【论文学习】UoMo: 一个用于无线网络优化的移动流量预测通用模型
UoMo: 一个用于无线网络优化的移动流量预测通用模型
柴浩毅 电子工程系,清华伯克利网络研究院,清华大学 北京,中国haoyechai@mail.tsinghua.edu.cn
张诗源 电子工程系,清华伯克利网络研究院,清华大学 北京,中国zhhangshi22@mails.tsinghua.edu.cn
戚晓倩 电子工程系,清华伯克利网络研究院,清华大学 北京,中国qi xiaoqian24@mails.tsinghua.edu.cn
邱宝华 中国移动 北京,中国q iubaohua@chinamobile.com
李勇 电子工程系,清华伯克利网络研究院,清华大学 北京,中国liyong07@tsinghua.edu.cn
论文链接:https://dl.acm.org/doi/10.1145/3711896.3737272
数据及代码链接:https://github.com/tsinghua-fib-lab/UoMo
摘要
移动流量预测使运营商能够提前预知网络动态和性能,为提升服务质量和提高用户体验提供了巨大潜力。它涉及多个任务,包括长期预测、短期预测以及不依赖历史数据的生成任务。通过利用这些任务生成的不同类型的移动网络数据,运营商可以执行各种网络优化和规划活动,例如基站(BS)部署、资源分配、能耗优化、等。然而,现有模型通常针对特定任务设计并使用专门数据进行训练,缺乏适用于不同城市环境的通用流量预测模型。在本文中,我们提出了一种通用移动流量预测模型(UoMo),旨在处理跨多个城市的短期/长期预测和分布生成等多样化预测任务,以支持网络规划和优化。UoMo结合了扩散模型和Transformer,提出了多种时空掩码,使UoMo能够学习不同任务的内在特征,并开发了一种对比学习策略来捕获移动流量与城市环境之间的相关性,从而提高其迁移学习能力。在9个真实世界数据集上的大量评估表明,UoMo在各种预测任务和零/少样本学习中优于现有模型。它在长期预测、短期预测和生成任务中分别平均提高了 27.85%27.85\%27.85% 、 18.57%18.57\%18.57% 和 15.6%15.6\%15.6% 的准确率,展示了其强大的预测能力。我们将UoMo部署在中国移动的九天平台上,利用预测的移动数据优化实时网络。这种优化包括基站部署,从而提高了 25.3%25.3\%25.3%
服务用户数量增加,以及BS睡眠控制,这减少了设备折旧 40.7%40.7\%40.7% 源代码可在网上获取:https://github.com/tsinghua- fib- lab/UoMo。
CCS Concepts
计算方法 ⟶\longrightarrow⟶ 知识表示与推理;.网络 ⟶\longrightarrow⟶ 网络模拟;.信息系统 ⟶\longrightarrow⟶ 时空系统
关键词
移动流量预测;基础模型;扩散模型
ACM参考格式:
柴浩叶,张诗远,齐晓倩,邱宝华,和李勇.2025. UoMo:一种用于无线网络优化的通用移动流量预测模型.在第31届ACMSIGKDD知识发现与数据挖掘会议论文集V.2(KDD25),2025年8月3- 7日,多伦多,安大略省,加拿大.ACM,纽约,纽约,美国,12页.https://doi.org/10.1145/3711896.3737272
1引言
近年来,基础模型[6,48,42]在自然语言处理和计算机视觉领域取得了重大进展。这些模型通过其强大的数据处理、泛化和零/少样本学习能力,正在重塑人工智能生态系统。越来越多的专业领域开发了针对其特定数据和上下文需求的基础模型,包括医疗保健、医学、城市导航等[68,65,24,4]。移动网络包含大量的移动流量、用户和地理数据,为构建通用模型提供了内在的数据支持。然而,针对移动网络领域的此类专用模型尚未建立。因此,我们旨在构建一个用于移动流量预测的通用模型,该模型能够处理大规模移动数据的丰富特征,同时保留跨多个网络应用所需的泛化能力[54,8,67]。
构建这样一个通用的移动流量预测模型对于移动网络[14,53,76]至关重要。一方面,移动流量预测为网络规划和优化提供了巨大的潜力。它使运营商能够预测流量动态,促进对资源利用和服务质量的主观感知,并允许提前制定优化策略。另一方面,移动网络包含各种优化场景,包括无线资源调度[36,32],基站(BS)部署[12,13],和天线配置[34,29]等。这些场景涉及吞吐量、覆盖范围和能效等不同的目标,这些对流量预测提出了不同的任务。例如,无线资源调度需要执行短期流量预测任务,优先考虑流量动态以改善用户体验[9,16],而BS部署则涉及长期流量预测任务,关注区域内长期的流量模式以适应网络需求[75,52]。对于实时无线网络的规划和部署,必须利用通用模型的强大数据挖掘能力和强大的泛化能力,以同时解决各种优化任务。
尽管在移动流量预测领域已经涌现出许多值得注意的研究成果[17,25,39,26,58,71,45],当前的方法通常采用一对一的方法:通过利用特定任务的数据[63,20,76,28]设计定制模型。在实时网络中部署的复杂、定制的模型通常需要手动编排和调度,这将导致计算和存储资源的浪费,增加模型部署的开销。此外,移动流量本质上具有各种收集粒度和范围的异质性。例如,测量报告(MR)数据主要收集毫秒级的用户流量,而性能管理(PM)数据收集15分钟间隔的蜂窝级流量统计[37,51],导致缺乏类似于自然语言的统一表示。因此,直接将自然语言/视觉领域的预训练模型应用于移动流量数据具有挑战性。尽管已经做出了一些努力将移动流量数据重新编程为自然语言格式[18,23],但这种方法严重依赖于手动制作的提示的质量,难以捕捉移动流量的通用表示。具体来说,当前的移动流量预测模型面临两个关键限制:
i)有限的泛化能力。移动流量数据本质上受到人口分布和通信需求时空动态的影响。由于不同城市在地理环境、生活习惯和城市布局上的差异,移动流量可能存在显著差异[66,57]。对于相对较小的参数,当前模型难以捕捉跨多个城市的大规模数据中固有的多样化时空模式。此外,将上下文因素与移动流量之间的复杂关联进行封装具有挑战性,导致在多城市场景中迁移性较差。
ii)约束任务适应性。移动交通预测在各种优化场景中得到了广泛应用。然而,当前的模型通常设计有针对特定任务的专用模块。例如,在短期预测中,模型通常专注于捕捉采用自回归或事件驱动方法的交通波动。相比之下,长期预测强调交通的规律性,并且通常
利用时间序列分解技术。这些专用模型在应用于多样化场景时增加了设计复杂性和部署成本。
为了解决这些局限性,我们提出了一种通用的移动流量预测模型(UoMo),旨在学习移动流量数据的通用特征,并处理移动网络中的多任务,从而建立一种通用的预测模型。首先,受Sora[5]启发,UoMo采用基于Transformer的扩散模型作为骨干,而不是U- Net结构,以帮助模型理解海量移动数据的多样化特征。我们提出了一种对比扩散算法,并通过分析移动流量与上下文特征之间的交叉来调整变分下界。这有助于模型更好地整合环境信息,提高泛化能力并解决第一个局限性。其次,我们采用面向任务的掩码和自监督训练范式,将移动网络中的流量预测分为三个任务:短期预测、长期预测和生成。我们设计了相应的掩码策略,使模型能够学习各种任务的数据特征并适应多任务,从而解决第二个研究挑战。
·据我们所知,这是第一个专为移动流量预测设计的通用模型。该模型通过统一的框架,支持不同城市环境中移动网络的各种预测任务,帮助网络运营商实现高效的网络规划和优化。
·我们使用具有针对不同预测任务(包括短期/长期预测和分布生成)的时空掩码策略的掩码扩散方法来开发我们的通用模型。为了加强上下文特征与移动流量的相关性,我们进一步提出了一种上下文感知对比学习微调策略,这可以增强预测和迁移学习能力。
·我们在9个真实世界的移动流量数据集上进行了广泛的评估。结果表明,UoMo具有卓越的泛化能力、多任务能力和在未知场景中的鲁棒性少数/零样本性能。我们还将UoMo模型部署在中国移动的九天平台上。在实时系统数据上的实验证明,我们的模型赋能了多种网络优化场景,包括BS部署用户量增加 25.3%25.3\%25.3% 和BS睡眠控制设备折旧减少 40.7%40.7\%40.7%
2问题公式化
移动流量是指在一定时间内,移动设备与BS之间通过无线信道传输的数据量
我们考虑一个离散时间场景 T={0,…T}T = \{0,\dots T\}T={0,…T} ,具有相等的时间间隔。对于单个基站,随时间变化的流量 TTT 可以表示为 {bt}t=0:T\{b_t\}_{t = 0:T}{bt}t=0:T ,其中 btb_tbt 表示基站在时间 ttt 的覆盖区域内的总流量。为了表征城市区域G(具有上下文特征 CCC G</style})的移动流量特征,我们将该区域的地理长度和宽度分别定义为 HHH 和 VVV 。然后,区域G的移动流量可以定义为位于 G:S0:T=∑b{bt}t=0:TG:S_{0:T} = \sum_{b}\{b_t\}_{t = 0:T}G:S0:T=∑b{bt}t=0:T 的所有基站的总流量之和。关于通信网络中的多样化任务,例如基站部署、用户访问控制和无线资源分配,通常需要不同的流量预测任务。我们将预测分为3个典型任务:
·短期预测任务使用长期历史数据 0∼t0\sim t0∼t 来预测未来短期内的移动流量动态,i.e., {S0:t,CG}→St:T\{S_{0:t},C_{G}\} \rightarrow S_{t:T}{S0:t,CG}→St:T ,其中 t≫(T−t)0t\gg (T - t)_0t≫(T−t)0 基于具有波动的预测,运营商可以了解即将到来的网络需求,并进行资源分配[35]和访问控制[31]等优化,以改善实时网络中的用户体验。
·长期预测任务基于有限的历史数据估计未来流量模式,i.e., {S0:t,CG}→St:T\{S_{0:t},C_{G}\} \rightarrow S_{t:T}{S0:t,CG}→St:T ,其中 t≪T∘t\ll T_{\circ}t≪T∘ 它探索了流量中的固有周期性模式。这种预测使运营商能够从全局角度估计和分析网络性能,从而促进网络优化规划策略的制定,例如小区休眠[56]和网络容量扩展[78]。
·生成任务专注于识别特定区域内潜在的网路需求,而不参考历史数据,i.e., {CG}→St=0:T\{C_{G}\} \rightarrow S_{t = 0:T}{CG}→St=0:T 。它帮助运营商评估缺乏历史数据的新地区的潜在通信需求,使他们能够制定规划策略,例如BS部署[34]网络分割[60],和容量规划[33],等。
我们的目标是构建一个能够实现上述3个预测任务的领域通用模型。问题可以定义如下。
问题定义。给定任意城市区域 G\mathcal{G}G ,目标是使用模型 F\mathcal{F}F 预测具有短期/长期/生成任务的多样化移动流量序列 SSS ,条件为城市上下文因素 CGC_GCG i.e. F(St=T0:T1/St=0:T1,CG)\mathcal{F}(S_{t = T_0:T_1} / S_{t = 0:T_1},C_{\mathcal{G}})F(St=T0:T1/St=0:T1,CG) ,。
然而,构建这样一个通用模型并不容易。具体来说,出现了两个关键挑战:i).如何制定训练过程中的策略,确保模型能够处理多样化的预测任务?ii).如何有效地将用户动态和上下文特征与移动流量集成?
3UoMo设计
3.1框架概述
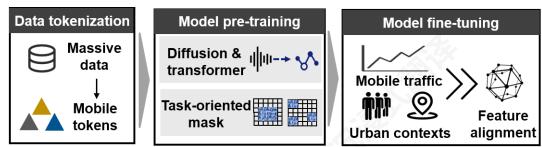
图1:UoMo框架的流程图
为应对这些挑战,我们提出了一个包含三个阶段的UoMo框架,如图1所示
1).数据分词将多个城市中不同时空跨度上的移动流量数据重塑为统一的移动分词模型训练并捕捉其多样化特征。
ii).掩码扩散预训练.倾向于全面掌握移动流量在不同预测任务中的基本时空特征,其中我们设计了一个基于扩散的骨干网络和面向任务的掩码。
iii).城市上下文感知微调引入了一种对比学习算法,该算法紧密结合与移动流量密切相关的外部因素,包括网络用户动态和城市POI分布。
3.2基于掩码扩散的预训练
我们提出了一种带自监督训练的掩码扩散模型,其中为三个预测任务定制了特定的掩码,以增强模型对各种预测任务的理解,并捕获海量移动数据中固有的时空相关性,如图2所示
3.2.1移动流量数据分词。我们从自然语言处理(NLP)分词中获得灵感,将具有不同采样间隔和多样化空间范围的流量数据分解为基本单元 h0×v0×t0h_0\times v_0\times t_0h0×v0×t0 。对于城市区域 H×VH\times VH×V 内长度为 TTT 的流量数据 SSS ,分词过程将 SSS 分解为多个小的移动分词 XXX ,可以表示为 S∈RH×V×T→X∈R(H′×V′×T′)×(h0×v0×t0)S\in \mathbb{R}^{H\times V\times T}\to X\in \mathbb{R}^{(H^{\prime}\times V^{\prime}\times T^{\prime})}\times (h_{0}\times v_{0}\times t_{0})S∈RH×V×T→X∈R(H′×V′×T′)×(h0×v0×t0) 其中 Ht=H/h0,Vt=V/v0H_{t} = H / h_{0},V_{t} = V / v_{0}Ht=H/h0,Vt=V/v0 ,以及 T′=T/t0T^{\prime} = T / t_{0}T′=T/t0 (h0,t0,v0)(h_0,t_0,v_0)(h0,t0,v0) 表示X的移动分词。随后,我们使用嵌入层 EX(X)E_{X}(X)EX(X) (e- g,池化层、卷积层或全连接层)将移动分词映射到隐藏特征 CCC i.e. EX(X)∈R(H′×V′×T′)×C∘E_{X}(X)\in \mathbb{R}^{(H^{\prime}\times V^{\prime}\times T^{\prime})\times C_{\circ}}EX(X)∈R(H′×V′×T′)×C∘
3.2.2任务导向掩码。在移动流量数据分词后,原始 H×VH\times VH×V 区域被划分为多个 h0h_0h0 区域。掩码策略通过掩码和重建部分区域进行自监督训练。我们将掩码的部分定义为目标区域,目标区域周围的未掩码部分定义为周边区域。我们开发了4种不同的掩码:短期、长期、生成和随机掩码, m∈RH′×V′×T′m\in \mathbb{R}^{H^{\prime}\times V^{\prime}\times T^{\prime}}m∈RH′×V′×T′ 。前三种专注于特定的预测任务,而随机掩码探索时空相关性以增强泛化能力。
·短期/长期掩码。该方案在特定空间位置 (h,v)(h,v)(h,v) 掩码时间维度 T′</style}T^{\prime}< /\mathrm{style}\}T′</style} ,以重建该时期的移动流量,其中。根据与’的比例,该方案对应短期/长期预测:
mh,v,t={0,t0<t≤T′∣1,0<t≤t0}.(1) m_{h,v,t} = \{0,t_0< t\leq T'|1,0< t\leq t_0\} . \tag{1} mh,v,t={0,t0<t≤T′∣1,0<t≤t0}.(1)
·生成掩码。生成掩码在特定空间位置 (h,v)(h,v)(h,v) 完全遮蔽时间维度,使模型能够在目标区域内生成移动流量序列。与依赖历史数据的预测掩码不同,它捕获了目标区域及其周边区域之间的时空依赖关系,以生成底层分布:
mh,v,t={0,0≤t≤T′}.(2) m_{h,v,t} = \{0,0\leq t\leq T'\} . \tag{2} mh,v,t={0,0≤t≤T′}.(2)
·随机掩码。它掩蔽了空间和时间维度上的移动流量,旨在捕获移动标记的多样化相关性,帮助模型理解移动数据的复杂特征。记 R(H′,V′,T′)\mathcal{R}(H^{\prime},V^{\prime},T^{\prime})R(H′,V′,T′) 为从 HHH 、 VVV 和 TTT 中随机选择项:
mh,v,t={0,R(H′,V′,T′)∣1,else}.(3) m_{h,v,t} = \{0,\mathcal{R}(H^{\prime},V^{\prime},T^{\prime})\mid 1,else\} . \tag{3} mh,v,t={0,R(H′,V′,T′)∣1,else}.(3)
3.2.3自监督掩码扩散模型。在完成多任务掩码过程后,原始移动标记 EX(X)E_{X}(X)EX(X) 被分为两部分:需要被重建的掩码部分e,以及未掩码观测o:
e=EX(X)⊙m,o=EX(X)⊙(1−m),(4) e = E_{X}(X)\odot m,\quad o = E_{X}(X)\odot (1 - m), \tag{4} e=EX(X)⊙m,o=EX(X)⊙(1−m),(4)
其中,m对应于四种掩码策略,而 ⊙\odot⊙ 表示逐元素乘积。随后,0作为条件输入到
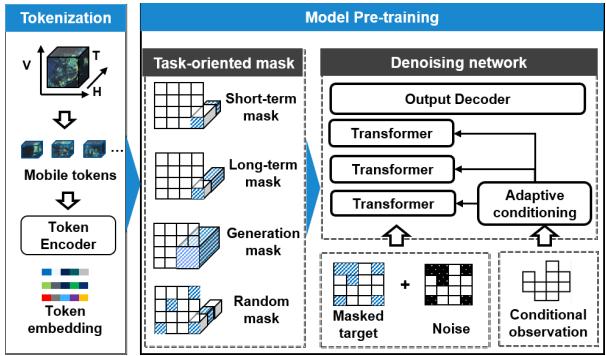
图2:基于掩码扩散的预训练网络
去噪网络中,而e根据正向过程添加噪声,其表达式为
ek=α^ke+(1−α^k)ϵ,ϵ∼N(0,1).(5) e_k = \sqrt{\hat{\alpha}_k} e + (1 - \hat{\alpha}_k)\epsilon , \epsilon \sim N(0,1). \tag{5} ek=α^ke+(1−α^k)ϵ,ϵ∼N(0,1).(5)
随后, eke_kek 被输入到基于变压器的去噪网络中进行进一步的特征提取。为了完全捕捉条件观测和移动流量之间的依赖关系,我们采用了一种自适应条件方法[40]。该方法通过参考给定条件来重塑变压器的layernorm的尺度和偏移参数,这已被证明能提供更好的有效性和计算效率[41]。它可以表示如下:
α,β,γ=Fθ(o),ek←ek+αAθ(βek+γ),(6) \alpha ,\beta ,\gamma = \mathcal{F}_{\theta}(o),\quad e_k\gets e_k + \alpha \mathcal{A}_{\theta}(\beta e_k + \gamma), \tag{6} α,β,γ=Fθ(o),ek←ek+αAθ(βek+γ),(6)
其中Fo和A分别表示线性层和注意力层。 α,β,γ\alpha ,\beta ,\gammaα,β,γ 分别表示残差、尺度和偏移参数。去噪网络的目的是拟合扩散过程的后验分布以预测噪声均值,最终通过输出解码器重建最终的网络流量。因此,我们的目标强调掩码部分的重构精度,这可以表示为公式(5)所示:
Lθ=minθEe∼q(⋅){∥ϵ−ϵθ(ek,k∣o)∥2⊙m}.(7) L_{\theta} = \min_{\theta}\mathbb{E}_{e\sim q(\cdot)}\left\{\| \epsilon -\epsilon_{\theta}(e_k,k|o)\| ^2\odot m\right\} . \tag{7} Lθ=θminEe∼q(⋅){∥ϵ−ϵθ(ek,k∣o)∥2⊙m}.(7)
3.3城市上下文感知微调
移动流量不仅是一个时空序列,还受到城市上下文的影响。因此,我们提出了一种城市上下文感知微调方案,将人类动态和兴趣点(POI)集成到UoMo中,如图3所示。
3.3.1上下文数据转换。移动用户指的是访问网络的用户数量,它可以充分表征移动网络中的人类动态。类似于移动流量,它本质上是一个时空序列,记为 U∈RH×V×TU\in \mathbb{R}^{H\times V\times T}U∈RH×V×T 。我们应用与流量标记相同的处理方法,对移动用户进行标记化,如 cu∈R(H′×V′×T′)×(h0×a0×t0)c^{u}\in \mathbb{R}^{(H^{\prime}\times V^{\prime}\times T^{\prime})\times (h_{0}\times \mathfrak{a}_{0}\times t_{0})}cu∈R(H′×V′×T′)×(h0×a0×t0) ,允许这些数据直接输入网络进行训练。
POI反映了城市布局的静态分布。对于每个基站覆盖的区域,我们统计该区域内每种POI类别的总数,以便我们可以获得一个POI向量 P∈RH×VP\in \mathbb{R}^{H\times V}P∈RH×V 。尽管POI的分布是静态的,但不同类别的POI对人类行为的影响在不同时间会有所不同,从而导致移动
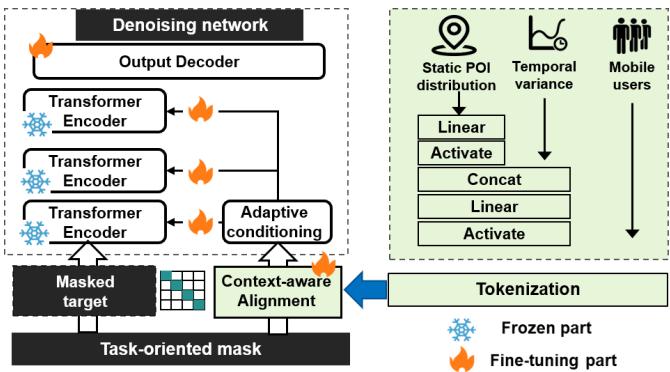
图3:上下文感知微调过程
交通出现相应的变化。例如,餐厅类型的POI通常在午餐时间和晚上表现出更高的交通量。在这方面,我们设计了一种动态POI转换方案。我们首先提取POI分布的内在静态特征,可以表示为:
hps=σ(Ws⋅P+Bs),(8) h_p^s = \sigma (W^s\cdot P + B^s), \tag{8} hps=σ(Ws⋅P+Bs),(8)
其中 σ\sigmaσ 是Sigmoid激活函数, WsW^sWs 和 BsB^sBs 是MLP网络的权重和偏置参数。我们进一步利用一个MLP网络 τ(t)\tau (t)τ(t) 将时间戳作为时间嵌入进行投影,我们使用nn.Embedding层对2D向量 t=t =t= [day, hour]进行编码,并使用MLP网络融合这两个嵌入,然后将静态POI特征与时间指标融合:
hpd=σ(Wl⋅[hps⊕τ(t)]+Bl),(9) h_{p}^{d} = \sigma (W^{l}\cdot [h_{p}^{s}\oplus \tau (t)] + B^{l}), \tag{9} hpd=σ(Wl⋅[hps⊕τ(t)]+Bl),(9)
其中 ⊕\oplus⊕ 表示向量拼接, WlW^{l}Wl 和 BlB^{l}Bl 是可学习的参数。通过这种方式,我们可以获得时空动态表示 hpd∈RH×V×Th_p^d\in \mathbb{R}^{H\times V\times T}hpd∈RH×V×T 。POI的最终特征可以通过与移动流量数据相同的分词方法计算得到: cp∈R(H′×V′×T′)×(h0×a0×t0)c^{p}\in \mathbb{R}^{(H^{\prime}\times V^{\prime}\times T^{\prime})\times (h_{0}\times \mathfrak{a}_{0}\times t_{0})}cp∈R(H′×V′×T′)×(h0×a0×t0) 。最终的上下文特征标记可以表示为 y=cu+cPy = c^{u} + c^{P}y=cu+cP
3.3.2上下文感知对齐。为了在移动流量和上下文特征之间建立桥梁,我们提出了一种对比学习算法。我们将同一时空块内的移动流量标记和上下文特征标记定义为正样本,表示为 (e,y)(e,y)(e,y) ;而将不同时空块中的两种类型标记定义为负样本,表示为 (e,y)(e,y)(e,y) 。我们的目标是在流量特征 eee 和上下文特征 yyy 之间最大化互信息。根据先前研究[49],可以使用密度比来保留互信息作为 I(e,y)∝p(e∣c)p(e)I(e,y)\propto \frac{p(e|c)}{p(e)}I(e,y)∝p(e)p(e∣c) ,而最大化问题等价于最小化InfoNCE损失,其结果为:
min−Ee∈Blogp(e∣c)p(e)p(e∣c)p(e)+∑e′p(e′∣c)p(e′)≥log(N)−I(e,y),(10) min - \mathbb{E}_{e\in \mathbb{B}}log\frac{\frac{p(e|c)}{p(e)}}{\frac{p(e|c)}{p(e)} + \sum_{e^{\prime}}\frac{p(e^{\prime}|c)}{p(e^{\prime})}}\geq log(N) - I(e,y), \tag{10} min−Ee∈Blogp(e)p(e∣c)+∑e′p(e′)p(e′∣c)p(e)p(e∣c)≥log(N)−I(e,y),(10)
where B\mathbb{B}B 表示整个样本批次
我们在引理1中声称,使用正样本和负样本训练扩散模型等效于在对比学习的等式(10)中最小化InfoNCE损失:
引理1:通过使用公式(11)优化正负样本的均方误差(MSE),我们可以实现移动流量和上下文特征之间的对齐。
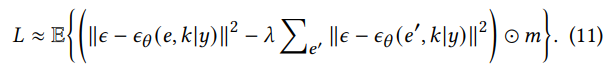
引理的证明在附录A.3中提供。在微调过程中,我们部分冻结了预训练模型的主参数,包括注意力层、线性层和MLP网络,以保留模型学习移动流量通用时空特征的能力。我们主要更新自适应调节和输出解码器层的参数。通过部分更新这些组件,可以减少微调过程的时间和计算成本。
4评估
我们在9个真实世界数据集上进行了评估,以使用13个基线评估UoMo。评估需要解决以下2个问题。
- RQ1:它在多任务预测中的表现如何?- RQ2:它在零样本和少样本学习中的表现如何?
4.1评估设置从实时移动系统
4.1.1数据集。移动流量数据。我们从中国7个不同规模的城市收集实时网络移动流量数据,包括4G和5G数据的下行流量。数据的时间粒度范围从15分钟到1小时。此外,我们利用中国和德国另外2个城市的移动流量数据来验证UoMo的零/少样本能力。
城市上下文数据。我们收集每个数据集中的移动用户数据和移动流量数据。我们通过公共地图服务从每个城市抓取POI数据,包括与生活、娱乐和其他方面相关的15个类别。
4.1.2基线。我们选择了13个基线,包含4种类型。i).统计模型。历史移动平均(HA)和ARIMA[59]。ii)基于自然语言处理(NLP)的模型。Time- LLM[23]和Tempo[7]使用自然语言描述时间序列特征,并使用这些描述进行预测。iii).基于时空的模型。CSDI[47],TimeGPT[15],Lagllama[43],PatchTST[38],和UniST[69]通过自回归、分解和空间卷积将移动流量预测为时空序列。iv).专为移动网络设计的模型。SpectraGAN[58],KEGAN[21],ADAP- TIVE[71],和Open- Diff[8]利用专门上下文数据生成移动流量。我们在附录A.1和A.2中描述了收集的数据和基线。
4.2多任务预测(RQ1)
在我们的实验中,时间长度为64。对于短期预测,模型使用之前的48个点预测16个未来点。对于长期预测,模型使用之前的16个点预测48个未来点。对于数据生成,模型根据当前时间戳预测所有64个点。我们主要使用35M UoMo模型(具有16个transformer层和256的隐藏特征大小),其他缩放评估在表6中提供。
为了直观地展示我们的模型在不同任务上的普适性,我们选择两个数据集作为示例(北京和南昌),并在图4中绘制了预测结果。从左到右,它表示短期预测 →\rightarrow→ 长期预测
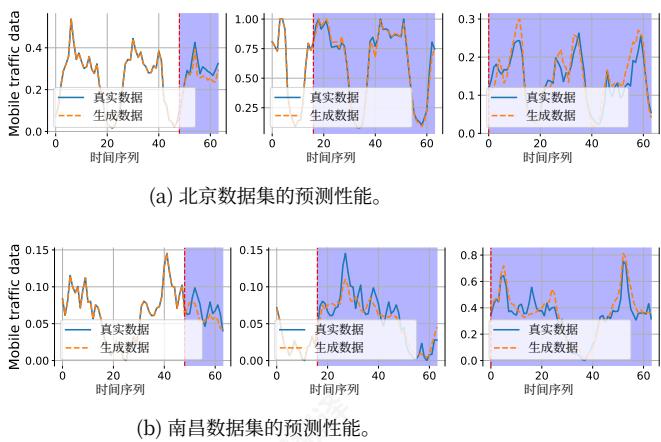
(a) 北京数据集的预测性能。
图4:可视化结果。从左到右,它表示短期/长期/生成任务。
→\rightarrow→ 流量生成。蓝色阴影区域表示模型的预测结果,而未阴影区域表示历史观测值。UoMo生成的移动交通与真实值紧密对齐,在所有任务中准确预测周期性趋势并捕捉快速动态,这表明我们的UoMo模型实现了跨多个城市和任务的预测,突出了其泛化能力。
-
短期预测。结果在表1中呈现。由于有足够的参考历史数据,大多数基线利用其时间特征提取模块有效地预测短期变化。总体而言,UoMo在7个数据集上平均RMSE性能提高了 17.80%17.80\%17.80% ,平均MAE提高了 27.85%27.85\%27.85% ,其中UoMo可以将RMSE指标提高高达 29.1%29.1\%29.1% (南昌-4G数据集)和MAE指标提高高达 50%50\%50% (南京-4G数据集),与其他模型相比表现出更强的泛化能力。通过自适应层归一化模块,扩散模型迭代地整合上下文特征,并利用transformer捕获移动交通和环境之间的长期依赖关系。我们相信这种相关性可以跨不同城市传递,提高模型的泛化能力。
-
长期预测。结果也显示在表2中。对于这项任务,由于缺乏足够的历史观测数据,一些基线的性能会下降。然而,UoMo始终能取得最佳性能,它在7个真实世界数据集上平均将RMSE性能提升了 18.93%18.93\%18.93% ,平均将MAE提升了 18.57%18.57\%18.57% ,MAE的最大提升为 31.36%31.36\%31.36% ,RMSE的最大提升为 27.41%27.41\%27.41% (北京数据集),这展示了它适应各种任务的能力。
-
移动流量生成。如表3所示,由于缺乏生成任务的历史观测数据,一些现有基线无法完成任务。然而,UoMo仍然实现了强大的生成结果。它在所有数据集上平均JSD性能提高了 6.95%6.95\%6.95% ,平均MAE提高了 15.6%15.6\%15.6% ,在JSD指标上(山东数据集)最高提高了 21.19%21.19\%21.19% ,在MAE指标上(南京-4G数据集)最高提高了 29.04%29.04\%29.04% 。这是由于在微调过程中使用的上下文特征融合模块,
表1:短期预测任务的性能。粗体数字表示最佳结果,underline数字表示次佳结果。所提出的UoMo在7个数据集上具有最佳预测性能。
表2:长期预测任务的性能
| 模型 | 北京 | 上海 | 南京 | 南京-4G | 南昌 | 南昌-4G | 山东 | |||||||
| RASE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | |
| HA | 0.1199 | 0.0697 | 0.1151 | 0.0576 | 0.0788 | 0.0353 | 0.0830 | 0.0371 | 0.0589 | 0.0266 | 0.0702 | 0.0319 | 0.1739 | 0.0578 |
| ARIMA | 0.2212 | 0.1333 | 0.1609 | 0.0819 | 0.1353 | 0.0622 | 0.1449 | 0.0668 | 0.1532 | 0.0666 | 0.1740 | 0.0799 | 0.1366 | 0.0531 |
| SpectraGAN | 0.2675 | 0.1228 | 0.2086 | 0.1226 | 0.2412 | 0.1186 | 0.2079 | 0.1151 | 0.2974 | 0.1467 | 0.1892 | 0.0955 | 0.2492 | 0.0814 |
| keGAN | 0.3307 | 0.2994 | 0.3456 | 0.2174 | 0.3586 | 0.3318 | 0.3579 | 0.3297 | 0.3123 | 0.1913 | 0.2521 | 0.2216 | 0.2662 | 0.2616 |
| Adaptive | 0.2779 | 0.2138 | 0.3007 | 0.2164 | 0.2606 | 0.1906 | 0.2219 | 0.1469 | 0.2305 | 0.1709 | 0.2572 | 0.1919 | 0.2688 | 0.1937 |
| Open-Diff | 0.1104 | 0.0899 | 0.1326 | 0.0981 | 0.1087 | 0.0823 | 0.1196 | 0.1005 | 0.1204 | 0.0801 | 0.1377 | 0.0962 | 0.1166 | 0.0799 |
| Time-LLM | 0.1511 | 0.1115 | 0.1388 | 0.0964 | 0.2351 | 0.1817 | 0.1754 | 0.1309 | 0.2039 | 0.1474 | 0.1770 | 0.1296 | 0.1571 | 0.0846 |
| Tempo | 0.1206 | 0.0873 | 0.0747 | 0.0455 | 0.0805 | 0.0625 | 0.0652 | 0.0498 | 0.0830 | 0.0638 | 0.0749 | 0.0590 | 0.0969 | 0.0763 |
| CSDI | 0.1752 | 0.1015 | 0.2060 | 0.1141 | 0.1722 | 0.0929 | 0.2299 | 0.1251 | 0.1797 | 0.0929 | 0.1587 | 0.0788 | 0.2131 | 0.0976 |
| patchTST | 0.1107 | 0.0686 | 0.1286 | 0.0872 | 0.0935 | 0.0616 | 0.0960 | 0.0631 | 0.1182 | 0.0635 | 0.1162 | 0.0628 | 0.1089 | 0.0703 |
| TimeGPT | 0.0538 | 0.0422 | 0.0868 | 0.0457 | 0.0646 | 0.0397 | 0.0657 | 0.0388 | 0.0502 | 0.0281 | 0.0576 | 0.0399 | 0.1219 | 0.0358 |
| Laglama | 0.0501 | 0.0349 | 0.0853 | 0.0441 | 0.0529 | 0.0302 | 0.0530 | 0.0286 | 0.0505 | 0.0271 | 0.0625 | 0.0307 | 0.1272 | 0.0371 |
| UniST | 0.0331 | 0.0252 | 0.0658 | 0.0448 | 0.0623 | 0.0442 | 0.0608 | 0.0409 | 0.0433 | 0.0246 | 0.0852 | 0.0503 | 0.0766 | 0.0489 |
| UoMo(我们) | 0.0284 | 0.0135 | 0.0588 | 0.0349 | 0.0442 | 0.0247 | 0.0439 | 0.0143 | 0.0360 | 0.0178 | 0.0408 | 0.0221 | 0.0609 | 0.0343 |
| Improvement | 14.45% | 46.42% | 10.63% | 22.44% | 16.44% | 18.21% | 16.60% | 50.00% | 16.85% | 27.64% | 29.16% | 26.08% | 20.49% | 4.19% |
表3:生成任务性能
| 模型 | 北京 | 上海 | 南京 | 南京-4G | 南昌 | 南昌-4G | 山东 | |||||||
| RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | |
| HA | 0.2945 | 0.1887 | 0.2214 | 0.1180 | 0.1808 | 0.0877 | 0.1914 | 0.0941 | 0.2011 | 0.0948 | 0.2285 | 0.1176 | 0.1331 | 0.0409 |
| ARIMA | 0.2023 | 0.1237 | 0.1560 | 0.0811 | 0.1269 | 0.0592 | 0.1340 | 0.0634 | 0.1533 | 0.0709 | 0.1751 | 0.0848 | 0.1224 | 0.0380 |
| SpectraGAN | 0.3880 | 0.3005 | 0.1962 | 0.1234 | 0.3621 | 0.2717 | 0.3212 | 0.2160 | 0.2432 | 0.1787 | 0.2352 | 0.1260 | 0.2438 | 0.0809 |
| keGAN | 0.3041 | 0.3716 | 0.2695 | 0.1837 | 0.2525 | 0.1809 | 0.2601 | 0.1917 | 0.2241 | 0.1770 | 0.2132 | 0.1837 | 0.1742 | 0.1315 |
| Adaptive | 0.2885 | 0.2234 | 0.3019 | 0.2197 | 0.2631 | 0.1876 | 0.2099 | 0.1907 | 0.1959 | 0.1419 | 0.2436 | 0.1752 | 0.1605 | 0.1144 |
| Open-Diff | 0.2801 | 0.1993 | 0.1562 | 0.1102 | 0.2042 | 0.1813 | 0.1809 | 0.1602 | 0.1222 | 0.1511 | 0.2097 | 0.1749 | 0.1496 | 0.1097 |
| Time-LLM | 0.1472 | 0.1099 | 0.1765 | 0.1124 | 0.2463 | 0.1843 | 0.2239 | 0.1623 | 0.2861 | 0.1751 | 0.1909 | 0.1621 | 0.1789 | 0.0868 |
| Tempo | 0.3581 | 0.2559 | 0.1518 | 0.0787 | 0.2896 | 0.1892 | 0.2780 | 0.1793 | 0.2380 | 0.1347 | 0.2365 | 0.1306 | 0.1020 | 0.0275 |
| CSDI | 0.3822 | 0.2836 | 0.2880 | 0.0856 | 0.414 | 0.3034 | 0.3492 | 0.2520 | 0.3479 | 0.2913 | 0.3459 | 0.1307 | 0.2973 | 0.1705 |
| patchTST | 0.1512 | 0.1531 | 0.1627 | 0.0817 | 0.1521 | 0.1236 | 0.1044 | 0.0999 | 0.1830 | 0.0905 | 0.1789 | 0.2060 | 0.0985 | 0.0676 |
| TimeGPT | 0.3422 | 0.2433 | 0.1110 | 0.0766 | 0.2272 | 0.1391 | 0.2116 | 0.1345 | 0.1994 | 0.1001 | 0.1953 | 0.0919 | 0.0887 | 0.0253 |
| Laglama | 0.2313 | 0.1879 | 0.1453 | 0.0874 | 0.0960 | 0.0683 | 0.1115 | 0.0959 | 0.1091 | 0.0788 | 0.1684 | 0.0889 | 0.1076 | 0.0439 |
| UniST | 0.1156 | 0.0194 | 0.0264 | 0.0679 | 0.1831 | 0.0585 | 0.1268 | 0.0860 | 0.0853 | 0.0535 | 0.1445 | 0.0753 | 0.0622 | 0.0337 |
| UoMo(our) | 0.1025 | 0.1096 | 0.1983 | 0.0803 | 0.0818 | 0.0842 | 0.0849 | 0.0579 | 0.1387 | 0.0876 | 0.1206 | 0.0538 | 0.0518 | 0.0197 |
| 改进 | 27.47% | 31.36% | 11.44% | 11.35% | 14.79% | 10.14% | 23.85% | 10.09% | 21.81% | 18.76% | 16.54% | 26.29% | 16.72% | 22.13% |
| 模型 | 北京 | 上海 | 南京 | 南京-4G | 南昌 | 南昌-4G | 山东 | |||||||
| JSD | MAE | JSD | MAE | JSD | MAE | JSD | MAE | JSD | MAE | JSD | MAE | JSD | MAE | |
| SpectraGAN | 0.3621 | 0.1584 | 0.3788 | 0.1284 | 0.3477 | 0.2888 | 0.3352 | 0.2494 | 0.2285 | 0.1288 | 0.3482 | 0.1762 | 0.3364 | 0.1794 |
| keGAN | 0.3425 | 0.2297 | 0.3799 | 0.2183 | 0.3071 | 0.1808 | 0.2482 | 0.2804 | 0.4032 | 0.1988 | 0.4792 | 0.1693 | 0.4007 | 0.2387 |
| 自适应 | 0.3044 | 0.2143 | 0.4901 | 0.1848 | 0.3040 | 0.1531 | 0.4567 | 0.1365 | 0.2730 | 0.2251 | 0.3201 | 0.2481 | 0.2806 | 0.1889 |
| CSDI | 0.3385 | 0.1431 | 0.2331 | 0.1025 | 0.4044 | 0.1844 | 0.3875 | 0.2516 | 0.3416 | 0.2163 | 0.2895 | 0.1384 | 0.2666 | 0.2170 |
| Open-Diff | 0.2155 | 0.0112 | 0.2299 | 0.1020 | 0.2171 | 0.0149 | 0.2275 | 0.1322 | 0.2296 | 0.1036 | 0.2624 | 0.1222 | 0.1777 | 0.1203 |
| UoMo(our) | 0.2013 | 0.1894 | 0.2259 | 0.1002 | 0.194 | 0.1948 | 0.2100 | 0.0938 | 0.2226 | 0.1343 | 0.2494 | 0.1759 | 0.1558 | 0.0993 |
| 改进 | 6.58% | 6.60% | 1.74% | 1.76% | 6.76% | 17.49% | 4.29% | 29.04% | 2.58% | 19.02% | 4.95% | 5.15% | 21.19% | 17.45% |
该模块通过对比学习捕获上下文和移动流量特征之间的相关性。这使得模型能够在没有历史数据的情况下,根据环境变化推断潜在的流量分布。
4.3 零样本/少样本学习 (RQ2)
为了评估UoMo的零/Few shot学习能力,我们选择了UoMo在训练期间未遇到的两个数据集:杭州(中国)和慕尼黑(德国)。我们选择了在之前的multitask forecasting 中表现良好的4个基线:Open- Diff、TimeGPT、Laglama 和UniST。结果如图5所示,其中5%few- shot和10%few- shot表示模型训练
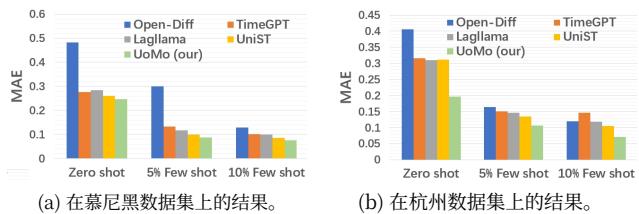
图5:零/少样本跨两个城市(慕尼黑:长期预测任务,杭州:短期预测任务)。
使用少量数据(分别为5%和10%)。它显示
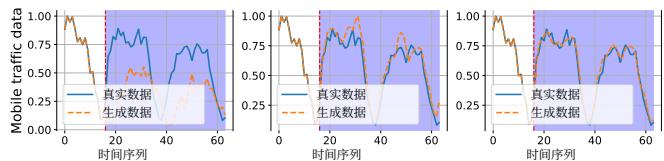
(a)在慕尼黑数据集上的零/少样本长期预测结果。
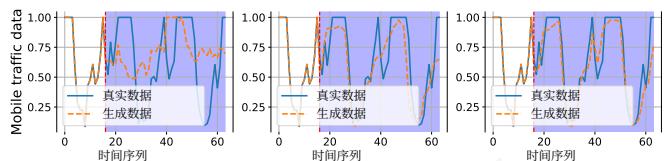
(b)在杭州数据集上的零/少样本长期预测结果。
图6:零/少样本学习的可视化。从左到右:零样本 →5%\rightarrow 5\%→5% 少样本 →10%\rightarrow 10\%→10% 少样本。
表4:在FY和NN数据集上的零/少样本评估
| 模型 | 零样本 (MAE) | 5%少样本 (MAE) | 10%少样本 (MAE) |
| UoMo (FY) | 0.136 | 0.034 | 0.023 |
| LagLlama (FY) | 0.132 | 0.094 | 0.053 |
| UoMo (NN) | 0.134 | 0.051 | 0.021 |
| LagLlama (NN) | 0.132 | 0.088 | 0.026 |
表明UoMo表现出良好的零样本性能,尤其是在慕尼黑数据集上,UoMo的零样本性能甚至在小规模训练后超过了Open- Diff。在小规模数据训练后,所有模型都表现出不同程度的改进。UoMo仍然表现出最佳性能,表明UoMo可以利用预训练模型快速捕获未见移动数据中的通用特征。我们在图6中可视化了零样本/少样本场景下的性能。我们选择一个长期预测任务,图中从左到右依次为零样本 →5%\rightarrow 5\%→5% 少样本 →10%\rightarrow 10\%→10% 少样本的结果。可以观察到,UoMo可以在零样本阶段学习移动流量的通用分布特征,在小样本训练后,模型实现了准确的流量预测。我们额外选择了两个数据集,阜阳(FY)和南宁(NN),来评估模型。这些数据集代表两个不同规模的中国城市,我们以小时粒度收集移动流量数据。如表4所示,与基线方法相比,UoMo也能够在小规模训练数据的情况下快速学习新城市的流量模式,展示了其可迁移性。
4.4 消融研究
为了测试我们提出的微调模块的有效性,我们在UoMo上进行了消融实验,如表5所示,其中UoMo- user和UoMo- POI分别表示在微调过程中整合移动用户和POI分布。可以观察到,在微调过程中添加这两个上下文特征增强了模型性能,程度各不相同
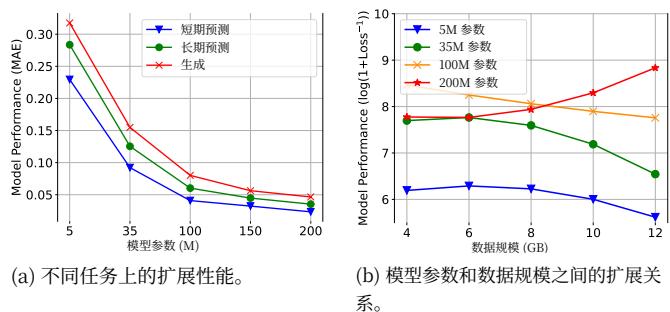
图7:UoMo的扩展性能。
。此外,UoMo- POI的性能下降更为显著,表明移动用户更能反映移动流量的动态特性,并且在移动流量预测中比POI分布更为关键。
表5:消融研究的性能。 Δ\DeltaΔ 表示移除某些模块后的性能下降。
| 模型 | 北京 | 上海 | 南昌 | |||
| 预测 (RMSE) | 生成 (ISD) | 预测 (RMSE) | 生成 (ISD) | 预测 (RMSE) | 生成 (ISD) | |
| UoMo(我们) | 0.1035 | 0.2213 | 0.0983 | 0.2202 | 0.0360 | 0.2226 |
| UoMo-user | 0.1230 | 0.2294 | 0.1295 | 0.2264 | 0.0421 | 0.2260 |
| Δ | 0.0338 | 0.1776 | 0.775 | 0.2438 | 0.0386 | 0.2468 |
| UoMo-POI | 0.1758 | 0.2464 | 0.1507 | 0.2362 | 0.0636 | 0.2301 |
| Δ | -88.38% | -67.47% | -80.36% | -63.13% | -89.61% | -76.53% |
| 预测练 | 0.1853 | 0.2585 | 0.1635 | 0.2457 | 0.0668 | 0.2324 |
4.5 UoMo的扩展性能
扩展性能反映了模型参数、数据大小和整体性能之间的关系。理解基础模型的扩展性能为模型部署过程中的参数选择提供了有价值的指导,从而优化整个系统的计算和存储开销。我们探讨了模型大小和任务性能之间的关系,如图7(a)所示。较小的模型随着参数的增加快速改进,而较大的模型则显示出边际效益递减
我们将此归因于较大模型相对于固定训练数据的参数冗余,导致过拟合并限制性能提升。为了评估扩展性能,我们在图7(b)中用不同数据集大小评估模型。较大模型在小数据集上性能下降,但随着数据量增加,它们利用其丰富的参数来提升性能。相比之下,较小模型难以处理多样化特征,导致性能下降。从这些观察中,我们为UoMo识别出一种扩展规律:仅仅增加模型参数并不能保证在移动交通预测中取得更好的性能。最佳模型大小取决于可用数据,这促使我们进一步研究模型规模与城市规模、人口和时序粒度等因素之间的关系,以提升性能。
5部署应用
5部署应用部署。为了验证UoMo的预测有效性,我们在九天平台上部署了该模型,这是一个由中国移动开发的AI平台,具备场景构建、网络仿真、优化策略制定和性能评估等功能。九天平台提供全要素网络仿真能力,能够高效仿真通信系统与用户行为之间的交互。它还支持运营商开发定制算法和应用,将其部署到生产环境,并使用真实网络数据进行产品验证和测试。该平台现已在中国移动全面部署,支持中国31个省份的网络发展。我们选择了预定义的城市布局和人类活动数据。UoMo部署在移动交通模块中,其预测结果输入到优化选择模块。我们关注三种优化场景(图中黄色高亮显示),并通过网络覆盖范围、吞吐量和能耗来评估性能。UoMo的训练使用4块NVIDIA A100 GPU(80GBeach)和PyTorch 2.0.1进行。表6总结了模型的参数和每样本的训练/推理时间。
表6:九天上的模型部署效率。训练/推理时间是指每个样本的单位时间,通过将生成一组数据所需的时间除以批量中的样本数量获得。
| 模型 | 层数 | 隐藏 feature | 参数 scale | 训练 time | 推理 time |
| Open-Diff | 6 | 128 | 10M | 0.09 min | 0.021 min |
| UniST | 12 | 512 | 30M | 0.19 min | 0.009 min |
| Laglama | 8 | 114 | 5M | 0.24 min | 0.011 min |
| 12 | 128 | 10M | 0.21 min | 0.043 min | |
| UoMo | 16 | 226 | 35M | 0.32 min | 0.054 min |
| 20 | 708 | 200M | 0.82 min | 0.162 min |
优化. Jiutian平台的优化方法如图8所示。首先,我们使用UoMo或其他移动流量预测算法生成流量数据。平台随后使用这些生成的数据来制定和解决网络优化和规划问题。在获得最优网络策略后,我们将真实的实时网络流量数据输入平台,以验证优化策略并评估其性能。
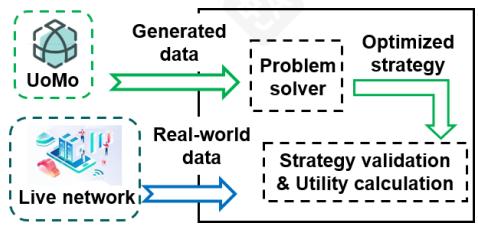
图8:UoMo的优化工作流程。
5.1基站部署
我们在一个离散时间{1,</style}…}框架内研究了网格级别的BS部署规划。目标区域由N组成
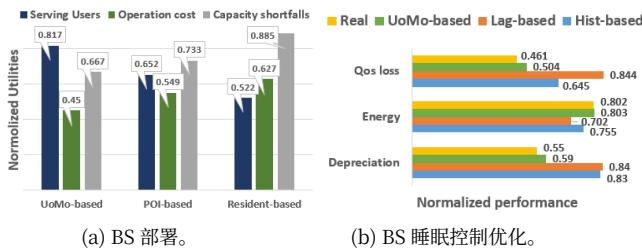
图9:使用实时系统数据的优化结果
网格组成,并且MBS需要在网格中部署。每个网格在不同的时间t会经历不同的移动用户,并且每个BS在任何给定时间都有C用户的最大容量。部署策略的目标是在每个网格中优化服务用户数量,同时最小化运营成本(在移动用户较少的网格中部署较少的BS)并减少容量不足(防止网格缺乏BS而无法容纳过多用户的情况)。由于目标区域没有移动用户分布的历史数据,我们依赖于预测方法来估计未来的移动流量需求。使用了三种不同的估计方法:使用(2)中的生成掩码的移动流量生成方法(基于UoMo)、基于POI的POI分布以及基于住宅人口分布的住宅人口分布。我们的重点是从长期角度解决BS部署问题。决策变量包括 xix_{i}xi ,它表示在网格i中部署的BS数量,以及 uitu_{i}^{t}uit ,它表示网格i在时间t服务的移动流量。然后BS部署问题产生
max∑tT∑iN(yit−β(U^it−yit)+−α∑iMxi)s.t.∑iNxi=M,0≤yit≤min{xiC0,F^it},(12) \begin{array}{l}{max\sum_{t}^{T}\sum_{i}^{N}\left(y_{i}^{t} - \beta (\hat{U}_{i}^{t} - y_{i}^{t})^{+} - \alpha \sum_{i}^{M}x_{i}\right)}\\ {s.t.\sum_{i}^{N}x_{i} = M,0\leq y_{i}^{t}\leq min\{x_{i}C_{0},\hat{F}_{i}^{t}\} ,} \end{array} \tag{12} max∑tT∑iN(yit−β(U^it−yit)+−α∑iMxi)s.t.∑iNxi=M,0≤yit≤min{xiC0,F^it},(12)
在 (y)+=max(0,y)(y)^{+} = max(0,y)(y)+=max(0,y) 表示在 yyy 和0之间选择最大值,而 U^it\hat{U}_{i}^{t}U^it 是UoMo、POI和住宅分布估计的移动网络需求。我们采用Pulp库来解决上述优化问题,并通过参考三种估计方法推导出3种不同的基站部署策略。随后,我们使用由九天平台流式传输的南昌真实用户移动轨迹数据测试优化策略,测试结果如图9(a)所示。基于UoMo的策略比最大化服务收入的同时显著降低了运营成本和容量不足,将服务用户比率提高了 25.3%25.3\%25.3% (从0.652提高到0.817),并将成本和不足分别降低了 18.03%18.03\%18.03% (从0.549降低到0.45)和 9.00%9.00\%9.00% (从0.733降低到0.667)。这种成功归因于UoMo考虑了不同区域网络使用的时变特性。通过使用UoMo准确估计移动流量预测,我们可以有效地捕捉区域内人类活动随时间变化的动态模式。相比之下,基于POI和住宅的策略仅依赖静态属性来指导基站部署。这些方法在捕捉人类活动随时间变化的动态模式方面效果较差,与基于流量的方法相比存在不足。
5.2基站睡眠控制
我们考虑C- RAN场景,其中基站通过激活不同数量的RRU[1]实现蜂窝覆盖。基站睡眠策略涉及根据网络负载控制RRU的运行状态(激活或睡眠)。我们从服务质量、折旧成本和能耗的角度对问题进行建模。我们设置 NNN 个基站,每个基站在时间 ttt 有 MMM 个单元格提供服务。定义单个RRU可服务的流量负载为 c0c_{0}c0 ,然后对于基站 nnn ,其服务质量(QoS)等于 Q(n)=∑t∑max(Lm,t−xmtc00)/Lmt,\begin{array}{r}Q(n) = \sum_t\sum_max(L_{m,t} - x_{m}tc_00) / L_{m}t, \end{array}Q(n)=∑t∑max(Lm,t−xmtc00)/Lmt, 其中 Lt,mL_{t,m}Lt,m 是实际单元格负载, xm,tx_{m,t}xm,t 是激活的RRU。此外,RRU的频繁切换会导致基站寿命的减少,折旧收益为 W(n)=∑t∑m∣xmt−xmt−∣hW(n) = \textstyle \sum_t\textstyle \sum_m\mid x_m t - x_{m}t - \mid_{\mathfrak{h}}W(n)=∑t∑m∣xmt−xmt−∣h 。基站能耗等于()P (.,tc0)](.,t c_0)](.,tc0)] En=∑t∑mE n = \textstyle \sum_t\textstyle \sum_mEn=∑t∑m [min Lm,xmL_{m},x_{m}Lm,xm 该值由RRU[70],处的负载决定,其中 P[L]=αL+β(L/c0)\mathcal{P}[L] = \alpha L + \beta (L / c_0)P[L]=αL+β(L/c0) 是能耗函数。因此,优化目标为:
min∑nY(xm,t(n)∣Lm,t(n))=Q(n)+W(n)+E(n).(13) min\sum_{n}Y(x_{m,t}^{(n)}|L_{m,t}^{(n)}) = Q(n) + W(n) + E(n). \tag{13} minn∑Y(xm,t(n)∣Lm,t(n))=Q(n)+W(n)+E(n).(13)
对于基站睡眠策略,在短时间内频繁调整RRU是不切实际的。更合理的方法是评估更长时间内的网络动态,并制定长期调整策略。因此,我们利用UoMo的长期预测能力,通过公式(1)中的长期预测掩码估计 Lm,tL_{m,t}Lm,t 。如图9(b)所示,基于UoMo的策略与基于实际的策略紧密一致,实现了 21.9%21.9\%21.9% 的服务质量提升(从0.645提升到0.504),并比其他方法降低了高达40.7 %\%% 的基站折旧(从0.83降低到0.59)。尽管能耗高于基线,但它与基于实际的策略相匹配,展示了UoMo的准确流量预测和强大的需求对齐能力。
6相关工作
移动流量预测。它可以大致分为两类:预测和生成。移动流量预测涉及使用历史数据估计未来值,而生成则学习移动流量的潜在分布,依赖于外部上下文信息和从这个分布中采样新数据。早期的预测使用了统计方法或模拟技术[3,11],但这些方法通常难以捕捉复杂的流量模式。随着机器学习的兴起,许多研究使用人工智能进行移动流量预测。对于移动流量预测,LSTM模型已被用于捕捉流量模式中的长期依赖关系[10,77,50]。一些研究将空间属性纳入流量预测,Li等人[27]结合了Transformer和GCN来捕捉时空相关性。Wu等人[55]结合了GAN和GCN来捕捉跨多个城市的空间相关性。MVSTGN模型[64]将城市空间划分为多属性图,以捕捉潜在空间中的移动流量特征。对于移动流量生成,早期工作使用GAN来捕捉移动流量的整体分布[44,30]。SpectraGAN[58]将城市视为图像,通过CNN提取POI和土地利用信息,并将其纳入流量生成。Sun等人[46]向GAN网络添加了用户使用特征,提高了流量生成的准确性。Hui等人[21]构建了一个城市知识图谱,将广泛的语义特征纳入流量生成模型。Open- Diff[8]使用扩散模型通过开放上下文数据生成网格级流量。
通用和基础模型。这些模型显示出在多任务和零/少样本学习中表现出色,并且已被应用于各种专业领域。Yang等人[61]和Zhang等人[72]提出了基础模型,旨在实现各种专业任务,如投资、量化和城市导航。值得注意的是,许多用于时空预测的通用模型已被提出。利用现有的LLM,TEMPO[7]和Time- LLM[23]在预测练的LLM中引入了一种提示机制,通过将移动流量和自然语言标记之间的特征对齐以及重新编程方法来进行长期预测。一些方法不依赖于现有的语言模型,而是使用Transformer架构重建时空基础模型。LagLLama[43]使用滞后索引来标注多维周期特征,如月度、每日和每小时周期。TimeGPT[15]用CNN替换了Transformer中的前馈层,以增强时间相关性。UniST[69]通过使用记忆网络在城市环境中实现了时空预测。虽然现有模型在预测移动流量方面具有优势,但它们通常是为特定任务设计的,如短期预测或生成[73,22,74]。在实际部署中,网络优化涉及跨城市的多个预测任务,需要频繁切换模型和复杂的适应,这增加了部署成本。主要挑战在于掌握各种预测任务,同时整合上下文特征,如人类动态和地理特征。这种整合对于构建一个能够捕捉环境、用户和移动流量之间内在相关性的鲁棒模型至关重要。
7结论
在本文中,我们提出了UoMo,一个用于移动流量预测的通用模型,该模型结合了扩散模型。据我们所知,这是移动网络中第一个同时支持多种预测任务(包括短期/长期预测和生成)的通用模型。通过捕捉与移动流量相关的时序、空间、人类动态和地理特征,UoMo展现出强大的多任务适应性和零/少样本学习能力,能够在多个城市处理各种任务,这体现了其良好的通用性。此外,我们通过检查不同参数规模和数据量下的模型性能,确定了UoMo的缩放特性。我们在九天平台上部署了UoMo,该平台利用其精确的流量预测来优化网络覆盖范围、吞吐量和能耗等多个方面。目前,UoMo已在中国广西省南宁市实现实时流量预测和数据流。该模型具有大规模部署的潜力,能够有效帮助运营商设计定价策略和网络扩展,从而提升用户体验和经济收益。
致谢
本研究部分得到了中国国家重点研发计划(项目编号:2023YFB2904801)、国家自然科学基金(项目编号:U23B2030)和中国博士后科学基金(项目编号:2023M742010)的支持。
[1] 2023. Artificial intelligence for reducing the carbon emissions of 5g networks in china. Nature Sustainability, 6, 1522- 1523. https://api.semanticscholar.org /CorpusID:260979998. [2] Jacob Austin, Daniel J. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. 2021. Structured denoising diffusion models in discrete state spaces. In Advances in Neural Information Processing Systems. M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, (Eds.) Vol. 34. Curran Associates, Inc., 17981- 17993. [3] Shruti Bothe, Haneya Naem Qureshi, and Ali Imran. 2019. Which statistical distribution best characterizes modern cellular traffic and what factors could predict its spatiotemporal variability? IEEE Communications Letters, 23, 5, 810- 813. doi:10.1109/LCOMM.2019.2908370. [4] Vukasin Bozic, Abdelaziz Elebouan, Yang Zhang, Radu Timonte, Markus Gross, and Christopher Schroers. 2024. Versatile vision foundation model for image and video colorization. In ACM SIGGRAPH 2024 Conference Papers (SIGGRAPH '24) Article 94. Association for Computing Machinery, Denver, CO, USA, 11 pages. ISBN: 9798400705250. doi:10.1145/3641519.3657509. [5] Tim Brooks et al. 2024. Video generation models as world simulators. https://o penai.com/research/video- generation- models- as- world- simulators. [6] Tom B Brown. 2020. Language models are few- shot learners. arXiv preprint arXiv:2005.14165. [7] Defu Cao, Furong Jia, Sercan O Arik, Tomas Pfister, Yixiang Zheng, Wen Ye, and Yan Liu. 2024. Tempo: prompt- based generative pre- trained transformer for time series forecasting. (2024). https://arxiv.org/abs/2310.04948 arXiv: 2310.04948 [cs.LG]. [8] Haoye Chai, Tao Jiang, and Li Yu. 2024. Diffusion model- based mobile traffic generation with open data for network planning and optimization. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD '24). Association for Computing Machinery, Barcelona, Spain, 4828- 4838. ISBN: 9798400704901. doi:10.1145/3637528.3671544. [9] Minen Chen, Yiming Miao, Hamid Gharavi, Long Hu, and Iztok Humar. 2020. Intelligent traffic adaptive resource allocation for edge computing- based 5g networks. IEEE Transactions on Cognitive Communications and Networking, 6, 2, 499- 508. doi:10.1109/TCCN.2019.2953061. [10] Anestis Dalgkitsis, Malamati Louta, and George T. Karetsos. 2018. Traffic forecasting in cellular networks using the lstm rnn. In Proceedings of the 22nd Pan- Hellenic Conference on Informatics (PCI '18). Association for Computing Machinery, Athens, Greece, 28- 33. ISBN: 9781450368616. doi:10.1145/3291533.3 291540. [11] Alvise De Biasio, Federico Chiariotti, Michele Polese, Andrea Zanella, and Michele Zorzi. 1979. A quit implementation for ns- 3. In. [12] Xiaoleiao Dong, Taejoon Kim, Jingjin Wu, and Eric Wing- Ming Wong. 2020. Millimeter- wave base station deployment using the scenario sampling approach. IEEE Transactions on Vehicular Technology, 69, 11, 14013- 14018. doi:10 .1109/TVT.2020.3026216. [13] Ahmed Fahim and Yasser Gadallah. 2023. An optimized lte- based technique for drone base station dynamic 3d placement and resource allocation in delay- sensitive m2m networks. IEEE Transactions on Mobile Computing, 22, 2, 732- 743. doi:10.1109/TMC.2021.3089229. [14] Zhiying Feng, Qiong Wu, and Xu Chen. 2024. Communication- efficient multiservice mobile traffic prediction by leveraging cross- service correlations. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD '24). ACM SIGKDD Conference on Knowledge Discovery, Spain, 794- 805. ISBN: 9798400704901. doi:10.1145/3637528.3671730. [15] Azul Garza and Max Mergenthaler- Canseco. 2023. Timegpt- 1. (2023). arXiv: 2310.03589 [cs.LG]. [16] Abdennaceur Ghandri, Houssed Eddine Nouri, and Maher Ben Jemaa. 2024. Deep learning for vbr traffic prediction- based proactive mbsfn resource allocation approach. IEEE Transactions on Network and Service Management, 21, 1, 463- 476. doi:10.1109/TNSM.2023.3311876. [17] Jiahui Gong, Yu Liu, Tong Li, Haoye Chai, Xing Wang, Junlan Feng, Chao Deng, Depeng Jin, and Yong Li. 2023. Empowering spatial knowledge graph for mobile traffic prediction. In Proceedings of the 31st ACM International Conference on Advances in Geographic Information Systems (SIGSPATIAL '23) Article 24. Association for Computing Machinery, Hamburg, Germany, 11 pages. ISBN: 9798400701689. doi:10.1145/3589132.362569. [18] Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew G Wilson. 2023. Large language models are zero- shot time series forecasters. In Advances in Neural Information Processing Systems. A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, (Eds.) Vol. 36. Curran Associates, Inc., 19622- 19635. https://proceedings.neurip. (c.) paper. files/paper/2023/file/3eb7ca52e8207697 361b2c0fb3926511- Paper- Conference.pdf. [19] Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS '20) Article 574. Curran Associates Inc., Vancouver, BC, Canada, 12 pages. ISBN: 9781713829546.
[20] Yahui Hu, Yujiang Zhou, Junping Song, Luyang Xu, and Xu Zhou. 2023. City- wide mobile traffic forecasting using spatial- temporal downsampling transformer neural networks. IEEE Transactions on Network and Service Management, 20, 1, 152- 165. doi:10.1109/TNSM.2022.3214483. [21] Shuodi Hui et al. 2023. Large- scale urban cellular traffic generation via knowledge- enhanced gains with multi- periodic patterns. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD '23). Association for Computing Machinery, Long Beach, CA, USA, 4195- 4206. ISBN: 9798400701030. doi:10.1145/3589035.359953 [22] Yushan Jiang, Zijie Pan, Xikun Zhang, Salsil Garg, Anderson Schneider, Yuriy Nevmyvaka, and Dongjin Song. 2024. Empowering time series analysis with large language models: a survey. In Proceedings of the Thirty- Third International Joint Conference on Artificial Intelligence (ICAI '24). Article 895. Jeju, Korea, 9 pages. ISBN: 978- 1- 956703- 04- 1. doi:10.3496/jicai.2024/895 [23] Ming Jin et al. 2024. Time- llm: time series forecasting by reprogramming large language models. (2024). https://arxiv.org/abs/2310.01728 arXiv: 2310.01728 [cs.LG]. [24] Inwon Kang. 2024. Advancing web science through foundation model for tabular data. In Companion Publication of the 16th ACM Web Science Conference (Websci Companion '24). Association for Computing Machinery, Stuttgart, Germany, 32- 36. ISBN: 9798400704536. doi:10.1145/3630744.3658614 [25] Migyeong Kang, Juho Jung, Minhan Cho, Daejin Choi, Eunil Park, Sangheon Pack, and Jinyoung Han. 2024. Poster: isoml: inter- service online meta- learning for newly emerging network traffic prediction. In Proceedings of the 22nd Annual International Conference on Mobile Systems Applications and Services (MOBISYS '24). Association for Computing Machinery, Minato- ku, Tokyo, Japan, 718- 719. ISBN: 9798400705816. doi:10.1145/36438323661437 [26] Fatemeh Kavehmadavani, Van- Dinh Nguyen, Thang X. Vu, and Symeon Chatzino- tas. 2024. Empowering traffic steering in 6g open ran with deep reinforcement learning. IEEE Transactions on Wireless Communications, 1- 1. doi:10.1109 /TWC.2024.3396273 [27] He Li, Duo Jin, Xuejiao Li, Jianbin Huang, Xiaoke Ma, Jiangtao Cui, Deshuang Huang, Shaojie Qiao, and Jaesoo Yoo. 2023. Dangf- net: an efficient dynamic multi- graph fusion network for traffic prediction. ACM Trans. Knowl. Discov. Data, 17, 3. Article 97. (Apr. 2023), 19 pages. doi:10.1145/3586164. [28] Tong Li, Shuodi Hui, Shiyuan Zhang, Huangdong Wang, Yuheng Zhang, Pan Hui, Depeng Jin, and Yong Li. 2024. Mobile user traffic generation via multi- scale hierarchical gain. ACM Trans. Knowl. Discov. Data, 18, 8, Article 189. (July 2024). Proceedings of the 2024 IEEE Conference on Wireless Communications and Networks. Liu, Youyun Xu, Lei Wang, and Jin- Yuan Wang. 2022. Coverage analysis and chance- constrained optimization for hsr communications with carrier aggregation. IEEE Transactions on Intelligent Transportation Systems, 23, 9, 15107- 15120. doi:10.1109/TITS.2021.3177030. [30] Zinan Lin, Alankar Jain, Chen Wang, Giulia Fanti, and Vyas Sekar. 2020. Using gans for sharing networked time series data: challenges, initial promise, and open questions. In Proceedings of the ACM Internet Measurement Conference (IMC '20). Association for Computing Machinery, Virtual Event, USA, 464- 483. ISBN: 9781450381383. doi:10.1145/34193943423643. [31] Chunchi Liu et al. 2024. Tbac: a tokoin- based accountable access control scheme for the internet of things. IEEE Transactions on Mobile Computing, 23, 5, 6133- 6148. doi:10.1109/TMC.2023.3316622. [32] Sudha Lohani, Roya Arab Loodaricheh, Ekram Hossain, and Vijay K. Bhargava. 2016. On multiuser resource allocation in relay- based wireless- powered uplink cellular networks. IEEE Transactions on Wireless Communications, 15, 3, 1851- 1865. doi:10.1109/TWC.2015.2496943. [33] Wencan Mao, Ozgur Umut Akgul, Byungjin Cho, Yu Xiao, and Antti Ala- Jaaski. 2023. On- demand vehicular fog computing for beyond 5g networks. IEEE Transactions on Vehicular Technology, 72, 12, 15237- 15253. doi:10.1109 /TVT.2023.3289862. [34] Weidong Mei and Rui Zhang. 2023. Joint base station and iris deployment for enhancing network coverage: a graph- based modeling and optimization approach. IEEE Transactions on Wireless Communications, 22, 11, 8200- 8213. doi:10.1109/TWC.2023.3260805. [35] Erhan Meskar and Ben Liang. 2023. Fair multi- resource allocation in heterogeneous servers with an external resource type. IEEE/ACM Transactions on Networking, 31, 3, 1244- 1262. doi:10.1109/TNET.2022.3213426. [36] Jie Miao, Zheng Hu, Kun Yang, Canru Wang, and Hui Tian. 2012. Joint power and bandwidth allocation algorithm with qos support in heterogeneous wireless networks. IEEE Communications Letters, 10, 4, 479- 481. doi:10.1109/LCOMM.2012.030512.112304. [37] Diala Naboulsi, Marco Fiore, Stephane Ribot, and Razvan Stanica. 2016. Large- scale, mobile traffic analysis: a survey. IEEE Communications Surveys & Tutorials, 18, 1, 124- 161. doi:10.1109/COMST.2015.2491361. [38] Yuqi Nie, Nam H. Nguyen, Phanwadee Sinhong, and Jayant Kalagnanam. 2023. A time series is worth 64 words: long- term forecasting with transformers. (2023). https://arxiv.org/abs/2211.14730 arXiv: 2211.14730 [cs. LG]. [39] Chandrasen Pandey, Vaibhav Tiwari, Joul J. P. C. Rodrigues, and Diptendu Sinha Roy. 2024. 5gt- gan- net: internet traffic data forecasting with supervised
loss based synthetic data over 5 g. IEEE Transactions on Mobile Computing, 1- 12. doi:10.1109/TMC.2024.3364655. [40] William Peebles and Sainig Xie. 2023. Scalable diffusion models with transformers. In 2023 IEEE/CVF International Conference on Computer Vision (ICCV), 4172- 4182. doi:10.1109/ICCV51070.2023.00387. [41] Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron Courville. 2018. Film: visual reasoning with a general conditioning layer. In Proceedings of the Thirty- Second AAAI Conference on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conference and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence (AAAI’18/AAAI’18/AAAI’18) Article 483. AAAI Press, New Orleans, Louisiana, USA, 10 pages. isbn: 978- 1- 57735- 800- 8. [42] Alec Radford et al. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning. PMLR, 8748- 8763. [43] Kashif Rasul et al. 2024. Lag- llama: towards foundation models for probabilistic time series forecasting. (2024). https://arxiv.org/abs/2310.08278 arXiv: 2310.08278 [cs.LG]. [44] Markus Ring, Daniel Schlot, Dieter Landes, and Andreas Hotho. 2019. Flow- based network traffic generation using generative adversarial networks. Computers & Security, 82, 156- 172. [45] Zhi Sheng, Yuan Yuan, Jingtao Ding, and Yong Li. 2025. Unveiling the power of noise priors: enhancing diffusion models for mobile traffic prediction. (2025). https://arxiv.org/abs/2501.13794 oreXiv:2051.13794 [cs.LG]. [46] Chuanhao Sun, Kai Xu, Marco Fiare, Mahesh K. Marina, Yue Wang, and Cezary Ziemlicki. 2022. Appshot: a conditional deep generative model for synthesizing service- level mobile traffic snapshots at city scale. IEEE Transactions on Network and Service Management, 19, 4, 4136- 4150. doi:10.1109/TNSM.2022.3199458. [47] Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. 2021. Csdii: conditional score- based diffusion models for probabilistic time series imputation. In Advances in Neural Information Processing Systems: M. Ranzato, A. Beygelzimer, Y. Dauphin, E.S. Liang, and J. Wortman Vaughan, (Eds.). Vol. 34. Curran Associates, Inc., 24504- 24816. [48] Hugo Touvron et al. 2023. Liqua: open and efficient foundation language models. arXiv preprint arXiv:13292.13971. [49] Aaron van den Oord, Yazhi Li, and Oriol Vinyals. 2019. Representation learning with contrastive predictive coding. (2019). https://arxiv.org/abs/1807.03748 arXiv:1807.03748 [cs.LG]. [50] Xiaojia Wang, Liang- Xiao, Xuanhong Ning, Lei- Cao, Zuziyu Wang, Xiuhai Cao, and Neeraj Kumar. 2022. Deep learning- based network traffic prediction for secure backbone networks in internet of vehicles. ACM Trans. Internet Technol., 22, 4, Article 87. (2022). doi:10.1145/3433548. [51] Zhen Wang, Guofu Wei, Xualing Zhan, and Yanhuan Sun. 2017. Big data in telecommunication operators: data, platform and practices. Journal of Communications and Information Networks, 2, 3, 78- 91. doi:10.1007/s41650- 017- 0010- 1. [52] Zi Wang, Jia Hu, Geyong Min, Zhiwei Zhao, and Jin Wang. 2021. Data- augmentation based cellular traffic prediction in edge computing- enabled smart- city. IEEE Transactions on Industrial Informatics, 17, 6, 4179- 4187. doi:10.1109/TII.2020.30 09159. [53] Qiong Wu, Xu Chen, Zhi Zhou, Liang Chen, and Junshan Zhang. 2021. Deep reinforcement learning with spatio- temporal traffic forecasting for data- driven base station sleep control. IEEE/ACM Trans. Netw., 29, 2, (Apr. 2021), 935- 948. doi:10.1109/TNET.2021.3053771. [54] Qiong Wu, Kaiwen He, Xue Chen, Shuai Yu, and Junshan Zhang. 2021. Deep transfer learning across cities for mobile traffic prediction. IEEE/ACM Trans. Netw., 30, 3, (Dec. 2021), 1255- 1267. doi:10.1109/TNET.2021.3136707. [55] Qiong Wu, Kaiwen He, Xue Chen, Shuai Yu, and Junshan Zhang. 2022. Deep transfer learning across cities for mobile traffic prediction. IEEE/ACM Transactions on Networking, 30, 3, 1255- 1267. doi:10.1109/TNET.2021.3136707. [56] Yi Wu, Pengcheng Jin, Yihan Zhang, Tiejiong Cai, and Ying Ji. 2023. Coverage quality optimization strategy for static heterogeneous wireless sensor networks. In 2023 International Conference on Ambient Intelligence, Knowledge Informatics and Industrial Electronics (AIKIIIE), 1- 6. doi:10.1109/AKIIIE.60097.2023.10390348. [57] Pengli Xu, Yong Li, Huanding Wang, Pengyu Zhang, and Depeng Jin. 2017. Understanding mobile traffic patterns of large scale cellular towers in urban environment. IEEE/ACM Trans. Netw., 25, 2, (Apr. 2017), 1147- 1161. doi:10.110 9/TNET.2016.2623950. [58] Kai Xu, Rajkarn Singh, Marco Fiore, Mahesh K. Marina, Hakan Bilen, Muhammad Usama, Howard Benn and Cezary Ziemlicki. 2021. Spectragan: spectrum based generation of city scale spatiotemporal mobile network traffic data. In Proceedings of the 17th International Conference on Emerging Networking Experiments and Technologies (CeNEXT’ 21), Association for Computing Machinery, Virtual Event, Germany, 243- 258. ISBN: 9781450390989. doi:10.1145/3485983.34 94844. [59] Xiongxiao Xu, Xin Wang, Elkin Cruz- Camacho, Christopher D. Carothers, Kevin A. Brown, Robert B. Ross, Zhiling Lan, and Kai Shu. 2023. Machine learning for interconnect network traffic forecasting: investigation and exploitation. In Proceedings of the 2023 ACM SIGSIM Conference on Principles of Advanced
Discrete Simulation (SIGSIM- PADS '23). Association for Computing Machinery, Orlando, FL, USA, 133- 137. ISBN: 978- 400100309. doi:10.1145/3573900.3591123. [60] Arwaneesh Kumar Yadav. 2024. Skapnasstwoymetric key- based authentication protocol for 5g network slicing. IEEE Transactions on Industrial Informatics, 20, 11, 13363- 13372. doi:10.1109/TII.2024.3431535. [61] Hongyang Yang, Xiao- Yang Liu, and Christina Dan Wang. 2023. Fingpt: open- source financial large language models. FinLIM Symposium at IJCAI 2023. [62] Ling Yang, Zhilong Zhang, Yang Song, Shenda Hong, Runsheng Xu, Yue Zhao, Wentao Zhang, Bin Cui, and Ming- Hsuan Yang. 2023. Diffusion models: a comprehensive survey of methods and applications. ACM Comput. Surv., 56, 4, Article 105, (Nov. 2023), 39 pages. doi:10.1145/3626235. [63] Shun- Ren Yang, Yu- Ju Su, Yao- Yuan Chang, and Hui- Nien Hung. 2019. Short- term traffic prediction for edge computing- enhanced autonomous and connected cars. IEEE Transactions on Vehicular Technology, 68, 4, 3140- 3152. doi:10.1109/TVT.2019.2899125. [64] Yang Yao, Bo Gu, Zhou Su, and Mohsen Guizani. 2023. Mvstgn: a multi- view spatial- temporal graph network for cellular traffic prediction. IEEE Transactions on Mobile Computing, 22, 5, 2837- 2849. doi:10.1109/MC.2023.3129796. [65] Chin- Chia Michael Yeh et al. 2023. Toward a foundation model for time series data. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKAC’23). Association for Computing Machinery, Birmingham, United Kingdom, 4400- 4404. ISBN: 9798400701245. doi:10.1145/3583780.3615155. [66] Jieli Yin, Yali Fan, Tong Xia, Yong Li, Xiang Chen, Zhi Zhou, and Xu Chen. 2020. Mobile app usage patterns aware smart data pricing. IEEE Journal on Selected Areas in Communications, 38, 4, 645- 654. doi:10.1109/JSAC.2020.2971896. [67] Yucheng Yin, Zinan Lin, Minhao Jin, Giulia Fanti, and Vyas Sekar. 2022. Practical gan- based synthetic ip header trace generation using netshare. In Proceedings of the ACM SIGCOMM 2022 Conference (SIGCOMM '22). Association for Computing Machinery, Amsterdam, Netherlands, 458- 472. ISBN: 9781450394208. doi:10.1145/3544216.3544251. [68] Jinliang Yuan et al. 2024. Mobile foundation model as firmware. In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking (ACM MobiCom '24). Association for Computing Machinery, Washington D.C., DC, USA, 279- 295. ISBN: 9784007048955. doi:10.1145/366534.3649361. [69] Yuan Yuan, Jingtao Ding, Jie Feng, Depei Jin, and Yong Li. 2024. Unis: a prompt- empowered universal model for urban spatio- temporal prediction. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Decision Making (KDD '24). IEEE Transactions on Computer Vision, Peking, China, 4095- 4106. ISBN: 9798400704901. doi:10.1145/3637528.3671662. [70] Sheng Zhang, Shenglin Zhao, Mingxuan Yuan, Jia Zeng, Jianguo Yao, Michael R. Lyu, and Irwin King. 2017. Traffic prediction based power saving in cellular networks: a machine learning method. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (SIGSPATIAL '17). Article 29. Association for Computing Machinery, Redondo Beach, CA, USA, 10 pages. ISBN: 9781450354905. doi:10.1145/319958.3140035. [71] Shiyuan Zhang, Tong Li, shuodi Hui, Guangyu Li, Yanping Liang, Li Yu, De- peng Jin, and Yong Li. 2023. Deep transfer learning for city- scale cellular traffic generation through urban knowledge graph. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD '23). Association for Computing Machinery, Long Beach, CA, USA, 4842- 4851. ISBN: 9798400701030. doi:10.1145/3580305.3599001. [72] Weijiao Zhang, Jindong Han, Zhao Xu, Han Ni, Hao Liu, and Hui Xiong. 2024. Towards urban general intelligence: a review and outlook of urban foundation models. ArXiv, abs/2402.01749. [73] Xiyuan Zhang, Ranak Roy Chowdhury, Rajesh K. Gupta, and Jingbo Shang. 2024. Large language models for time series: a survey. In Proceedings of the Thirty- Third International Joint Conference on Artificial Intelligence, IJCAI- 24. Kate Larson, (Ed.) Survey Track. International Joint Conferences on Artificial Intelligence Organization, (Aug. 2024), 8335- 8343. doi:10.24963/ijcai.2024/921. [74] Zijian Zhang, Yujie Sun, Zepu Wang, Yujie Nie, Xiaobo Ma, Ruolin Li, Peng Sun, and Xuegang Ban. 2025. Large language models for mobility analysis in transportation systems: a survey on forecasting tasks. (2025). https://arxiv.org/abs/2405.02357. arXiv:2405.02357 [cs.LG]. [75] Zhongliang Zhao, Lucas Pacheco, Hugo Santos, Minghui Liu, Antonio Di Maio, Denis Rosario, Eduardo Cerqueira, Torsien Braun, and Xianbin Cao. 2021. Predictive uav base station deployment and service offloading with distributed edge learning. IEEE Transactions on Nervyork and Service Management, 18, 4, 3955- 3972. doi:10.1109/TNSM.2021.3123216. [76] Shenghan Zhou, Chaofan Wei, Chaofei Song, Xing Pan, Wenbing Chang, and Linchao Yang. 2023. Short- term traffic flow prediction of the smart city using 5g internet of vehicles based on edge computing. IEEE Transactions on Intelligent Transportation Systems, 24, 2, 2229- 2238. doi:10.1109/ITTS.2022.3147845. [77] Feiyue Zhu, Lixiang Liu, and Teng Lin. 2020. An lstm- based traffic prediction algorithm with attention mechanism for satellite network. In Proceedings of the 2020 3rd International Conference on Artificial Intelligence and Pattern Recognition (AIPR '20). Association for Computing Machinery, Xiamen, China, 205- 209. ISBN: 9781450375511. doi:10.1145/3430199.3430208.
[78] Xiaomeng Zhu, Yi Li, Yuting Zheng, Rui Xia, Lexi Xu, Bei Li, Zixiang Di, Lu Zhi, 和 Xinzhou Cheng. 2022. 5G网络容量与扩展研究。在 2022年IEEE国际计算、通信和网络安全信任、安全与隐私会议 (TrustCom), 1473- 1478。doi:10.1109/TrustCom56396.2022.00209。
A 附录
A.1 数据集描述
我们从9个城市收集了移动流量和用户数据,覆盖超过30,000个基站,时间粒度从15分钟到1小时不等。POI数据从地图服务中抓取,包括15个类别,如生活方式、娱乐、工作和餐饮,如表7所示。
表7:数据集描述
| 数据集 | 使用 | Data | 移动流量 | 移动用户 | Time | |
| 描述 | 流量 | 粒度 | ||||
| 北京 | 模型训练 | 5G数据,2021年10月,4000+ BSs | ✓ | ✓ | 1小时 | |
| 上海 | 4G数据,2014年8月,5000+ BSs | ✓ | ✓ | 1小时 | ||
| 南京 | 5G数据,2021年2月至3月,6000+ BSs | ✓ | ✓ | 15 min | ||
| Nanjing-4G | 4G数据,2021年2月至3月,6000+ 小区 | ✓ | ✓ | 15 min | ||
| Nanchang | 5G数据,2023年7月,5000+ 小区 | ✓ | ✓ | 30 min | ||
| Nanchang-4G | 4G数据,2023年7月,7000+ 小区 | ✓ | ✓ | 30 min | ||
| 山东 | 5G数据,2024年7月,1000+ 小区 | ✓ | ✓ | 1小时 | ||
| 杭州 | 5G数据,2023年7月,1000+ 小区 | ✓ | ✓ | 1小时 | ||
| 葛思慧 | 4G数据,2000+ 2500+ 网格数据 | ✓ | - | 1小时 | ||
| POI | 架构,企业,餐厅,本地生活,交通,公共卫生,汽车,物理设施,住 | 购物,企业,餐厅,本地生活,交通,公共卫生,汽车,物理设施,住 | ||||
| 宿,金融,政府机构,教育,商业,公共设施,景点。 | ||||||
A.2 基线描述
统计模型。历史移动平均法(HA)和ARIMA方法,该方法将自回归与平均移动相结合。基于自然语言的模型。
Time- LLM使用自然语言描述时间序列特征,并将这些描述作为提示输入到自然语言预训练模型(LLAMA- 7B)中进行预测。Tempo为预训练模型(GPT- 2)设计具有趋势和季节性特征的时间提示,以预测时间序列。基于时空的模型。TimeGPT用CNN网络替换transformer中的前馈层,并在大量的时空数据上进行训练。Lagllama使用一组滞后索引来捕获时间序列中的不同周期相关性。CSDI是一种条件扩散模型它使用掩码方法对时间序列数据进行预测和插补。PatchTST将时间序列分解为多个片段,并使用transformer进行特征提取。UniST分割时空数据,并使用地理邻近性和时间相关性对模型进行微调。用于移动流量预测的专用模型。SpectraGAN将移动流量生成转换为图像生成问题,并利用基于CNN的GAN网络进行流量预测。KEGAN是一种分层GAN,它利用自构建的城市知识图谱(UKG)在预测过程中显式地包含城市特征。ADAPTIVE利用UKG和BS对齐方案将移动流量知识从一个城市转移到另一个城市。Open- Diff利用卫星图像、住宅计数和POI分布等开放上下文数据来生成移动流量数据。
A.3 引理1的证明
DDPM的前向链逐渐将高斯噪声 ϵ∼N(0,1)\epsilon \sim N(0,1)ϵ∼N(0,1) 添加到原始数据中,因为 q(xk∣xk−1)=N(1−βkxk−1,βkI),{βk∈(0,1,k‾∈(1,K)}q(x_{k}|x_{k - 1}) = N(\sqrt{1 - \beta_{k}x_{k - 1}},\beta_{k}\mathbf{I}),\{\beta_{k}\in (0,\overline{1,k}\in (1,K)\}q(xk∣xk−1)=N(1−βkxk−1,βkI),{βk∈(0,1,k∈(1,K)} 是一组计划噪声权重,并且步骤 kkk 生成的噪声数据可以通过 xk=α^kx0+(1−α^k)ϵx_{k} = \sqrt{\hat{\alpha}_{k}x_{0} + (1 - \hat{\alpha}_{k})\epsilon}xk=α^kx0+(1−α^k)ϵ 。反向链利用去噪网络 pθp_{\theta}pθ 来递归地恢复 xKx_{K}xK 到原始数据 x0x_{0}x0 ,从而产生 pθ(xk−1∣xk)=p_{\theta}(x_{k - 1}|x_{k}) =pθ(xk−1∣xk)= N(μθ(xk,k),σθ(xk,k)I)∘N(\mu_{\theta}(x^{k},k),\sigma_{\theta}(x_{k},k)\mathrm{I})_{\circ}N(μθ(xk,k),σθ(xk,k)I)∘ 扩散模型的目标本质上是最大化去噪网络 pθp_{\theta}pθ 对初始数据 x0x_{0}x0 的对数似然函数,即,
L(θ)=Ex0∼q(x0){−logpθ(x0)}.(14) L(\theta) = \mathbb{E}_{x_0\sim q(x_0)}\{-logp_\theta (x_0)\} . \tag{14} L(θ)=Ex0∼q(x0){−logpθ(x0)}.(14)
随后,该函数使用变分下界(VLB)进行优化,其可以表示为:
−logpθ(x0)≤−logpθ(x0)+DKL(q(x1:T∣x0)∣∣pθ(x1:T∣x0))=Eq(x1:T∣x0){logq(x1:T∣x0)pθ(x0:T∣x0)}.(15) \begin{array}{rl} & {-logp_{\theta}(x_0)\leq -logp_{\theta}(x_0) + D_{KL}(q(x_{1:T}|x_0)||p_{\theta}(x_{1:T}|x_0))}\\ & {\qquad = \mathbb{E}_{q(x_{1:T}|x_0)}\{log\frac{q(x_{1:T}|x_0)}{p_{\theta}(x_{0:T}|x_0)}\} .} \end{array} \tag{15} −logpθ(x0)≤−logpθ(x0)+DKL(q(x1:T∣x0)∣∣pθ(x1:T∣x0))=Eq(x1:T∣x0){logpθ(x0:T∣x0)q(x1:T∣x0)}.(15)
对上述方程两边取期望并应用Fubini定理[62],我们可以推导出:
L(θ)=Eq(x0){−logpθ(x0)}≤Eq(x0){pq(x1:T∣x0){logq(x1:T∣x0)pθ(x0:T∣x0)}}=Eq(x0:T){logq(x1:T∣x0)pθ(x0:T∣x0)}≥Lνb(θ).(16) \begin{array}{r}L(\theta) = \mathbb{E}_{q(x_0)}\{-logp_\theta (x_0)\} \leq \mathbb{E}_{q(x_0)}\Big\{p_{q(x_{1:T}|x_0)}\{log\frac{q(x_{1:T}|x_0)}{p_\theta(x_{0:T}|x_0)}\} \Big\} \\ = \mathbb{E}_{q(x_{0:T})}\{log\frac{q(x_{1:T}|x_0)}{p_\theta(x_{0:T}|x_0)}\} \geq L_{\nu b}(\theta). \end{array} \tag{16} L(θ)=Eq(x0){−logpθ(x0)}≤Eq(x0){pq(x1:T∣x0){logpθ(x0:T∣x0)q(x1:T∣x0)}}=Eq(x0:T){logpθ(x0:T∣x0)q(x1:T∣x0)}≥Lνb(θ).(16)
我们可以通过最小化 LνbL_{\nu b}Lνb 来最小化 L(θ)L(\theta)L(θ) 的上界,从而最大化 pθp_{\theta}pθ 的对数似然函数。Ho et al.[19]证明了 Lνb(θ)L_{\nu b}(\theta)Lνb(θ) 可以进一步通过 μθ(xk,k)=αk−0.5[xk−βk(1−α^k)−0.5ϵθ(xk,k)]\mu_{\theta}(x_{k},k) = \alpha_{k}^{- 0.5}[x_{k} - \beta_{k}(1 - \hat{\alpha}_{k})^{- 0.5}\epsilon_{\theta}(x_{k},k)]μθ(xk,k)=αk−0.5[xk−βk(1−α^k)−0.5ϵθ(xk,k)] 参数化,而 σθ\sigma_{\theta}σθ σθ(xk,k)=(1−α^k−1)/(1−α^k)βk\sigma_{\theta}(x_{k},k) = \sqrt{(1 - \hat{\alpha}_{k - 1}) / (1 - \hat{\alpha}_{k})}\beta_{k}σθ(xk,k)=(1−α^k−1)/(1−α^k)βk 可以参数化为。然后,网络 pθp_{\theta}pθ 可以通过以下目标进行优化:
minθLνb(θ)≈minθEx0∼q(x0),ϵ∼N(0,L)∣∣ϵ−ϵθ(xk,k)∣∣22].(17) \min_{\theta}L_{\nu b}(\theta)\approx \min_{\theta}\mathbb{E}_{x_0\sim q(x_0),\epsilon \sim N(0,L)}||\epsilon -\epsilon_\theta (x_k,k)||_2^2 ]. \tag{17} θminLνb(θ)≈θminEx0∼q(x0),ϵ∼N(0,L)∣∣ϵ−ϵθ(xk,k)∣∣22].(17)
方程(17)中的目标本质上等同于对比学习中InfoNCE的目标。我们使用 pθp_{\theta}pθ 来表示互信息中的概率,即 I(x,y)=pθ(e0:K∣y)/pθ(e0:K)∘I(x,y) = p_{\theta}(e_{0:K}|y) / p_{\theta}(e_{0:K})_{\circ}I(x,y)=pθ(e0:K∣y)/pθ(e0:K)∘ 通过这种方式,原始InfoNCE损失可以重写为:
L=Ee∈B−logpθ(e0:K∣y)/pθ(e0:K)pθ(e0:K∣y)/pθ(e0:K)+∑e′pθ(e0:K′∣y)/pθ(e0:K′)=Ee∈Blog{1+pθ(e0:K)pθ(e0:K∣y)⋅NEe′pθ(e0:K′∣y)pθ(e0:K′)},(18) \begin{array}{r}L = \mathbb{E}_{e\in \mathbb{B}} - log\frac{p_{\theta}(e_{0:K}|y) / p_{\theta}(e_{0:K})}{p_{\theta}(e_{0:K}|y) / p_{\theta}(e_{0:K}) + \sum_{e'}p_{\theta}(e_{0:K}'|y) / p_{\theta}(e_{0:K}')}\\ = \mathbb{E}_{e\in \mathbb{B}}log\{1 + \frac{p_{\theta}(e_{0:K})}{p_{\theta}(e_{0:K}|y)}\cdot \mathbb{N}\mathbb{E}_{e'}\frac{p_{\theta}(e_{0:K}'|y)}{p_{\theta}(e_{0:K}')}\} , \end{array} \tag{18} L=Ee∈B−logpθ(e0:K∣y)/pθ(e0:K)+∑e′pθ(e0:K′∣y)/pθ(e0:K′)pθ(e0:K∣y)/pθ(e0:K)=Ee∈Blog{1+pθ(e0:K∣y)pθ(e0:K)⋅NEe′pθ(e0:K′)pθ(e0:K′∣y)},(18)
where,表示所有负样本。参考[2]中的参数化,其中 ρθ(xk−1∣xk)\rho_{\theta}(x_{k - 1}|x_{k})ρθ(xk−1∣xk) =∑x0∈qq(xk−1∣xk,x0)pθ(x0∣xk)= \sum_{x_0\in q}q(x_{k - 1}|x_{k},x_0)p_\theta (x_0|x_k)=∑x0∈qq(xk−1∣xk,x0)pθ(x0∣xk) ,上述损失可以进一步表示为:
L≈E{Eq{−logpθ(e0:K∣y)q(e1:K∣e0)}−logNEe′Eq{−logpθ(e0:K′∣y)q(e1:K′∣e0′)}}=Lνbe−logN∑e′Lνbe′≐E{(∥ϵ−ϵθ(e,k∣y)∥2−λ∑e′∥ϵ−ϵθ(e′,k∣y)∥2)⊙m},(19) \begin{array}{rl} & {L\approx \mathbb{E}\Big\{\mathbb{E}_{q}\{-log\frac{p_{\theta}(e_{0:K}|y)}{q(e_{1:K}|e_{0})}\} -logN\mathbb{E}_{e'}\mathbb{E}_{q}\{-log\frac{p_{\theta}(e_{0:K}'|y)}{q(e_{1:K}'|e_{0}')}\} \Big\}}\\ & {\quad = L_{\nu b}^{e} - logN\sum_{e'}L_{\nu b}^{e'}}\\ & {\quad \doteq \mathbb{E}\Big\{(\| \epsilon -\epsilon_{\theta}(e,k|y)\|^{2} - \lambda \sum_{e'}\| \epsilon -\epsilon_{\theta}(e',k|y)\|^{2})\odot m\Big\} ,} \end{array} \tag{19} L≈E{Eq{−logq(e1:K∣e0)pθ(e0:K∣y)}−logNEe′Eq{−logq(e1:K′∣e0′)pθ(e0:K′∣y)}}=Lνbe−logN∑e′Lνbe′≐E{(∥ϵ−ϵθ(e,k∣y)∥2−λ∑e′∥ϵ−ϵθ(e′,k∣y)∥2)⊙m},(19)
其中符号 ≐\doteq≐ 表示我们在模型训练过程中使用的损失函数, λ\lambdaλ 是一个与 logNlogNlogN 成比例的缩放参数。