5分钟开发一个AI论文抓取和ChatGPT提炼应用
5分钟开发一个AI论文抓取和ChatGPT提炼应用
第一步

- 点击“即刻开始” -选择模板 python -修改标题 “AIPaper”,项目标识“AIPaper”,点击“创建项目”
第二步

- 在编程区域右侧AI区域,输入框输入以下内容:
请根据下面的内容,用streamlit写一个抓取和显示https://arxiv.org/list/cs.AI/recent 最新ai论文的标题、摘要和pdf url的应用:arXiv is a project by the Cornell University Library that provides open access to 1,000,000+ articles in Physics, Mathematics, Computer Science, Quantitative Biology, Quantitative Finance, and Statistics.Usage
Installation
$ pip install arxiv
In your Python script, include the lineimport arxiv
Search
A Search specifies a search of arXiv's database.arxiv.Search(query: str = "",id_list: List[str] = [],max_results: float = float('inf'),sort_by: SortCriterion = SortCriterion.Relevance,sort_order: SortOrder = SortOrder.Descending
)
query: an arXiv query string. Advanced query formats are documented in the arXiv API User Manual.
id_list: list of arXiv record IDs (typically of the format "0710.5765v1"). See the arXiv API User's Manual for documentation of the interaction between query and id_list.
max_results: The maximum number of results to be returned in an execution of this search. To fetch every result available, set max_results=float('inf') (default); to fetch up to 10 results, set max_results=10. The API's limit is 300,000 results.
sort_by: The sort criterion for results: relevance, lastUpdatedDate, or submittedDate.
sort_order: The sort order for results: 'descending' or 'ascending'.
To fetch arXiv records matching a Search, use search.results() or (Client).results(search) to get a generator yielding Results.Example: fetching results
Print the titles fo the 10 most recent articles related to the keyword "quantum:"import arxivsearch = arxiv.Search(query = "quantum",max_results = 10,sort_by = arxiv.SortCriterion.SubmittedDate
)for result in search.results():print(result.title)
Fetch and print the title of the paper with ID "1605.08386v1:"import arxivsearch = arxiv.Search(id_list=["1605.08386v1"])
paper = next(search.results())
print(paper.title)
Result
The Result objects yielded by (Search).results() include metadata about each paper and some helper functions for downloading their content.The meaning of the underlying raw data is documented in the arXiv API User Manual: Details of Atom Results Returned.result.entry_id: A url http://arxiv.org/abs/{id}.
result.updated: When the result was last updated.
result.published: When the result was originally published.
result.title: The title of the result.
result.authors: The result's authors, as arxiv.Authors.
result.summary: The result abstract.
result.comment: The authors' comment if present.
result.journal_ref: A journal reference if present.
result.doi: A URL for the resolved DOI to an external resource if present.
result.primary_category: The result's primary arXiv category. See arXiv: Category Taxonomy.
result.categories: All of the result's categories. See arXiv: Category Taxonomy.
result.links: Up to three URLs associated with this result, as arxiv.Links.
result.pdf_url: A URL for the result's PDF if present. Note: this URL also appears among result.links.
They also expose helper methods for downloading papers: (Result).download_pdf() and (Result).download_source().
第三步

- 打开左侧main.py文件,将AI区生成的代码插入到文件中。
第四步

- 打开左侧文件”requirements.txt“,输入下面的两行,用来加载安装arxiv的api和inscode的chatgpt api包:
arxiv
inscode_api

- 打开.inscode文件
- 将第一行修改为:
run = "pip install -r requirements.txt;streamlit run main.py"
第五步

- 打开"main.py"文件,在第三行添加:
from inscode_api.send_question import send_question
用来加载inscode的chatgpt api
- 倒数第二行添加
st.write(send_question("你是一名专业IT记者,把下面的论文内容变成50字的中文快讯:",result.summary))
-
说明:send_question是调用chatgpt的函数,第一个参数是prompt,第二个参数是传递的内容。
-
最终代码如下:
import streamlit as st
import arxiv
from inscode_api.send_question import send_question# 设置标题和页面描述
st.title('最新AI论文列表')
st.write('这个应用程序使用arxiv API抓取最新的AI论文列表并显示它们的标题、摘要和PDF链接。')# 设置查询参数
search = arxiv.Search(query='cat:cs.AI', max_results=10, sort_by=arxiv.SortCriterion.SubmittedDate
)# 循环遍历结果并显示标题、摘要和PDF链接
for result in search.results():st.write('##', result.title)st.write(result.summary)st.write(send_question("你是一名专业IT记者,把下面的论文内容变成50字的中文快讯:",result.summary)) st.write('PDF链接:', result.pdf_url)第六步
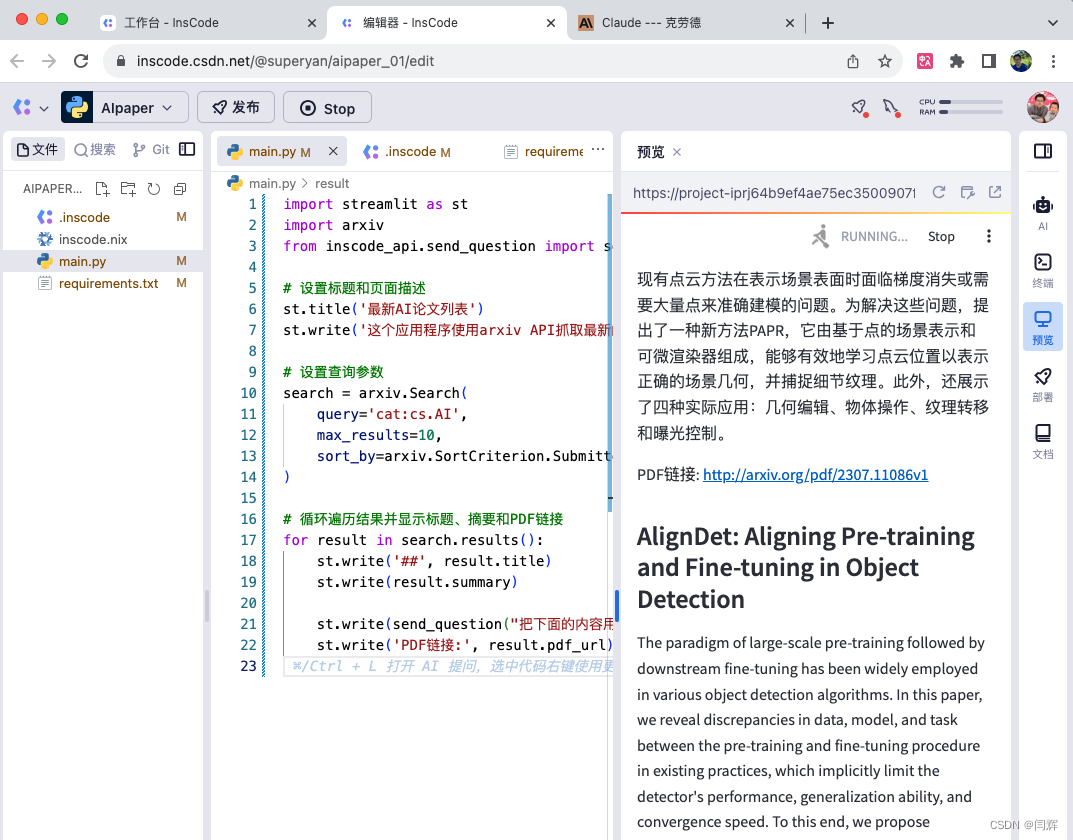
- 点击顶部工具栏的绿色“run”按钮。
- 运行成功后,右侧会显示一个网页,内容是最新的AI论文内容,以及中文的快讯摘要。
- 然后你可以发布到社区或者进行部署