Mysql中常用到的查询关键字
文章目录
- 1、join
- 2、like 模糊查询
- 3、or
- 4、distinct
- 5、in 包含
- 6、group by 分组
- 7、order by
- 8、limit
1、join
MySQL 的连接主要分为内连接和外连接。
什么是内连接: 取得两张表中满足存在连接匹配关系的记录。
什么是外连接: 不只取得两张表中满足存在连接匹配关系的记录,还包括某张表(或两张表)中不满足匹配关系的记录。
上图!!!!!
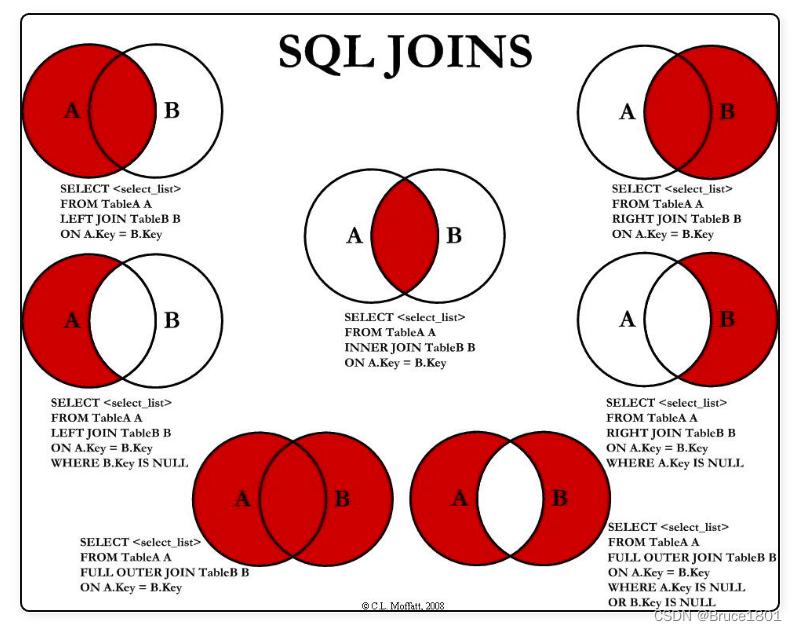
内连接 inner join:在两张表进行连接查询时,只保留两张表中完全匹配的结果集
外连接常用的有左连接、右连接。
左连接 left join :在两张表进行连接查询时,会返回左表所有的行,以及右表中匹配的行,右表中没有匹配到的返回null
右连接 right join:在两张表进行连接查询时,会返回右表所有的行,以及左表中匹配的行,左表中没有匹配到的返回null。
on先对数据进行过滤,然后再进行连接
先建两张表:t_user和t_class
CREATE TABLE `t_user` (`id` bigint NOT NULL AUTO_INCREMENT,`user_name` varchar(32) DEFAULT NULL,`password` varchar(32) DEFAULT NULL,`status` int DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;CREATE TABLE `t_class` (`user_id` int NOT NULL,`class_name` varchar(32) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
插入数据:
# t_user 表
INSERT INTO `t_user` VALUES (9, 'yuanhaozhe', '123456', 2);
INSERT INTO `t_user` VALUES (10, 'yuanhaozhe', '123456', 2);
INSERT INTO `t_user` VALUES (11, 'yuanhaozhe', '123456', 2);
INSERT INTO `t_user` VALUES (12, 'yuanhaozhe', '123456', 2);
INSERT INTO `t_user` VALUES (13, 'yuanhaozhe', '123456', 2);
INSERT INTO `t_user` VALUES (14, 'yuanhaozhe', '123456', 2);
INSERT INTO `t_user` VALUES (15, 'yuanhaozhe', '123456', 2);
INSERT INTO `t_user` VALUES (16, 'yuanhaozhe', '123456', 2);
INSERT INTO `t_user` VALUES (17, 'yuanhaozhe', '123456', 2);#t_class 表
INSERT INTO `t_class` VALUES (9, '软件1班');
INSERT INTO `t_class` VALUES (9, '人工智能1班');
INSERT INTO `t_class` VALUES (10, '软件2班');
INSERT INTO `t_class` VALUES (1, '计算机科学1班');
INSERT INTO `t_class` VALUES (11, '计算机科学2班');
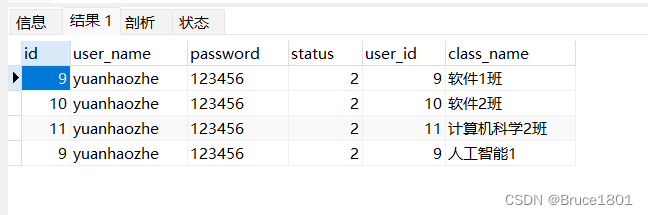
内连接:匹配规则是 t_user的id=t_class的user_id
select * from t_user tu inner join t_class tc on tu.id = tc.user_id
返回的是完全满足规则的记录:
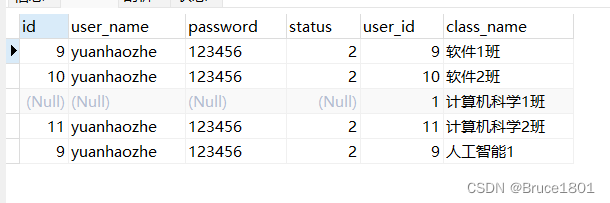
左连接:匹配规则是 t_user的id=t_class的user_id
select * from t_user tu left join t_class tc on tu.id = tc.user_id
返回的是左表的所有记录,以及右表中匹配的记录(左表的一条记录可以匹配右表的多条记录,例如 t_user中id为9的记录,匹配右表中user_id为9的两条记录):

右连接:匹配规则是 t_user的id=t_class的user_id
select * from t_user tu right join t_class tc on tu.id = tc.user_id
返回的是右表的所有记录,以及左表中匹配的记录(右表的一条记录可以匹配左表的多条记录):
2、like 模糊查询
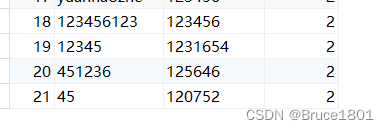
此时t_user表中有以下记录:
当 like 后面的内容没有一个%时,此时 like相当于=;
select * from t_user where user_name like '45';
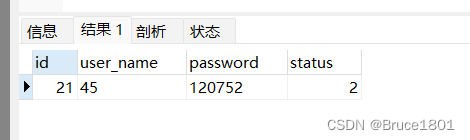
当 like 后面的内容 %写在左侧开头时(‘%45’),此时查询的是某个字段以%后面的内容为结尾的记录
select * from t_user where user_name like '%45';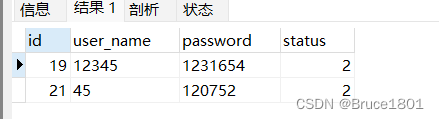
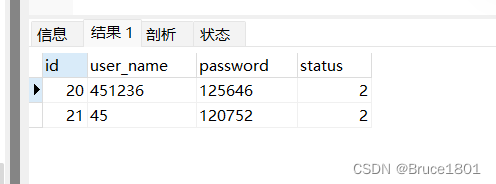
当 like 后面的内容 %写在右侧结尾时(‘45%’),此时查询的是某个字段以%后面的内容为开头的记录
select * from t_user where user_name like '45%';
当 like 后面的内容 %写在左侧开头和右侧结尾时(‘%45%’),此时查询的是某个字段包含两个%之间的内容的记录
select * from t_user where user_name like '%45%';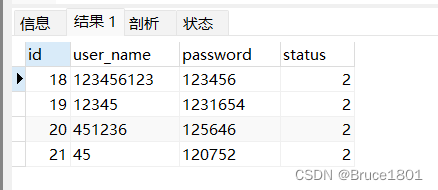
3、or
OR运算符可以实现对多个条件进行同时判断
and 的优先级高于or
select * from t_user where id = 9 or status = 0 and id = 3;
上面这条sql的判断条件是: id=9 或 (status=0 and id=3)
select * from t_user where id = 2 and id = 3 or status = 0;
上面这条sql的判断条件是: (id=2 and id=3)or status=0
4、distinct
distinct 用于对某个字段过滤重复数据
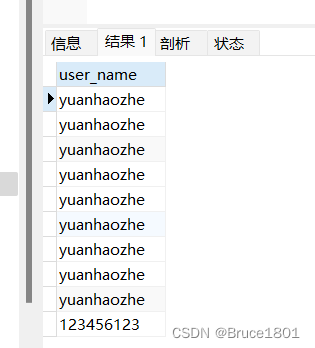
当我执行下面sql去查询t_user表中的user_name时(不加distinct):
select user_name from t_user ;
当我执行下面sql去查询t_user表中的user_name时(加distinct)
select distinct user_name from t_user ;
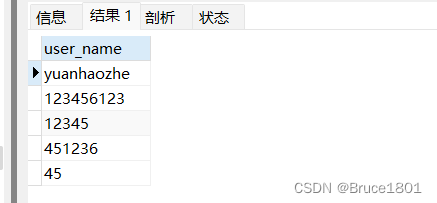
可以明显看到将重复的yuanhaozhe过滤掉,只保留了一条记录。
5、in 包含
in常用于where表达式中,其作用是查询某个范围内的数据(是用来指定一个值在一个列表或一个子查询中是否存在的运算符),可以代替多个or
举例:
SELECT * FROM `t_class` where user_id in (1,9,10) ORDER BY user_id DESC
这条sql将会查询出t_class表中 user_id = 1 或 user_id =9 或 user_id =10 的

6、group by 分组
分组查询的原理:先对数据进行分组,在对分组后的数据进行汇总,分组查询通常用于配合聚合函数,达到分类汇总统计信息的目的。而分类汇总的本质实际上就是先将数组进行分组,分组后相同类别的信息会聚在一起,然后通过需求进行计算。
比如:查询出记录中出现的名字,每个名字出现的次数,状态码
select user_name,count(user_name),status from t_user GROUP BY user_name,status
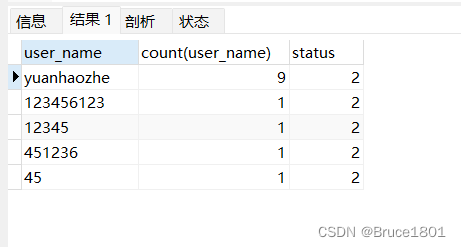
如果使用group by ,则select中只能出现 group by 后面的字段 或 聚合函数
7、order by
查询结果集通常是按照id排序的,也就是根据主键排序。这也是大部分数据库的做法。如果我们要根据其他条件排序怎么办?可以加上ORDER BY子句。
以这个表为例(没有设置主键):
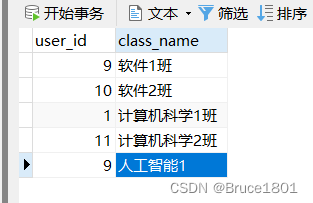
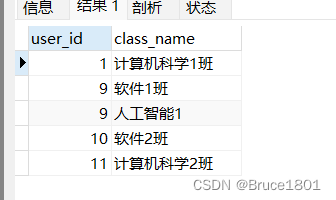
按照user_id从低到高进行排序:
SELECT * FROM `t_class` order by user_id
如果要反过来,按照user_id从高到底排序,我们可以加上DESC表示“倒序”:
SELECT * FROM `t_class` order by user_id DESC
默认的排序规则是ASC:“升序”,即从小到大。ASC可以省略,即ORDER BY score ASC和ORDER BY score效果一样。
8、limit
使用SELECT查询时,如果结果集数据量很大,比如几万行数据,放在一个页面显示的话数据量太大,不如分页显示,每次显示100条。
要实现分页功能,实际上就是从结果集中显示第1~ 100条记录作为第1页,显示第101~200条记录作为第2页,以此类推。
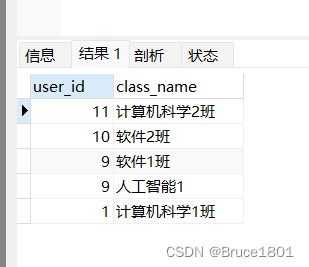
因此,分页实际上就是从结果集中“截取”出第M~N条记录。这个查询可以通过LIMIT OFFSET 子句实现。我们先把所有信息按照user_id从高到低进行排序:
SELECT * FROM `t_class` order by user_id DESC
现在,我们把结果集分页,每页2条记录。要获取第2页的记录,可以使用LIMIT 2 OFFSET 2:
SELECT * FROM `t_class` order by user_id DESC LIMIT 2 OFFSET 2
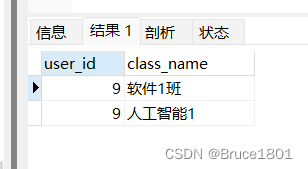
上述查询LIMIT 2 OFFSET 2表示,对结果集从2号记录开始(跳过前两条),最多取2条。注意SQL记录集的索引从0开始。
可见,分页查询的关键在于,首先要确定每页需要显示的结果数量pageSize(这里是2),然后根据当前页的索引pageIndex(从1开始),确定LIMIT和OFFSET应该设定的值:
- LIMIT总是设定为pageSize;
- OFFSET计算公式为pageSize * (pageIndex - 1)。