『python爬虫』05. requests模块入门(保姆级图文)
目录
- 安装requests
- 1. 抓取搜狗搜索内容 requests.get
- 2. 抓取百度翻译数据 requests.post
- 3. 豆瓣电影喜剧榜首爬取
- 4. 关于请求头和关闭request连接
- 总结
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
安装requests
直接安装
pip install requests
使用国内源安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple requests
1. 抓取搜狗搜索内容 requests.get
import requests
query = input("输入你要搜索的内容:")url = f'https://www.sogou.com/web?query={query}'# 写一个 Mozilla的请求头参数
headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
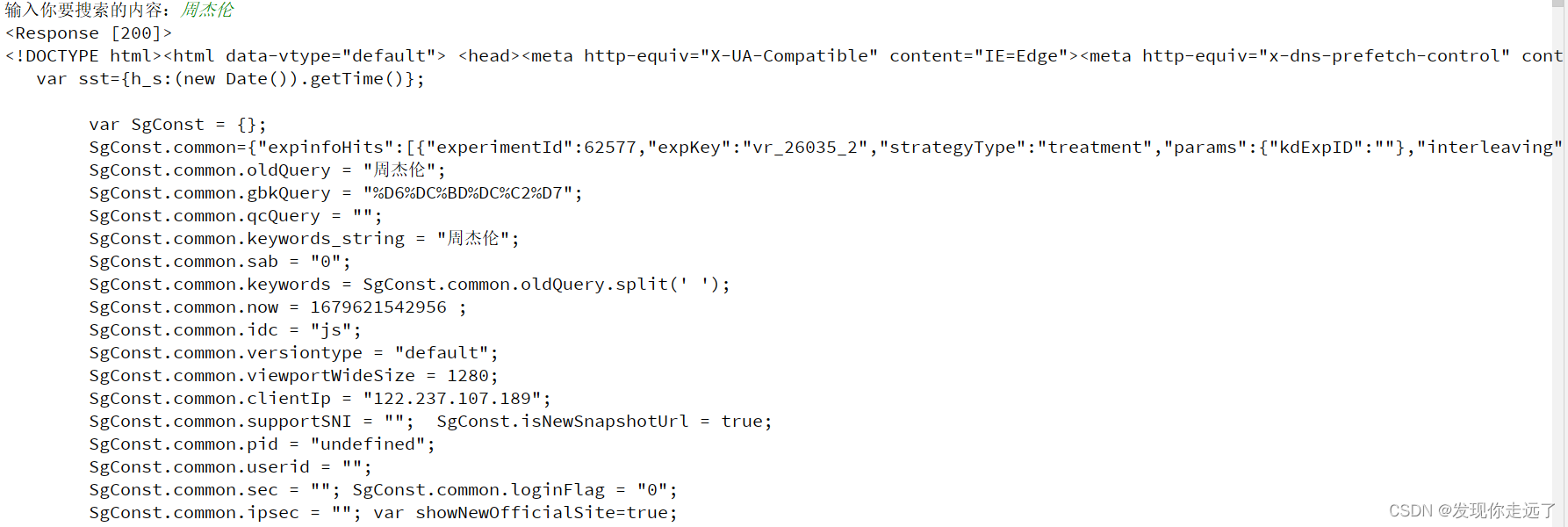
}resp = requests.get(url, headers=headers) # 模拟 Mozilla 浏览器访问网页print(resp)# 返回响应结果 状态码
print(resp.text) # 拿到页面源代码
2. 抓取百度翻译数据 requests.post
https://fanyi.baidu.com/
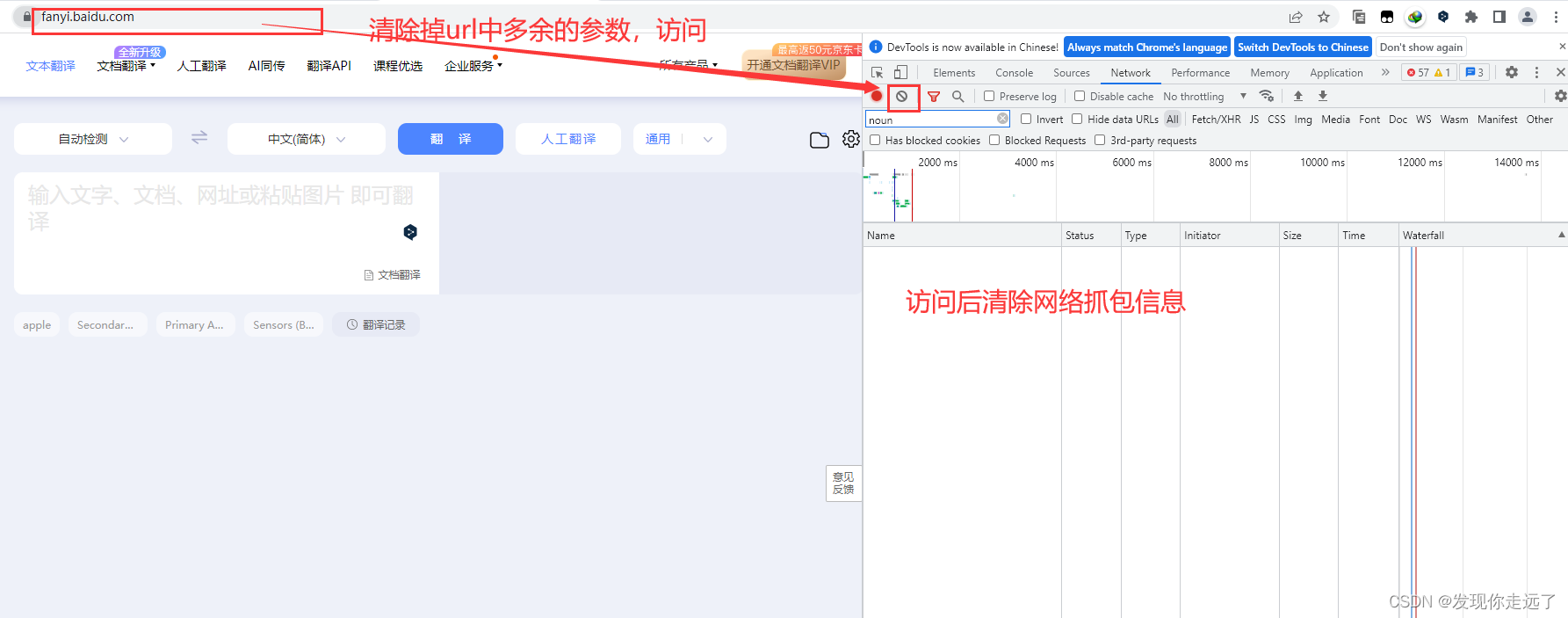
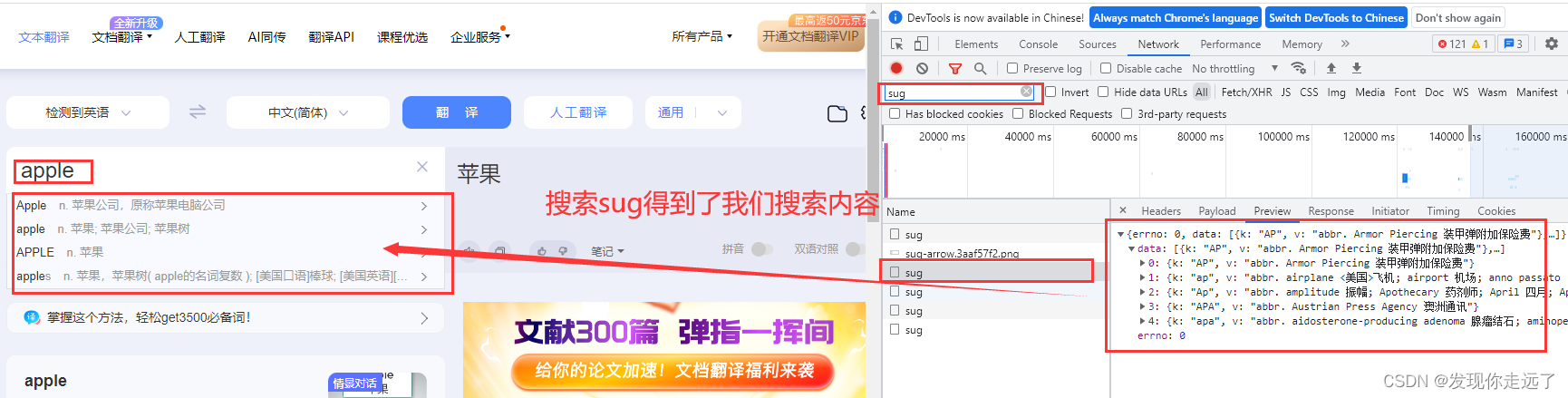
由此可知,我们的请求方式是post,请求url是post的地址https://fanyi.baidu.com/sug
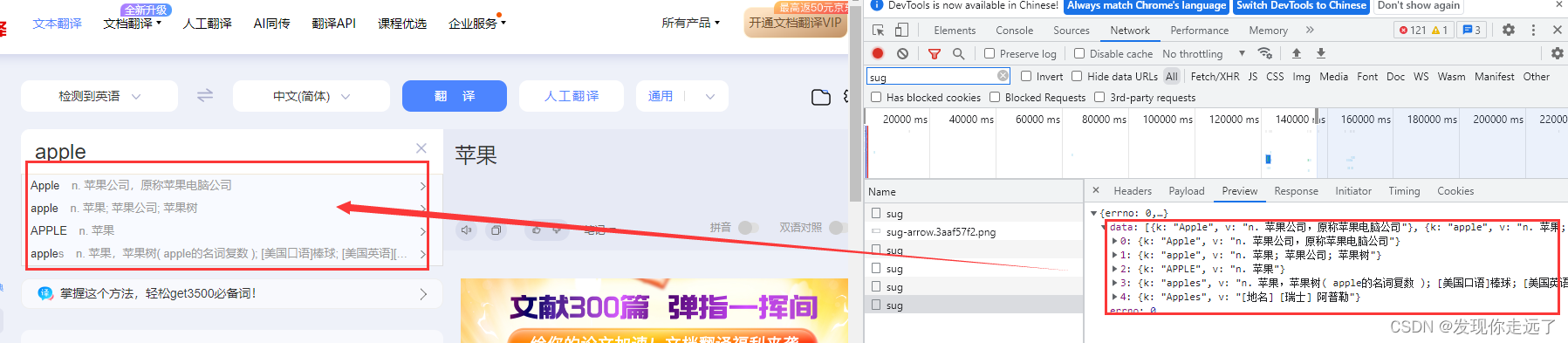
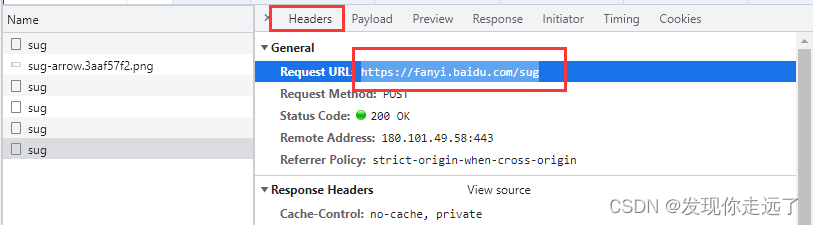
观察一下我们的formdata,在我们逐渐输入apple的过程中,分别post请求,带有kw参数为“a” “ap” “app” “appl” "apple"的五次请求。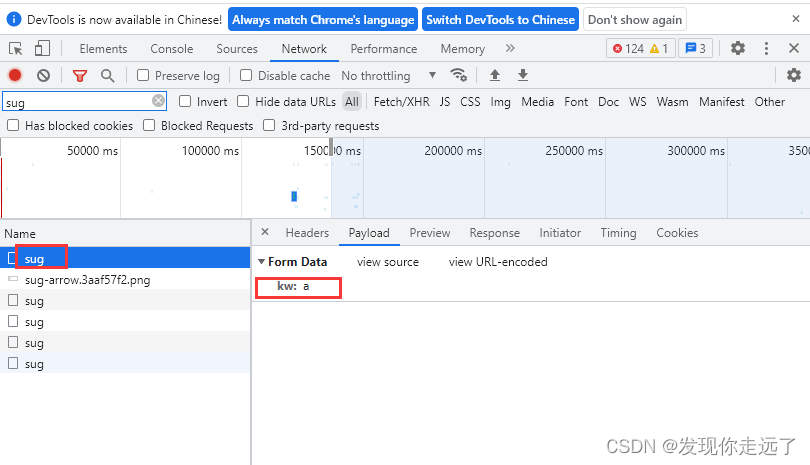
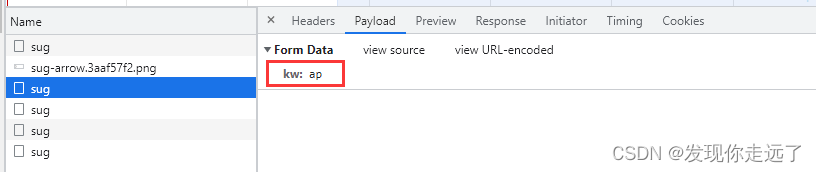
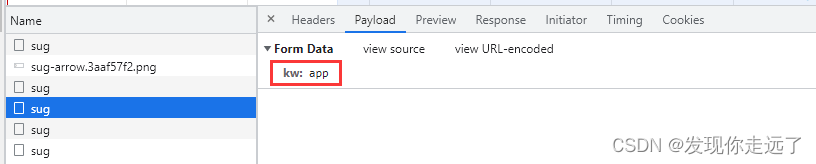
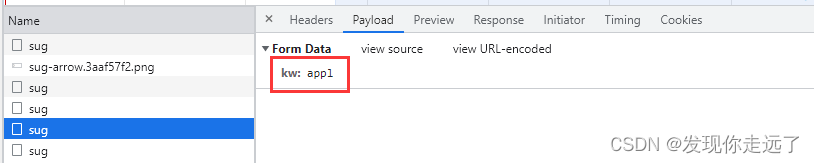
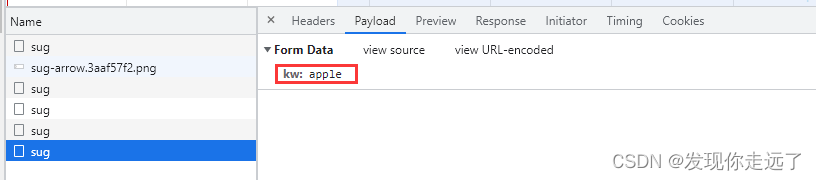
总结:请求地址https://fanyi.baidu.com/sug,请求方式post,请求带有参数kw
url = "https://fanyi.baidu.com/sug"s = input("请输入你要翻译的英文单词:")
dat = {"kw": s
}# 发送post请求, 发送的数据必须放在字典中, 通过data参数进行传递
resp = requests.post(url, data=dat)
print(resp.json()) # 将服务器返回的内容直接处理成json() => dict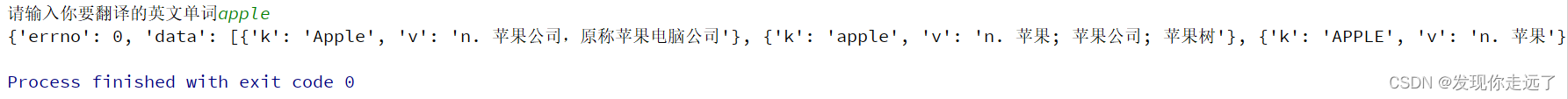
采用逐字逐字地输入搜索关键词,多次搜索的方式,可以快速寻找得到我们需要的请求地址。
post请求的参数一般是formdata。
3. 豆瓣电影喜剧榜首爬取
https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=
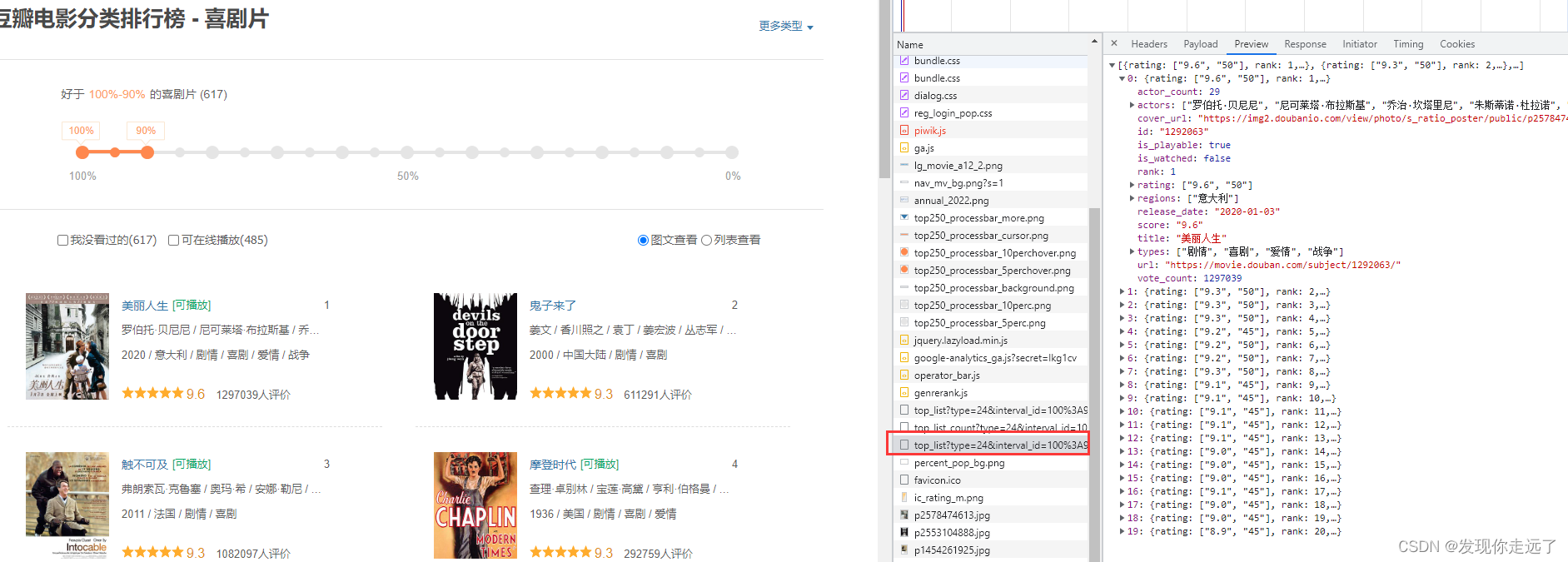
请求方式get 得到了请求的url
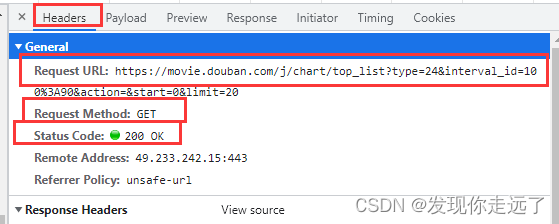
查看请求的参数
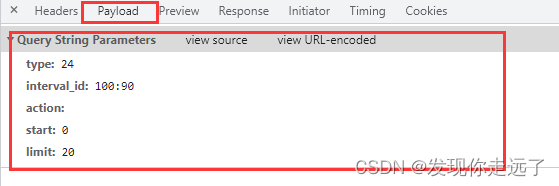
import requestsurl = "https://movie.douban.com/j/chart/top_list"# 重新封装参数
param = {"type": "24","interval_id": "100:90","action": "","start": 0,"limit": 20,
}headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
}resp = requests.get(url=url, params=param, headers=headers)print(resp.json())
get请求的参数一般是query String。
4. 关于请求头和关闭request连接
服务器在爬虫中是可以知道访问网页的是爬虫还是浏览器,通过我们的请求头判断。<Response [418]> 表示服务器的反爬机制拒绝了爬虫
请求后,如果不需要这个request连接需要close关闭,request默认的keep alive是保持的。如果不关闭,会导致同时多个端口爬取目标网页,可能会对网站的负载带来压力(一般情况下不会,因为人家会先把你封掉)
import requestsurl = "https://movie.douban.com/j/chart/top_list"# 重新封装参数
param = {"type": "24","interval_id": "100:90","action": "","start": 0,"limit": 20,
}headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36"
}resp = requests.get(url=url, params=param) #试试不使用请求头的后果? 提示服务器检测到了python爬虫,无法返回信息
print(resp)#<Response [418]> 表示服务器的反爬机制拒绝了爬虫
resp.close()#关闭连接
resp = requests.get(url=url, params=param, headers=headers)
print(resp)
print(resp.json())
resp.close()#关闭连接

总结
大家喜欢的话,给个👍,点个关注!给大家分享更多计算机专业学生的求学之路!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2023 mzh
Crated:2023-3-1
欢迎关注 『python爬虫』 专栏,持续更新中
欢迎关注 『python爬虫』 专栏,持续更新中
『未完待续』