消写时复制标志,设置写权限char* mem = kalloc();if (!mem) {return -1;}memmove(mem, (char*)pa, PGSIZE);uvmunmap(pagetable, va, 1, 1); // 取消映射if (mappages(pagetable, va, PGSIZE, (uint64)mem, flags) != 0) {kfree(mem);return -1;}return 0;
}
并在defs.h创建声明
int is_cow_fault(pagetable_t pagetable, uint64 va);
int handle_cow_fault(pagetable_t pagetable, uint64 va);
4. 引用计数管理内存释放
首先思考一下我们的引用计数怎么实现,hint提示我们可以利用一个数组,直接映射对应页的引用计数,于是我们在kalloc.c中:
// 引用计数的锁和保存值
struct spinlock cow_ref_lock;
int cow_cnt[(PHYSTOP - KERNBASE) / PGSIZE];
#define PA2IDX(pa) (((uint64)(pa) - KERNBASE) / PGSIZE)
初始化锁:
void
kinit()
{initlock(&kmem.lock, "kmem");initlock(&cow_ref_lock, "cow_ref_lock"); // 初始化引用计数的锁freerange(end, (void*)PHYSTOP);
}
然后定义自增操作与自减操作:
void
inc_ref(void* pa) // 自增引用计数
{acquire(&cow_ref_lock);cow_cnt[PA2IDX(pa)]++;release(&cow_ref_lock);
}void
dec_ref(void* pa) // 自减引用计数
{acquire(&cow_ref_lock);cow_cnt[PA2IDX(pa)]--;release(&cow_ref_lock);
}
完善alloc与free:
void
kfree(void *pa)
{dec_ref(r);if (cow_cnt[PA2IDX(r)] > 0) // 只有引用计数为1时才释放return;struct run *r;if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)panic("kfree");// Fill with junk to catch dangling refs.memset(pa, 1, PGSIZE);r = (struct run*)pa;acquire(&kmem.lock);r->next = kmem.freelist;kmem.freelist = r;release(&kmem.lock);
}// Allocate one 4096-byte page of physical memory.
// Returns a pointer that the kernel can use.
// Returns 0 if the memory cannot be allocated.
void *
kalloc(void)
{struct run *r;acquire(&kmem.lock);r = kmem.freelist;if(r)kmem.freelist = r->next;release(&kmem.lock);if(r){cow_cnt[PA2IDX(r)] = 1; // 将引用计数置1memset((char*)r, 5, PGSIZE); // fill with junk}return (void*)r;
}
然后我们思考一下什么时候引用计数需要增加呢?那应该是fork的时候,因此我们需要暴露出inc_ref(略)然后在uvmcopy中调用它:
int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{pte_t *pte;uint64 pa, i;uint flags;for(i = 0; i < sz; i += PGSIZE){// 检查页表合法性if((pte = walk(old, i, 0)) == 0)panic("uvmcopy: pte should exist");if((*pte & PTE_V) == 0)panic("uvmcopy: page not present");if (*pte & PTE_W) // 对于本身可写的页才去取消写权限{*pte &= ~PTE_W; // 取消写权限*pte |= PTE_C; // 设置写时复制标志}pa = PTE2PA(*pte);flags = PTE_FLAGS(*pte);if(mappages(new, i, PGSIZE, pa, flags) != 0){goto err;}inc_ref((void*)pa);}return 0;err:uvmunmap(new, 0, i / PGSIZE, 1);return -1;
}
最后还有个问题,就是对于不会触发trap的页操作,这里没有涉及到,根据提示,我们可以找到vm.c下的copyout,这个函数是通过软件访问页表,我们就仿照trap里为它新增一段逻辑:
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{uint64 n, va0, pa0;while(len > 0){va0 = PGROUNDDOWN(dstva);if (is_cow_fault(p->pagetable, stval)) {if (handle_cow_fault(p->pagetable, stval) < 0) {printf("copyout(): alloc failed!\n");return -1;}}pa0 = walkaddr(pagetable, va0);if(pa0 == 0)return -1;n = PGSIZE - (dstva - va0);if(n > len)n = len;memmove((void *)(pa0 + (dstva - va0)), src, n);len -= n;src += n;dstva = va0 + PGSIZE;}return 0;
}
5. 测试
最后运行make grade评分即可,这里说一下我遇到过的错:
- 终端刚开回车两下就出现 panic: uvmunmap: not aligned :
原因是va没有对齐,在单独写的那两个函数里对vaa使用va = PGROUNDDOWN(va);即可; - Test file测试过不了:
原因是copyout没有改,改了就行;