完整爬虫学习笔记(第一章)
文章目录
- 前言
- :fu:. 爬虫概述:hotdog:
- 原理解剖
- :one: 服务器渲染
- :two: 前端JS渲染
- :fire: 第一个爬虫程序
- 案例
- 总结
前言
最近正在学习Python网络爬虫的相关知识,鉴于本人Python水平有限 , 对Python并无太深的理解,所以此文章的主要目的在于抛砖引玉,若文章中有什么错误与瑕疵,望大家可以指出,使我们共同进步。
提示:以下是本篇文章正文内容,下面案例可供参考
🖕. 爬虫概述🌭
网络爬虫,是一种自动获取网页内容的程序,是搜索引擎的重要组成部分。一般人能访问到的网页,爬虫也都能抓取。所谓的爬虫抓取,也是类似于我们浏览网页。
爬⾍合法么?🐶
⾸先, 爬⾍在法律上是不被禁⽌的. 也就是说法律是允许爬⾍存在的。但是, 爬⾍也具有违法⻛险的,就像菜⼑⼀样, 法律是允许菜⼑的存在的,但是你要是⽤来砍⼈, 那对不起. 没⼈惯着你. 就像王欣说过的,技术是⽆罪的。主要看你⽤它来⼲嘛. ⽐⽅说有些⼈就利⽤爬⾍⼀些⿊客技术每秒钟对着bilibili撸上⼗万⼋千次. 那这个肯定是不被允许的。
❤️因此,网站中有些数据可以被爬取有些不可以被爬取,俗称:君子协议(robots.txt)。
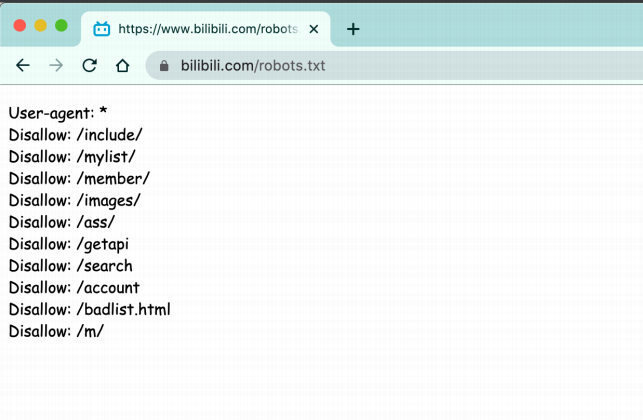
原理解剖
1️⃣首先先介绍一下HTTP协议,Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web)服务器传输超文本到本地浏览器的传送协议,直白点儿,就是浏览器和服务器之间的数据交互遵守的就是HTP协议。
HTTP协议把一条消息分为以下内容。
请求:
1.请求行 -> 请求方式(get/post)请求url地址协议
2.请求头 -> 放一些服务器要使用的附加信息
3请求体 -> 一般放一些请求参数
响应:
1 状态行 -> 协议状态码
2 响应头 -> 放一些客户端要使用的一些附加信息
3 响应体 -> 服务返回的真正客户端要用的内容(HTML,json)等
🔥 requests库共有如下七个主要方法: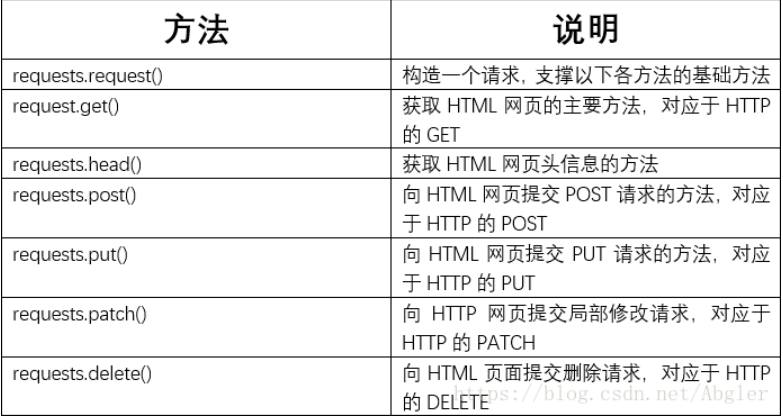 get()方法要涉及requests库的两个重要对象——Request与Response.
get()方法要涉及requests库的两个重要对象——Request与Response.
- Request对象包含了向服务器请求的相关操作的信息;
- Response对象包含了爬虫从服务器所返回的全部信息
Response类含有以下的属性:
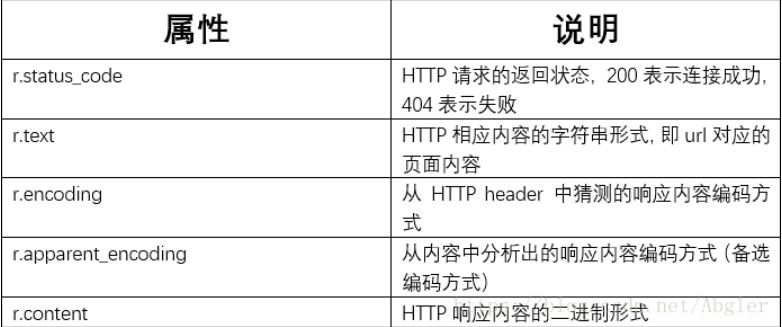
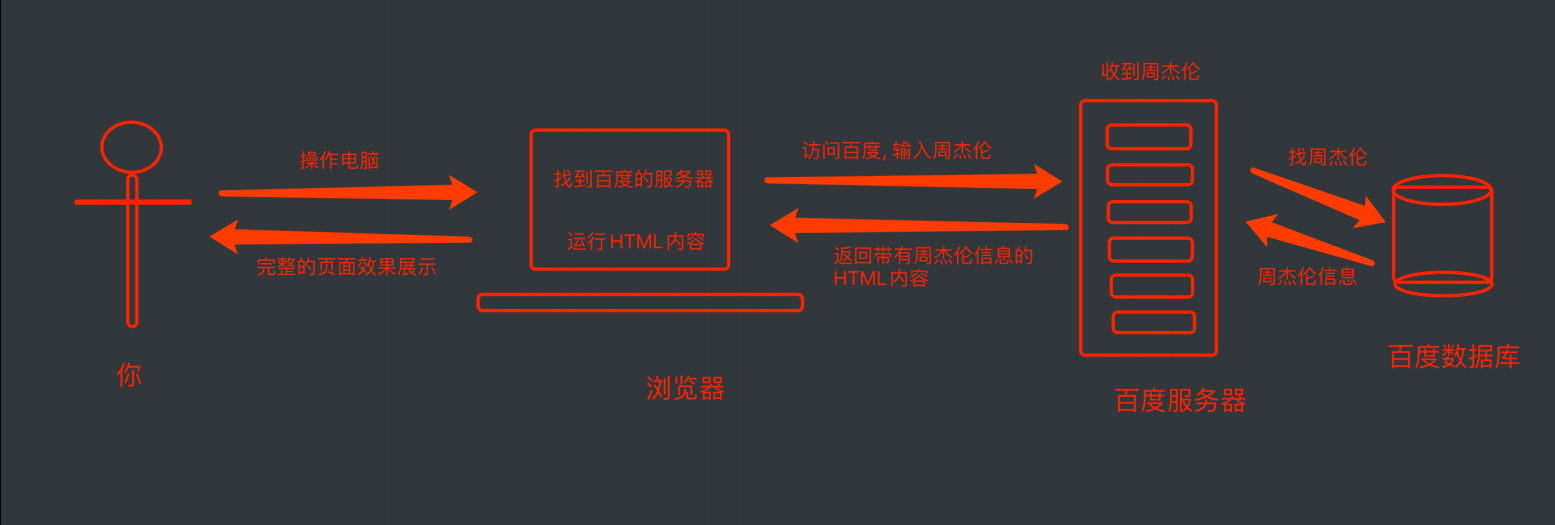
在访问百度的时候, 浏览器会把这⼀次请求发
送到百度的服务器(百度的⼀台电脑), 由服务器接收到这个请求, 然后加载⼀些数据. 返回给浏览器, 再由浏览器进⾏显示. 听起来好像是个废话…但是这⾥蕴含着⼀个极为重要的东⻄在⾥⾯, 注意, 百度的服务器返回给浏览器的不直接是⻚⾯, ⽽是⻚⾯源代码(由html, css, js组成). 由浏览器把⻚⾯源代码进⾏执⾏, 然后把执⾏之后的结果展示给⽤户. 所以我们能看到在内容中, 我们拿到的是百度的源代码(就是那堆看不懂的⻤东⻄)。
具体过程如图:
页面渲染过程,我们常⻅的⻚⾯渲染过程有两种:
1️⃣ 服务器渲染
由于数据是直接写在html中的, 所以我们能看到的数据都在⻚⾯源代码中能找的到的。这种⽹⻚⼀般都相对⽐较容易就能抓取到⻚⾯内容.
在后面我们写爬虫的时候要格外注意请求头和响应头,这两个地方一般都隐含着一些比较重要的内容
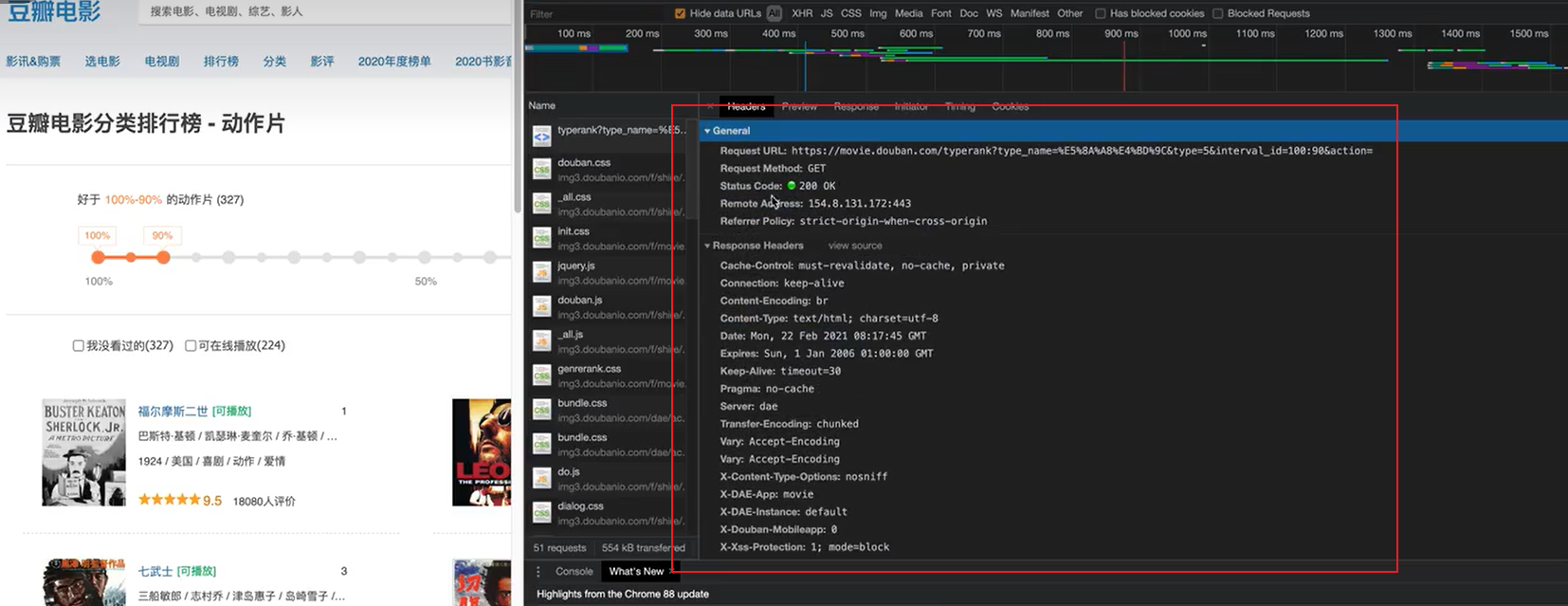
请求头中最常见的一些重要内容瓜爬虫需要):
1.User-Agent:请求载体的身份标识(用啥发谜的请求)
2.Referer:防盗链(这次请求是从哪个页面来的?反爬会用到)
3.cookie:本地字符串数据信息(用户登录信息,反爬的token)
响应头中一些重要的内容:
1.cookie:本地字符串数据信息(用户登录信息,反爬的token)
2.各种神奇的莫名其妙的字符串(这个需要经验了,一般都是token字样,防止各种攻击和反爬)
非对称秘钥加密:“非对称加密”使用的时候有两把锁,一把叫做“私有密钥”,一把是“公开密钥”,使用非对象加密的加密方式的时候,服务器首先告诉客户端按照自己给定的公开密钥进行加密处理,客户端按照公开密钥加密以后,服务器接受到信息再通过自己的私有密钥进行解密,这样做的好处就是解密的钥匙根本就不会进行传输,因此也就避免了被挟持的风险。就算公开密钥被窃听者拿到了,它也很难进行解密,因为解密过程是对离散对数求值,这可不是轻而易举就能做到的事。
以下是非对称加密的原理图:
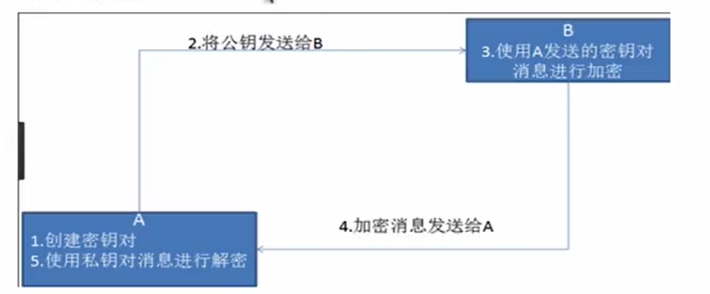
但是非对称秘钥加密技术也存在如下缺点:
第一个是:如何保证接收端向发送端发出公开秘钥的时候,发送端确保收到的是预先要发送的,而不会被挟
持。只要是发送密钥,就有可能有被挟持的风险。
第二个是:非对称加密的方式教率比较低,它处理起来更为复杂,通信过程中使用就有一定的效率问题而影响通信速度
2️⃣ 前端JS渲染
这种就稍显麻烦了. 这种机制⼀般是第⼀次请求服务器返回⼀堆HTML框架结构. 然后再次请求到真正保存数据的服务器, 由这个服务器返回数据, 最后在浏览器上对数据进⾏加载. 就像这样:
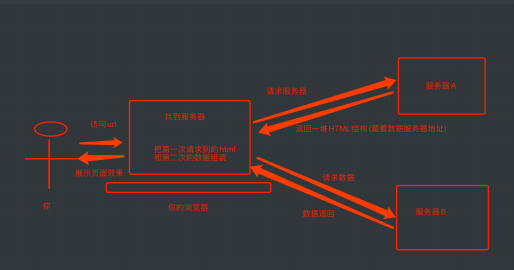
这样做的好处是服务器那边能缓解压⼒. ⽽且分⼯明确. ⽐较容易维护. 典型的有这么⼀个⽹⻚。
⭕️
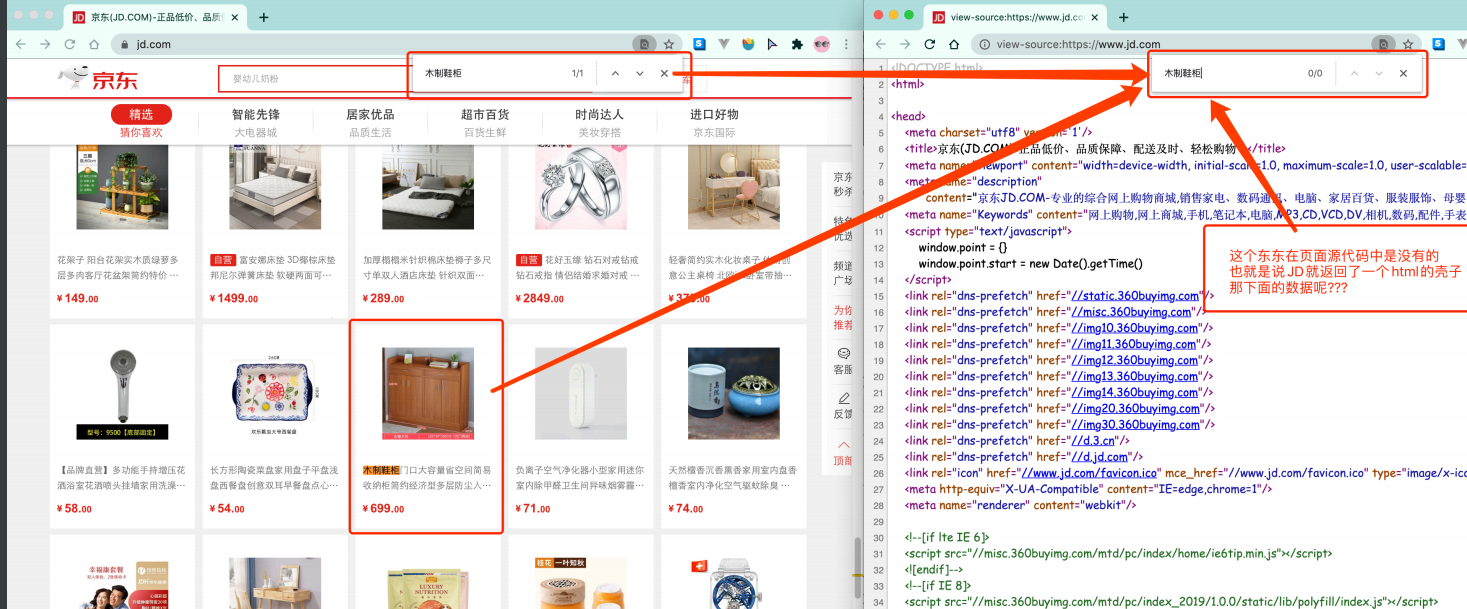
那数据是何时加载进来的呢? 其实就是在我们进⾏⻚⾯向下滚动的时候, jd就在偷偷的加载数据了, 此时想要看到这个⻚⾯的加载全过程。
我们就需要借助浏览器的调试⼯具了(F12)
🔥
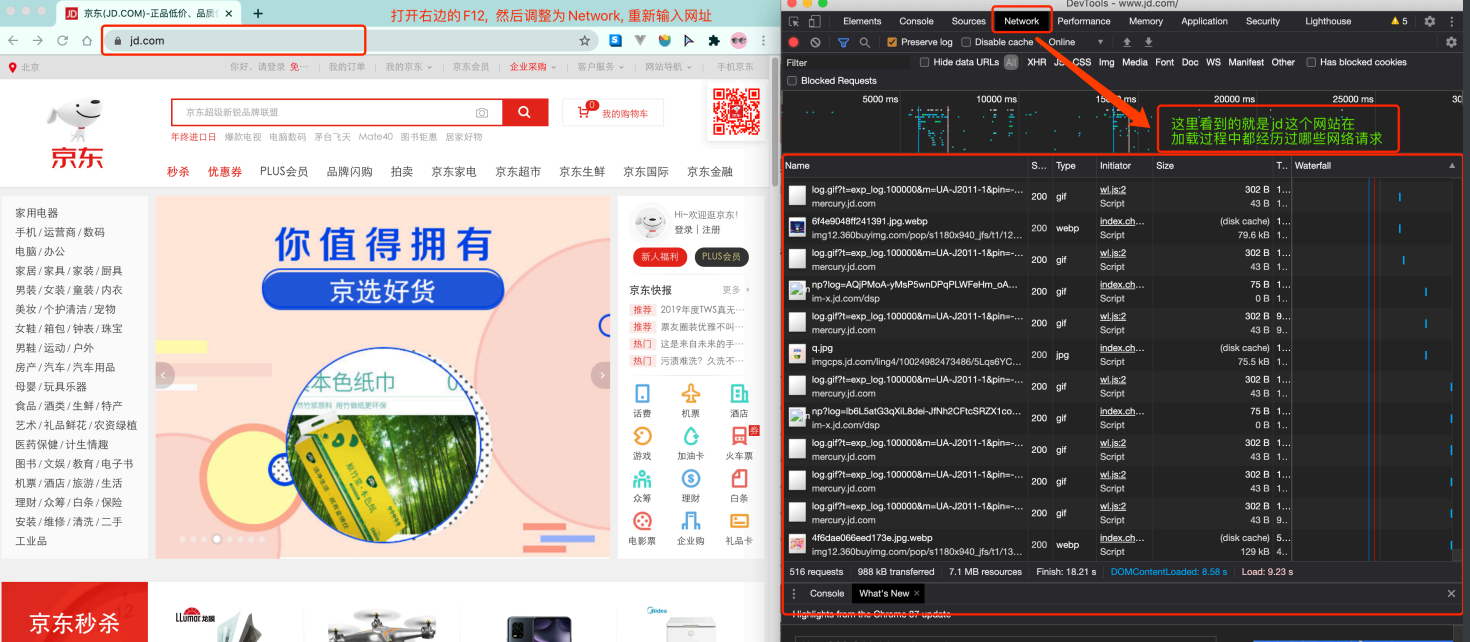
🔥
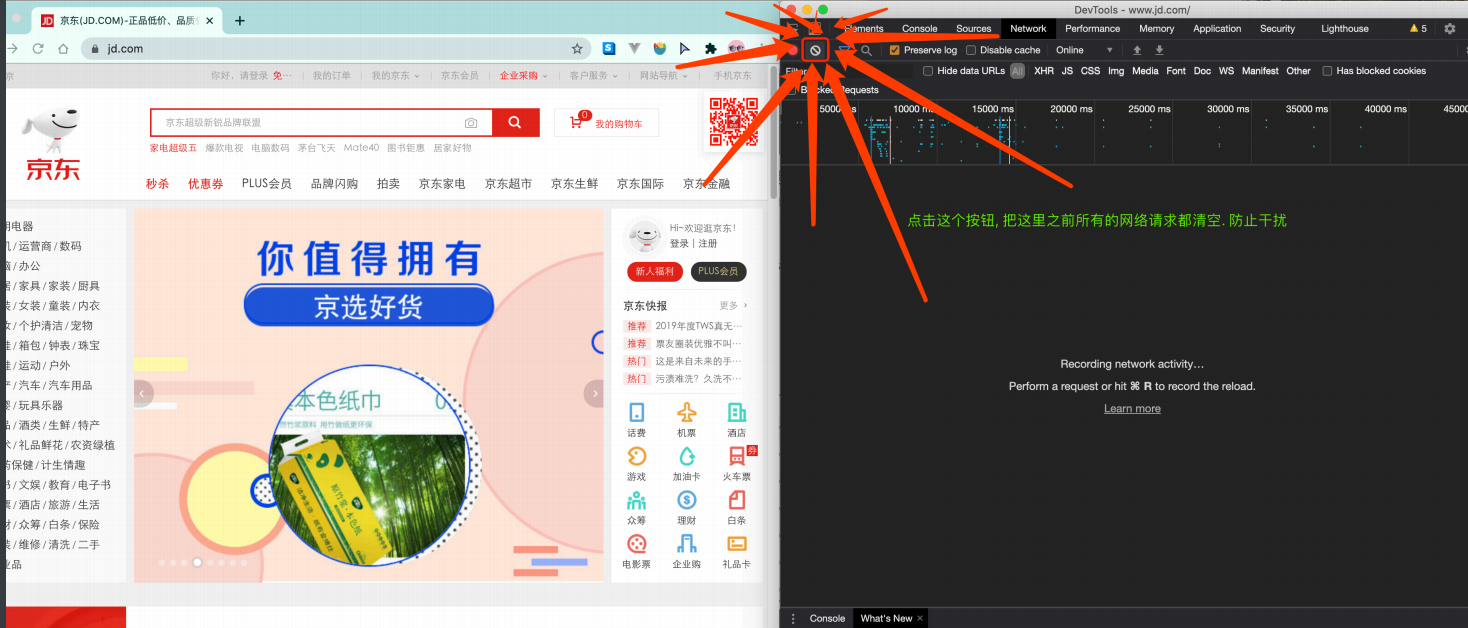
🔥
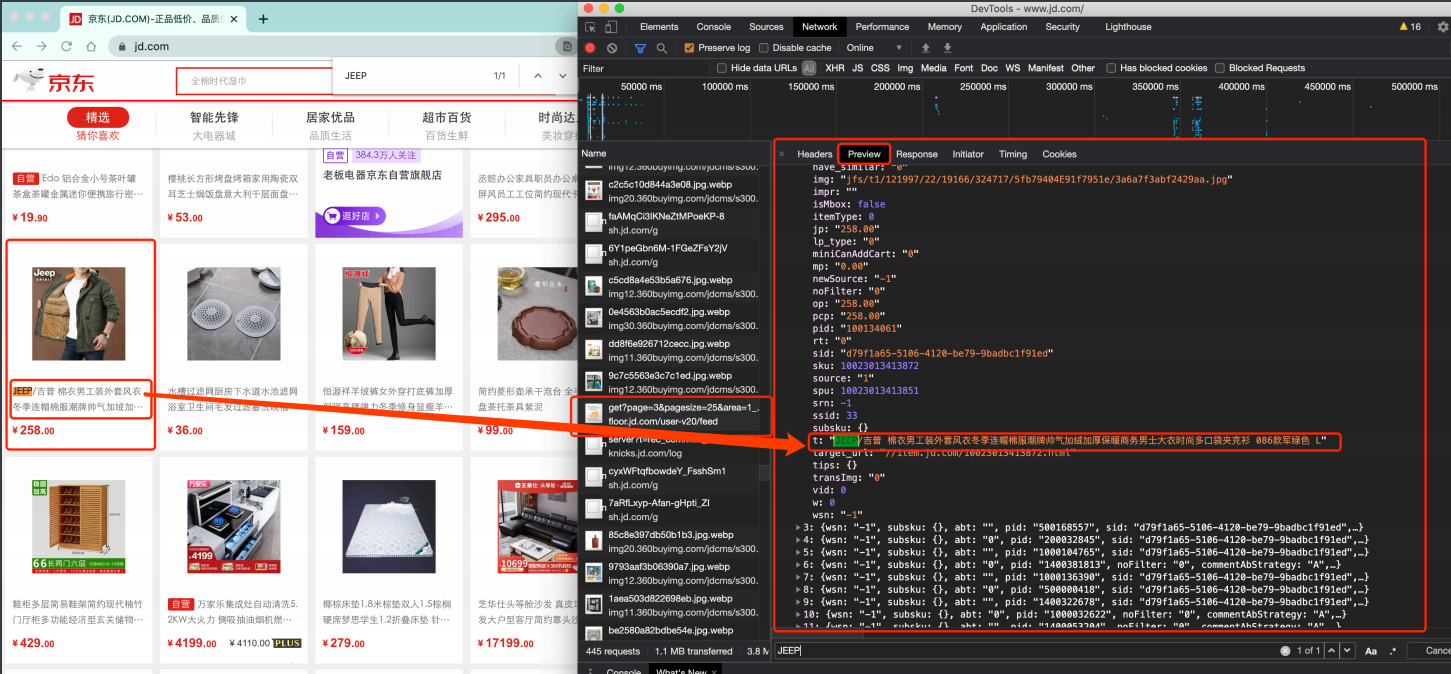
⻚⾯上看到的内容其实是后加载进来的。
🔥 第一个爬虫程序
我们使⽤urllib来抓取⻚⾯源代码. 这个是python内置的⼀个模块, 但是, 它并不是我们常⽤的爬⾍⼯具. 常⽤的抓取⻚⾯的模块通常使⽤⼀个第三⽅模块requests. 这个模块的优势就是⽐urllib还要简单, 并且处理各种请求都⽐较⽅便。
安装⽅法
pip install requests
如果安装速度慢的话可以改⽤国内的源进⾏下载安装.(清华源)
pip install -i
https://pypi.tuna.tsinghua.edu.cn/simple (下载的包名称)requests
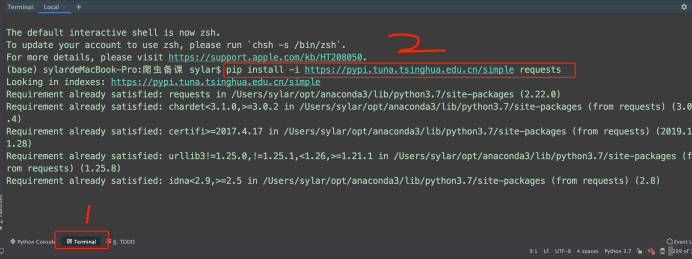
- 爬⾍就是写程序去模拟浏览器⽤来抓取互联⽹上的内容
- python中⾃带了⼀个urllib提供给我们进⾏简易爬⾍的编写
- requests模块的简单使⽤, 包括get, post两种⽅式的请求. 以及User-Agent的介绍.
案例
1️⃣ 抓取搜索词
# 安装requests
# pip install requests
# 国内源
# pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requestsimport requests
query = input("输入一个你喜欢的明星")url = f'https://www.sogou.com/web?query={query}'dic = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
}
resp = requests.get(url, headers=dic) # 处理一个小小的反爬print(resp)
print(resp.text) # 拿到页面源代码2️⃣ 抓取百度翻译数据
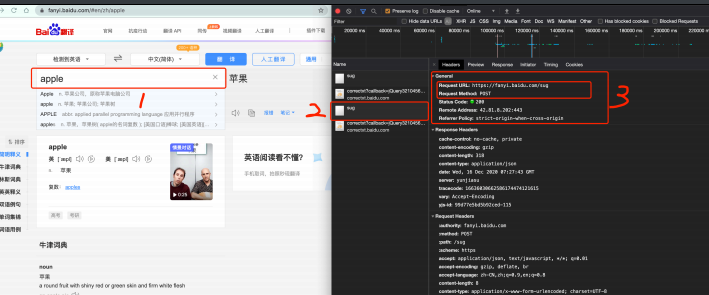
import requestsurl = "https://fanyi.baidu.com/sug"s = input("请输入你要翻译的英文单词")
dat = {"kw": s
}# 发送post请求, 发送的数据必须放在字典中, 通过data参数进行传递
resp = requests.post(url, data=dat)
print(resp.json()) # 将服务器返回的内容直接处理成json() => dict3️⃣ 抓取百度翻译数据
import jsonimport requestsurl = "https://movie.douban.com/j/chart/top_list"# 重新封装参数
param = {"type": "24","interval_id": "100:90","action": "","start": 0,#从库中的第⼏部电影去取"limit": 20,#⼀次取出的个数
}headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
}response =requests.get(url=url,params=param,headers=headers)list_data = response.json()
fp = open('./douban.json', 'w', encoding='utf-8')
json.dump(list_data, fp=fp, ensure_ascii=False)
response.close()
# print(response.json())
print('over!!!')
总结
提示:这里对文章进行总结:
以上就是今天要讲的内容,本文仅仅简单介绍了爬虫概述,原理,简单使用,而python提供了大量能使我们快速便捷地爬取数据的api和方法。