【cuda入门系列】通过代码真实打印线程ID
【cuda入门系列】通过代码真实打印线程ID
- 1.`gridDim(6,1),blockDim(4,1)`
- 2.`gridDim(3,2),blockDim(2,2)`
【cuda入门系列之参加CUDA线上训练营】在Jetson nano本地跑 hello cuda!
【cuda入门系列之参加CUDA线上训练营】一文认识cuda基本概念
【cuda入门系列之参加CUDA线上训练营】共享内存实例1:矩阵转置实现及其优化
【cuda入门系列之参加CUDA线上训练营】共享内存实例2:矩阵相乘
【cuda入门系列】通过代码真实打印线程ID
定义一个长度为24的向量,分别用gridDim(6,1),blockDim(4,1)以及gridDim(3,2),blockDim(2,2)的thread去访问,确认thread与向量各元素之间的对应关系。
1.gridDim(6,1),blockDim(4,1)
#include <stdio.h>
#define BLOCK_SIZE 4__global__ void gpu_print(int *a,int m,int n)
{ int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x;printf("%d %d\n", gridDim.x,gridDim.y); printf("%d %d\n", blockDim.x,blockDim.y);printf("blockIdx.y:%d blockIdx.x:%d threadIdx.y:%d threadIdx.x:%d val:%d \n", blockIdx.y,blockIdx.x,threadIdx.y,threadIdx.x,a[row*n+col]);
}int main(int argc, char const *argv[])
{int m=4;int n=6;int *h_a;cudaMallocHost((void **) &h_a, sizeof(int)*m*n);for (int i = 0; i < m; ++i) {for (int j = 0; j < n; ++j) {h_a[i * n + j] = i * n + j;}}int *d_a;cudaMalloc((void **) &d_a, sizeof(int)*m*n);cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice);dim3 dimGrid(6,1);dim3 dimBlock(4,1);gpu_print<<<dimGrid, dimBlock>>>(d_a,m, n); // free memorycudaFree(d_a);cudaFreeHost(h_a);system("pause");return 0;
}
编译后打印结果如下:
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
6 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
4 1
blockIdx.y:0 blockIdx.x:1 threadIdx.y:0 threadIdx.x:0 val:4
blockIdx.y:0 blockIdx.x:1 threadIdx.y:0 threadIdx.x:1 val:5
blockIdx.y:0 blockIdx.x:1 threadIdx.y:0 threadIdx.x:2 val:6
blockIdx.y:0 blockIdx.x:1 threadIdx.y:0 threadIdx.x:3 val:7
blockIdx.y:0 blockIdx.x:3 threadIdx.y:0 threadIdx.x:0 val:12
blockIdx.y:0 blockIdx.x:3 threadIdx.y:0 threadIdx.x:1 val:13
blockIdx.y:0 blockIdx.x:3 threadIdx.y:0 threadIdx.x:2 val:14
blockIdx.y:0 blockIdx.x:3 threadIdx.y:0 threadIdx.x:3 val:15
blockIdx.y:0 blockIdx.x:2 threadIdx.y:0 threadIdx.x:0 val:8
blockIdx.y:0 blockIdx.x:2 threadIdx.y:0 threadIdx.x:1 val:9
blockIdx.y:0 blockIdx.x:2 threadIdx.y:0 threadIdx.x:2 val:10
blockIdx.y:0 blockIdx.x:2 threadIdx.y:0 threadIdx.x:3 val:11
blockIdx.y:0 blockIdx.x:4 threadIdx.y:0 threadIdx.x:0 val:16
blockIdx.y:0 blockIdx.x:4 threadIdx.y:0 threadIdx.x:1 val:17
blockIdx.y:0 blockIdx.x:4 threadIdx.y:0 threadIdx.x:2 val:18
blockIdx.y:0 blockIdx.x:4 threadIdx.y:0 threadIdx.x:3 val:19
blockIdx.y:0 blockIdx.x:0 threadIdx.y:0 threadIdx.x:0 val:0
blockIdx.y:0 blockIdx.x:0 threadIdx.y:0 threadIdx.x:1 val:1
blockIdx.y:0 blockIdx.x:0 threadIdx.y:0 threadIdx.x:2 val:2
blockIdx.y:0 blockIdx.x:0 threadIdx.y:0 threadIdx.x:3 val:3
blockIdx.y:0 blockIdx.x:5 threadIdx.y:0 threadIdx.x:0 val:20
blockIdx.y:0 blockIdx.x:5 threadIdx.y:0 threadIdx.x:1 val:21
blockIdx.y:0 blockIdx.x:5 threadIdx.y:0 threadIdx.x:2 val:22
blockIdx.y:0 blockIdx.x:5 threadIdx.y:0 threadIdx.x:3 val:23
从代码打印结果来看,一共有blcokDim4*gridDim 6=24个线程在工作。
- gridDim.x,gridDim.y———grid中x方向、y方向各含有多少个block;
- blockDim.x,blockDim.y——一个block中x方向、y方向各含有多少个thread。
定义的gridDim.x,gridDim.y以及blockDim.x,blockDim.y通过打印结果,可知:

各block中的thread与矩阵中元素的指向关系如下图:

2.gridDim(3,2),blockDim(2,2)
将代码中的
dim3 dimGrid(6,1);
dim3 dimBlock(4,1);
修改为:
dim3 dimGrid(3,2);
dim3 dimBlock(2,2);
其他不变,同样进行编译,打印输出:
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
3 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
2 2
blockIdx.y:0 blockIdx.x:1 threadIdx.y:0 threadIdx.x:0 val:2
blockIdx.y:0 blockIdx.x:1 threadIdx.y:0 threadIdx.x:1 val:3
blockIdx.y:0 blockIdx.x:1 threadIdx.y:1 threadIdx.x:0 val:8
blockIdx.y:0 blockIdx.x:1 threadIdx.y:1 threadIdx.x:1 val:9
blockIdx.y:1 blockIdx.x:0 threadIdx.y:0 threadIdx.x:0 val:12
blockIdx.y:1 blockIdx.x:0 threadIdx.y:0 threadIdx.x:1 val:13
blockIdx.y:1 blockIdx.x:0 threadIdx.y:1 threadIdx.x:0 val:18
blockIdx.y:1 blockIdx.x:0 threadIdx.y:1 threadIdx.x:1 val:19
blockIdx.y:0 blockIdx.x:2 threadIdx.y:0 threadIdx.x:0 val:4
blockIdx.y:0 blockIdx.x:2 threadIdx.y:0 threadIdx.x:1 val:5
blockIdx.y:0 blockIdx.x:2 threadIdx.y:1 threadIdx.x:0 val:10
blockIdx.y:0 blockIdx.x:2 threadIdx.y:1 threadIdx.x:1 val:11
blockIdx.y:1 blockIdx.x:1 threadIdx.y:0 threadIdx.x:0 val:14
blockIdx.y:1 blockIdx.x:1 threadIdx.y:0 threadIdx.x:1 val:15
blockIdx.y:1 blockIdx.x:1 threadIdx.y:1 threadIdx.x:0 val:20
blockIdx.y:1 blockIdx.x:1 threadIdx.y:1 threadIdx.x:1 val:21
blockIdx.y:0 blockIdx.x:0 threadIdx.y:0 threadIdx.x:0 val:0
blockIdx.y:0 blockIdx.x:0 threadIdx.y:0 threadIdx.x:1 val:1
blockIdx.y:0 blockIdx.x:0 threadIdx.y:1 threadIdx.x:0 val:6
blockIdx.y:0 blockIdx.x:0 threadIdx.y:1 threadIdx.x:1 val:7
blockIdx.y:1 blockIdx.x:2 threadIdx.y:0 threadIdx.x:0 val:16
blockIdx.y:1 blockIdx.x:2 threadIdx.y:0 threadIdx.x:1 val:17
blockIdx.y:1 blockIdx.x:2 threadIdx.y:1 threadIdx.x:0 val:22
blockIdx.y:1 blockIdx.x:2 threadIdx.y:1 threadIdx.x:1 val:23
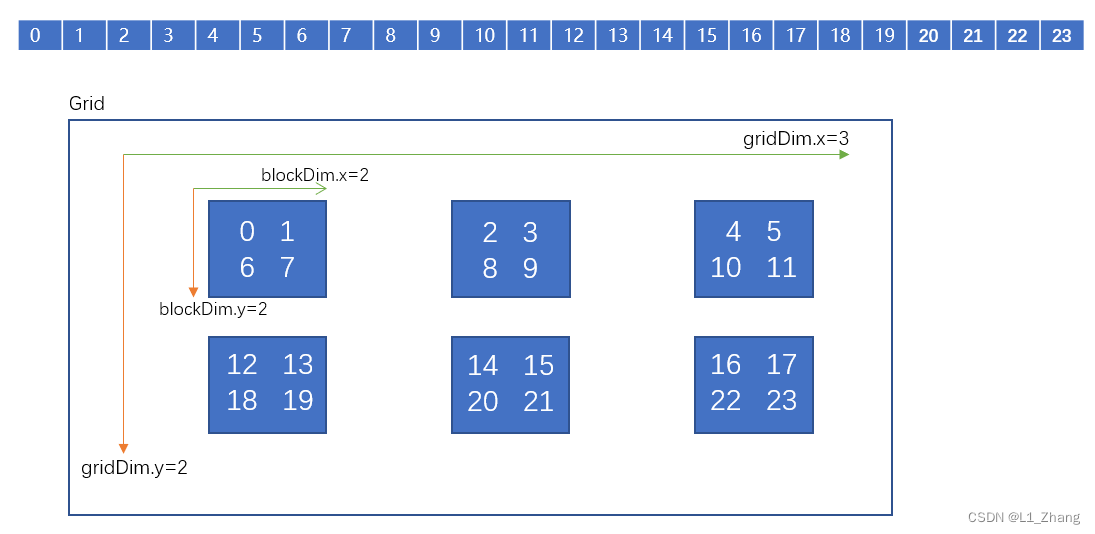
貌似是先切割y方向,比如此例子中,gridDim.yblockDim.y=22=4,所以将24个元素平分成了4份;然后再在x方向分割。最后组装,由各block中的thread访问。