【大数据】YARN节点标签Node Label特性
简介
YARN 的 Node-label 特性能够将不同的机器类型进行分组调度,也可以根据不同的资源要求进行分区调度。运维人员可以根据节点的特性将其分为不同的分区来满足业务多维度的使用需求。YARN的Node-label功能将很好的试用于异构集群中,可以更好地管理和调度混合类型的应用程序。
开启Node-label
默认情况下系统时没有开启node label标签功能的,可以在yarn-site.xml中修改下列配置来开启label特性。
<!-- Yarn Node Labels --><property><name>yarn.node-labels.enabled</name><value>true</value></property><property><name>yarn.node-labels.manager-class</name><value>org.apache.hadoop.yarn.server.resourcemanager.nodelabels.RMNodeLabelsManager</value></property><property><name>yarn.node-labels.fs-store.root-dir</name><value>hdfs://cdp-cluster/yarn/node-labels</value><description>标签数据在HDFS上的存储位置</description></property>
设置这个HDFS的Node-labels存储目录,是因为label信息默认是保存在内存中的,如果将label信息存于hdfs上,重启resourcemanager之后label信息不会因此丢失。
配置步骤:
先按上述要求修改yarn-site.xml并同步到集群各节点中,然后重启resourcemanager节点
添加集群便签
yarn rmadmin -addToClusterNodeLabels label_1,label_2
删除集群标签
bin/yarn rmadmin -removeFromClusterNodeLabels "label_1,label_2"
添加节点标签
yarn rmadmin -replaceLabelsOnNode spark-31:45454,label_1
yarn rmadmin -replaceLabelsOnNode spark-32:45454,label_2
yarn rmadmin -replaceLabelsOnNode spark-33:45454,label_2# 或者下面这种方式
# yarn rmadmin -replaceLabelsOnNode "spark-31=label_1 spark-32=label_2 spark-33=label_2"
需一个一个添加,节点较多时建议写成脚本执行
删除标签
yarn rmadmin -replaceLabelsOnNode "spark-33"查看标签
yarn node -status spark-31:45454
也可以通过Yarn管理页面查看Node Label
node-label webUI 访问地址为 :http://RM-Address:port/cluster/nodelabels
将节点标签与队列关联
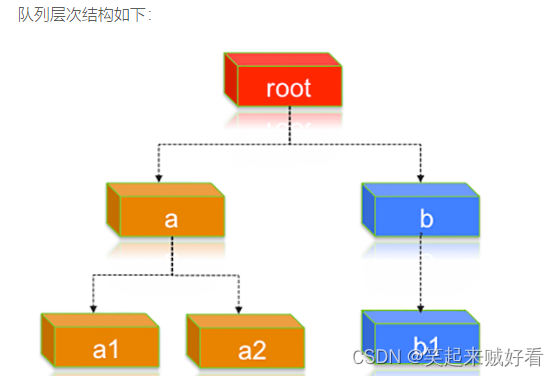
(1)假设集群有8个节点:前3个节点(n1-n3)具有节点标签: x,后3个节点(n4-n6)具有节点标签= y,最后2个节点(n7,n8)没有任何节点标签;每个节点可以运行10个容器。
(2)现在分配资源如下:队列a可以访问节点标签x和y,队列b只能访问节点标签y;
(3)假设按这个需求去分配:队列a占用x 100%,占用y 50%,占用没有标签的40%;队列b占用y 50%,占用x 0%,占用没有标签的60%。
即:a(无)40% + b(无)60% = 1 n7,n8
a(x)100% + b(x)0 = 1 n1,n2,n3
a(y)50% + b(y)50% = 1 n4,n5,n6
(4)在(3)的基础上,a队列有子队列a1,a2;b队列只有b1子队列。
那么假设a1占用a(无)40%,a(x)30%,a(y)50%;a2占用a(无)60%,a(x)70,a(y)50%;
b1 占用b(无)100%,占用b(y)100%。
则具体的资源划分为:
a1:
无标签的节点(n7,n8)可用资源为:20(2个节点的总的容器) * a(无)40% * a1(无)40% = 3.2 个(container)
x标签节点(n1,n2,n3)可用资源为:30 * a(x)100% * a1(x)30% = 9 个(container)
y标签节点(n4,n5,n6)可用资源为:30 * a(y)50% * a1(y)50% = 7.5 个(container)
a2:
无标签的节点(n7,n8)可用资源为:20(2个节点的总的容器) * a(无)40% * a2(无)60% = 4.8 个(container)
x标签节点(n1,n2,n3)可用资源为:30 * a(x)100% * a1(x)70% = 21 个(container)
y标签节点(n4,n5,n6)可用资源为:30 * a(y)50% * a1(y)50% = 7.5 个(container)
b1:
无标签的节点(n7,n8)可用资源为:20(2个节点的总的容器) * b(无)60% * b1(无)100% = 12 个(container)
x标签节点(n1,n2,n3)可用资源为:30 * b(x)0 = 0 个(container)
y标签节点(n4,n5,n6)可用资源为:30 * b(y)50% * b1(y)50% * b1(y)100% = 15 个(container)
无:3.2+4.8+12=20;
x:9+21=30;
y:15 + 15=30;