第五篇:强化学习基础之马尔科夫决策过程
你好,我是zhenguo(郭震)
今天总结强化学习第五篇:马尔科夫决策过程
基础
马尔科夫决策过程(MDP)是强化学习的基础之一。下面统一称为:MDP
MDP提供了描述序贯决策问题的数学框架。
它将决策问题建模为:
状态、动作、转移概率和奖励的组合,并通过优化累积奖励的目标来找到最优的决策策略。
详细来说,MDP包含以下要素:
状态(State):系统或环境可能处于的不同状态。
动作(Action):在每个状态下可选的决策或行动。
转移概率(Transition Probability):在执行某个动作后,系统从一个状态转移到另一个状态的概率分布。
奖励(Reward):在每个状态执行某个动作后获得的即时奖励。
策略(Policy):根据当前状态选择动作的策略。
再看迷宫游戏
之前文章,我已经拿着迷宫例子详细阐述过一遍上面的这些概念。
"迷宫问题"是MDP的经典案例。下面我们拿着此案例,再深入理解下这些基础概念。
假设我们有一个迷宫,智能体要在迷宫中找到一个宝藏。
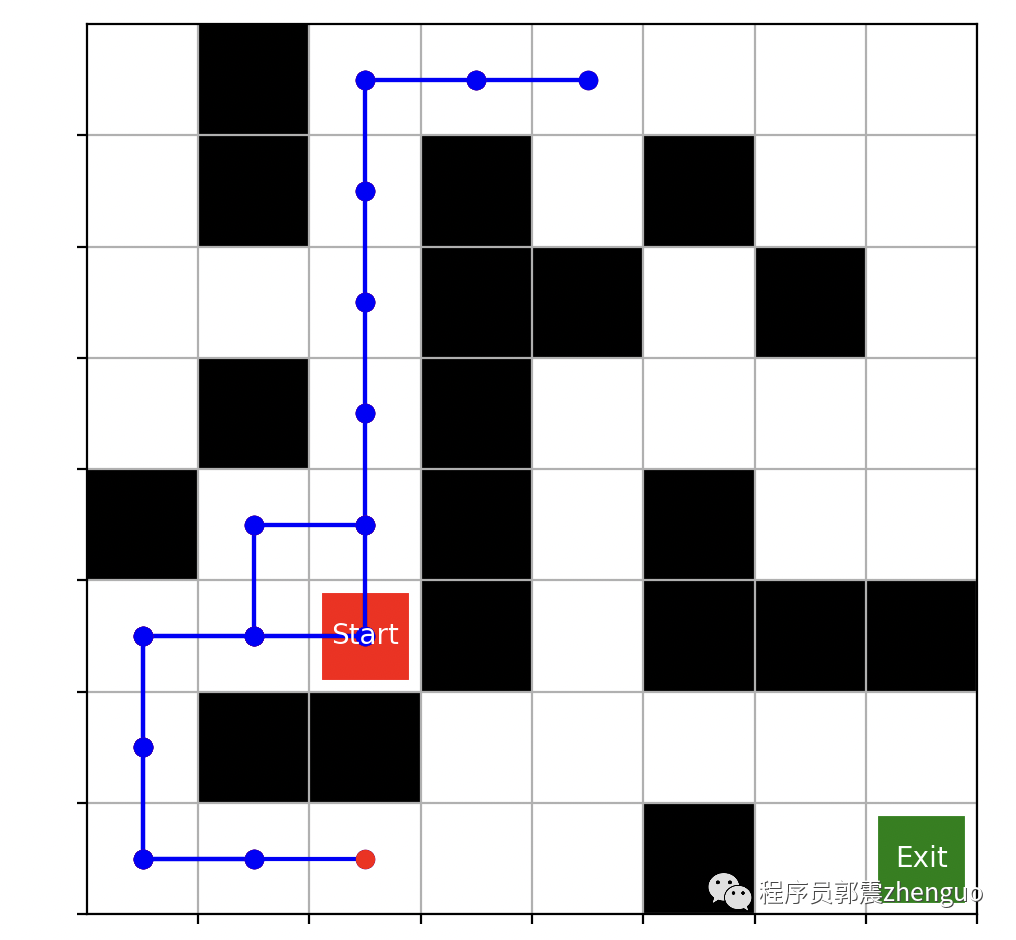
迷宫可以表示为一个二维网格,每个格子可以是墙壁(不可通过)或空地(可通过)。智能体可以采取四个动作:向上、向下、向左和向右移动。目标是找到宝藏,同时避免碰到墙壁。
现在,逐一解释下MDP的这些要素。
状态(State)
在这个例子中,状态是智能体所处的位置坐标,即迷宫中的某个格子。
例如,可以使用(x, y)坐标来表示状态,其中x和y是迷宫中某个格子的行和列索引。
动作(Action)
动作是智能体在某个状态下可以采取的行动,即向上、向下、向左或向右移动。
可以使用符号(U,D,L,R)来表示相应的动作。
转移概率(Transition Probability)
转移概率描述在某个状态下执行某个动作后,智能体转移到下一个状态的概率分布。
在迷宫游戏中,转移概率是确定性的,因为智能体在执行一个动作后会准确地移动到下一个状态。
例如,如果智能体在状态(x, y)执行向上的动作,那么下一个状态将是(x, y-1),转移概率为1。
奖励(Reward)
奖励是智能体在执行某个动作后所获得的即时反馈。
在迷宫游戏中,可以设置以下奖励机制:
当智能体移动到宝藏位置时,获得正奖励(例如+10)。
当智能体移动到墙壁位置时,获得负奖励(例如-5)。
在其他情况下,获得较小的负奖励(例如-1),以鼓励尽快找到宝藏。
公式化表达
下面,我们尝试将这个例子使用公式化表达。
状态(State)
状态可以表示为一个二维坐标 (x, y),其中 x 表示迷宫的行索引,y 表示迷宫的列索引。
假设迷宫的大小为 N × M,则状态集合为
动作(Action)
动作集合为 ,分别代表向上、向下、向左和向右移动。
转移概率(Transition Probability)
由于在迷宫中移动是确定性的,转移概率可以表示为函数
其中 表示在状态 s 下执行动作 a 后转移到状态 s' 的概率。
根据迷宫规则,如果智能体在状态 执行动作 a,那么下一个状态 s' 可以根据动作 a 来计算,例如:
如果 ,则
如果 ,则
如果 ,则
如果 ,则
注意,在边界情况下,如果智能体试图移动到迷宫之外的位置或者移动到墙壁位置,转移概率为0。
奖励(Reward)
奖励函数可以表示为函数 ,其中 表示在状态 s 下执行动作 a 后转移到状态 `s'`` 的即时奖励。
根据迷宫的设定,定义如下奖励:
如果 是宝藏位置,则
如果 是墙壁位置,则
否则,
这篇文章我想重点阐述清楚MDP的这些核心要素,它们是强化学习的根基,这些你一定要理解。
下一篇介绍:MDP的决策方法
你的点赞和转发,给我更新增加更大动力,感谢你的支持。