ICCV 2025 | 首个3D动作游戏专用VLA模型,打黑神话只狼超越人类玩家
内容源自公主号计算机科研圈
3D多模态大模型在动作角色扮演游戏的战斗任务中,成功率超越GPT-4o和人类玩家,淘天集团未来生活实验室团队提出了CombatVLA,已被ICCV 2025接收。
在复杂的三维环境中实现实时决策仍面临重大挑战,要求模型能在秒级时间尺度做出响应,具备高分辨率感知能力,并能够在动态条件下进行战术推理。
如下图所示,团队给出了CombatVLA推理得到的AoT解释、解析成Python代码的动作指令,以及执行这些动作后的帧序列。前三行案例来自“黑神话:悟空”,第四行为“只狼:影逝二度”。

△测试案例可视化
第一行中,CombatVLA检测到自身血量较低,于是先将角色后撤到安全位置,然后按“r”键进行回血操作。
第二行中,CombatVLA判断定身技能可用,便按下“1”键定身敌人,并立即发动连招,大幅削减敌人血量。
第三行展示了模型有效闪避敌人攻击,并抓住时机用蓄力重击进行反击。
第四行中,在SSDT场景下,CombatVLA先用格挡动作抵御攻击,随后用轻攻击发动忍杀,一击击败敌人。
具体而言,CombatVLA是一个3B级别的模型,通过动作追踪器收集的视频-动作对进行训练,数据被格式化为“动作思维”(action-of-thought, AoT)序列。随后,CombatVLA无缝集成进动作执行框架,并通过截断AoT策略实现高效推理。
实验结果表明,CombatVLA不仅在战斗理解基准测试中超越了所有现有模型(如GPT-4o等),还在游戏战斗中实现了50倍的加速。此外,CombatVLA的任务成功率也高于人类玩家。

一. CombatVLA概览
视觉-语言-动作模型(VLA)结合视觉、语义和动作控制,推动具身智能发展。尽管这类模型在UI操作和导航任务表现优异,但3D战斗场景(如“黑神话:悟空”和“只狼:影逝二度”)仍面临三大挑战:
1)视觉感知(如敌我定位、运动、环境感知);
2)战斗推理(识别敌方攻击模式等);
3)高效推理(实时响应),目前尚无框架在这些任务上表现突出,也缺乏有效的战斗理解评测基准。
且当前方案存在明显缺陷——基于强化学习方法操控游戏的方法们仅凭视觉输入,通过DQN和PPO等算法训练智能体自主学习战斗,但需要大量预设奖励和反复试错,泛化能力弱。
依赖超大模型(如GPT-4o)的方法们推理延迟较高,有时高达60-90秒,严重影响实时战斗表现,难以落地应用。
为解决这些问题,团队提出了CombatVLA——首个高效3D战斗智能专用VLA模型。
CombatVLA基于3B参数规模,能处理视觉输入并输出一系列具体可执行的动作指令(支持键鼠操作),实现高效战斗决策。团队首先开发了动作跟踪器自动采集大规模训练数据,
数据被加工为“动作思维”(Action-of-Thought, AoT)格式,方便模型理解和推理战斗动作。
接下来,CombatVLA采用渐进式学习范式,逐步从视频级到帧级优化动作生成。
最终,模型可嵌入动作执行机器人中,并通过自定义截断输出策略加速推理。
实验表明,CombatVLA在战斗理解准确率上超过现有大模型,在执行速度上也实现了50倍提升。
本文主要贡献如下:
- 动作跟踪器:
开发了一套后台自动记录玩家动作的工具,大幅提升数据采集效率,为后续研究提供基础。
- 战斗理解基准:
基于动作跟踪器建立了CUBench评测集,通过VQA任务测试模型的敌方识别和动作推理能力。
- AoT数据集:
提出分三阶段(视频粗粒度/帧级细粒度/帧级截断)构建AoT数据,助力模型渐进学习战斗技能。
- CombatVLA模型:
结合自适应动作权重损失,经过渐进式训练,在战斗理解基准上达到最优。
- 动作执行框架:将CombatVLA无缝嵌入PC端执行,实现基于截断策略的50倍加速。
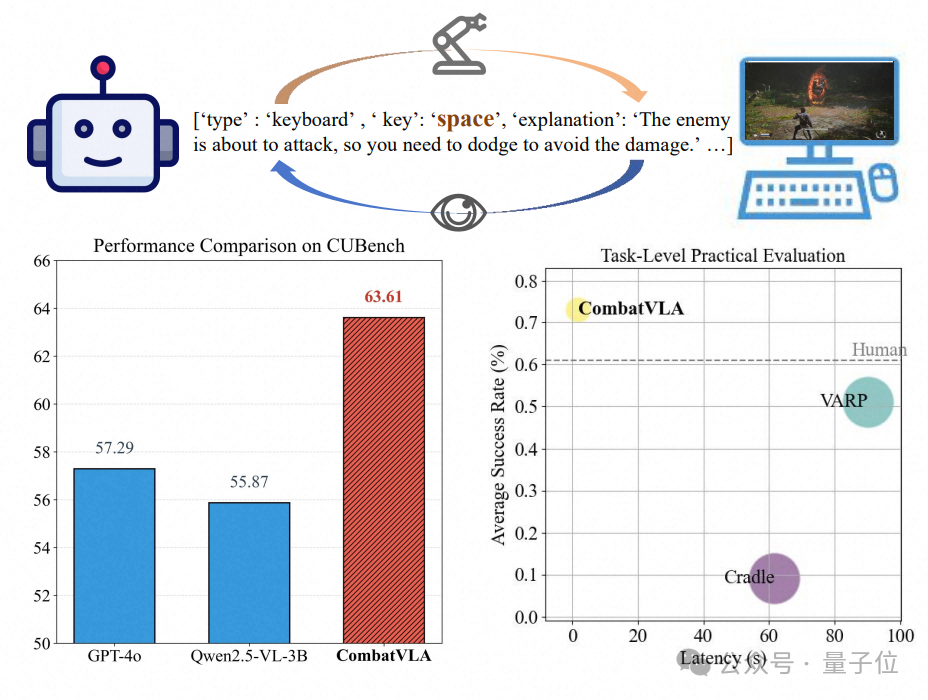
△CombatVLA在CUBench和任务级实际评测中均达到最优性能
二. 动作追踪器和评测基准
团队开发了一个动作跟踪器,用于收集游戏中的人类动作序列,为战斗理解模型提供了大量训练数据。此外,团队还基于该动作跟踪器建立了一个全面的战斗理解benchmark,涵盖三个不同任务。

△战斗理解评测基准 - CUBench
2.1 动作跟踪器
由于标注动作的数据极其稀缺,团队开发了一个高效收集视频-动作对的轻量级Python工具,称为动作跟踪器。
该工具可以在后台运行,监控键盘和鼠标操作以记录用户动作,并同步截取游戏截图。
2.2 评测基准
为了让基于VLM或VLA的模型在3D ARPG游戏中有良好表现,必须具备高维视觉感知和战斗语义理解能力。
因此,团队基于三项核心能力(信息获取、理解、推理)构建了战斗理解评测基准——CUBench,用于评估模型的战斗智商。
分别为:单图判断、多图判断和多图多选,团队汇总出914条数据(39.4%为信息获取,22.3%为理解,38.3%为推理),用于全面测试模型的战斗理解能力。
三.CombatVLA模型
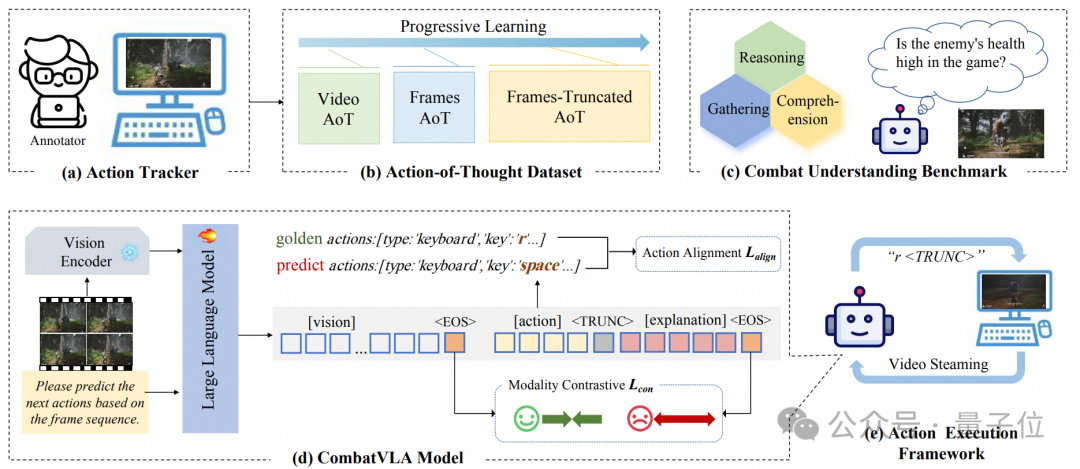
△动作跟踪器、AoT数据集、CUBench、CombatVLA模型和动作执行框架
3.1 Action-of-Thought数据集
受CoT启发,团队将动作跟踪器采集的数据转化为“动作思维”数据,如下图所示。具体而言,模型的输出以JSON格式表达,包含[action](如“按下空格键”)以及[explanation](用于描述当前敌人状态、该动作的物理含义等)。
此外,还引入特殊标记⟨TRUNC⟩,用于实现输出截断,以提高推理速度。
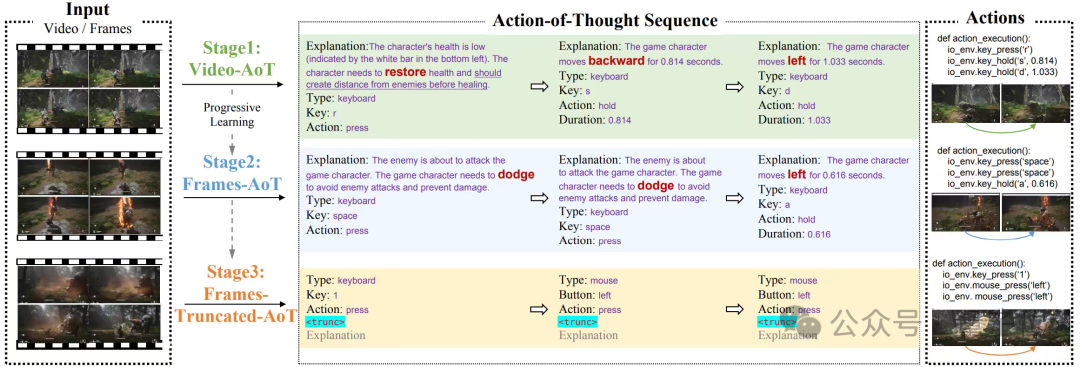
△数据集和训练范式
3.2 三阶段渐进式训练
CombatVLA的训练过程遵循三级渐进式学习范式,使模型能够逐步掌握战斗策略。具体分为:
(1)阶段1:视频级粗粒度AoT微调。
该阶段旨在让模型初步理解战斗环境,数据以若干帧组成的视频为单元,结合每帧对应的动作(时间并不精确对齐)。
这样,模型需要根据整体视频内容推测动作,有助于建立对战斗整体的初步认知,也便于后续稳定训练。
(2)阶段2:帧级细粒度AoT微调。
在3D战斗游戏中,模型需要具备秒级反应和快速决策能力。
此阶段构建了动作与若干前序帧严格对齐的数据对(Frames-AoT),帮助模型理解动作前因后果及战斗逻辑。
例如,连续几帧内敌方蓄力攻击,则模型可能触发闪避行为。
(3)阶段3:帧级截断AoT微调。
大模型推理速度与输出长度相关,为提升实时响应,团队引入了⟨TRUNC⟩特殊标记,对AoT输出内容进行截断加速。
这样既保留了AoT带来的推理优势,又显著提升了模型推理速度。
整个训练过程中,视觉编码器参数冻结,仅微调语言模型参数。
在前两阶段中,AoT的[explanation]置于[action]前面,便于模型推理出正确的动作;在第三阶段,AoT的[explanation]置于[action]后面,便于模型进行快速截断,以实现推理加速。
3.3 动作执行框架
(1)基于VLA的智能体框架。
为让视觉语言模型(VLM)能够像人类一样玩电脑游戏,团队开发了一个轻量级且高效的动作执行智能体。
在实际运行中,框架接收实时游戏画面(视频)作为输入,输出则是具体的键鼠动作指令,实现对游戏角色的自动控制。
团队对实时游戏画面进行帧采样,去除冗余视觉信息,降低VLM推理负担。模型推理采用截断输出策略,提取有效动作并执行。
(2)截断推理与执行。
推理过程中,每生成一个新输出token就进行监控,一旦检测到特殊的⟨TRUNC⟩标记即停止,将之前的内容解析为动作。这大大加快了推理速度。
最后,利用“pyautogui”库将动作转换为Python代码,自动完成键盘鼠标操作,让角色完成战斗任务。
四.实验结果
4.1 实现细节
(1)数据集。
团队选用了“黑神话:悟空(BMW)”和“只狼:影逝二度(SSDT)”两款游戏作为实验平台。
标注人员根据难度将13个战斗任务分为四个等级:简单、中等、困难和极难(如下表所示)。
团队通过动作跟踪器在“黑神话:悟空”的第9和第10任务中收集训练数据。AoT涵盖10种动作,包括“wsad”移动、“shift”冲刺、“space”翻滚(只狼中为格挡防御)、“r”回血、“1”定身、鼠标左键普攻、鼠标右键长按重击等,这些动作可以组合使用。
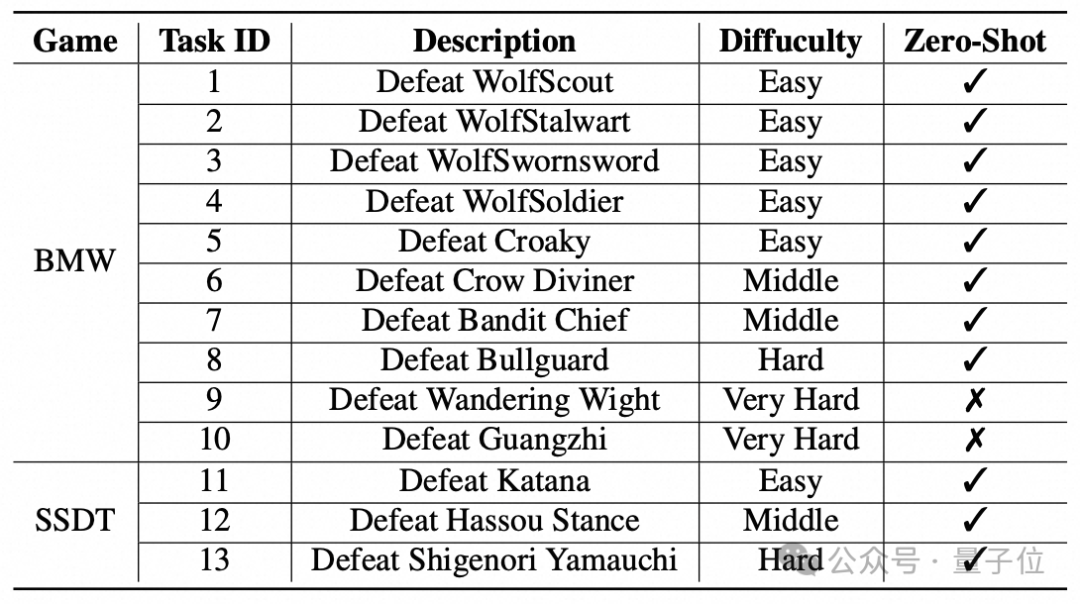
△任务定义
(2)基准测试。团队用战斗理解基准(CUBench)、通用基准(如MME、VideoMME、OCRBench)和任务级实际评测作为评测方式。
在任务级实战测试中,动作执行框架直接操控PC进行战斗,每个基线模型对每个任务测试10次,以击败敌人为成功,否则为失败,记录成功率和平均推理时长。
值得注意的是,团队的CombatVLA只在极难任务(9和10)上微调,测试时将简单到困难难度的任务(1–8, 同一游戏的不同任务)及其他游戏的任务(11–13)作为零样本(zero-shot)测试,以考察泛化能力。
4.2 定量实验结果
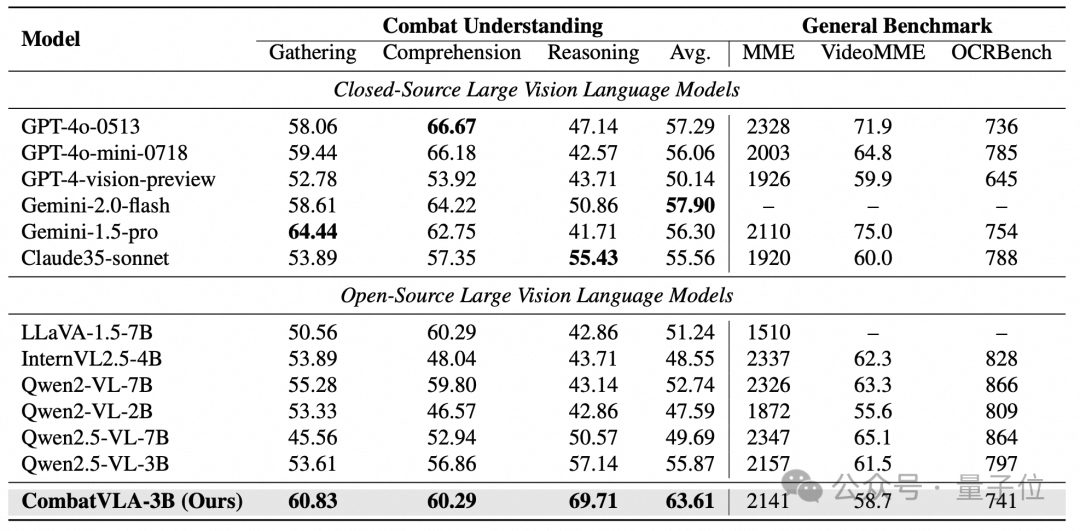
△战斗理解和通用基准评测结果
(1)战斗理解评测。在CUBench上,CombatVLA取得了63.61的最高平均分,比第二名Gemini-2.0-flash高出5.71分,较原始基座Qwen2.5-VL-3B高出7.74分,显著提升了模型的战斗理解能力。
(2)通用基准评测。CombatVLA在MME、VideoMME和OCRBench等通用基准上的表现依然与基座模型Qwen2.5-VL-3B相当,验证了团队方法的稳健性和泛化能力。
(3)任务级实际评测。团队将CombatVLA接入动作执行代理,让其像人类一样自动完成战斗任务。如下图所示,CombatVLA不仅在简单任务接近人类外,在中高难度任务上全面超越基线,并在零样本任务上也展现出较强的泛化能力。
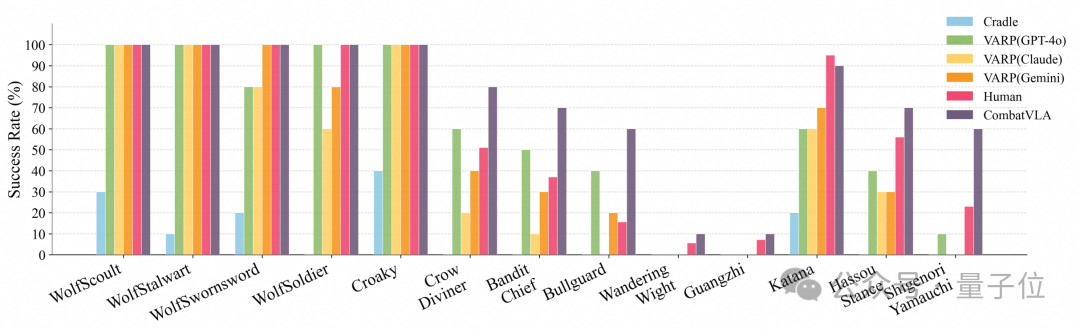
△任务级实际评测结果
(4)推理延迟。团队还统计了平均推理延迟和每次动作所需模型调用次数(见下表)。CombatVLA平均推理延迟仅1.8秒,且只需一次模型调用,比VARP快约50倍,模型调用成本仅为其1/10。

△推理延迟和调用次数比较
结束语
本文针对当前视觉语言模型(VLMs)或视觉-语言-动作模型(VLAs)在3D动作角色扮演游戏中缺乏秒级响应、高分辨率感知和战术推理能力的问题,提出了CombatVLA模型。
该模型规模为3B,采用AoT序列训练,并引入动作对齐损失和模态对比损失进行优化。
CombatVLA可无缝集成到动作执行框架中,通过截断AoT策略实现高效推理。
实验结果表明,CombatVLA在战斗理解基准上全面超越现有模型,同时具备良好的泛化能力,并在实时战斗场景中实现了50倍速度提升。
未来,团队将进一步增强模型对游戏场景的理解能力,拓展其在更多类型游戏甚至物理世界中的应用。
论文链接:https://arxiv.org/pdf/2503.09527
项目主页:https://combatvla.github.io/
开源信息:https://combatvla.github.io/