【论文笔记】图像修复Learning Joint Spatial-Temporal Transformations for Video Inpainting
论文地址:https://arxiv.org/abs/2007.10247
源码地址:GitHub - researchmm/STTN: [ECCV'2020] STTN: Learning Joint Spatial-Temporal Transformations for Video Inpainting
一、项目介绍
当下SITA的方法大多采用注意模型,通过搜索参考帧中缺失的内容来完成一帧,并进一步逐帧完成整个视频。然而,这些方法在空间和时间维度上的注意结果可能会不一致,这往往会导致视频中的模糊和时间伪影。
本文提出时空转换网络STTN(Spatial-Temporal Transformer Network)。具体来说,是通过自注意机制同时填补所有输入帧中的缺失区域,并提出通过时空对抗性损失来优化STTN。为了展示该模型的优越性,我们使用标准的静止掩模和更真实的运动物体掩模进行了定量和定性的评价。
二、STTN
模型输入是图像帧序列和masks序列,图像帧序列经过Encoder、Mask经过scale变化成原来的1/4,然后一起送入Spatial-Temporal Transformer模块;Spatial-Temporal Transformer模块由8个TransformerBlock组成;最后Decoder模块负责将特征还原成图像帧序列。STTN的整体结构图如下:
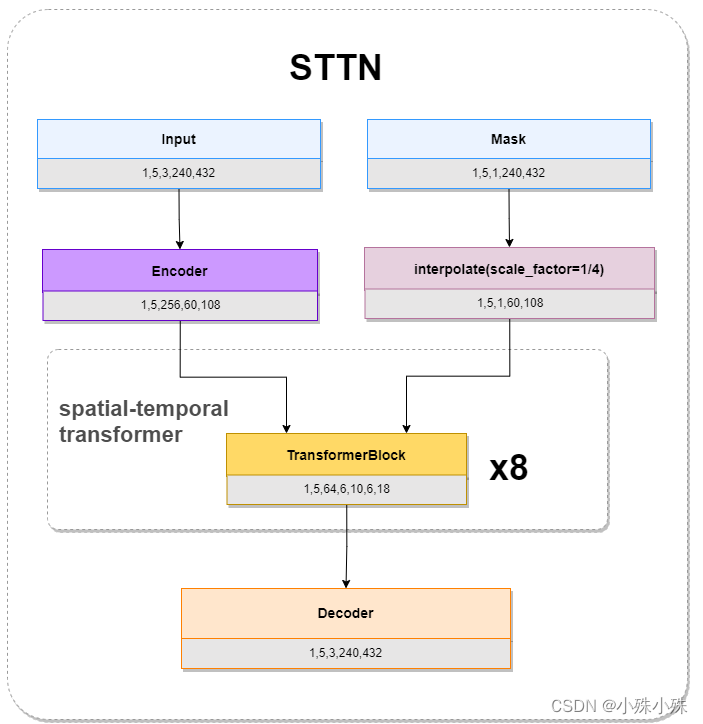
图1
1.Encoder
Frame-Level Encoder帧级编码器,通过叠加二维卷积层来构建的,目的是为每一帧的低级别像素的深度特征,就是四个卷积层提取单帧图像特征,要素不多,结构图如下:

图2
代码如下:
# 位置model/sttn.py
self.encoder = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(128, channel, kernel_size=3, stride=1, padding=1),nn.LeakyReLU(0.2, inplace=True),)2.Spatial-Temporal Transformer Network
这是STTN的核心部分,通过一个多头 patch-based attention模块沿着空间和时间维度进行搜索。transformer的不同头部计算不同尺度上对空间patch的注意力。这样的设计允许我们处理由复杂的运动引起的外观变化。例如,对大尺寸的patch(例如,帧大小H×W)旨在修复固定的背景;对小尺寸的patch(如H/10×W/10)有助于在视频的任意位置捕捉移动的前景信息。
(1)TranformerBlock
TransformerBlock由Embedding、Matching和Attending组成,代码中Matching和Attending被放在一起合成了MultiHeadedAttention。输入是帧序列特征和masks。
帧序列的特征平分成四部分,每个部分经过Embedding映射为四种尺度的Key、Query、Value,从而对应不同尺度的patch。masks经过变换也变成四个尺度。将四个尺度的Key、Query、Value和四个尺度masks分别送入MultiHeadedAttention,然后将结果Concat到一起,经过FeedForward层进一步分特征融合,得到融合了时间维度上不同尺度空间patch的特征。结构图如下:

图3
代码如下:
# 位置model/sttn.py
class TransformerBlock(nn.Module):"""Transformer = MultiHead_Attention + Feed_Forward with sublayer connection"""def __init__(self, patchsize, hidden=128):super().__init__()self.attention = MultiHeadedAttention(patchsize, d_model=hidden)self.feed_forward = FeedForward(hidden)def forward(self, x):x, m, b, c = x['x'], x['m'], x['b'], x['c']x = x + self.attention(x, m, b, c)x = x + self.feed_forward(x)return {'x': x, 'm': m, 'b': b, 'c': c}(2)KQV Formatting
图3中的KQV Formatting结构如下图:
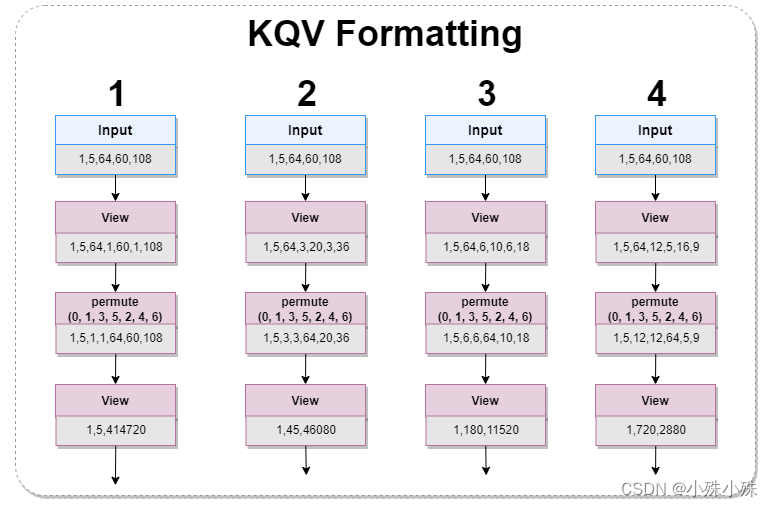
图4
TranformerBlock输入的帧序列特征,被平分成四个部分,每个部分经过变换,变成四种尺度patch的特征。
代码如下:
# 位置model/sttn.py
query = query.view(b, t, d_k, out_h, height, out_w, width)
query = query.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(b, t*out_h*out_w, d_k*height*width)
key = key.view(b, t, d_k, out_h, height, out_w, width)
key = key.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(b, t*out_h*out_w, d_k*height*width)
value = value.view(b, t, d_k, out_h, height, out_w, width)
value = value.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(b, t*out_h*out_w, d_k*height*width)(3)Mask Formatting
KQV Formatting将帧序列变成四种尺度,masks也需要对应的变成四种尺度,结构如下:
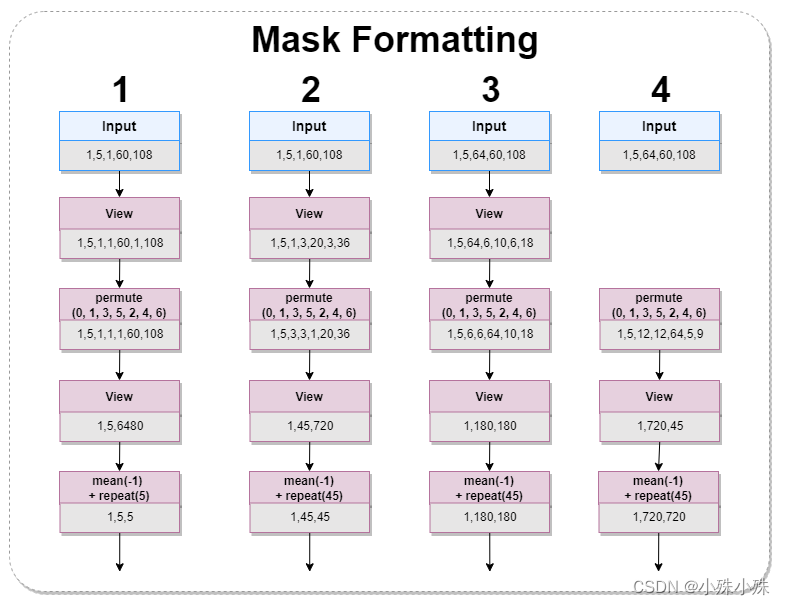
图5
代码如下:
# 位置model/sttn.py
mm = m.view(b, t, 1, out_h, height, out_w, width)
mm = mm.permute(0, 1, 3, 5, 2, 4, 6).contiguous().view(b, t*out_h*out_w, height*width)
mm = (mm.mean(-1) > 0.5).unsqueeze(1).repeat(1, t*out_h*out_w, 1)(4)Attention
图3中的Attention层其实包括了论文中的Matching和Attending,结构图如下:
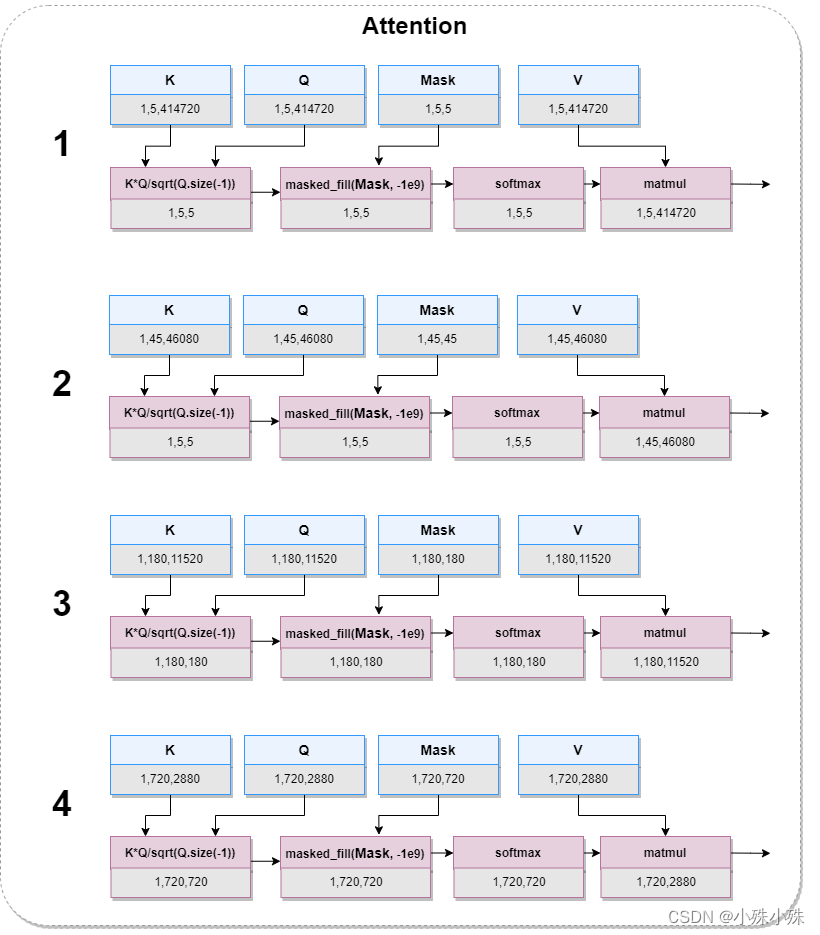
图6
图6中的K*Q/sqrt(Q.size(-1))是在计算各个patch的相似性,对应论文中公式,第i个斑块与第j个patch的相似性记为::

图6中的masked_fill(Mask, -1e9)是将图像中的损坏部分mask掉,意思是只学习图像中完整的部分,坏的就不要学习了。
论文中的Attention对应图6中的matmul,负责计算相关patches的value加权和得到输出patch的query。公式如下:

代码如下:
# 位置model/sttn.py
class Attention(nn.Module):"""Compute 'Scaled Dot Product Attention"""def forward(self, query, key, value, m):scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(query.size(-1))scores.masked_fill(m, -1e9)p_attn = F.softmax(scores, dim=-1)p_val = torch.matmul(p_attn, value)return p_val, p_attn3.Decoder
frame-level decoder: 帧级解码器,把特征解码成帧。期间特征图经过了两次的膨胀,中间穿插几个2d卷积,整体过程有点像Encoder倒过来,结构图如下:
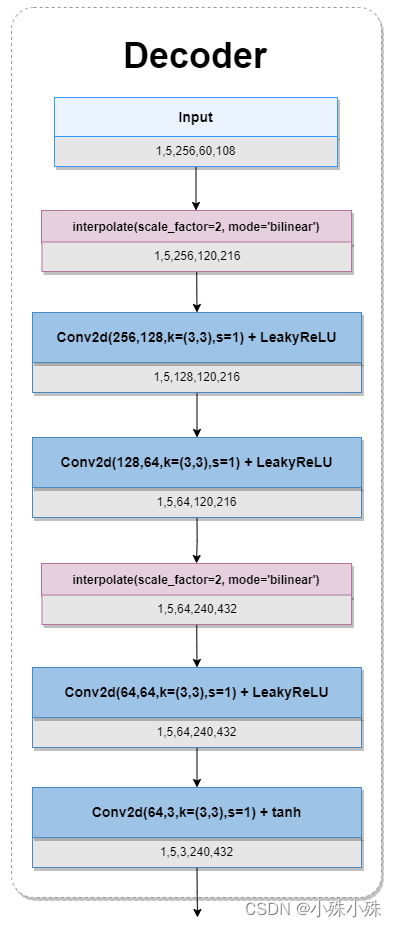
图7
代码如下:
# 位置model/sttn.py
self.decoder = nn.Sequential(deconv(channel, 128, kernel_size=3, padding=1),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(128, 64, kernel_size=3, stride=1, padding=1),nn.LeakyReLU(0.2, inplace=True),deconv(64, 64, kernel_size=3, padding=1),nn.LeakyReLU(0.2, inplace=True),nn.Conv2d(64, 3, kernel_size=3, stride=1, padding=1))三、损失函数
本文使用GAN来对模型进行优化,G模型选择了一个像素级的重建损失即L1Loss,D网络使用T-PatchGAN来优化。
1.G模型损失函数
G模型图像破坏区域的L1Loss:

G模型图像有效区域的L1Loss:

STTN的对抗性损失:

上式看上去很复杂,其实就是将恢复的图像送入D模型,然后送入损失函数(可选nsgan、lsgan、hinge)
总结上面三个式子,得出G模型的损失函数,其中三个权重官方推荐
![]()
2.D网络的损失函数
对抗性的损失在提高视频绘制的感知质量和时空一致性方面显示出了良好的效果。公式如下:

看山去还是很复杂,其实就是将原图和复原图分别送入损失函数(可选nsgan、lsgan、hinge),然后求和,代码中是取均值,不过应该影响不大。
三、训练流程
下面是我根据官方代码梳理的整个训练过程:
1.从数据集选取数据,同时为选取的数据随机带有破坏图案的masks
2.根据masks将原图的破坏部分变成0,得到masked_frame
3.将masked_frame和masks送入G模型(生成模型,即STTN),得出估计pred_img
4.根据pred_img修复图像,得到comp_img
5.将原图和comp_img分别送入D模型,分别得到输出的特征 real_vid_feat和fake_vid_feat
6.使用real_vid_feat和fake_vid_feat对D模型进行优化(损失函数可选nsgan、lsgan、hinge)
7.使用原图、comp_img和gen_vid_feat对G模型进行优化(L1Loss)
代码如下:
# 位置core/trainer.pydef _train_epoch(self, pbar):device = self.config['device']for frames, masks in self.train_loader:self.adjust_learning_rate()self.iteration += 1frames, masks = frames.to(device), masks.to(device)b, t, c, h, w = frames.size()masked_frame = (frames * (1 - masks).float())# 将masked_frame和masks送入G模型(生成模型,即STTN),得出估计pred_imgpred_img = self.netG(masked_frame, masks)frames = frames.view(b*t, c, h, w)masks = masks.view(b*t, 1, h, w)# 根据pred_img修复图像,得到comp_imgcomp_img = frames*(1.-masks) + masks*pred_imggen_loss = 0dis_loss = 0# 将原图和comp_img分别送入D模型,分别得到输出的特征 real_vid_feat和fake_vid_featreal_vid_feat = self.netD(frames)fake_vid_feat = self.netD(comp_img.detach())# 计算D网络的损失dis_real_loss = self.adversarial_loss(real_vid_feat, True, True)dis_fake_loss = self.adversarial_loss(fake_vid_feat, False, True)dis_loss += (dis_real_loss + dis_fake_loss) / 2self.add_summary(self.dis_writer, 'loss/dis_vid_fake', dis_fake_loss.item())self.add_summary(self.dis_writer, 'loss/dis_vid_real', dis_real_loss.item())self.optimD.zero_grad()dis_loss.backward()# 使用real_vid_feat和fake_vid_feat对D模型进行优化self.optimD.step()# G模型的对抗性损失gen_vid_feat = self.netD(comp_img)gan_loss = self.adversarial_loss(gen_vid_feat, True, False)gan_loss = gan_loss * self.config['losses']['adversarial_weight']gen_loss += gan_lossself.add_summary(self.gen_writer, 'loss/gan_loss', gan_loss.item())# G模型图像破坏区域的L1Losshole_loss = self.l1_loss(pred_img*masks, frames*masks)hole_loss = hole_loss / torch.mean(masks) * self.config['losses']['hole_weight']gen_loss += hole_loss self.add_summary(self.gen_writer, 'loss/hole_loss', hole_loss.item())# G模型图像有效区域的L1Lossvalid_loss = self.l1_loss(pred_img*(1-masks), frames*(1-masks))valid_loss = valid_loss / torch.mean(1-masks) * self.config['losses']['valid_weight']gen_loss += valid_loss self.add_summary(self.gen_writer, 'loss/valid_loss', valid_loss.item())self.optimG.zero_grad()gen_loss.backward()# 使用原图、comp_img和gen_vid_feat对G模型进行优化self.optimG.step()# 日志if self.config['global_rank'] == 0:pbar.update(1)pbar.set_description((f"d: {dis_loss.item():.3f}; g: {gan_loss.item():.3f};"f"hole: {hole_loss.item():.3f}; valid: {valid_loss.item():.3f}"))# saving modelsif self.iteration % self.train_args['save_freq'] == 0:self.save(int(self.iteration//self.train_args['save_freq']))if self.iteration > self.train_args['iterations']:break接下来代码中有些重点,需要简单说明一下:
1.准备数据集
项目中用到Davis或youtube-vos数据集,两个数据集其实都是为segmentation任务设计的,代码中都只使用图像数据,不使用标注数据。我们以davis数据集为例,davis数据集由90个视频组成,每个视频已经拆帧成图片,数据集下载完每个视频一个文件夹,但是程序需要每个视频这图片打成zip文件,下面的程序可以用来完成这个工作:
import os
import zipfiledef zipDir(dirpath, out_full_name):zipname = zipfile.ZipFile(out_full_name, 'w', zipfile.ZIP_DEFLATED)for path, dirnames, filenames in os.walk(dirpath):fpath= path.replace(dirpath, '')for filename in filenames:zipname.write(os.path.join(path, filename), os.path.join(fpath, filename))zipname.close()if __name__=="__main__":org_dir = r'datasets/davis/JPEGImages_org'zip_dir = r'datasets/davis/JPEGImages'g = os.walk(org_dir)for path, dir_list, file_list in g:for dir_name in dir_list:input_path = os.path.join(path, dir_name)output_path = os.path.join(zip_dir, dir_name+'.zip')print(input_path, '\n', output_path)zipDir(input_path, output_path)2.数据选取策略
数据是从90个视频中随机挑一个,然后在这个视频中选取sample_length张图片,最终每个视频都会选取一个图片组,在论文中提到有两种数据选取策略,就是下面这个公式:

其中代表以t为中心n为半径的连续帧序列,代码实现是50%概率用一个长度为sample_length的框随机滑动选取;
表示从以s采样率的视频
中均匀采样的远处帧,代码中并未使用这种方式,而是50%概率随机选取帧,这样也许是为了解决缓解数据不够多的问题。
选图片组的代码如下:
# 位置:core/dataset.py
def get_ref_index(length, sample_length):# 50%概率随机选取帧if random.uniform(0, 1) > 0.5:ref_index = random.sample(range(length), sample_length)ref_index.sort()else:# 50%概率用一个长度为sample_length的框随机滑动选取pivot = random.randint(0, length-sample_length)ref_index = [pivot+i for i in range(sample_length)]return ref_index3.生成随机masks
有了图片组,还需要为每个图片组随机生成masks。其中0代表背景,1代表破坏部分。代码如下,注释已经很清楚:
# 位置:core/utils.py
def create_random_shape_with_random_motion(video_length, imageHeight=240, imageWidth=432):# 生成的破坏图案宽高占原图的1/3到100%height = random.randint(imageHeight//3, imageHeight-1)width = random.randint(imageWidth//3, imageWidth-1)# 生成不规则的破坏图案edge_num = random.randint(6, 8)ratio = random.randint(6, 8)/10region = get_random_shape(edge_num=edge_num, ratio=ratio, height=height, width=width)region_width, region_height = region.size# 随机放置破坏图案x, y = random.randint(0, imageHeight-region_height), random.randint(0, imageWidth-region_width)velocity = get_random_velocity(max_speed=3)m = Image.fromarray(np.zeros((imageHeight, imageWidth)).astype(np.uint8))m.paste(region, (y, x, y+region.size[0], x+region.size[1]))masks = [m.convert('L')]# 50%概率所有的mask一样if random.uniform(0, 1) > 0.5:return masks*video_length# 50%概率mask中的破坏图案会移动for _ in range(video_length-1):x, y, velocity = random_move_control_points(x, y, imageHeight, imageWidth, velocity, region.size, maxLineAcceleration=(3, 0.5), maxInitSpeed=3)m = Image.fromarray(np.zeros((imageHeight, imageWidth)).astype(np.uint8))m.paste(region, (y, x, y+region.size[0], x+region.size[1]))masks.append(m.convert('L'))return masks