MySQL强化关键_018_MySQL 优化手段及性能分析工具
目 录
一、优化手段
二、SQL 性能分析工具
1.查看数据库整体情况
(1)语法格式
(2)说明
2.慢查询日志
(1)说明
(2)开启慢查询日志功能
(3)实例
3.show profiles
(1)语法格式
(2)实例
4.explain
(1)id
(2)select_type
(3)type
(4)possible_keys
(5)key
(6)key_len
(7)rows
(8)Extra
一、优化手段
MySQL 优化手段包括但不限于:
- SQL 查询优化:成本最低,通过优化查询语句、适当添加索引等方式进行;
- 数据库表结构优化:通过规范化设计、优化索引和数据类型等方式进行库表结构优化,需要对数据库结构进行调整和改进;
- 系统配置优化:根据硬件和操作系统的特点,调整最大连接数、内存管理、IO调度等参数;
- 硬件优化:成本较高,升级硬盘、增加内存容量、升级处理器等硬件方面。
二、SQL 性能分析工具
1.查看数据库整体情况
(1)语法格式
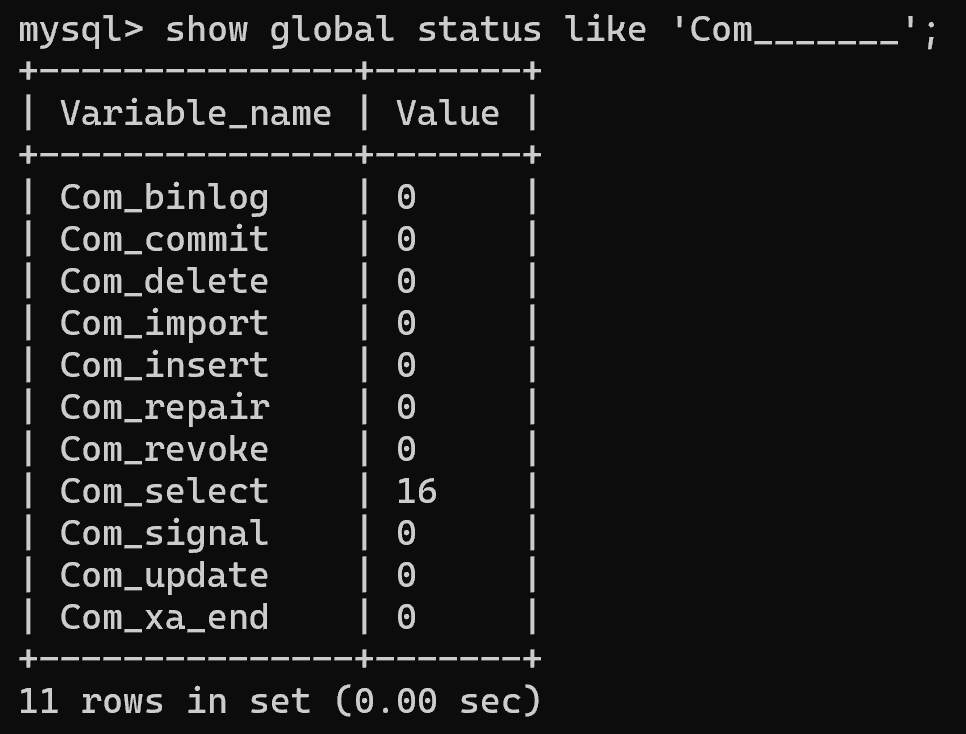
show global status like 'Com_select';show global status like 'Com_insert';show global status like 'Com_update';show global status like 'Com_delete';show global status like 'Com_______';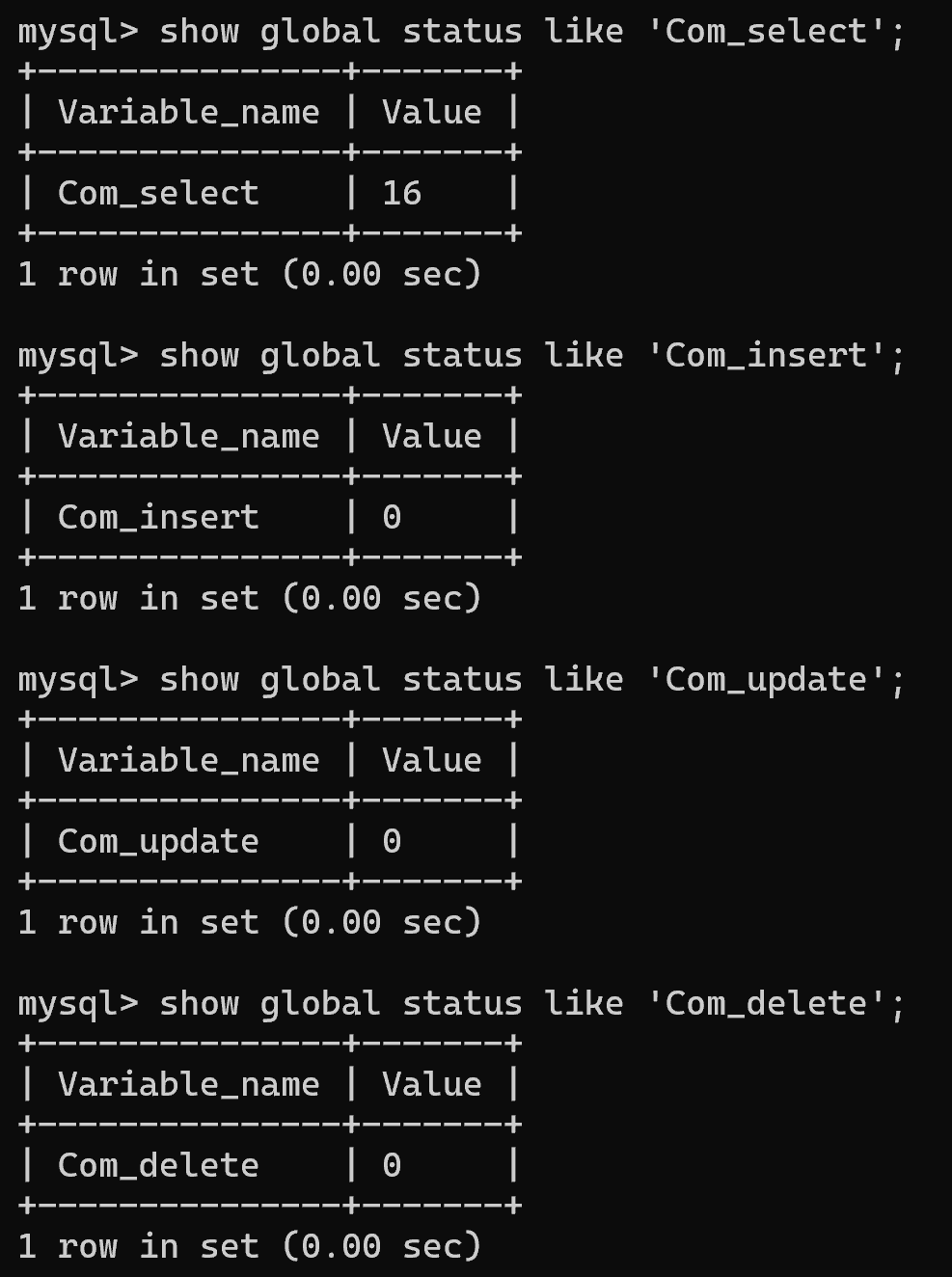
(2)说明
- 这些结果反映了从 MySQL 服务器启动到当前时刻,所有 SQL 执行总数;
- 对于 MySQL 性能优化而言,通过查看【Com_select】的值可以了解 SELECT 查询在整个 MySQL 服务期间所占比例;
- 若【Com_select】值较高,表示该数据库是读密集型数据库;
- 若【Com_select】值较低,同时【Com_insert】、【Com_update】、【Com_delete】值较高,表示该数据库是写密集型数据库。
2.慢查询日志
(1)说明
- 慢查询日志可以将查询较慢的 DQL 语句记录下来,便于定位调优位置;
- 慢查询日志默认关闭,修改 MySQL 安装根目录下的 my.ini 文件开启慢查询日志功能;
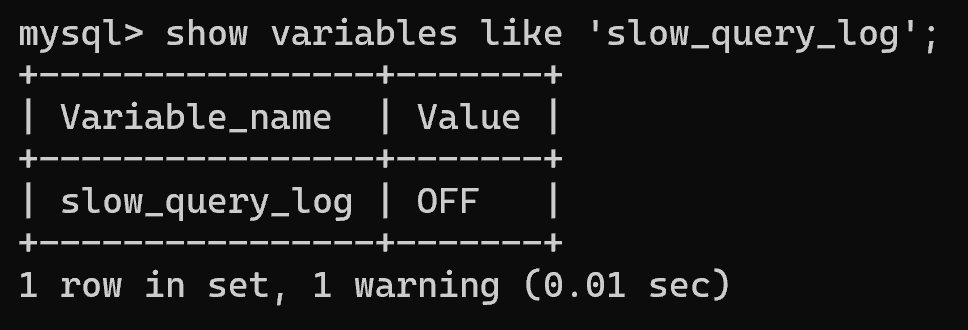
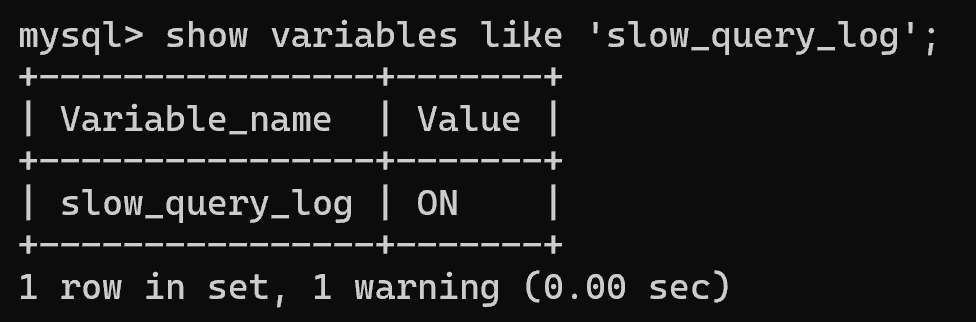
- 查看慢查询日志是否开启:【show variables like 'slow_query_log';】;
(2)开启慢查询日志功能
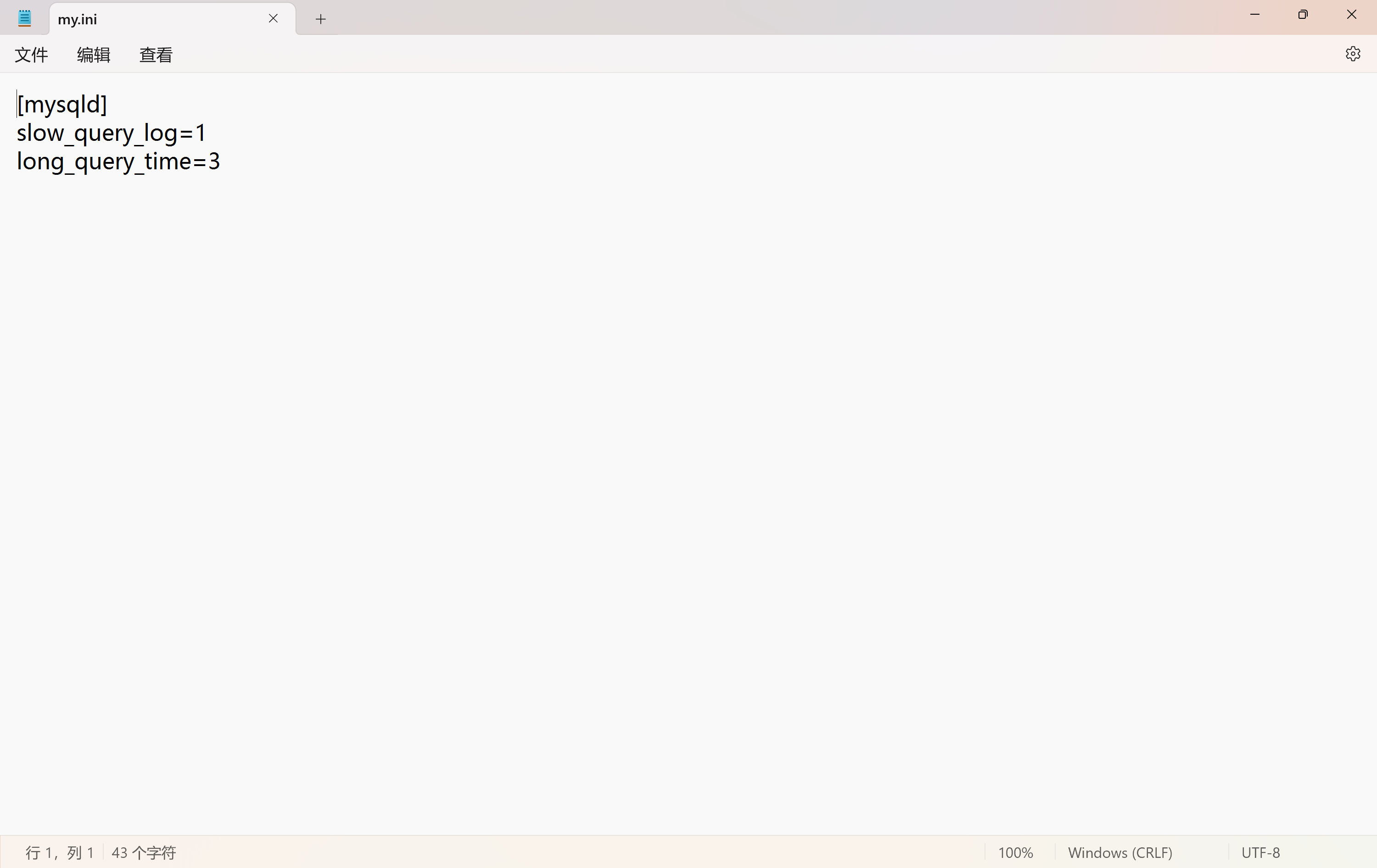
- 【slow_query_log=1】:表示开启慢查询日志功能;
- 【long_query_time=3】:表示只要 SELECT 语句执行耗时超过 3 秒就将其记录日志;
- 修改完 my.ini 需要重启 MySQL 服务;
- 慢查询日志默认存储在【[ MySQL 安装根目录下 ]\data\[ 计算机名称 ]-slow.log】;
- 查看计算机名称:在 dos 命令窗口输入【hostname】。
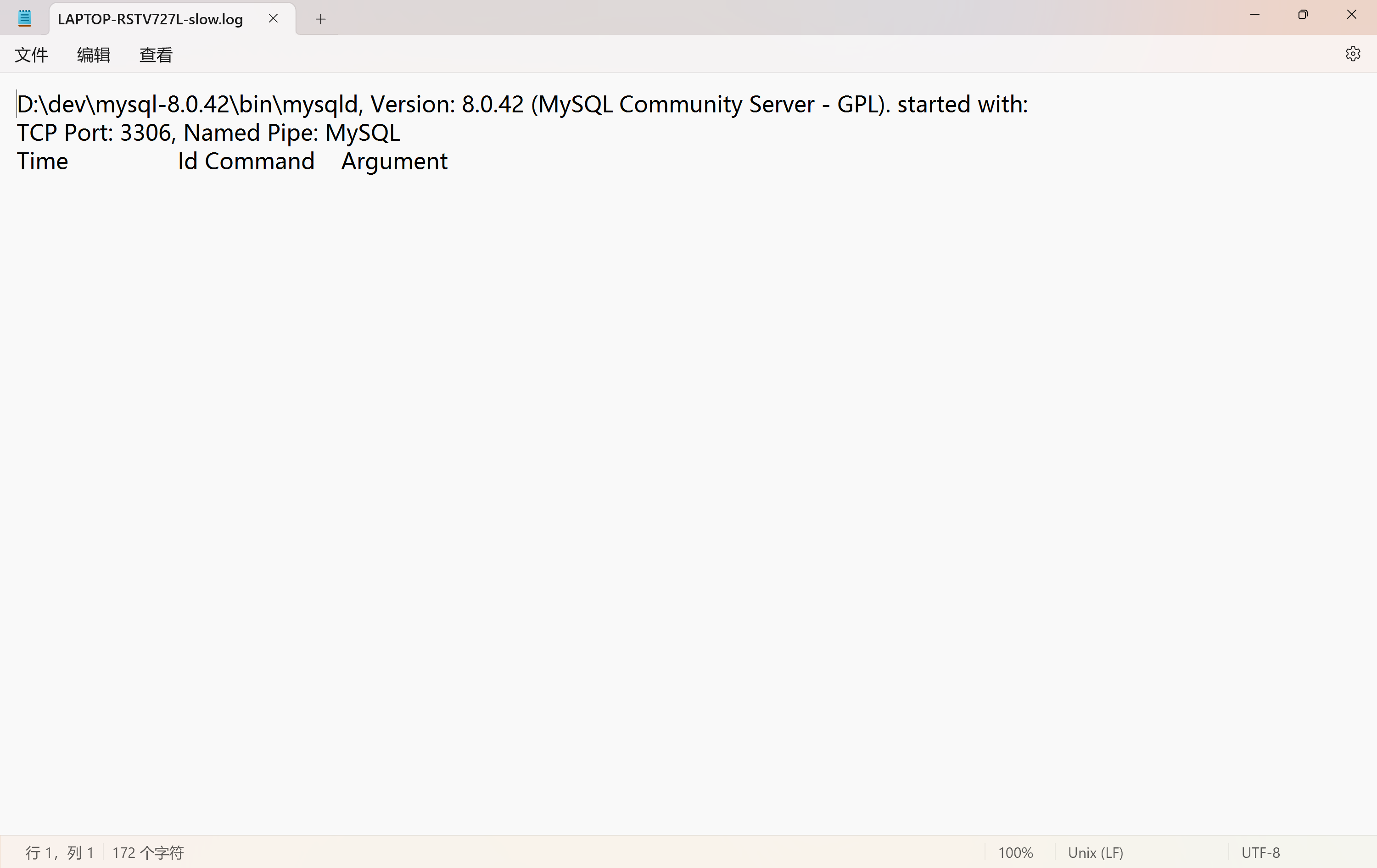
(3)实例
# 为演示慢查询日志记录,先创建一个数据库表
drop table if exists test_log;create table test_log(id int
);# 插入数据
insert into test_log values(1), (2);# 借助 sleep 使查询时间超过设定值 3
select id, sleep(5) from test_log; 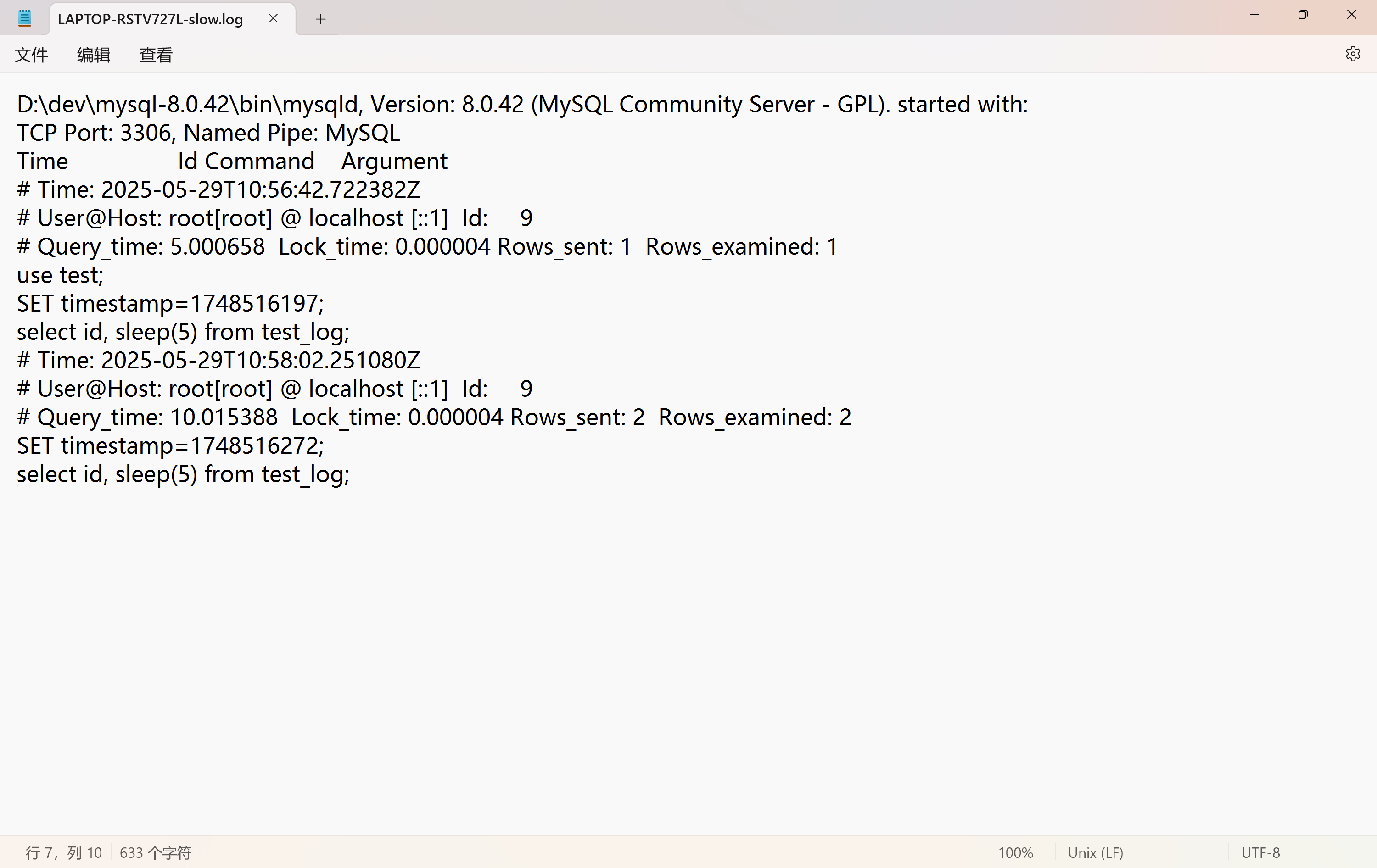
3.show profiles
可以查看一条 SQL 语句在执行过程中具体耗时情况。
(1)语法格式
# 查看当前数据库是否支持 profile 操作
select @@have_profiling;# 查看 profiling 是否开启(Navicat for MySQL 默认开启)
select @@profiling;# 开启 profiling
set profiling=1;# 查看执行过所有语句耗时情况
show profiles;
(2)实例
select * from users;
select name from users;
select * from users where gender = '女';
show profiles;# 查看具体每个阶段耗时情况(后加 id)
show profile for query 2;# 查看整个执行过程中 cpu 占用情况
show profile cpu for query 2;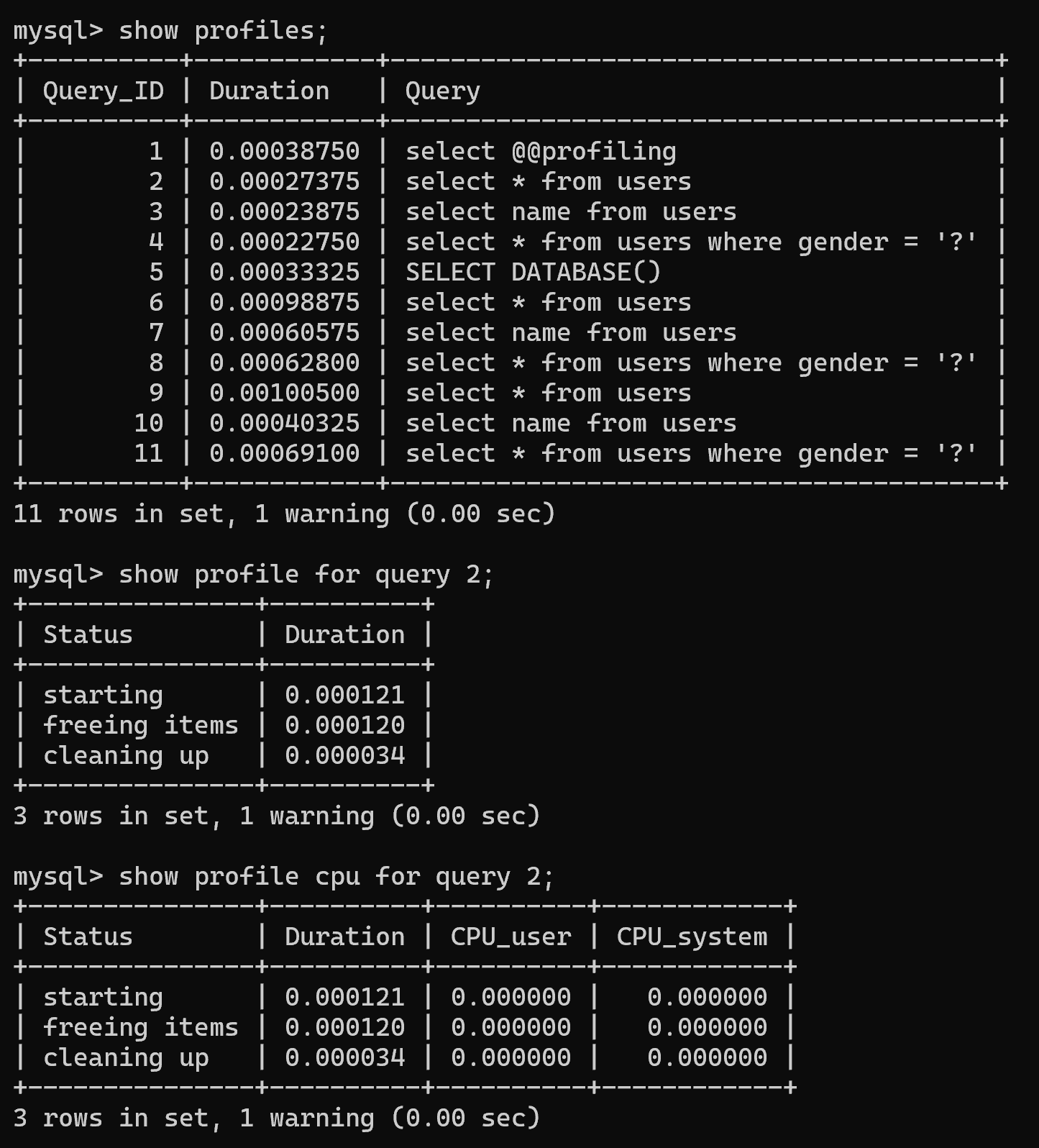
4.explain
查看一个 DQL 语句的执行计划。

(1)id
id 反映一条 DQL 语句执行顺序,id 越大优先级越高,id 相同则按照自上而下顺序执行。
explain select emp_name, dept_name from employees e join departments d on e.dept_no = d.dept_no where e.salary = (select salary from employees where emp_name = 'SMITH');
(2)select_type
- 反映查询语句的类型,其常用值包括:
- SIMPLE:表示查询中不包含子查询或 UNION 操作,这类查询通常是一个表或最多一个 JOIN 连接;
- PRIMARY:表示当前查询是一个主查询;
- SUBQUERY:表示当前查询是一个子查询;
- UNION:表示查询中包含 UNION 操作;
- DERIVED:表示派生表,即查询语句出现在 from 后。
(3)type
- 反映查询表中数据时的访问类型,其常用值包括:
- NULL:效率最高,一般不会优化到此级别,只有查询时没有查询表,访问类型才是 NULL;
- system:访问系统表,一般较难优化此级别;
- const:根据主键或唯一性索引查询,索引值是常量;
- eq_ref:根据主键或唯一性索引查询,索引值不是常量;
- ref:使用非唯一索引进行查询;
- range:使用了索引,扫描了索引树的一部分;
- index:使用了索引,遍历了整个索引树;
- ALL:全表扫描。
- 效率最高的是 NULL,效率最低的是 ALL。
(4)possible_keys
此查询可能用到的索引。
(5)key
实际用到的索引。
(6)key_len
反映索引在查询中使用的列,所占的总字节数。
(7)rows
查询扫描的预估计行数。
(8)Extra
与查询相关的额外信息和说明。