RNNLSTM
文章目录
- 前言
- 引言
- 应用示例-槽填充(slot filling)-订票系统
- 二、循环神经网络(RNN)
- 三、Long Short-term Memory (LSTM)
- LSTM原理
- [总结](https://zhuanlan.zhihu.com/p/42717426)
- LSTM例子
- lstm的训练
- RNN不但可以N2N
- Many2One(输入是一个矢量序列,但输出只有一个矢量)
- Many2Many(Output is shorter)
- 多对多(不限)
前言
- LSTM——起源、思想、结构 与“门”
- 完全图解RNN、RNN变体、Seq2Seq、Attention机制
- 完全解析RNN, Seq2Seq, Attention注意力机制
- Sequence to sequence入门详解:从RNN, LSTM到Encoder-Decoder, Attention, transformer
- 从RNN到Attention到Transformer系列-Attention介绍及代码实现
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
引言
应用示例-槽填充(slot filling)-订票系统
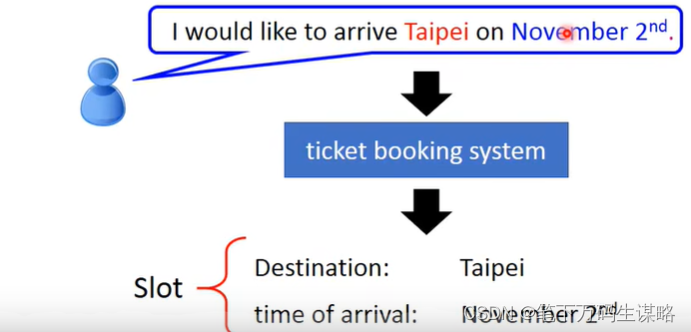
将句子输入给系统,系统将关键信息放到相应的槽内。
这个问题可以用前馈网络(Feedward network)?
输入: 一个词(每一个词都可以用一个向量表示)
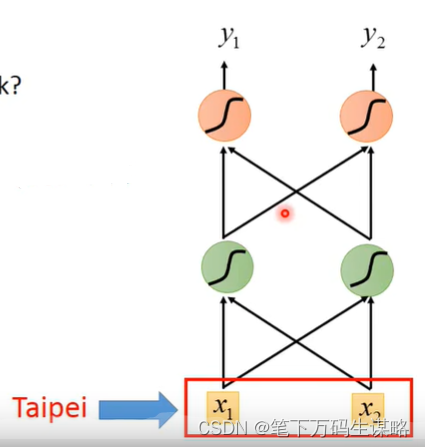
怎么把一个词汇用一个向量表示呢?
- 1-of-N encoding

- Beyond 1-of-N encoding
-
Dimension of ‘Other’
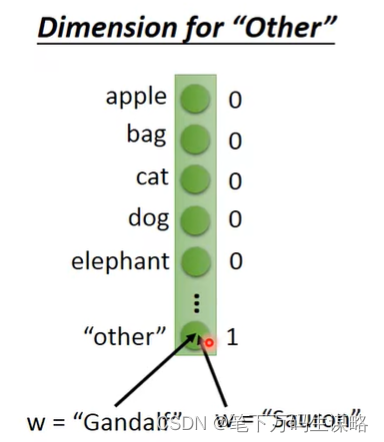
-
Word hashing
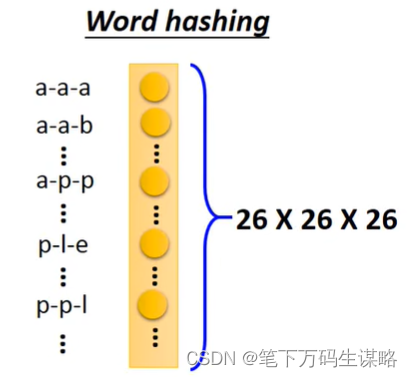
输出: 输入词汇属于每个槽的几率
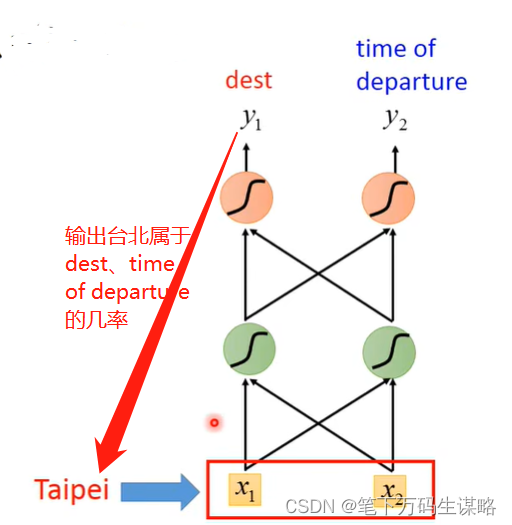
但是同一个词在不同语句中的语义可能不同
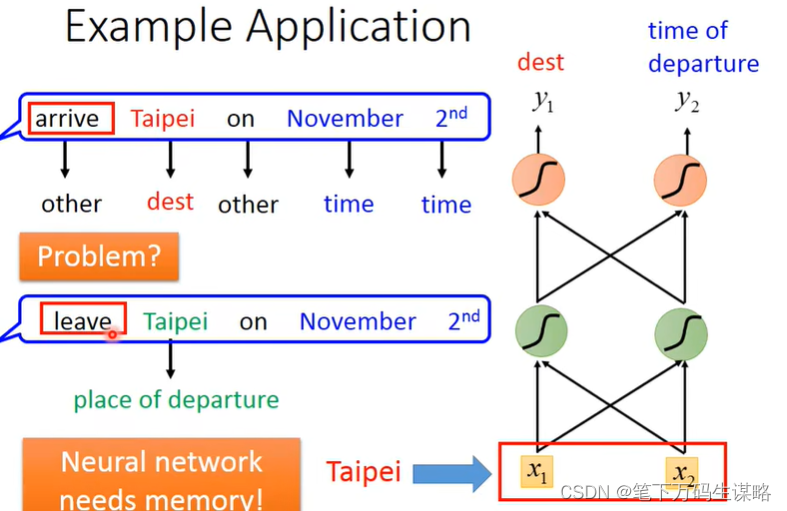
如果我们的网络有记忆力的话就可以根据上下文产生不同的输出。
二、循环神经网络(RNN)
隐层的输出会被存到memory里,memory会作为下一次的输入。
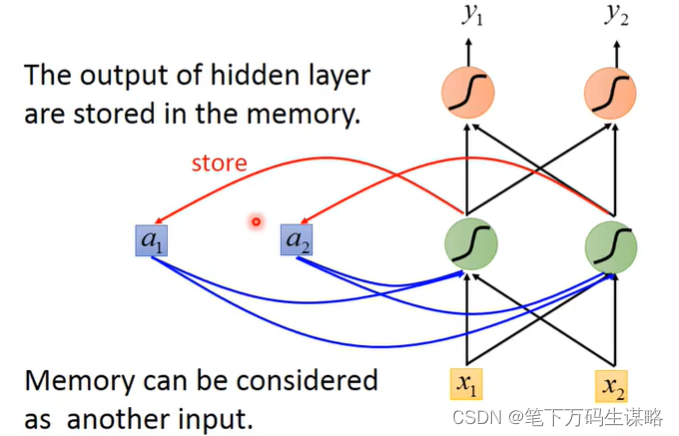
下面举一个例子:
假设所有的权重都是“1”,没有偏差;所有激活函数都是线性的。
输入序列:
[ 1 1 ] [ 1 1 ] [ 2 2 ] . . . \begin{bmatrix} 1 \\ 1 \\ \end{bmatrix} \begin{bmatrix} 1 \\ 1 \\ \end{bmatrix} \begin{bmatrix} 2 \\ 2 \\ \end{bmatrix} ... [11][11][22]...
1.给memory初始值,eg. [0, 0], 输入 [1, 1]
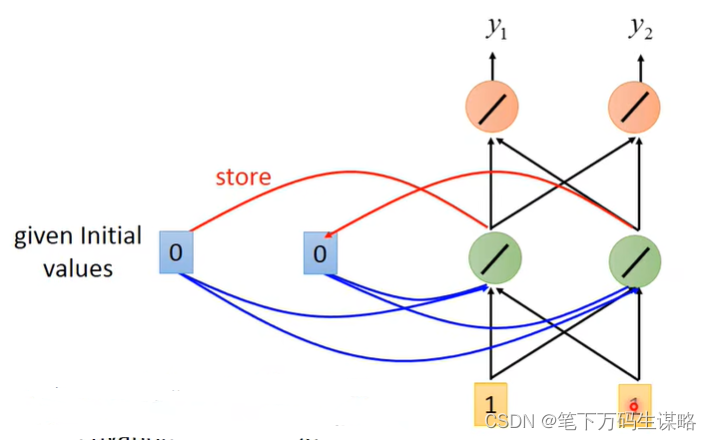
输出 [4, 4]
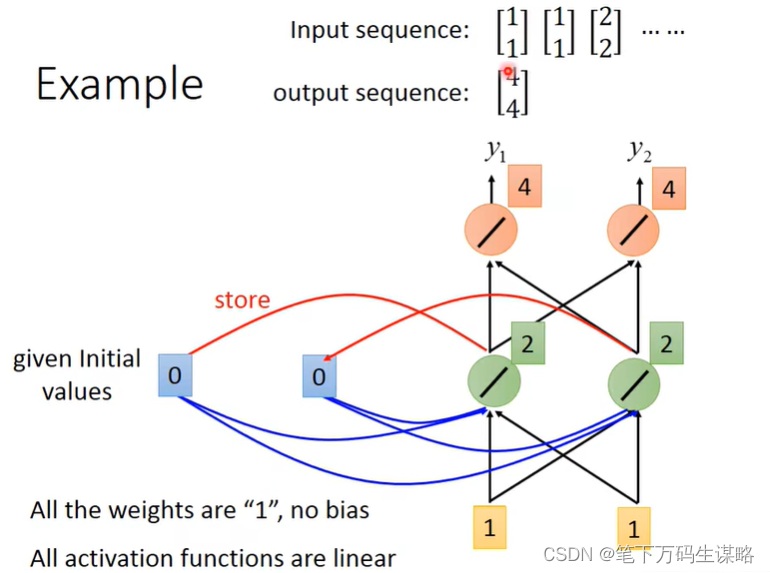
2.更新memory, [2, 2], 在输入 [1, 1]
输出 [12,12]
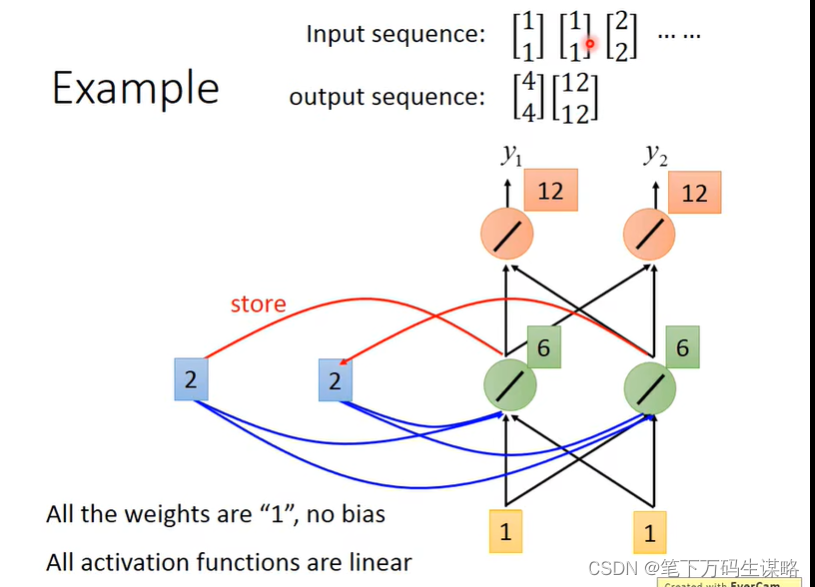
2.更新memory, [6, 6], 在输入 [2, 2]
输出 [32,32]
memory变为[16, 16]
改变序列顺序将会改变输出。
所以我们要用RNN处理slot filling的问题的话:
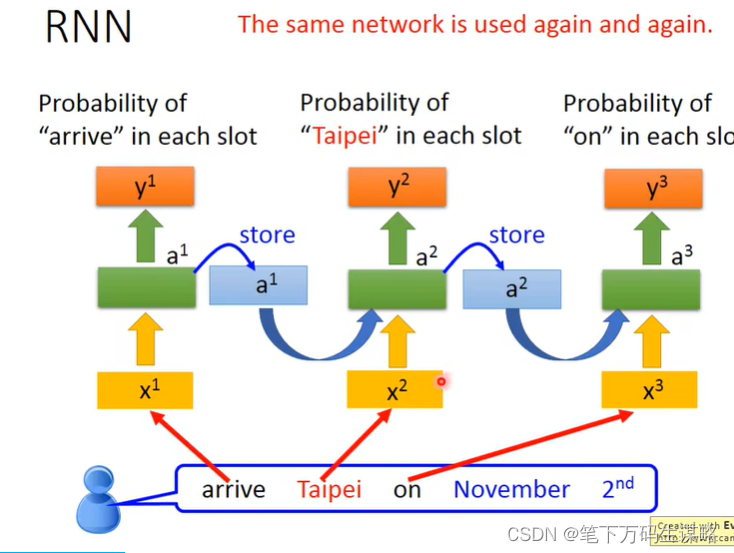
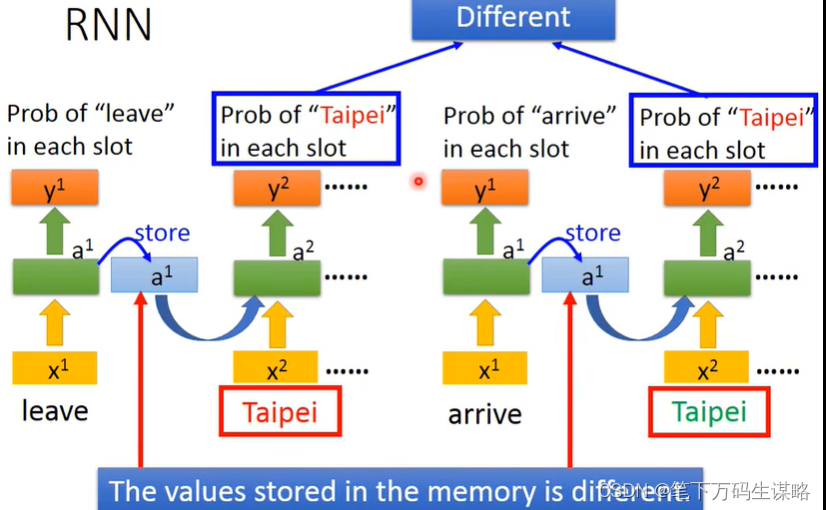
由于存入的memory不一样,导致相同词的输出不一样。
当然上面是原理,RNN的架构我们可以自己设计
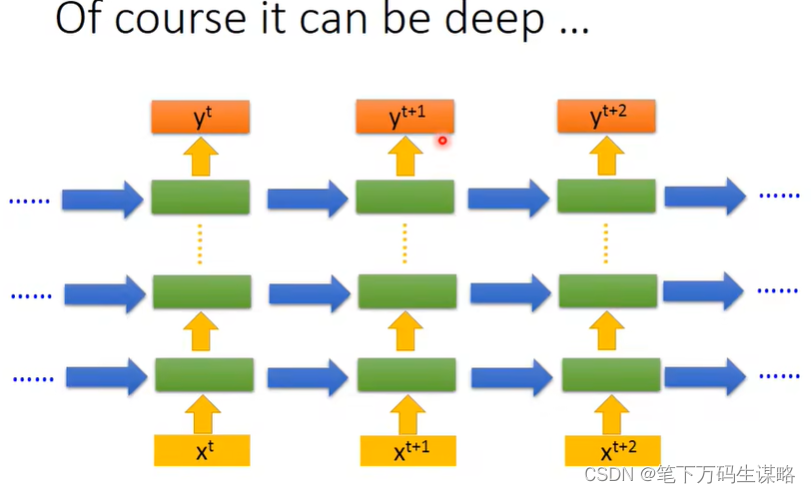
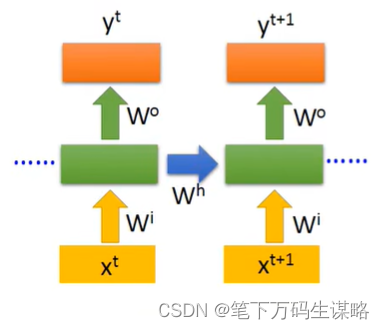
-
Elman Network:把hidden layer的值存起来,下一个时间点读取
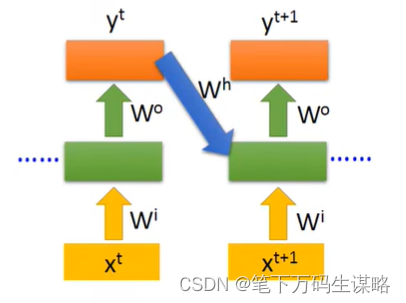
-
Jordan Network: 把output的值存起来,下一个时间点读取
传说Jordan Network有着更好表现,因为不知道RNN的潜层学到了什么 -
Bidirectional RNN:双向读取数据,更好的学习上下文
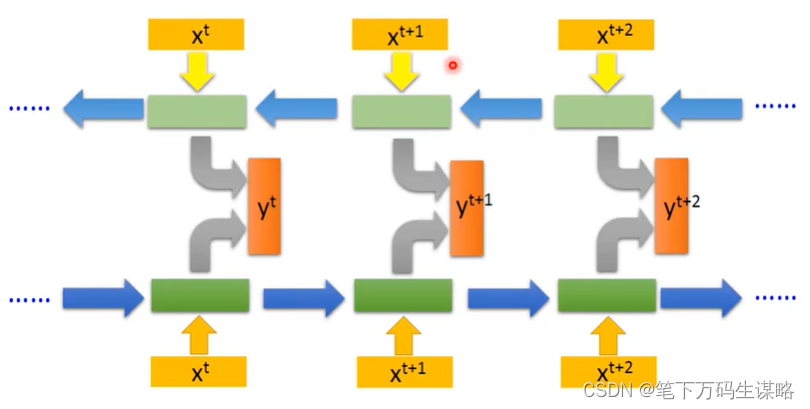
-
Long Short-term Memory (LSTM):比较长的短时记忆网络
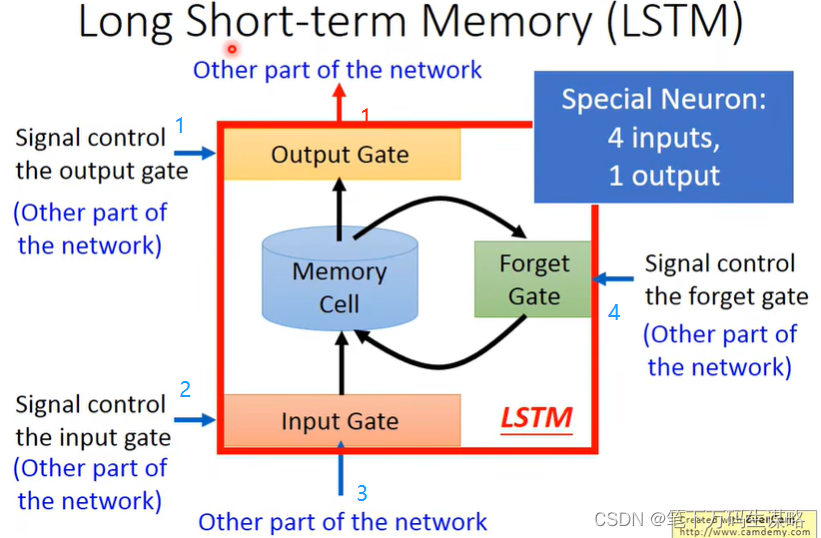
三、Long Short-term Memory (LSTM)
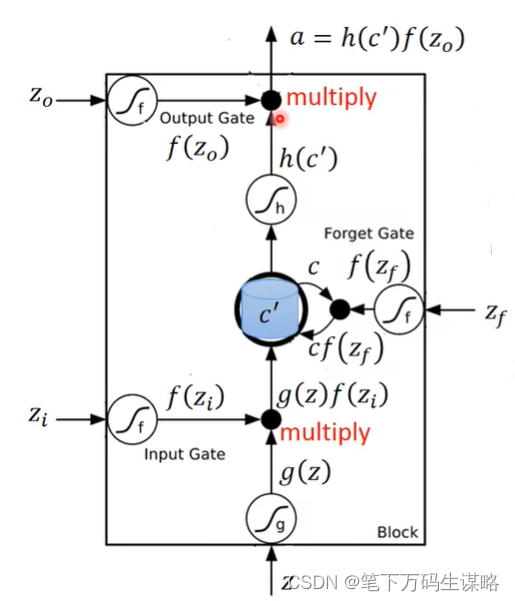
LSTM原理
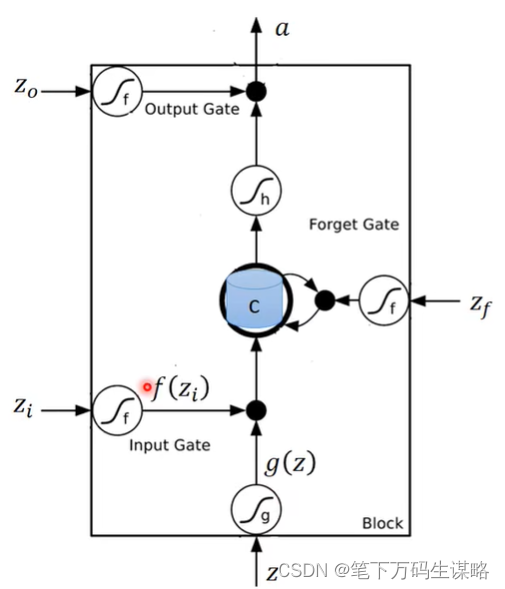
有四个输入: Z , Z i , Z f , Z o Z, Z_i, Z_f, Z_o Z,Zi,Zf,Zo,memory记录为c
三个门:输入门、遗忘门(打开记得,关闭遗忘)、输出门
Z i , Z f , Z o Z_i, Z_f, Z_o Zi,Zf,Zo通过的激活函数f通常是sigmoid函数,选择sigmoid函数意义就是它界在0,1之间,这个0到1的值代表这个Gate打开的程度。
接下来,