Demystifying Prompts in Language Models via Perplexity Estimation
Demystifying Prompts in Language Models via Perplexity Estimation
原文链接
Gonen H, Iyer S, Blevins T, et al. Demystifying prompts in language models via perplexity estimation[J]. arXiv preprint arXiv:2212.04037, 2022.
简单来说就是作者通过在不同LLM和不同任务上的实验,发现低困惑度的prompt更能提升LLM的性能,如下图所示,困惑度和acc大致呈一个负相关的趋势。
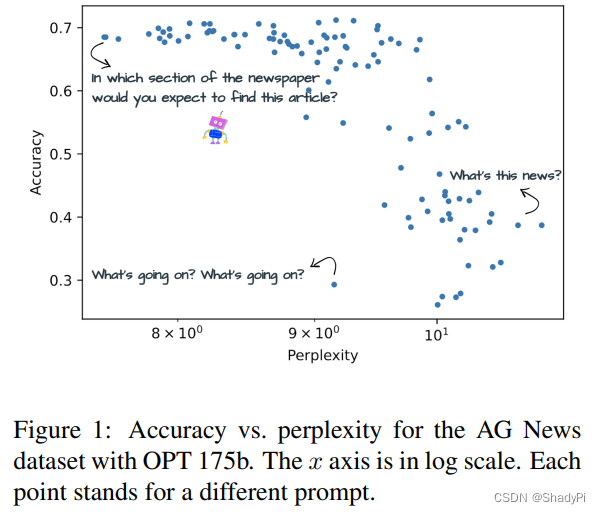
作者为了证明自己的猜想,先手写了少量人工prompt,之后交给LLM paraphrase,包括用命令让LLM直接重写以及来回翻译(翻译成别的语言再翻译回来),从而得到了大量prompt。作者之后测试了这些prompt的性能,并计算了困惑度和表现得相似度,基本都是负相关。
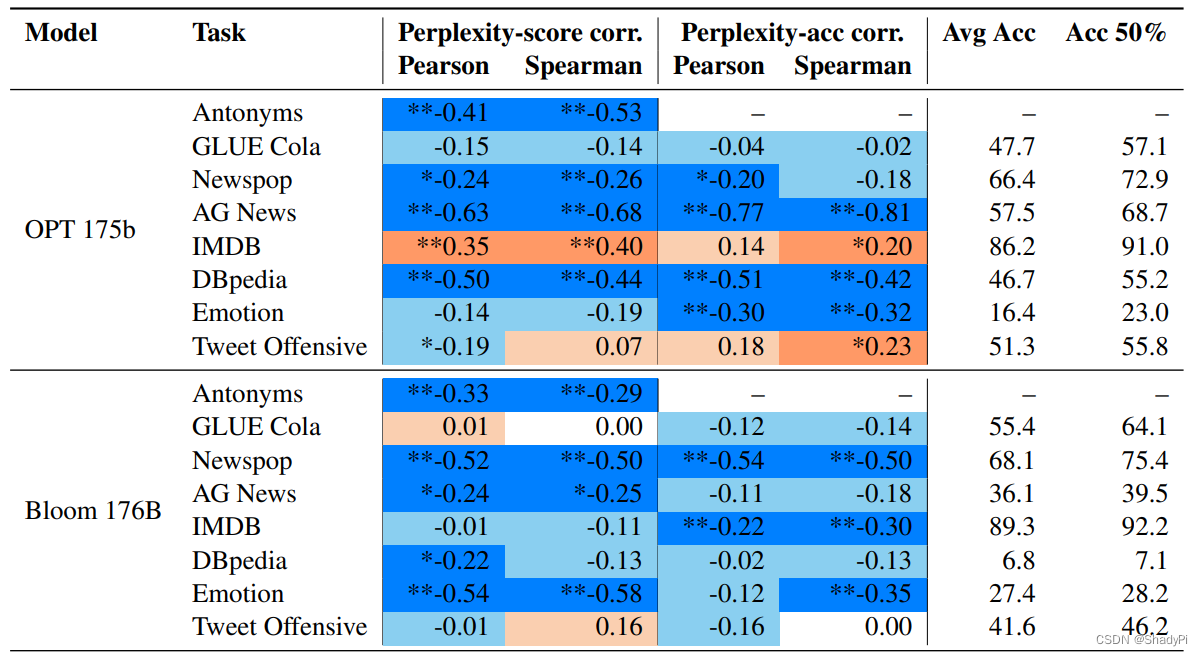
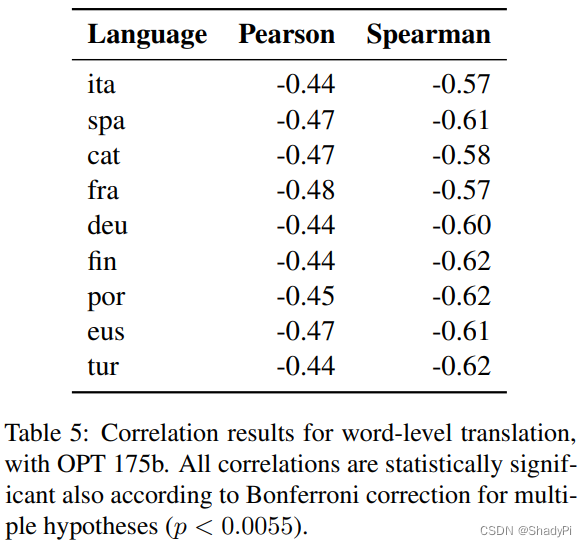
基于此,作者提出了一种新的prompt方式,也就是先手写,再paraphrase,最后根据困惑度筛选。
