[GraphRAG]完全自动化处理任何文档为向量知识图谱:AbutionGraph如何让知识自动“活”起来?
在当今信息爆炸的时代,企业和研究人员面对大量非结构化文档时,如何高效地提取、存储和查询其中的知识,已成为一个核心挑战。传统的关键词检索早已无法满足深层次语义关联和智能问答的需求。
每天面对成百上千份PDF论文、Excel报告、行业白皮书,你是否也曾陷入这样的困境:
- 想找某篇文献中提到的“钙钛矿氧化物磁性研究”,却要在数十个文件夹里逐个检索?
- 明明记得A技术与B材料有关联,却翻遍文档也找不到具体关联证据?
- 团队积累的核心知识散落在各种文档中,新人上手要花数月才能理清脉络?
今天,我们要介绍的AbutionGraphRag自动化工具,正在重新定义知识处理的逻辑——它能将任何格式的文档一键转化为“会思考”的向量知识图谱,让分散的信息变成结构化的智慧,让隐性的关联自动浮出水面。
一、核心功能:从文档到知识图谱的端到端自动化
该工具集成了小模型文档识别、多模态大模型与向量图数据库,实现了无人值守的文档解析和知识提取流程:
1. 多格式文档解析:把任何文件“拆”成结构化内容
支持PDF、Word等多种格式,利用OCR和深度学习模型自动提取文本、表格、图片中的内容,并统一转换为结构化的Markdown格式,为后续知识抽取奠定基础。
关键能力:
- 保留文档层级(章节→段落→实体),确保知识上下文不丢失;
- 支持非文本元素(如图表、公式)的识别与关联(例如将“图1.2 稀土元素周期表”与相邻分析文本绑定)。

2. 智能知识提取:让机器像领域专家一样“读”懂内容
基于大语言模型可识别通用的实体关系,通过自定义抽取规则:附加提示词(Prompt Engineering)和示例引导(Few-shot Learning),可从行业文档中精准抽取实体、属性以及实体间的语义关系,确保符合领域需求。
示例配置:
# 提示词:控制提取规则(如“不改写原文、保留实体属性”)
ADDITIONAL_PROMPT = """使用原文进行提取,不要改写或重复提取实体。为每个实体提供有意义的属性以增加上下文。"""# 示例数据:引导模型按领域规范提取(如区分“人物”“情感”实体)
EXAMPLES = [{"input": "Romeo... Juliet is the sun.","output": {"entities": [{"vertex": "Romeo", "label": "PERSON", "properties": {"emotional_state": "wonder"}},{"vertex": "Juliet", "label": "PERSON", "properties": {"emotional_state": "joy"}}],"relation": [{"source": "Romeo", "target": "Juliet", "label": "LOVE"}]}}
]
效果展示:
在处理稀土领域的专业材料学论文时,
-
实体关系精准识别:能精准识别“La0.65Ca0.35MnO3”(钙钛矿锰氧化物)、“NH3-SCR”(选择性催化还原技术)等专业术语,并提取“掺杂Ni²⁺影响磁性”等深层关系。
-
保持上下文关系:以原文的章节段落顺序保持上下文连接,并为后续保存为图谱关系。
-
复杂结构的关联识别:如下结果所示,文本和公式被提取为不同的类型(Text、Formulas),但实体识别结果保留了上下文的内容连贯性,能根据上下文为公式进行摘要解释,能从上下文为公式中的实体关系做出属性解释。
{"paragraphs": [{"type": "Text","original": "样品在相对较 高的温度范围内表现出顺磁性, 随着温度的降低, 样品的磁性将从顺磁性变为铁磁性, 在居里温度 T C ( x =0 ) =243 K , T C ( x =0.1 ) =238 K , T C ( x =0.3 ) =105 K 时, 样品 磁性主要表现为铁磁性。 通过 VESTA 软件计算出 样品 x =0 , 0.1 , 0.3 时所对应的 Mn-O-Mn 键角分别 是 169.9205° , 158.8492° , 108.5978° , 可知随着 Ni 的掺杂, 使得 Mn-O-Mn 键角减小, 进而使样品发 生更加强烈的晶格畸变, 减少了 Mn3+ 和 Mn4+ 之间双 交换相互作用[ 14 ] , 导致居里温度降低, 磁化强度减 小。 由于铁磁性和反铁磁性之间的竞争导致样品的 ZFC 曲线和 FC 曲线在较低温区出现了明显的分叉 现象, 表现出可能存在的团簇自旋玻璃行为[ 15-16 ] 。\n\n0.05 T\n\nLa\n\nCa\n\nMn\n\nNi\n\nO\n\n在 磁场下, 多晶样品 0.65 0.35 1x x 3 的 χT -T 曲线如图 3 所示, 未掺杂样品的值随温度 降低而增大, 大约在 216 K 附近达到最大, 而后迅 速减小, 可知奈尔温度为 T N ( x =0 ) =216 K , 样品低于 此温度表现出反铁磁性。 这与之前分析结果相符。 并且可知, Ni 掺杂后样品的奈尔温度分别为 T N ( x =0.1 ) = 215 K , T N ( x =0.3 ) =80 K , 与未掺杂样品的奈尔温度相 比较而降低。 根据反应机理, Ni2+ 部分取代 Mn3+ 离 子导致 Mn3+/Mn4+ 比值发生变化[ 17 ] 。 这样就使 DE 相 互作用减弱, 进而使 T C 和磁矩减小。\n\n4\n\nLa\n\nCa\n\nMn\n\nNi\n\nO\n\n=0\n\n0.1\n\n0.3\n\n图 为 0.65 0.35 1x x 3 ( x , , )在 0.05 T 下的 χ -1T 曲线, 以及对样品 χ -1T 曲线进行 的 Curie -Weiss 拟合, 拟合公式为[ 18 ] :\n\nT\n\n= C /\n\nT -\n\n1","index": 1,"title": "钙钛矿氧化物La0.65Ca0.35MnO3掺杂Ni后的磁性变化","abstracts": "本段落介绍了La0.65Ca0.35MnO3钙钛矿氧化物在不同Ni掺杂量下的X射线衍射图谱和磁化曲线。通过实验数据,发现掺杂Ni后样品的居里温度和奈尔温度降低,磁矩减小,表现出强烈的晶格畸变。","entities": [{"vertex": "La0.65Ca0.35MnO3", "label": "CHEMICAL_COMPOUND", "properties": {"structure": "Pbnm立方钙钛矿结构"}},{"vertex": "Ni", "label": "ELEMENT", "properties": {"doping_effect": "导致Mn-O-Mn键角减小,晶格畸变增强"}},{"vertex": "X射线衍射图谱", "label": "EXPERIMENTAL_TECHNIQUE", "properties": {"purpose": "验证样品的单相性和晶体结构"}}],"relation": [{"source": "La0.65Ca0.35MnO3", "target": "X射线衍射图谱", "label": "ANALYSIS_METHOD", "properties": {"result": "未观察到明显的杂质峰,样品具有良好的单相性"}},{"source": "La0.65Ca0.35MnO3", "target": "Ni", "label": "DOPING", "properties": {"effect": "使居里温度和奈尔温度降低,磁矩减小"}},{"source": "Mn-O-Mn键角", "target": "晶格畸变", "label": "CAUSE_EFFECT", "properties": {"description": "随着Ni掺杂量增加,Mn-O-Mn键角减小,晶格畸变增强"}}]},{"type": "Formulas","original": "\\nu ( T ) = \\mathcal { A } / ( T","index": 2,"title": "钙钛矿氧化物La0.65Ca0.35MnO3掺杂Ni后的磁性变化","abstracts": "本段介绍了钙钛矿氧化物La0.65Ca0.35MnO3在不同Ni掺杂浓度下的磁性行为。通过X射线衍射图谱和磁化曲线分析,发现样品具有良好的单相性,并且随着Ni掺杂量的增加,居里温度和奈尔温度降低,Mn-O-Mn键角减小,导致晶格畸变加剧,双交换相互作用减弱。","entities": [{"vertex": "La0.65Ca0.35MnO3", "label": "MATERIAL", "properties": {"composition": "La0.65Ca0.35MnO3", "structure": "Pbnm立方钙钛矿结构"}},{"vertex": "Ni", "label": "ELEMENT", "properties": {"role": "掺杂元素", "effect": "减少Mn3+和Mn4+之间的双交换相互作用"}},{"vertex": "Tc", "label": "PHYSICAL_QUANTITY", "properties": {"definition": "居里温度", "values": "243 K (x=0), 238 K (x=0.1), 105 K (x=0.3)"}}],"relation": [{"source": "La0.65Ca0.35MnO3", "target": "Ni", "label": "DOPING", "properties": {"description": "Ni掺杂到La0.65Ca0.35MnO3中"}},{"source": "Ni", "target": "Mn-O-Mn键角", "label": "AFFECTS", "properties": {"description": "Ni掺杂使得Mn-O-Mn键角减小"}},{"source": "Mn-O-Mn键角", "target": "Tc", "label": "INFLUENCES", "properties": {"description": "Mn-O-Mn键角减小导致居里温度降低"}},{"source": "La0.65Ca0.35MnO3", "target": "Tc", "label": "HAS_PROPERTY", "properties": {"description": "La0.65Ca0.35MnO3在不同Ni掺杂浓度下表现出不同的居里温度"}}]},{"type": "Text","original": "式中: C 为居里常数, θ 为居里外斯温度, 由居里外 斯拟合得出, 3 个样品的居里外斯温度分别为 270 , 268 , 179 K , 且由图可知, 3 个样品分别在 230~270 K , 207~268 K , 97~179 K 温区内表现出向上背离居","index": 3,"title": "居里外斯温度与样品磁性分析","abstracts": "通过居里外斯拟合得出三个样品的居里外斯温度分别为270 K、268 K和179 K。样品在不同温区表现出向上背离居里外斯行为。","entities": [{"vertex": "居里常数", "label": "PARAMETER", "properties": {"description": "用于描述物质磁性的参数"}},{"vertex": "居里外斯温度", "label": "PARAMETER", "properties": {"description": "通过居里外斯拟合得出的温度值,表示材料从顺磁性转变为铁磁性的临界温度"}},{"vertex": "钙钛矿锰氧化物La0.65Ca0.35MnO3", "label": "MATERIAL", "properties": {"description": "一种具有特定化学组成的钙钛矿结构材料"}}],"relation": [{"source": "居里常数", "target": "居里外斯温度", "label": "CALCULATION_PARAMETER", "properties": {"description": "居里常数是计算居里外斯温度时使用的参数之一"}},{"source": "钙钛矿锰氧化物La0.65Ca0.35MnO3", "target": "居里外斯温度", "label": "PROPERTY_OF", "properties": {"description": "钙钛矿锰氧化物La0.65Ca0.35MnO3的居里外斯温度是其磁性性质的一部分"}},{"source": "居里外斯温度", "target": "270 K, 268 K, 179 K", "label": "VALUE_OF", "properties": {"description": "居里外斯温度的具体数值,分别对应于三个不同的样品"}}]},... }
3. 向量图谱构建:给知识“装上导航系统”
抽取的知识会自动存入AbutionGraph图数据库。AbutionGraph不仅存储拓扑关系,还支持多粒度向量嵌入(实体、段落、章节、全文级别),为后续的语义搜索和社区发现提供支持。
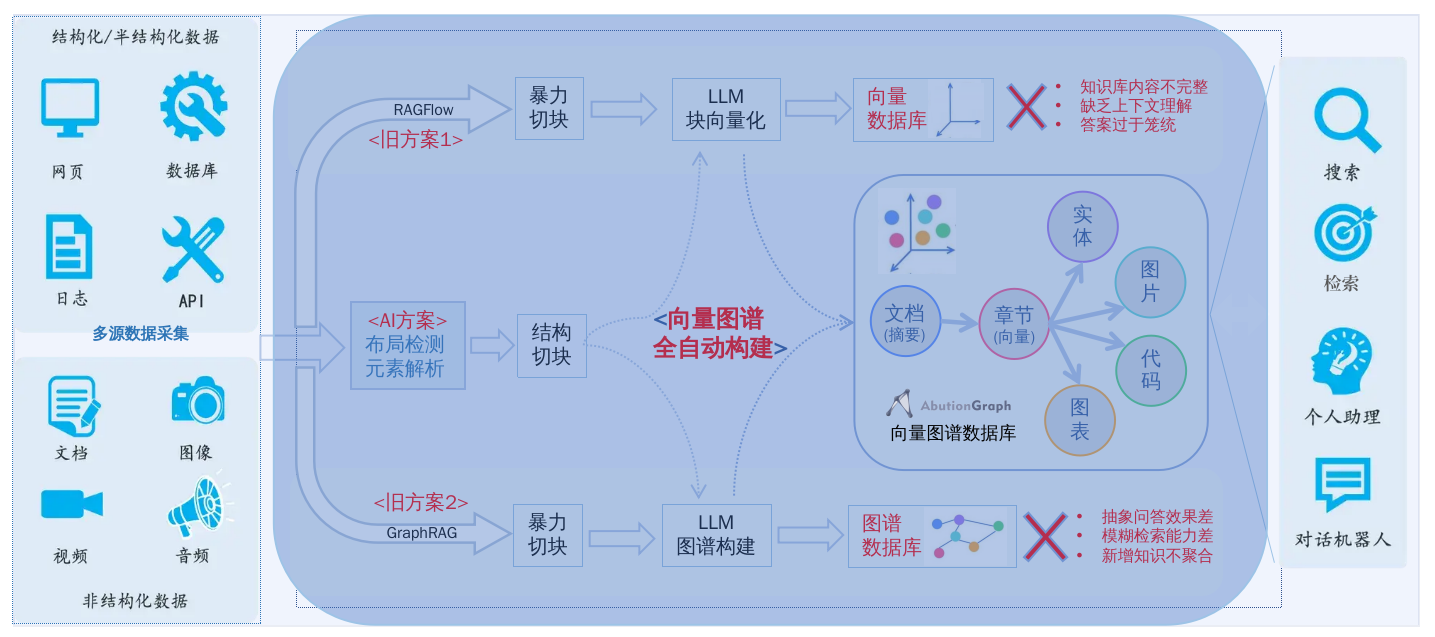
AbutionGraph提供了一套创新的全自动的非结构化数据治理方案,专注于构建高效、高质量、智能的本地知识库。
本地知识库构建: 从 数据接入 -> LLM企业数据问答 ,过程0人工,0知识构建成本,0开发,数据解析完立即可用。
4. 社区发现:自动“聚类”隐藏的知识主题
集成Leiden社区发现算法,自动识别知识图谱中潜在的主题社区或概念集群,形成社区摘要和社区成员语义融合,揭示文档集中隐藏的知识结构。
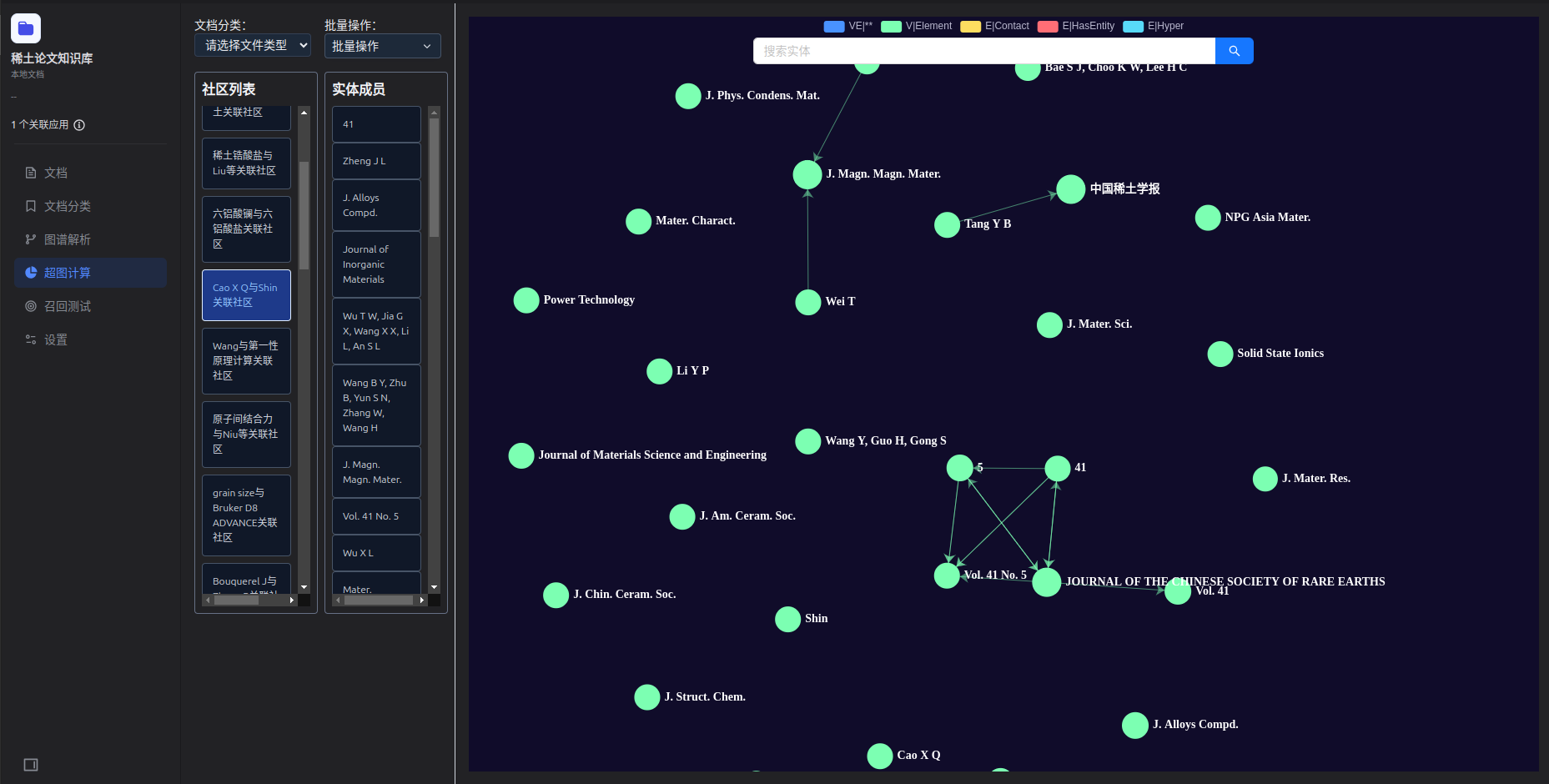
优势:支持增量计算,适合持续增长的文档库,新增文档时无需重新处理历史数据,大幅降低更新成本。
5. 多维度智能检索:想要的知识“一搜即得”
基于构建好的向量知识图谱,工具提供3种核心检索方式,满足不同场景需求:
| 检索方式 | 适用场景 | 示例效果 |
|---|---|---|
| 实体相似检索 | 找相关概念/术语 | 搜索“钙钛矿”,返回“La0.65Ca0.35MnO3”“SrTiO3”等相关材料及相似度 |
| 关系网络检索 | 查实体间的关联 | 搜索“稀土精矿与脱硝性能”,返回“稀土精矿→球磨酸浸→催化剂→提升脱硝性能”的完整关系链 |
| 流式智能问答 | 自然语言提问(RAG) | 提问“La0.65Ca0.35Mn1-xNixO3如何制备?”,返回结合多篇文献的步骤总结 |
代码示例:
# 检索最相关6个知识点
query_text = "福建省龙岩市长汀县河田镇的地理与气候特征是怎样"
response = rag_driver.search(text=query_text, top_k=6)# 流式问答:实时返回答案(边生成边输出)
response = rag_driver.search_call(text="钙钛矿氧化物La0.65Ca0.35Mn1-xNixO3的制备及表征",top_k=8, # 返回前8个相关知识片段stream=True
)
相似节点检索结果示例:
{'刈割': 0.50636005, '福建师范大学地理科学学院': 0.47888565, '等补偿': 0.45831108, 'ICP-MS': 0.36633873, '稀土元素': 0.3640747, '热液喷发物质': 0.35804176}
多维度检索结果示例:
{'question': '福建省龙岩市长汀县河田镇的地理与气候特征是怎样','answer_vertex_sim': {'刈割': 0.50636005,'福建师范大学地理科学学院': 0.47888565,'等补偿': 0.45831108,'ICP-MS': 0.36633873,'稀土元素': 0.3640747,'热液喷发物质': 0.35804176},'vertex_entity': ['ICP-MS: {hll:4; desc:[\'{"用途":"测定稀土元素含量"}\']}','刈割: {hll:1; desc:[\'{"context":"实验操作"}\', \'{"type":"农业操作"}\', \'{"作用":"既伤害植物组织又促进植物生长"}\', \'{"效果":"打破吸收壁垒, 促进稀土吸收"}\']}','福建师范大学地理科学学院: {hll:3; desc:[\'{"类型":"大学院系"}\']}','...'],'vertex_relations': ['中印度洋盆地 → GC11: {weight:1.0}','中印度洋盆地岩心沉积物稀土元素富集特征及赋存矿物 → GC11: {}','中印度洋盆富稀土沉积物中稀土元素赋存特征研究 → GC11: {}','中印度洋盆岩心样品采集及特征描述 → GC11: {}','中印度洋盆岩心沉积物中稀土元素含量 → GC11: {}','中印度洋盆岩心沉积物中稀土元素赋存特征 → GC11: {}','中国大洋矿产资源研究开发协会( COMRA ) → GC11: {weight:1.0}','全矿物分析中GC04和GC11岩心样本的检测层次 → GC11: {}','岩心沉积物中矿物组成及含量差异 → GC11: {}','岩心沉积物矿物组成特征及分析方法 → GC11: {}','...'],'vertex_neighbors': ['GC04','GC11','HNO3-H2O2法','Super304钢','...'],'vertex_belong_chapters': ['##### 全矿物分析','##### 单矿物原位微区分析','##### 成矿的控制因素','....'],'vertex_belong_para_contexts': ['GC03、GC04和GC11岩心沉积物的主微量及稀土元素组成','GC04和GC11岩心沉积物中稀土元素含量特征','...'],'vertex_belong_chapter_contexts': ['# Ce 2 ( SO 4 ) 3 对铜电沉积层晶粒细化的作用研究','# Dy 13.60 Ni 3.34 In 3.06 合金磁相变与磁热性能研究','...']
}
二、API核心类详解:AbutionGraphRagDriver
AbutionGraphRagDriver 是这个自动化流程的核心驱动类,提供了简洁而强大的编程接口。
1. 初始化
仅需简单配置,即可进行文档处理成向量图谱并更新到知识库。
gdb_client = AbutionConnector("http://localhost:9090/rest")
# gdb_client.create_rag_graph("RareEarthPaper")
graph = gdb_client.Graph("RareEarthPaper")MODEL_CONFIGS = {"text": { # 文本模型(仅处理文字对话)},"image": { # 多模态模型(处理文本+图片)},"embed": { # 向量模型(生成文本嵌入向量)}
}# 功能入口
rag_driver = AbutionGraphRagDriver(model_configs=MODEL_CONFIGS, # 多模型配置(文本、视觉、嵌入)work_path="storage/", # 工作目录,用于存储中间文件graph_instance=graph # AbutionGraph连接实例
)
- model_configs: 配置用于文本理解、视觉处理和向量嵌入的模型(例如通义千问Qwen系列)。
- graph_instance: 已初始化的AbutionGraph连接器,是所有知识数据的目的地。
- work_path: 处理过程中的中间文件(如解析后的Markdown、抽取的JSON等)会按文档存储在此目录下。
2. 核心方法
-
pipeline_to_knowledge(): 一站式管道方法。传入一个文件路径,即可自动完成上述所有步骤(解析、抽取、建图)。rag_driver.pipeline_to_knowledge(file_path="path/to/your/document.pdf",additional_prompt=ADDITIONAL_PROMPT,examples=EXAMPLES ) -
detect_communities(): 在构建好的图谱上执行社区检测,发现知识集群。rag_driver.detect_communities(increment=True, # 增量计算entity_sim=0.5, # 实体相似度阈值edge_sim=0.75 # 关系相似度阈值 ) -
search()与search_call(): 强大的检索功能。search(): 返回结构化的知识结果,包括实体、关系和上下文信息。search_call(): 在search()的基础上,将结果送入大模型进行总结和润色,直接生成流畅的问答结果,是开箱即用的RAG接口。
支持多粒度检索
您可以指定检索的粒度级别:
# 可选粒度: ["实体级别", "段落级别", "章节级别", "文件级别", "超边级别", "超点级别"]result = rag_driver.search(text="查询内容",top_k=10,rag_type=["实体级别", "段落级别"] )支持子图隔离检索
如果使用了classify_id创建了多个子图,可以指定检索范围:
result = rag_driver.search(text="查询内容",top_k=10,classify_list=["ProjectA", "ProjectB"] # 只在指定子图中检索 )
3. 图查询语言
使用AbutionGraphRagDriver可以满足知识库构建、更新和检索的任务,当然您也可以使用AbutionGraph的原生图查询语言或者Cypher、Gremlin、GraphQL等图查询语言定制内容。
一跳节点查询示例:
graph.V('稀土元素').BothV().exec()
一、什么是“向量知识图谱”?为什么它比传统知识库更强?
传统的文档管理工具,要么把文档当“文件”存(如文件夹),要么把内容当“字符串”搜(如关键词检索),但从未真正“理解”知识。而向量知识图谱的突破,在于它同时具备两种核心能力:
- “关系脑”:像人类大脑一样记录实体间的关联(如“La0.65Ca0.35MnO3”与“磁性”的影响关系、“稀土精矿”与“脱硝性能”的因果关系);
- “语义眼”:通过向量嵌入技术,让机器能“看懂”语义(比如自动识别“CeO2”与“氧化铈”是同一物质,即使文档中从未明说)。
这种“关系+向量”的双重特性,让知识不再是孤立的文字,而是能被检索、推理、关联的“活数据”。
三、什么是“向量知识图谱”?为什么AbutionGraph比传统向量检索知识库更强?
市面上知识图谱工具不少,但AbutionGraphRag的独特优势在于“全流程一体化+深度适配专业场景”:
1. 零代码门槛,却能深度定制
无需手动设计图谱结构、标注数据,基础流程“一键运行”;同时支持通过提示词、示例数据、相似度阈值等参数,精准适配科研、制造、金融等不同领域的知识特点。
2. 原生向量图数据库,性能碾压“拼凑方案”
AbutionGraph是“原生支持向量”的图数据库,无需额外对接向量库(如Milvus),避免数据同步问题。即使处理数十亿级实体关系,鉴于分布式特性,也能保持亚秒级检索响应。
3. 超图模型,轻松处理复杂知识
支持“超点”(如“某实验团队”作为一个整体节点)和“超边”(如“材料A+工艺B→性能C”的多实体关系),比传统图模型更自然地表达复杂知识(如科研协作网络、多因素影响关系)。
4. 多模态融合,不遗漏任何信息
不仅处理文本,还能解析文档中的图片、表格、公式,特别适合科研论文、技术手册等复杂文档——例如自动关联“XRD图谱”与对应的“物相分析结论”。
4. 语义计算 / 知识融合 / 动态知识更新
基于时序图谱自动聚合计算的特性,相同节点的实体属性可以自动聚合更新,且向量语义能够自动合并,实现效果:“女生”+“皇帝”=“女王”,这对于不断新增文档的知识库非常有用,因为相同的实体在跨文档中得到的信息大概率不同,语义合并能够丰富检索效果。
四、谁在需要AbutionGraphRag?
- 科研人员:处理数百篇领域论文,自动生成“稀土材料研究脉络图”,将文献综述时间从“周级”压缩到“小时级”;
- 企业知识库:将技术手册、故障案例、项目报告转化为可检索的知识图谱,新员工上手速度提升50%;
- 智能客服:基于产品文档构建问答系统,精准回答“某型号设备的材料成分”“故障代码E102的解决步骤”等问题;
- 金融风控:分析企业年报、舆情新闻,自动构建“公司-关联方-风险事件”图谱,提前预警传导风险;
- 工作流/智能体:绑定Dify等AI智能体业务创新平台,实现更精准有效的知识检索环节。
结语:让知识从“沉睡”到“流动”
在这个信息过载的时代,真正的竞争力不是拥有多少文档,而是能从文档中快速提炼、关联、应用知识的能力。
AbutionGraphRag正在做的,就是让知识处理从“人工逐条整理”变成“机器自动构建”,从“关键词匹配”变成“语义深度理解”。
不妨试试这款工具——让你的文档知识不再沉睡,而是成为能检索、能推理、能创造价值的“活资产”。
👉 立即访问官网。