视觉语言导航(11)——预训练范式 4.1
这是课上做的笔记,因此很多记得比较急,之后会逐步完善,每节课的逻辑流程写在大纲部分。
VLN领域发展初期最主要的障碍之一,是高质量训练数据的严重稀缺性 。
VLN领域发展初期的数据集,如Room-to-Room (R2R) 数据集,虽然开创了
领域先河,但其构建基础‘Matterport3D数据集’仅包含了有限数量的室内场景(约61至90个
训练环境)。对于需要从零开始学习复杂视觉语言对应关系和导航策略的深度学习模型而言,
这样规模的数据量远远不够。
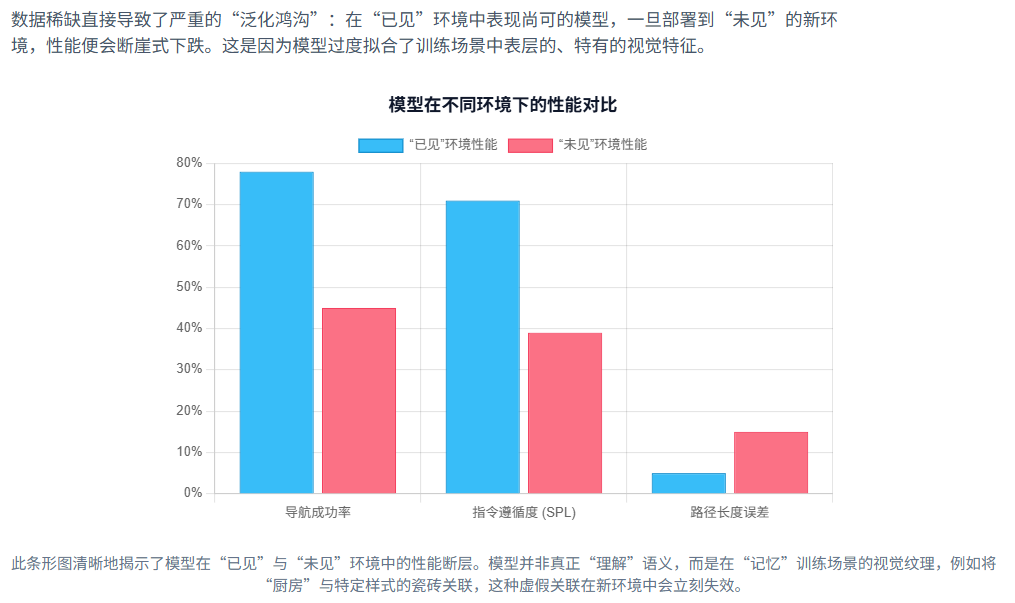
模型在这种“小数据”上训练,极易陷入对训练环境的过度拟合,而无法学习到能够泛化至未知环境的鲁棒知识障碍之一,是高质量训练数据的严重稀缺性 。
这一瓶颈的形成源于VLN数据采集与标注的内在复杂性。具体而言,手动收集照片般逼真的环
境观测数据,并为导航路径配上详细、自然的语言指令,是一个极其繁琐、昂贵且耗时的过程,
这极大地限制了数据集的可扩展性 。
早期范式的局限性
在预训练范式出现之前,VLN模型主要依赖于模仿学习(Imitation Learning, IL)和强化学习
(Reinforcement Learning, RL)从零开始进行训练。然而,在数据稀缺和泛化鸿沟的背景下,这些方法暴露出了其固有的局限性


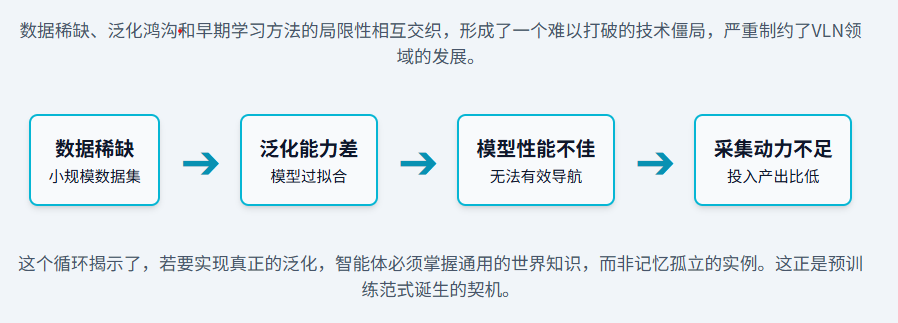
数据稀缺性、泛化鸿沟以及早期学习方法的内在缺陷,共同构成了一个阻碍VLN发展的“恶性循环”
预训练范式
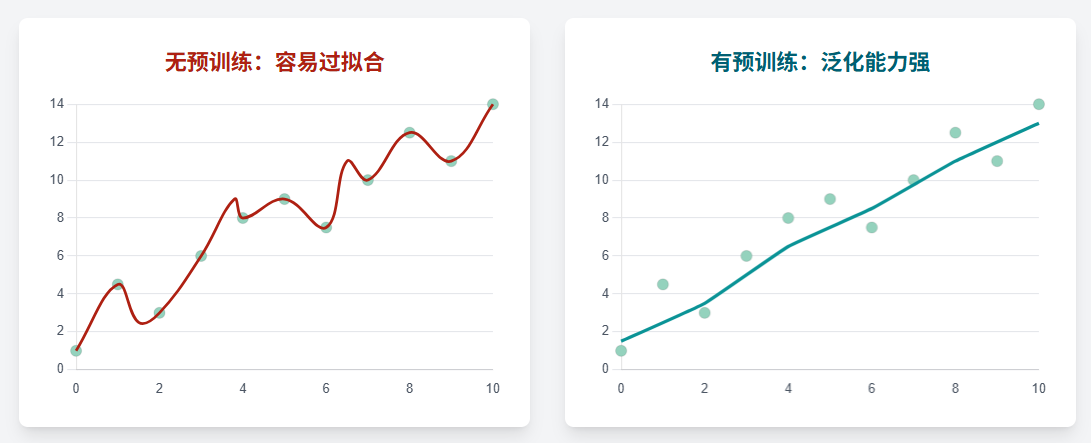
预训练本身也一定程度上起到了正则化器(Regularizer)的作用。
面对上一章所述的问题,研究界从自然语言处理(NLP)和计算机视觉(CV)领域的成功实践中获得启发,引入了“预训练-微调”(Pre-train & Fine-tune)的新框架,为VLN的发展开辟了全新的道路。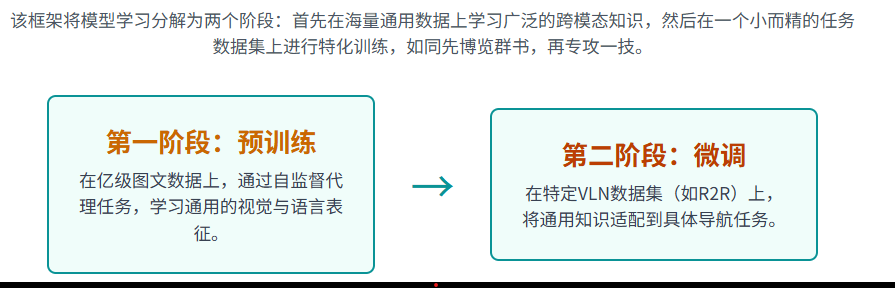
最典型的就是VLN-BERT,使用BERT做预训练,处理文字部分的输入Q。
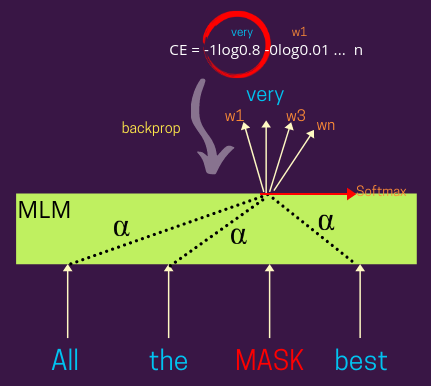
预训练的能力在很大程度上源于其对自监督学习(Self-supervised Learning)的巧妙运用。自监督
学习的核心思想是从数据本身自动生成标签,从而摆脱对昂贵的人工标注的依赖 。例如,在文本
中随机遮盖(mask)一个词,然后让模型根据上下文预测这个被遮盖的词,这就是一个典型的自
监督代理任务
训练数据可以基于导航任务内和任务外两种


基础预训练模型与方法
读高中
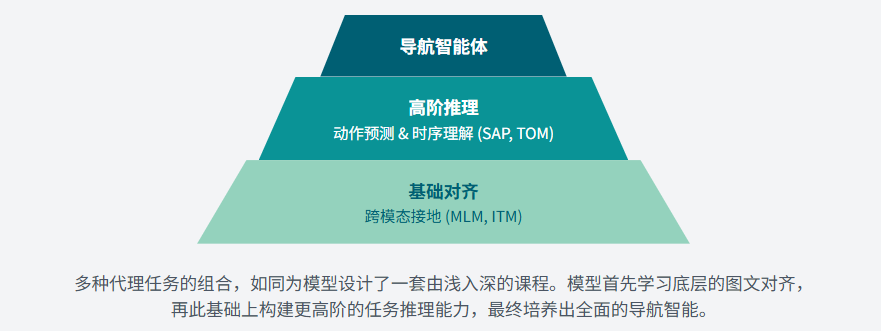
在学习具体的预训练模型之前,我们必须首先掌握驱动这些模型学习的引擎——代理任务(Pretext Tasks)。这些自监督的学习目标是模型在接触到真正的VLN任务之前,用以学习通用视觉语言表征的核心。
语言掩码(MLM)

图文匹配(ITM)

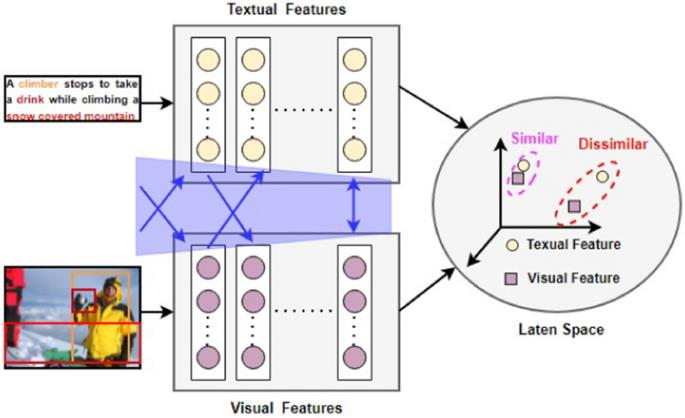
读大学
仅仅借鉴静态的视觉语言任务是不够的,还需要设计更贴近导航本质的代理任务
动作预测(SAP) 轨迹还原(TOM)

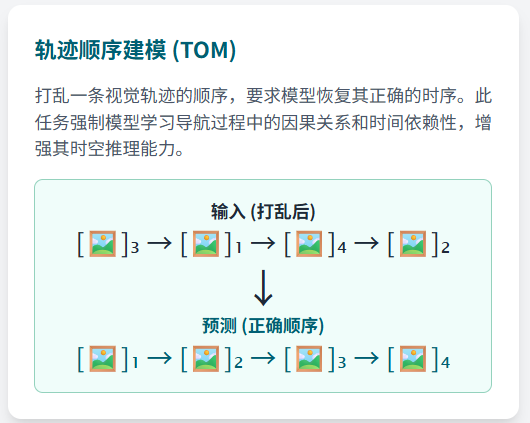
空间关系预测(SPREL) 轨迹合理性判断


总结
预训练-微调”不仅是一种技术手段的升级,更是一种研究思想的革新。它将VLN领域的研究重点,从过去过度关注为特定任务设计精巧的网络架构,转向了如何构建更有效的预训练目标和更大规模、更高质量的预训练数据。(从专家走向通识)
这一转变成功地为VLN智能体装上了“知识的引擎”,为其在真实世界中实现更高级别的理解和导航能力奠定了坚实的基础,并为后续章节将要探讨的更前沿技术铺平了道路
经典架构刨析

PREVALENT框架
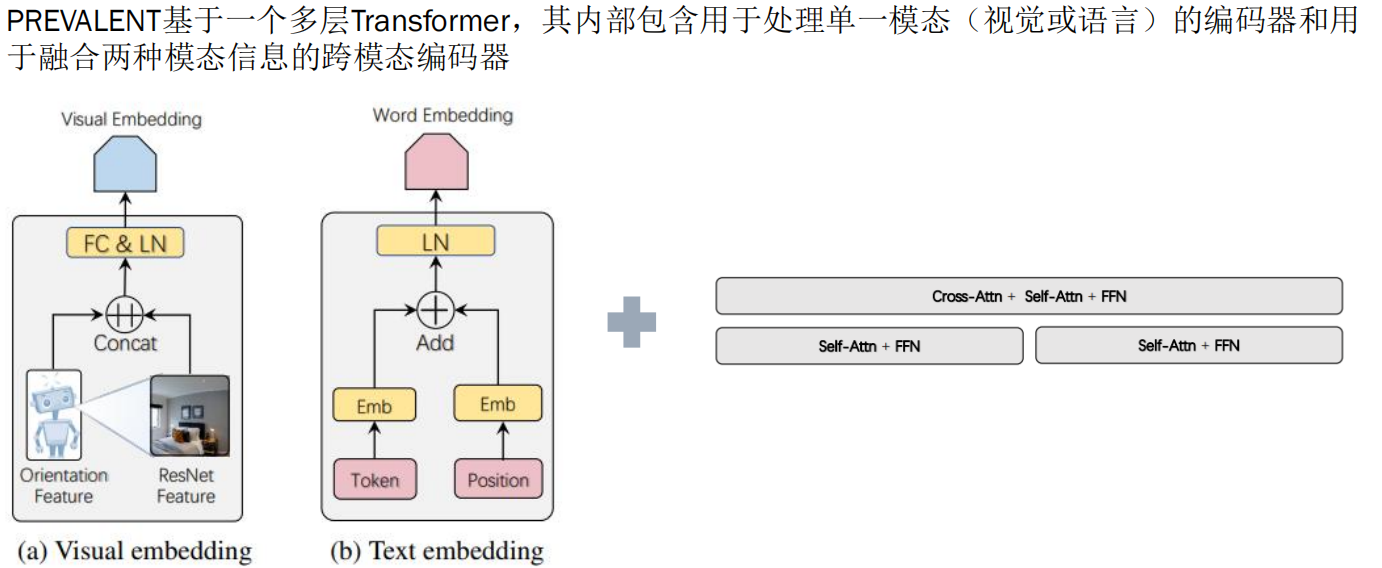

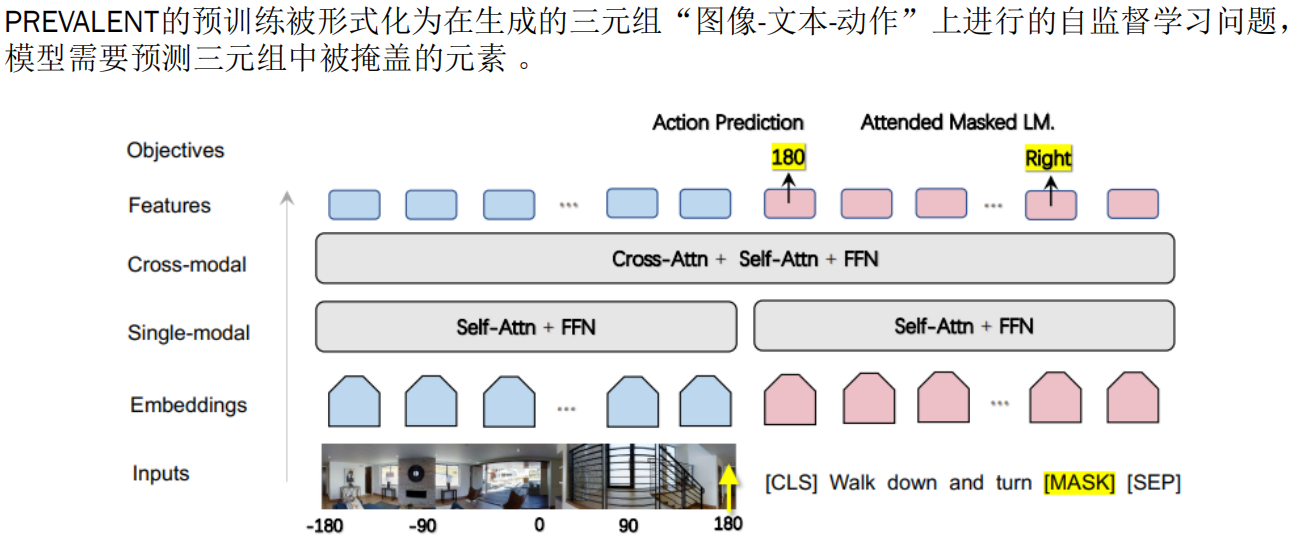
PREVALENT的预训练被形式化为在生成的三元组“图像-文本-动作”上进行的自监督学习问题,
模型需要预测三元组中被掩盖的元素 ,这一过程的核心在于两个代理任务:

- 每条 R2R 轨迹包含:
- 一系列视觉观察(panoramic views at each step)
- 一条自然语言指令(如 “Walk forward and turn left at the kitchen”)
- 一系列真实动作序列(如 ↑, ←, ↑, ↑, ■)
所以,PREVALENT 把这些数据组织成 (V, M, A) 三元组进行训练。
两种任务MLM和SAP
在 MLM-A(带动作上下文的掩码语言建模) 任务中:
- 输入的文本指令 MM 中随机掩盖一部分词,得到 M~M~
- 同时输入当前的 视觉观察 VV 和 下一步动作 AA
- 模型通过:
- 单模态自注意力(Self-Attention in Text Stream)
- 跨模态注意力(Cross-Modal Attention between Text, Image, Action)
- 最终预测被掩盖的词
在 SAP(情境化动作预测) 任务中:
- 训练时:
- 输入:自然语言指令 M + 当前视觉观察 V
- 输出:下一步应执行的动作 A(分类任务)
- 推理时(即“应用中”):
- 同样输入 M 和 V
- 模型输出动作 A,用于控制 agent 移动
📌 这就是 VLN 任务的核心:根据语言和视觉,决定怎么走
计算综合损失
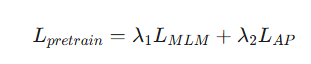
重新定义了具身智能体的“预训练任务”可以是什么。它将目标从简单的跨模态对齐(如图像-文本匹配)转变为为行动服务的跨模态接地(从QV训练理解的准确性,到QA训练动作的准确性)。通过将动作引入预训练三元组,它迫使模型学习的表征本质上对下游的策略学习更有用。
Recurrent VLN-BERT框架
在VLN中,智能体在每一步都需要知道“我从哪里来”、“我做过什么”,而不仅仅是“我在哪里”。
如果使用标准Transformer,就需要在每一步都将完整的历史观测序列作为输入,这在计算上是极其昂贵且低效的。Recurrent VLN-BERT的核心创新在于Transformer架构内部引入了一个循环函数,使其具备“时序感知”能力 。
我们现在来看一下Recurrent VLN-BERT 的整体框架,它采用了基于ViLBERT的双流Transformer架构。
在该架构中,视觉和语言信息首先在各自独立的流(stream)中进行处理,然后通过一系列“协同
注意力”(co-attentional)层进行深度交互和融合
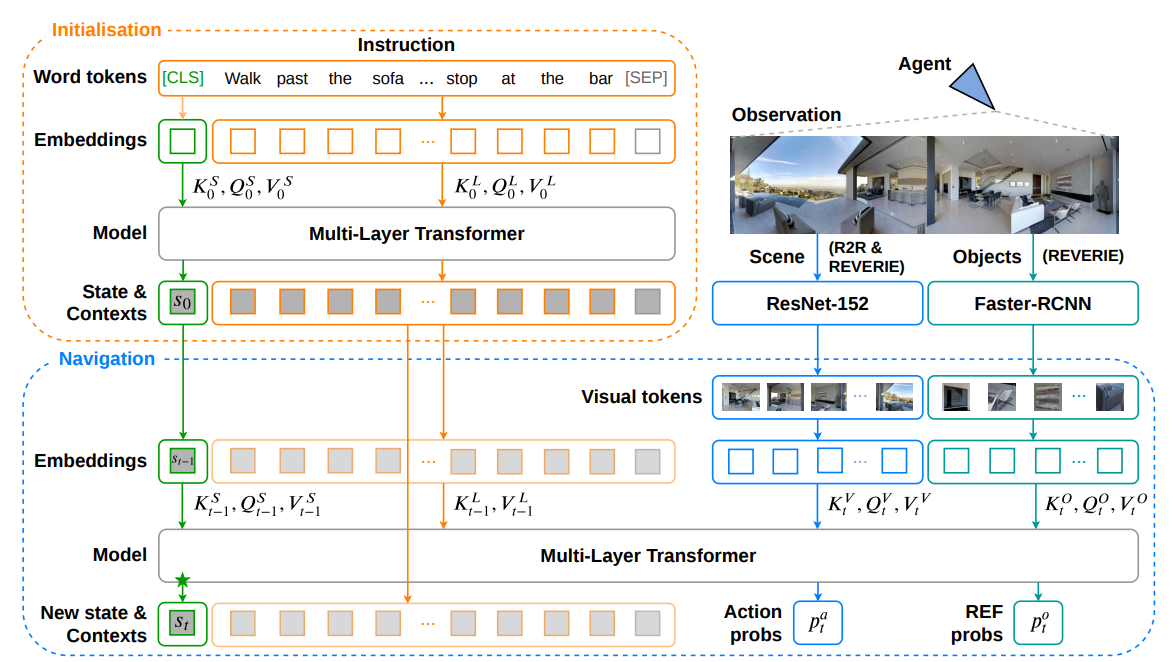
我们来看整个模型是怎么工作的:
[Step t]↓
1. 输入:当前视角图像 V_t + 指令 M↓
2. CMA 模块:用 Cross-Attention 融合 V_t 和 M → 得到 fused representation↓
3. 取 [CLS] 或 [NAV] token 的表示 h_t(代表“当前状态”)↓
4. 输入 GRU:h_t → GRU(hidden_{t-1}) → hidden_t↓
5. 输出动作:P(a_t | h_t, hidden_t) → 选择 ↑ / ← / → / ■↓
[Step t+1]✅ 所以你说的:
“先用交叉注意力处理跨模态,再把 [NAV] 向量送进 GRU 做序列建模”
是 完全正确的!👏

🎯 三、为什么说它是“解耦”?——这才是重点!
答案是:“解耦”指的是训练方式,不是推理结构
🔹 解耦的本质:
| 模块 | 训练方式 | 是否冻结 |
|---|---|---|
| CMA(跨模态融合) | 在大规模 CC 数据集上预训练 | ✅ 推理时通常冻结 |
| GRU(序列建模) | 在 R2R 等任务数据上微调 | ✅ 可训练 |
🎯 所以“解耦”意思是:
“先用大量数据学好‘看图说话’(CMA),再用少量任务数据学‘怎么走’(GRU)”
而不是像 LLM 那样所有参数一起从头训练。
Airbert框架
Airbert 认为,要提升视觉语言导航(VLN)模型的性能和泛化能力,关键在于使用与任务高度相关的领域内数据进行训练,而不是依赖通用的预训练数据集。
- 领域内数据的重要性:Airbert 提出,为了更好地解决 VLN 任务,应该创建一个大规模的、专门针对室内导航的数据集。这个数据集应该包含大量的室内环境图片和对应的导航指令,这样模型才能更有效地学习到如何在特定的室内环境中理解和执行导航指令。
- 具体做法:Airbert 使用了 Airbnb 的房源(BnB listings)来构建这样一个领域内数据集。这些房源图片和描述都是关于室内环境的,非常适合用来训练 VLN 模型。
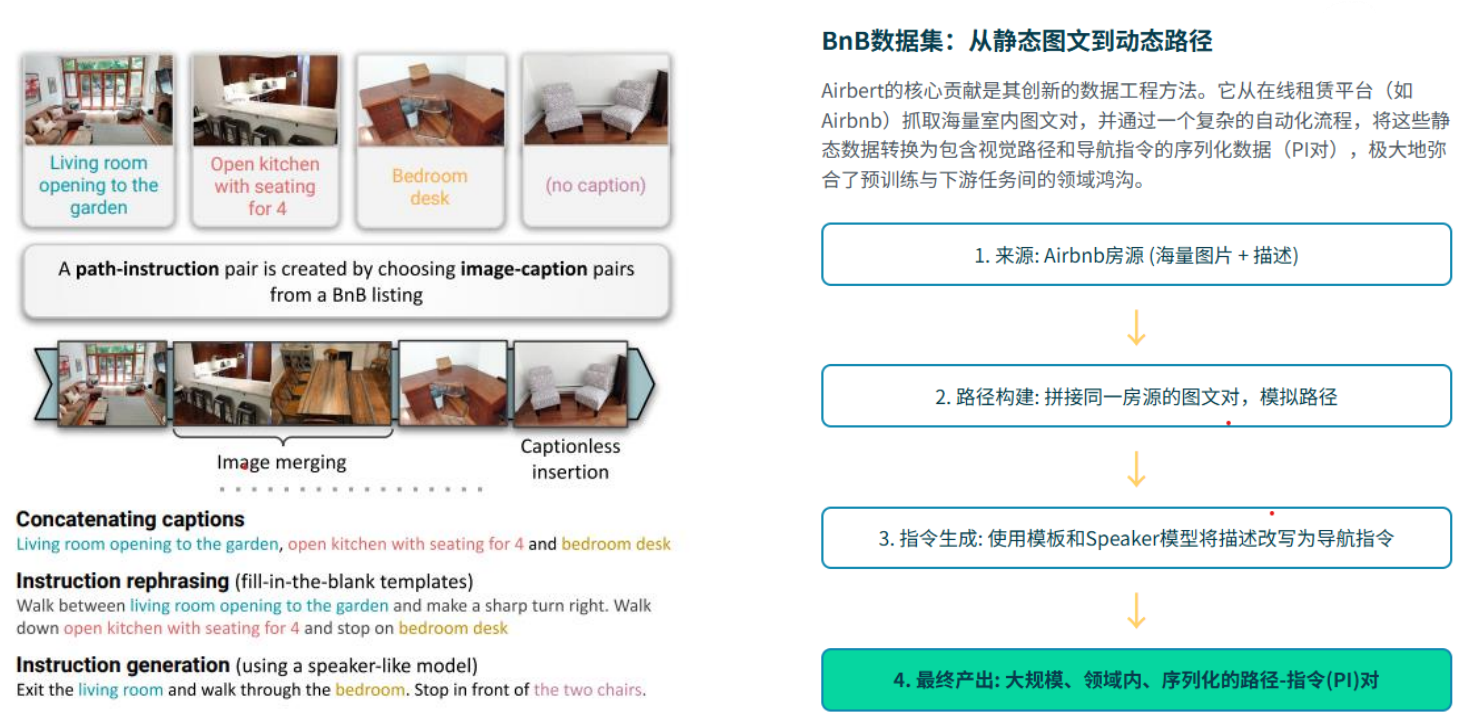
✅ 生成任务(Generative task)
- 这个过程考验了模型的理解能力和路径规划能力。
✅ 判别任务(Discriminative task)
- 这个过程考验了模型的判断能力和对指令的理解能力。
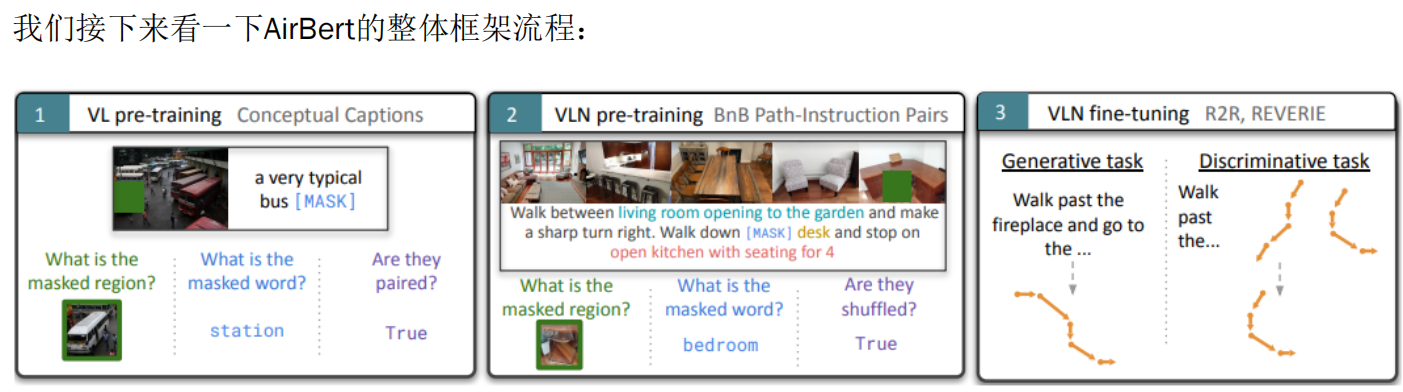
AirBert的三步走策略
第一步:视觉与语言预训练(VL pre-training)
- 任务:
- 猜测被遮盖的区域是什么(如图中的绿色框)。
- 猜测被遮盖的文字是什么(如“station”)。
- 判断图片和描述是否匹配(如“True”表示匹配)。
这个过程帮助AirBert学会如何将视觉信息和语言信息联系起来。
第二步:视觉导航预训练(VLN pre-training)
- 任务:
- 猜测被遮盖的区域是什么(如图中的绿色框)。
- 猜测被遮盖的文字是什么(如“bedroom”)。
- 判断路径和指令是否匹配(如“True”表示匹配)。
这个阶段让AirBert学会了如何理解和执行复杂的导航指令。
第三步:视觉导航微调(VLN fine-tuning)
- R2R, REVERIE:使用真实的数据集(如R2R和REVERIE)进行微调,这些数据集包含了各种复杂的导航任务。
- 任务:
- 生成任务:根据指令生成一条正确的路径,比如“走过壁炉,然后去……”。
- 判别任务:判断给定的路径是否正确,比如“走过……”。
- 任务:

Airbert代理任务
除了MLM和ITM,Airbert还引入了一种新颖的乱序损失(Shuffling Loss),通过判断轨迹片段是
否被打乱来提升模型的时序推理能力,这个数据和与之匹配的对比损失函数,它迫使模型学习
视觉路径和语言指令之间的时序对齐关系



Airbert贡献
Airbert模型本身是一个通用的、类似ViLBERT的Transformer骨干网络,与Recurrent VLNBert不同,这篇工作的主要贡献并非源于新颖的架构,而是通过其创新的数据和预训练任务所学习到的表征。预训练后的Airbert可以灵活地适配于判别式(如路径选择)和生成式(如序列化动作预测,类似于Recurrent VLN-BERT)的下游VLN任务。


对基础模型的影响
高级架构——BEVBERT
如何获取混合图:细节度量图(grid)+粗略拓扑图(topo)负责高层规划路径、精密导航
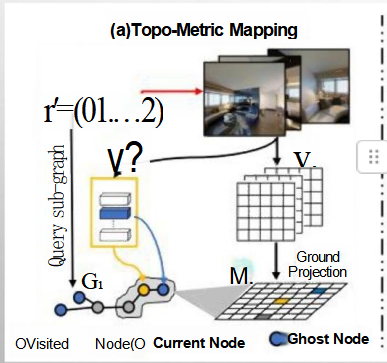
如何利用这些混合图和输入文字预训练:
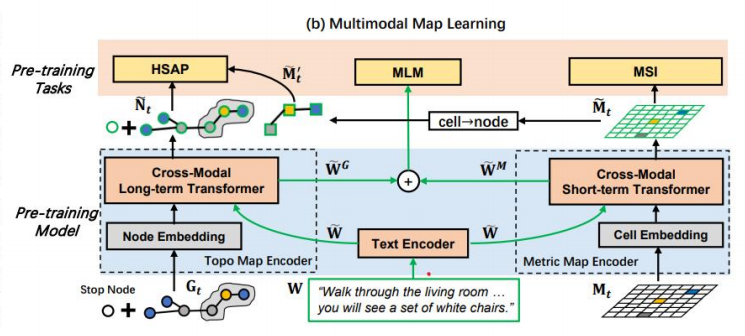
多模态地图学习(右图)
右图详细展示了 BEVBert 在多模态地图学习方面的机制,特别是如何通过结合视觉、文本和拓扑信息来提升模型的表现。它主要包括以下几个方面:
预训练任务:
- HSAP(Hierarchical Spatial Attention Prediction):预测空间注意力层次结构。
- MLM(Masked Language Modeling):掩码语言模型任务,用于增强语言理解能力。
- MSI(Multi-Scale Integration):多尺度集成,融合不同尺度的信息。
预训练模型架构:
- 跨模态长时Transformer:处理长时间序列的跨模态信息,包括节点嵌入、文本嵌入和单元格嵌入。
- 跨模态短时Transformer:处理短时间序列的跨模态信息。
- 节点嵌入、拓扑地图编码器、文本编码器 和 度量地图编码器 分别负责处理不同的输入模态。
具体操作流程:
- 通过文本编码器处理导航指令(例如:“穿过客厅……你会看到一套白色的椅子。”)
- 通过度量地图编码器处理度量地图信息。
- 通过拓扑地图编码器处理拓扑图信息。
- 最终通过跨模态Transformer进行联合编码和推理。
BEVBert的核心预训练目标





微调:模仿学习+强化学习

预训练、模仿学习与强化学习的协同作用
“预训练 → 模仿学习 → 强化学习”这一三步走的训练流程,在LLM-only方法普及之前,已经
成为VLN领域最主流、最高效的训练策略之一。这三个阶段环环相扣,协同作用,各自解决了
其他阶段的固有短板

