一周学会Pandas2 Python数据处理与分析-Pandas2数据合并与对比-pd.concat():轴向拼接
锋哥原创的Pandas2 Python数据处理与分析 视频教程:
2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili

在数据分析中,数据往往分散在多个来源(如不同文件、数据库表或API),需要通过合并整合为统一视图。同时,数据清洗、版本更新或业务验证时,常需对比数据差异以确保一致性。
一般有这样几种情况:
一是两份数据的列名完全相同,把其中一份数据追加到另一份的后面;
二是两份数据的列名有些不同,把这些列组合在一起形成多列;
三是以上两种情况混合。同时,在合并过程中还需要做些计算。
Pandas提供的各种功能能够轻而易举地完成这些工作。
pd.concat():轴向拼接
核心功能:
沿行(纵向)或列(横向)拼接多个 DataFrame,支持批量合并。 适用场景:结构相同的数据表合并(如多个 CSV 文件)、多维度数据堆叠。
基本语法:
pd.concat(objs, # 要合并的对象列表(如多个DataFrame)axis=0, # 合并方向:0沿行(纵向),1沿列(横向)join='outer', # 合并方式:'outer'保留所有列,'inner'保留共有列ignore_index=False, # 是否重置索引(避免重复)keys=None, # 添加层次化索引(标识来源)sort=False, # 是否对列排序
)参数详解
-
objs: 要拼接的 DataFrame 列表(必填,如
[df1, df2])。 -
axis: 拼接方向,
axis=0(默认,纵向堆叠),axis=1(横向拼接)。 -
ignore_index: 是否重置索引(默认
False,保留原索引)。 -
keys: 添加层级索引标识来源(如
keys=['A', 'B'])。 -
join: 对齐方式,
join='outer'(默认,保留所有列),join='inner'(仅共有列)。
常用场景示例
1,纵向合并(默认 axis=0)
import pandas as pddf1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})result = pd.concat([df1, df2])
2,横向合并(axis=1)
result = pd.concat([df1, df2], axis=1)
3,处理索引重复
使用 ignore_index=True 重置索引:
result = pd.concat([df1, df2], ignore_index=True)
4,仅合并共有列(join='inner')
若两个 DataFrame 列不完全一致:
df3 = pd.DataFrame({'A': [5, 6], 'C': [9, 10]})
result = pd.concat([df1, df3], join='inner') # 仅保留共有列'A'
5,添加层次化索引(keys)
标识数据来源:
result = pd.concat([df1, df2], keys=['df1', 'df2'])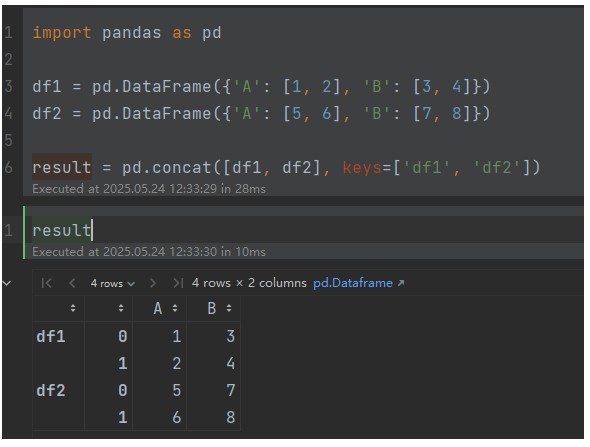
注意事项
-
索引问题:合并时默认保留原索引,可能导致重复,建议用
ignore_index=True重置。 -
列名对齐:横向合并(
axis=1)时,按行索引对齐,缺失值填充NaN。 -
性能优化:合并大量数据时,建议先预处理再合并,避免内存不足。