第五十九节:性能优化-GPU加速 (CUDA 模块)
在计算机视觉领域,实时性往往是关键瓶颈。当传统CPU处理高分辨率视频流或复杂算法时,力不从心。本文将深入探索OpenCV的CUDA模块,揭示如何通过GPU并行计算实现数量级的性能飞跃。
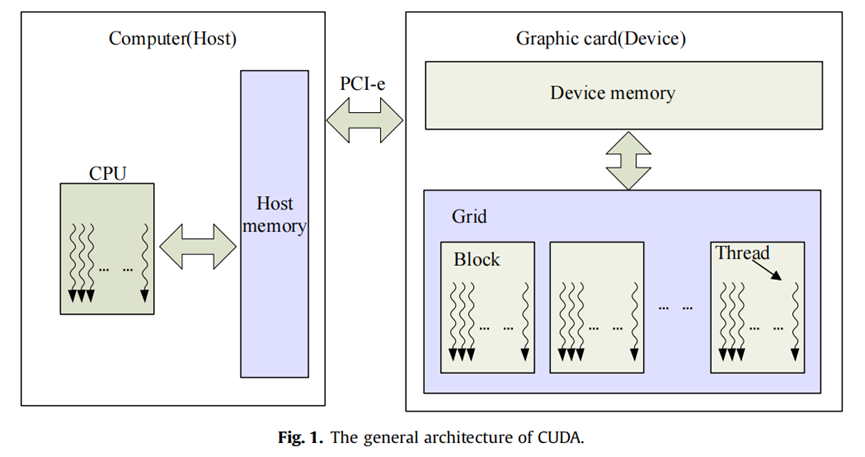
一、GPU加速:计算机视觉的必由之路
CPU的强项在于复杂逻辑和低延迟任务,但面对图像处理中高度并行的像素操作(如卷积、变换)时,其有限的物理核心成为致命短板。一块主流GPU拥有数千个CUDA核心,专为海量数据并行设计:
| 硬件类型 | 典型核心数 | 内存带宽 | 适用场景 |
|---|---|---|---|
| CPU | 4-32核 | 50GB/s | 逻辑控制、串行任务 |
| GPU | 2560-10496核 | 400-1000GB/s | 并行计算、数据密集型 |
OpenCV CUDA模块架构:
graph TDA[OpenCV Host 代码] --> B[Open