hive自定义函数
hive自定义函数
hive内置的函数满足不了所有的业务需求,可以考虑自己定义函数
UDF:一对一输出(upper)
UDTF:一对多输出 (lateral view explode)
UDAF:多对一输出(count, max, min)
自定义UDF
用java实现一个UDF
- 引入依赖
<dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>2.3.7</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-common</artifactId><version>2.7.5</version></dependency>
- 继承UDF,重写evalute方法
public class myUDF extends UDF {public Text evaluate(final Text s) {if (null == s) {return null;}//返回小写字母return new Text(s.toString().toLowerCase());}}
- 打包后上传到hive/lib目录下
打包
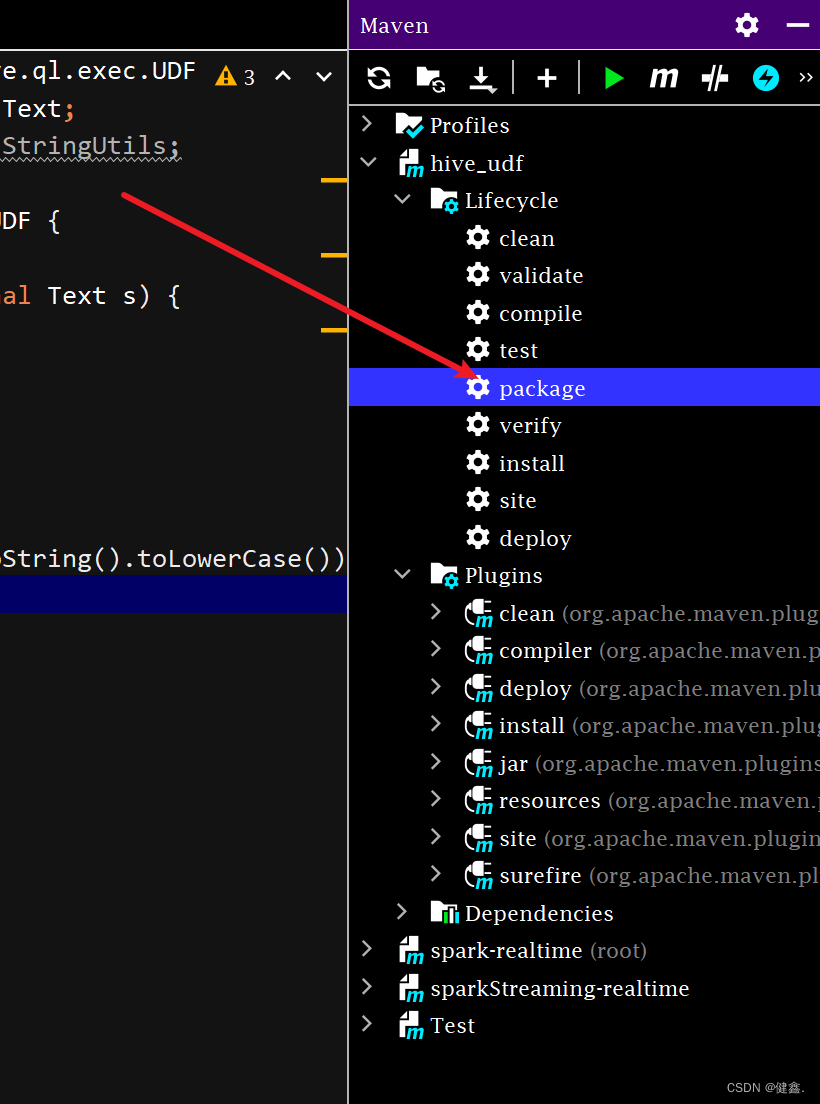
上传到hive/lib目录,
cd /opt/module/hive/libmv hive_udf-1.0-SNAPSHOT.jar myLower
进入hive客户端添加jar包
hive (default)> add jar /opt/module/hive/lib/myLower;
创建临时函数
hive (default)> create temporary function myLower as 'myUDF';-- create temporary function 表示创建临时函数
-- myLower 表示jar包的名称
-- myUDF 为全列名,获取方式下图所示
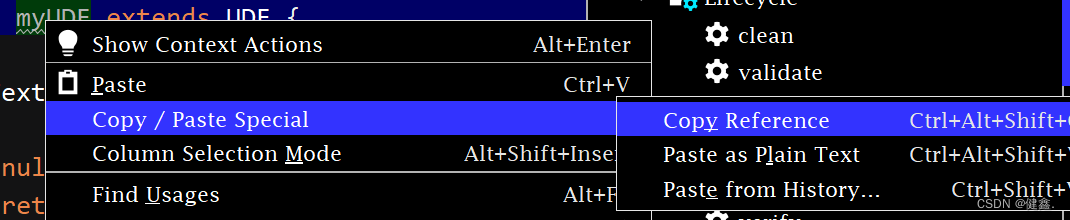
使用自定义函数
hive (default)> select myLower('AS');
OK
_c0
as自定义UDTF
需求
实现将用逗号分割的字符串,拆分成一个一个的字符串
输入:hello, world, hello, hive
输出:helloworldhellohive
实现
UDTF首先会调用 initlizer()方法,返回UDTF的返回行信息(返回个数、类型)
真正的处理过程在process()方法中,每一次forward()调用产生一行,产生多列可以将多列放在一个数组中,然后将数据传入到forward中
最后调用close()方法来进行清理
初始化方法 initialize
- 初始化方法
- 进行列名和输出对象的初始化
- UDTF输出的数据可以有多列(对于这句话的解释,看下面的图片),所以用ArrayList去存
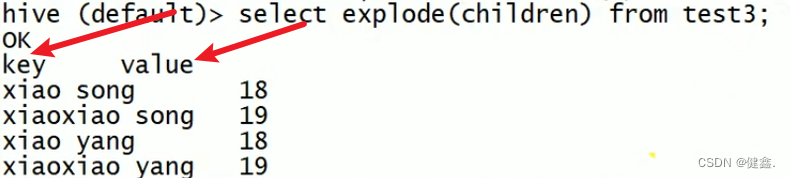
先看表名结构,下面用explode函数来输出children

由下图可知输出了两个列,所以UDTF输出的数据可以有多列
@Override
public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {// 设置输出数据的默认列名,可以被别名覆盖List<String> fieldName = new ArrayList<>();fieldName.add("word");// 设置输出数据的类型List<ObjectInspector> fieldOIs = new ArrayList<>();fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(fieldName, fieldOIs);
}
process方法
// 输出数据集合private ArrayList<String> outputList = new ArrayList<>();@Override
public void process(Object[] objects) throws HiveException {// 取出输入数据String input = objects[0].toString();// 按照 , 进行分割String[] words = input.split(",");// 遍历写出for (String word : words) {// 清空集合outputList.clear();// 将数据放入集合outputList.add(word);// 输出数据forward(outputList);}}
完整代码
public class myUDTF extends GenericUDTF {// 输出数据集合private ArrayList<String> outputList = new ArrayList<>();@Overridepublic StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {// 设置输出数据的默认列名,可以被别名覆盖List<String> fieldName = new ArrayList<>();fieldName.add("word");// 设置输出数据的类型List<ObjectInspector> fieldOIs = new ArrayList<>();fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(fieldName, fieldOIs);}@Overridepublic void process(Object[] objects) throws HiveException {// 取出输入数据String input = objects[0].toString();// 按照 , 进行分割String[] words = input.split(",");// 遍历写出for (String word : words) {// 清空集合outputList.clear();// 将数据放入集合outputList.add(word);// 输出数据forward(outputList);}}@Overridepublic void close() throws HiveException {}
}
测试
将上面程序进行打包,重复UDF中的过程,进行测试
mv hive_udf-1.0-SNAPSHOT.jar myUDTFadd jar /opt/module/hive/lib/myUDTF;create temporary function myUDTF as 'myUDTF';测试结果
hive (default)> select myUDTF("hello,world,hello,hive");
OK
word
hello
world
hello
hive
Time taken: 0.154 seconds, Fetched: 4 row(s)