Transformer中的编码器和解码器是什么?
今天,我们来具体介绍Transformer的架构设计。
一个完整的Transformer模型就像一个高效的语言处理工厂,主要由两大车间组成:编码车间和解码车间。
首先来看这幅“世界名画”,你可以在介绍Transformer的场景中常常看到这幅图,这就是《Attention Is All You Need》论文中所画的Transformer架构,左边就是我们说的编码车间,右边是解码车间。
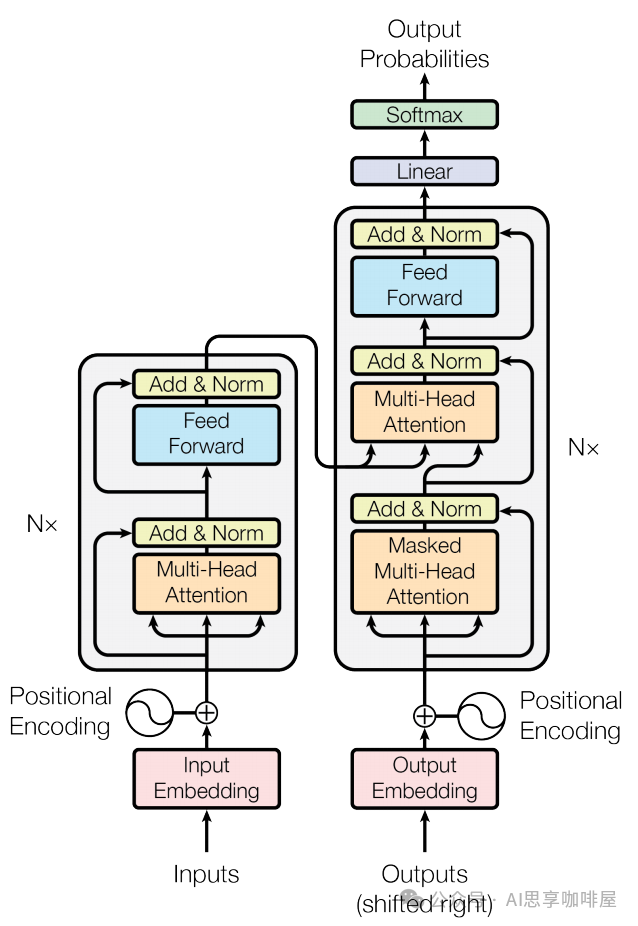
编码器(Encoder)车间:
任务是深度阅读理解输入信息(比如一句中文)。
1.将输入转成数字信息(即粉色框中的嵌入):将输入序列的每个token映射为高维向量。
2.再进行位置编码(即图中左侧的Positional Encoding),前文中提到过,通过正弦余弦函数来增加词向量的位置信息,弥补Transformer不考虑词序先后的缺陷。
3.编码团队(即灰色框):由N个(即图中左侧的N*)结构一致的“编码工人团队”(Encoder Layer)串联组成。

团队的工作流程:
3-1自注意力小组(即橙色框中的多头注意力):运用自注意力机制(前一篇中提到过,Transformer的最大创新),让当前句子里的所有词疯狂交流、互相理解,形成富含上下文关系的词表达。
3-2前馈神经网络小组(即蓝色框中的FFN):对每个词进行更深层次、更复杂的特征提取和变换(可以想象成给每个词的“升级版自我表达”再做一次深度加工和升华)。
3-3残差连接与层归一化(即黄色框中的Add & Norm):前面两个小组每次工作完,还要通过“传送带”(残差连接)快速传递,避免信息丢失;同时有“质检员”(层归一化)确保信息稳定、易处理,传给下一个人。
N个团队层层加工,让输入句子的理解越来越深刻、精准。
解码器(Decoder)车间:
任务是根据编码车间的深刻理解,生成输出(比如对应的英文翻译)。
1.输出嵌入(粉色框)和2.位置编码(右侧的PE)同编码车间。
3.解码团队(灰色框):同样由N个结构相似的“解码工人团队”(Decoder Layer)串联组成。
团队的特殊技能:
3-1掩码自注意力小组(下方橙色框中的掩码多头注意力):处理已生成的部分输出(比如已经翻译出来的前几个英文词)。这里的“掩码”(Mask)很关键,它让每个词在交流时只能看到它前面的词(已经生成的),看不到后面的(还没生成的),确保生成过程是顺序的、合理的(不能提前知道答案),即这是个自回归过程。
这里初学者不太容易理解,我们前面介绍过自注意力的特点,就是可以全局同时并行处理,不用按序逐个循环处理,为什么这里的掩码注意力是自回归的,只能看到前面的词,不能看到后面的内容呢?
这里的误解是源于,这个世界名画是介绍模型训练,就是模型自己来找到这么多的参数的过程。注意!这里并不是你已训练好了模型,输入prompt,让模型给出回答。
在训练模型的过程中,我们是知道输入的这句中文对应的英文翻译的答案的,我们就是用这些信息去训练模型。在生成任务的过程中,模型是需要逐步预测序列的下一个token的,如果不进行掩码,由于自注意力机制是全局的,模型就能提前看到未来生成的信息,直接知道生成的答案,其实就是训练时在作弊,会破坏自回归生成逻辑,预测结果将偏离正式概率分布,所以这就是为什么需要掩码。
在数学处理上,其实很简单,就是只保留注意力中的下三角区域,即当前位置及其之前的注意力权重,还是用上一篇中的“我爱吃苹果”举例,掩码注意力如下图。

3-2编码-解码注意力小组(中间橙色框中的多头注意力,起到关键桥梁作用):这是Decoder的巧妙设计,这里的工人会专门去“凝视”编码器车间最终输出的那个深刻理解(代表整个输入中文句子的精华信息)。他们让正在生成的每个英文词,都能有选择地、动态地聚焦于输入中文句子中最相关的部分。用我们翻译的例子来说明,我在翻译某个中文对应的英文时,我同时要关注这个中文的信息,这样翻译的结果会更加“信达雅”。
3-3前馈神经网络小组(蓝色框):同样进行深度特征处理。
3-4传送带与质检(黄色框):同样保证信息流稳定高效。
4.最终,解码器车间的输出经过一个简单的“包装处理”(紫色框中的线性层)和“概率转换”(绿色框中的Softmax层),就能预测出下一个最可能的词是什么了。一个个词生成,就得到了最终的翻译结果。
前面为了方便理解,我们用了工厂流水线的例子来进行比喻,读到这里,大家已经有个大致的了解,那我们再简单总结一下编码器和解码器。
编码器(Encoder)就是将输入序列(例如一句中文)转换成一个富含上下文信息的、固定大小的表示序列,每个输入元素对应一个输出向量,每个向量都包含了整个输入序列的上下文信息。
解码器(Decoder)就是利用编码器提供的上下文信息,逐步生成输出序列(例如目标语言的翻译)。
助理deepseek进行了下述比较总结:
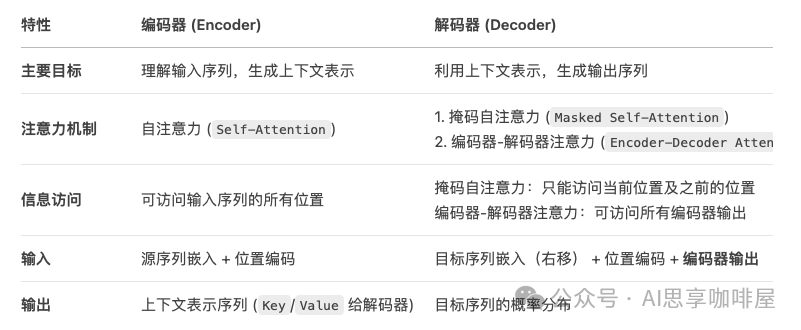
这里再额外说明一下,2017年发表的《Attention Is All You Need》论文中所述的Transformer是一个包含编码器和解码器的完整架构,但在后续训练产生的生成式大模型中,并非都是采用这样完整的编码器解码器模型,还有仅解码器模型、仅编码器模型、编码器-解码器模型。
仅解码器模型,就像内容创作者,擅长写出引人入胜且信息丰富的内容,但不擅长理解主题和学习目标。仅解码器模型的例子有GPT系列模型,如GPT-3。
仅编码器模型,就像审核者,擅长理解语言之间的关系和上下文,但不擅长生成内容。仅编码器模型的例子有BERT。
如果既能创作又能审核测验,这就是编码器-解码器模型。如BART和T5。
特意提出上述不同模型种类,是希望大家不要拘泥于对Transformer 架构的静态理解(不要死记硬背地学),实际应用中,模型设计需根据任务动态调整,Transformer 的编码器-解码器结构是通用框架,但并非所有任务都需要完整使用。例如GPT 系列继承了 Transformer 的自注意力机制,但通过架构简化(仅解码器)和训练策略优化(如 RLHF),实现了生成能力的突破。
最后
选择AI大模型就是选择未来!最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,人才需求急为紧迫!
由于文章篇幅有限,在这里我就不一一向大家展示了,学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!
获取方式:有需要的小伙伴,可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
包括:AI大模型学习路线、LLM面试宝典、0基础教学视频、大模型PDF书籍/笔记、大模型实战案例合集、AI产品经理合集等等
大模型学习之路,道阻且长,但只要你坚持下去,一定会有收获。本学习路线图为你提供了学习大模型的全面指南,从入门到进阶,涵盖理论到应用。
L1阶段:启航篇|大语言模型的基础认知与核心原理
L2阶段:攻坚篇|高频场景:RAG认知与项目实践
L3阶段:跃迀篇|Agent智能体架构设计
L4阶段:精进篇|模型微调与私有化部署
L5阶段:专题篇|特训集:A2A与MCP综合应用 追踪行业热点(全新升级板块)





AI大模型全套学习资料【获取方式】