华为昇腾使用ollama本地部署DeepSeek大模型
文章目录
- 前言
- 一、本次使用的硬件资源
- 二、Ollama介绍
- 三、Ollama在arm64位的芯片的安装及使用方法
- 总结
前言
本次打算在华为昇腾上面使用ollama进行部署DeepSeek大模型。
一、本次使用的硬件资源
存储资源

内存资源

cpu资源

二、Ollama介绍
Ollama 是一个开源的大型语言模型(LLM)平台,旨在让用户能够轻松地在本地运行、管理和与大型语言模型进行交互。以下是关于 Ollama 的详细介绍:
核心功能与特点
1.多种预训练语言模型支持:Ollama 提供了多种开箱即用的预训练模型,如 Llama3.1、Gemma2、Qwen2 等,用户可以轻松加载并使用这些模型进行文本生成、情感分析、问答等任务。
2,易于集成和使用:Ollama 提供了命令行工具(CLI)和 Python SDK,简化了与其他项目和服务的集成。开发者无需担心复杂的依赖或配置,可以快速将 Ollama 集成到现有的应用中。
3.本地部署与离线使用:Ollama 允许开发者在本地计算环境中运行模型,脱离对外部服务器的依赖,保证数据隐私,并且对于高并发的请求,离线部署能提供更低的延迟和更高的可控性。
4.支持模型微调与自定义:用户不仅可以使用 Ollama 提供的预训练模型,还可以在此基础上进行模型微调。根据自己的特定需求,开发者可以使用自己收集的数据对模型进行再训练,从而优化模型的性能和准确度。
5.性能优化:Ollama 关注性能,提供了高效的推理机制,支持批量处理,能够有效管理内存和计算资源。这让它在处理大规模数据时依然保持高效。
6.跨平台支持:Ollama 支持在多个操作系统上运行,包括 Windows、macOS 和 Linux。这样无论是开发者在本地环境调试,还是企业在生产环境部署,都能得到一致的体验。
7.开放源码与社区支持:Ollama 是一个开源项目,这意味着开发者可以查看源代码,进行修改和优化,也可以参与到项目的贡献中。此外,Ollama 有一个活跃的社区,开发者可以从中获取帮助并与其他人交流经验。
Ollama开源git地址
ollama下载地址
三、Ollama在arm64位的芯片的安装及使用方法
可以使用下面这条命令一键安装
curl -fsSL https://ollama.com/install.sh | sh
也可以进行手动安装
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
这里需要换成ARM64位的版本
curl -L https://ollama.com/download/ollama-linux-arm64.tgz -o ollama-linux-arm64.tgz
sudo tar -C /usr -xzf ollama-linux-arm64.tgz
使用虚拟机下载ARM64位的安装包版本。

将下载的ARM64位的版本通过U盘拷贝至华为昇腾芯片上面。
解压至指定的文件夹,这一步会进行自动安装。

tar -C ollama -xzf ollama-linux-arm64.tgz
可以查看一下ollama的目录结构

Ollama的版本信息

然后启动ollama服务

在服务开启的情况下使用ollama list可以查看当前使用ollama下载的模型文件。

llama可以支持的大预言模型可以通过如下链接地址进行查看
根据本次的硬件资源,我们选择列表中的deepseek-r1大模型


等待校验结束进入命令行。

进入命令行进行测试使用。

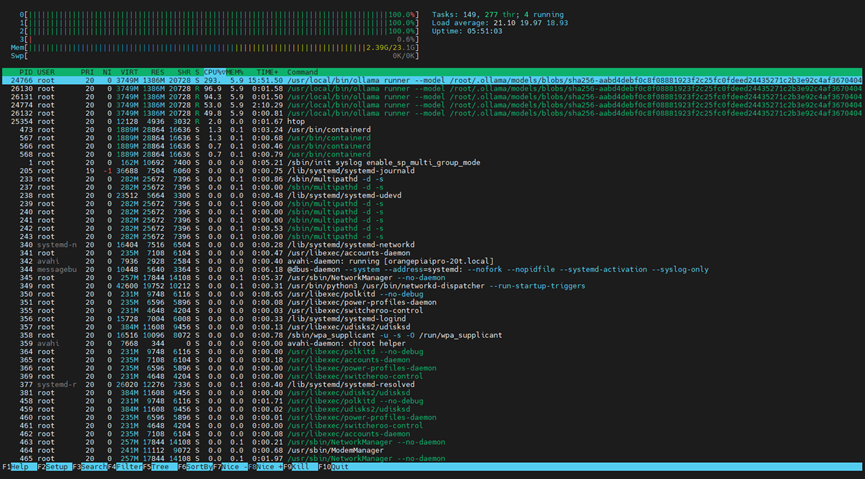
可以看见初步尝试很卡顿。这个模型在端侧的部署。


基本上CPU的使用率已经跑满了。
总结
本次使用华为昇腾用ollama部署适配deepseek的入门轻量级deepseek-r1:1.5b大模型。进行一个简单的模型部署尝试。实际运行这个入门版的参数量,芯片的CPU的占用率很高。速度比较慢。