数字IC后端设计实现常见后端问题解析
今天给大家分享下咱们社区IC后端训练营学员提问的数字IC后端实现常见问题。
数字IC后端培训教程之数字IC后端项目典型问题解析
Q1: 摆放pin的一些问题,教程中有如下命令:editPin -pin mcu_top_data_0 -layer M3 -assign ($x $y) -pinWidth 0.10 -pinDepth 0.5 -global_location -fixOverlap 1 -fixedPin 1 -edge 5 -snap TRACK,我有如下问题:
a)对T28工艺,可放pin的layer层有哪些?
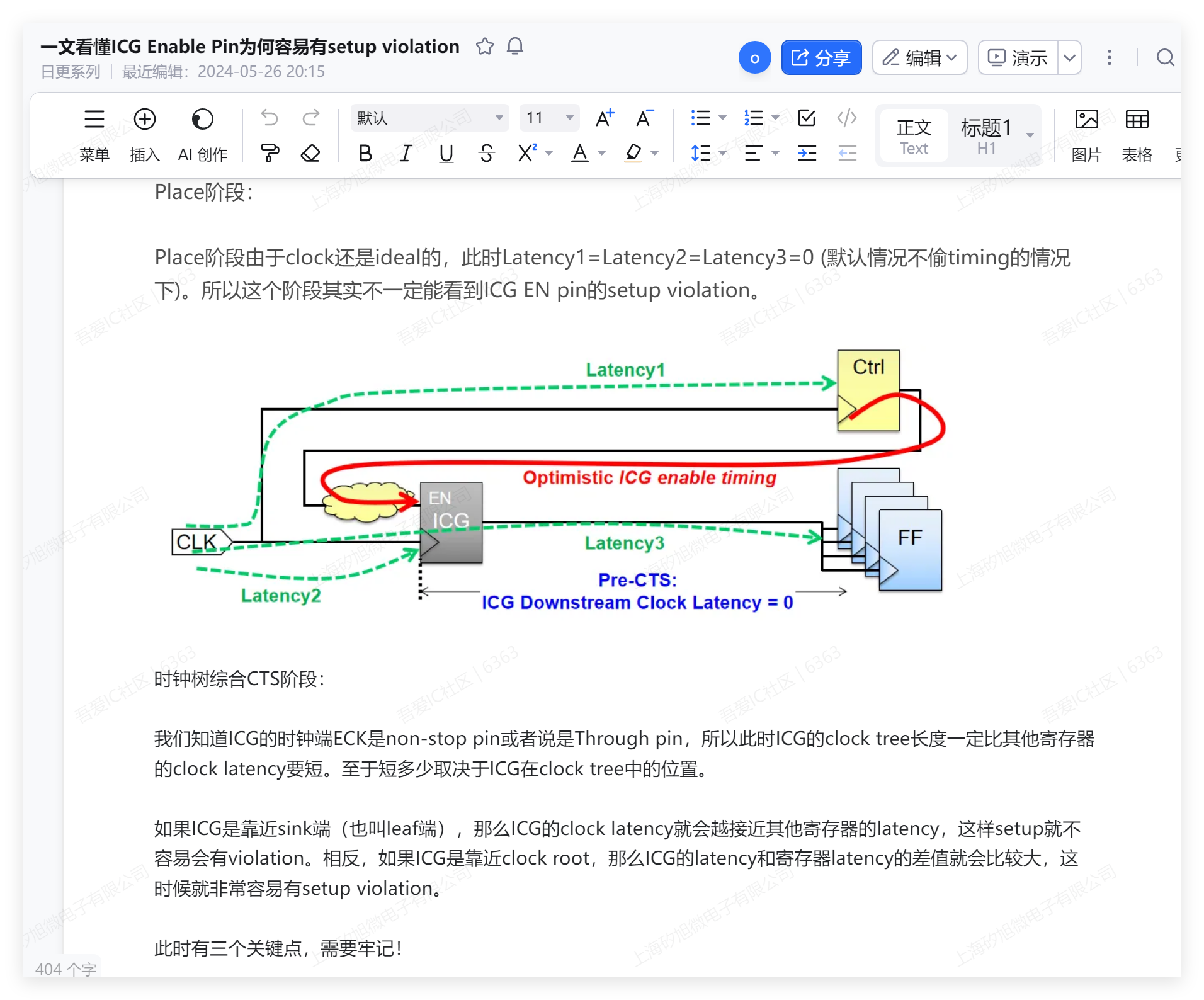
理论上能用于绕线的层都可以做为摆放pin的层。比如我们训练营项目有M1-M10。但由于高层最小线宽比较宽,因为我们尽量使用低层metal来摆放pin,比如M1-M6(M1和M2往往是rail metal,也不怎么用,怕有pg short)。
b)为啥把mcu_top_data_0放到M3 layer?
这里仅仅是示例,并没有严格限制。block level出pin用哪一层是灵活的,只要确保和top 连接得起来,没有drc即可。
c)如下六种典型pin该放哪层?VDD、VSS、Clock、Data、reset、set
没有严格限制。
c)pinWidth 可用范围?为何选0.10?跟所在层metal宽度一样?
pin width最小可以从0.05到metal的max width。但一般我们选择的是0.05和0.10两个档位。太宽反而在连接的时候容易有drc,而且也浪费更多的绕线资源。
d)pinDepth可用范围?为何选0.50
这个也是灵活的,一般选择0.5-0.7。metal有最小面积的约束条件,即pin width* pin depth要大于规则面积,否则会有drc。因此只要没有metal的min area drc即可。
e) 对于top design,io pad 也是分层放置的吗?
对于top level来说,io pad是一颗cell,需要手工摆放或者通过脚本来摆放。它是一颗cell,类似macro或IP,因此没有层的概念。
拓展:如果要求子模块的io port双层出pin,我们应该如何实现?clock port应该摆放在什么样的位置比较好?
数字IC后端经典笔试题IC秋招笔试题之时序报告解析
Q2:我自己分步长tree还有问题,比如common path仍然很短。能帮忙看看原因吗?
分步长出的tree:
所用本:/home/ic090/Desktop/mywork/scripts/456_cts_tree_test.tcl
我合并了04、05、06三个脚本并在里头加入了自己的修改
修改以aron为关键字可以搜到:
log: /home/ic090/Desktop/mywork/work/456_cts_test.log2
design: /home/ic090/Desktop/mywork/save/postCTS2.enc.dat
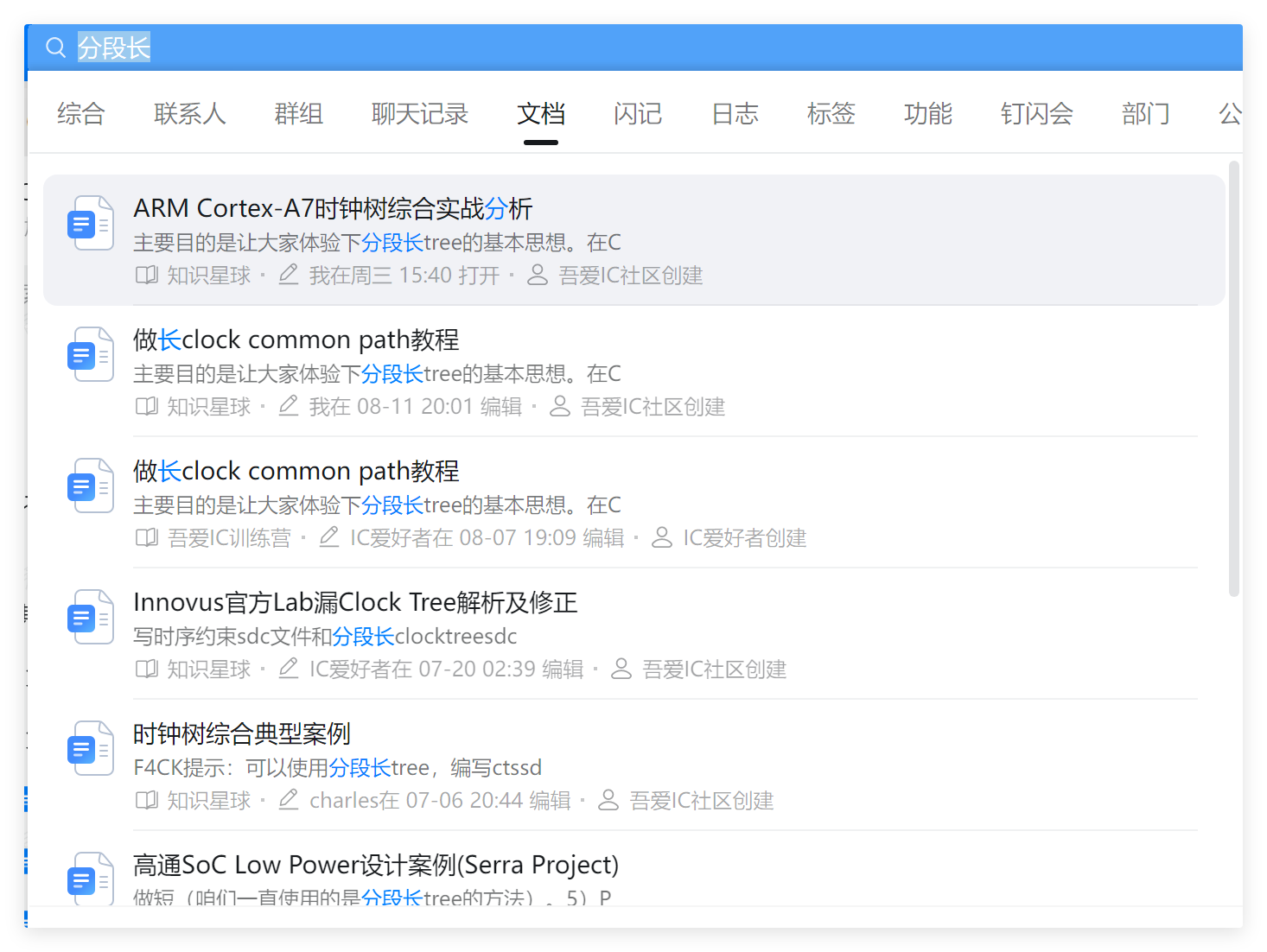
数字IC设计实现之分段长clock tree典型案例(clock tree synthesis)
看起来是guide buffer被删掉了。建议提供下端口号和密码做进一步分析。
innovus将pin设为ignore pin的命令是啥?
set_ccopt_property sink_type -pin $pin_name ignore
Q3: dont touch 是用来干什么的,和dont use有什么区别?
dont touch就是让工具不去优化所设置的net或者cell,而dont use则是告诉工具不去使用指定的lib cell类型。
place 阶段工具会有一步自动删除buffer tree,这样做的原因是什么?
因为设计上可能会有一些工具认为是冗余的buffer tree,所以工具一般在做之前会把这类buffer先删掉再做它的优化。目的是为了让数据更干净,优化效果会更好。如果设计上有一些buffer是不希望被工具优化的,可以通过设置dont touch来实现。
Q4: useful skew是在哪一步修timing用的啊?使用的时候怎么去设置?下图中说的向前后级路径借余量,是怎么借的,能举个例子解释一下吗?
在cts阶段使用,如果用的是innovus,那么ccopt自动会启动useful skew优化引擎来进行优化。
useful skew就是调整capture path或者launch path上的delay值,来实现先前或者向后借时序,比如后一级的timing path上面有5ns的余量,而前一级的timing path上面有5ns的违例,那么我们就可以做长一级timing path上面的capture path(相当于后一级timing path的launch path也做长了),那么后一级timing path上的余量就可以被前一级timing path给借走了,这样就可以使timing满足要求。
数字IC后端项目典型问题之后端实战项目问题记录(2025.04.24)
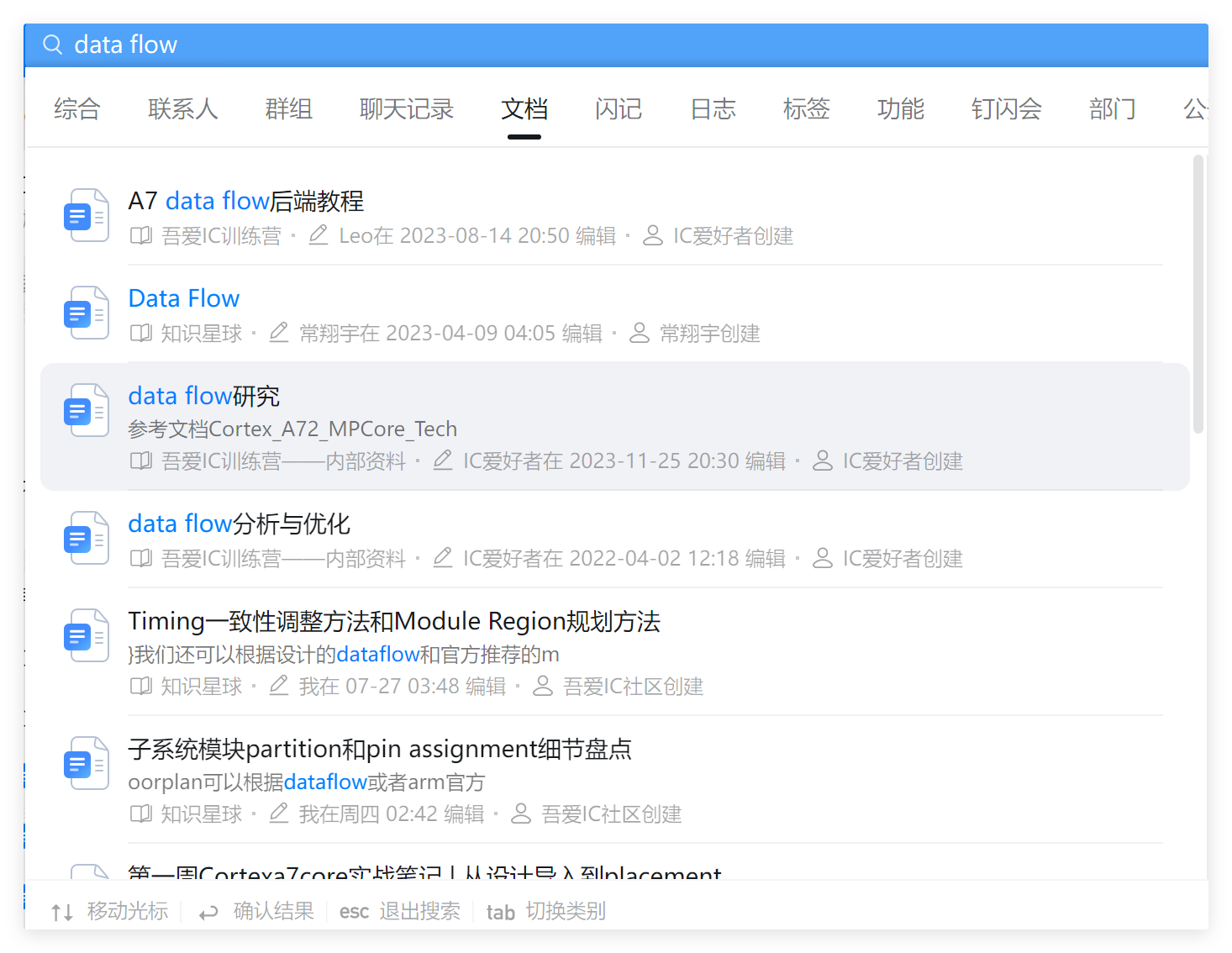
Q5: 数据流是不是只规定了stdcell的摆放并没有规定macro? 如下图所示module的分布是依照数据流摆放的,这些module位置的摆放工具是如何确定的?是通过脚本来摆的还是根据netlist定义好的?如何让同一module里的stacell集中摆放,不出现分散的情况?
macro也是需要根据数据流的走向来摆放的,可以看下下面这份文档,只不过macro是我们手动摆放的。
想要把某个module放置在一起,可以通过module constraint,比如添加region来实现。
https://alidocs.dingtalk.com/api/doc/transit?spaceId=5094368790&dentryId=45246066555&corpId=dingcd9df953ab4a15574ac5d6980864d335https://alidocs.dingtalk.com/api/doc/transit?spaceId=5094368790&dentryId=45246061469&corpId=dingcd9df953ab4a15574ac5d6980864d335
Q6: clock gate cell是用来干什么?
可以看下这篇推文。就是用来做时钟门控用。在时钟不用的时候可以把时钟关掉来节省时钟上的功耗。这个是面试经常会被问到的,需要引起重视。
https://alidocs.dingtalk.com/api/doc/transit?spaceId=5094368790&dentryId=45246111093&corpId=dingcd9df953ab4a15574ac5d6980864d335
下面(1)中route之后timing变差是因为place阶段设置的过于乐观导致的吗?下面(2)说的不太理解,是让工具在那个阶段看到violation,能举个例子解释一下吗?
另外涉及到clock uncertainty的设置,Foundary只会提供一个PT signoff的参考值。PR阶段的clock uncertainty值的取值取决于每个阶段的timing和PT看到timing的一致性。
(1)比如place阶段只有20ps violation,跑到ROUTE后pt看到有100ps violation,说明PR阶段留的margin不够,需要进一步让工具做时序优化。
(2)那想要让工具做优化就得让工具看到violation,那方法就是加大clock uncertainty(当然还有其他方法)。总之目的是让工具做最好的优化。所以clock uncertainty需要大家不断的去尝试修改。
route之后timing变差是因为place阶段设置的过于乐观导致的,那我们要让place阶段的timing更加悲观点,就是需要加大place阶段的clock uncertainty,让工具加大优化的力度。
Q7 : 什么是timing driven? congestion driven? SI driven ?
Timing driven是根据时序驱动来放置std cell或者绕线,工具会将有逻辑关系的cell放的近一些来满足timing。congestion driven是根据阻塞驱动来摆放std cell,这个时候工具不会将cell摆放的特别密,避免congestion过大而导致后续绕线绕不出去的问题。
可能初学者会觉得place阶段还没绕线,如何做congestion优化呢?那是因为place过程tool会通过global route来估算design中的绕线情况,从而根据估算的congestion状况来进行placement的优化。实际情况工具会在这两方面中间做一个trade off。
SI driven就是让工具在绕线的时候考虑串扰的影响,避免长距离并行绕线,避免SI的产生。
Q8: routeopt后max_transition的violation只有12ps,pt跑完sta后有30ps,跑完dmsa后,几乎没有了violation,但后面回到pr做完eco后会增加到三百多(如下图),不太清楚哪出问题了。
报告中第一个点u_ddata_bank2/CLK的max transition一看就是marco之间channel没有预留好导致插hold buffer被丢的比较远导致的。可以看下之前这个案例分享。
其他的点,比如Net net_PTECO_HOLD_NET583,它接了三个pin,分别是图中D[19],PTECO_HOLD_BUF13/I和PTECO_HOLD_BUF583/Z。有经验的人一看就是hold buffer被legalize太远导致的。建议把NET583选中就能一目了然。也可以选中那三个pin看飞线也可以的。
如果还有实践的问题,欢迎联系我们进行远程协助解决。
https://alidocs.dingtalk.com/api/doc/transit?spaceId=5094368790&dentryId=45246088387&corpId=dingcd9df953ab4a15574ac5d6980864d335
Q9: 请问有没有脚本可以把ICC2的时序报告分各个path group分别报出WNS和 TNS等信息?
report_qor可以实现
https://alidocs.dingtalk.com/api/doc/transit?spaceId=5094368790&dentryId=45246106289&corpId=dingcd9df953ab4a15574ac5d6980864d335
Q10: 《两个工具highlight timing path的方法》 用里面提到的方法在innovus里面高亮了timing path。但是只能高亮DATA line的部分。lunch clock和capture clock都不行。请问有什么办法把clock开始的完成路径高亮出来么?
用这个proc就可以报。下面的这篇文章介绍过这种方法,建议好好看下。
source hilite.tcl (这个脚本是一个proc,就是一个子程序)
hilitePath -report_timing_args $path -launch_clock_path
https://alidocs.dingtalk.com/api/doc/transit?spaceId=5094368790&dentryId=45246111074&corpId=dingcd9df953ab4a15574ac5d6980864d335
既然io相关的时序违例目前都不用管,是不是可以改一下sdc缓和一下,每次都报出来一大堆,看着很不方便。
如果In2Reg的group有很大的setup violation,我们可以通过slackAdjustment来调整slack。通过这个方法可以避免工具优化这部分假path而没有优化到真正需要优化的path。
setPathGroupOptions reg2out -slackAdjustment 0.2 -effortLevel low
setPathGroupOptions in2reg -slackAdjustment 0.2 -effortLevel low
比如原来reg2out的wns有-0.3ns violation,通过这个命令设置后工具会把-0.3ns+0.2ns 即-0.1ns作为这个group的WNS来做优化。其实就是做一个加法操作。
如果希望工具看到的WNS更大,那我们可以设置一个负值的slackAdjustment即可。
这个专题之前已经分享过了。
Q11: 想问一下这个读入顺序,正常不是先修drv吗?这里 是先修setup吗 这里是否应将所有的corner进行合并去重后,在吃进去?如果这样按单独corner直接插入是否会造成反复插入或者冗余的现象
这里并没有涉及到corner的概念。这个步骤是把pt的eco脚本转化成innvous能认的脚本(因为两家工具命令是完全不一样的)。转化后再把脚本直接读入innvous database。所以这里思路很清晰,把脚本分成hold,setup和transition fixing脚本。
dmsa出脚本时在fix_eco_drc或者fix_eco_timing时会涉及setup magin hold margin,这中margin设置的原则是什么?
这些值一般是经验值,可以直接参考。这里是告诉工具在修hold时要注意看setup margin,而且需要确保有30ps的setup slack才能去修这个hold 。因为我们知道修hold是要插hold buffer的,插多了是会把setup margin吃掉的甚至出现setup变差很多的情况。