HTTP请求方法:GET与POST的深度解析
http 首行的方法
描述了这次请求,想干啥
GET : 从服务器拿一个东西过来(读操作)
POST :往服务器放一个东西过去(写操作)
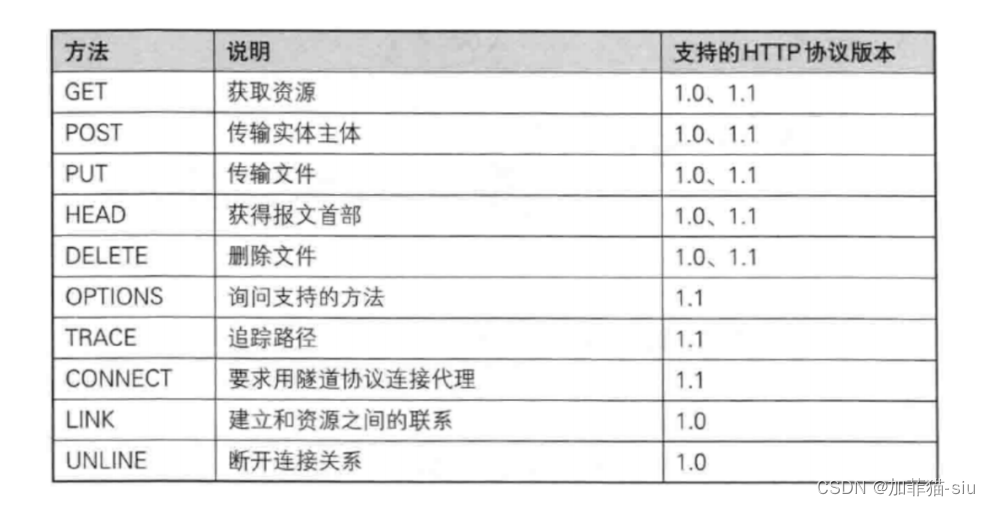
在实际开发中,完全可以用 POST 从服务器拿数据,也可以用 GET 往服务器放数据,完全可以不按说明来

POST 经常使用的场景
1.登录
2.上传
我们可以在登录后抓包到这个信息
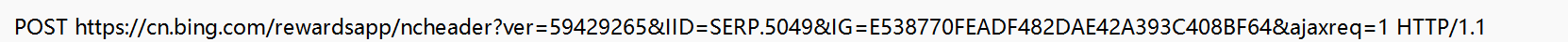
GET 通常没有body,POST 通常由 body
GET 会把需要给服务器补充信息放到 querystring 中(url中)
POST 会把这些信息放到 body 中


一些不太准确的观点
1.POST 比 GET 更安全
论据:登录的时候,如果使用 GET,用户名密码就会显示在 url 上,此时就会被别人直接看到,所以就不安全
即使是 POST,数据没有显示在 URL,也是可以通过抓包获取到的
真正保证安全性关键在于加密
2.GET 传输的数据量小(存在上限),POST 传输的数据量更大
实际上 HTTP 标准文档上说了,对于 GET URL 的长度不做限制
3.GET 只能携带文本数据,POST 则可以携带二进制数据
URL 通过 query string 来携带数据
query string 是只能包含文本的,但是可以对二进制数据进行 urlencode,自然成了文本了
到了服务器自然进行 urldecode,就能把数据还原成二进制
POSt 请求 body 中也经常不是携带二进制,有很多时候是对二进制进行 urlencode / base64 等方式进行转码
HOST
表示服务器主机的地址和端口

URL 已经有 HOST 了
这里的 HOST 和 URL 中的 ip 地址 端口 绝大部分情况下都是一样的
和 body 密切相关,如果这个数据包,没有 body,也就不会有这两个字段


Content-Type: text/html
正常来说,响应都得有 Content-Type,只要有 body
实际上如果响应确实没有 Content-Type,也没有 body,这个时候,有些浏览器也能自己猜一猜
浏览器容错能力很强,即使返回的数据有问题,也尽可能正确显示出来
Content-Type: text/html; charset=utf-8
后面写的服务器程序返回网页,发现乱码,就可以检查一下是否这里的编码方式没有设置或者设置的有问题

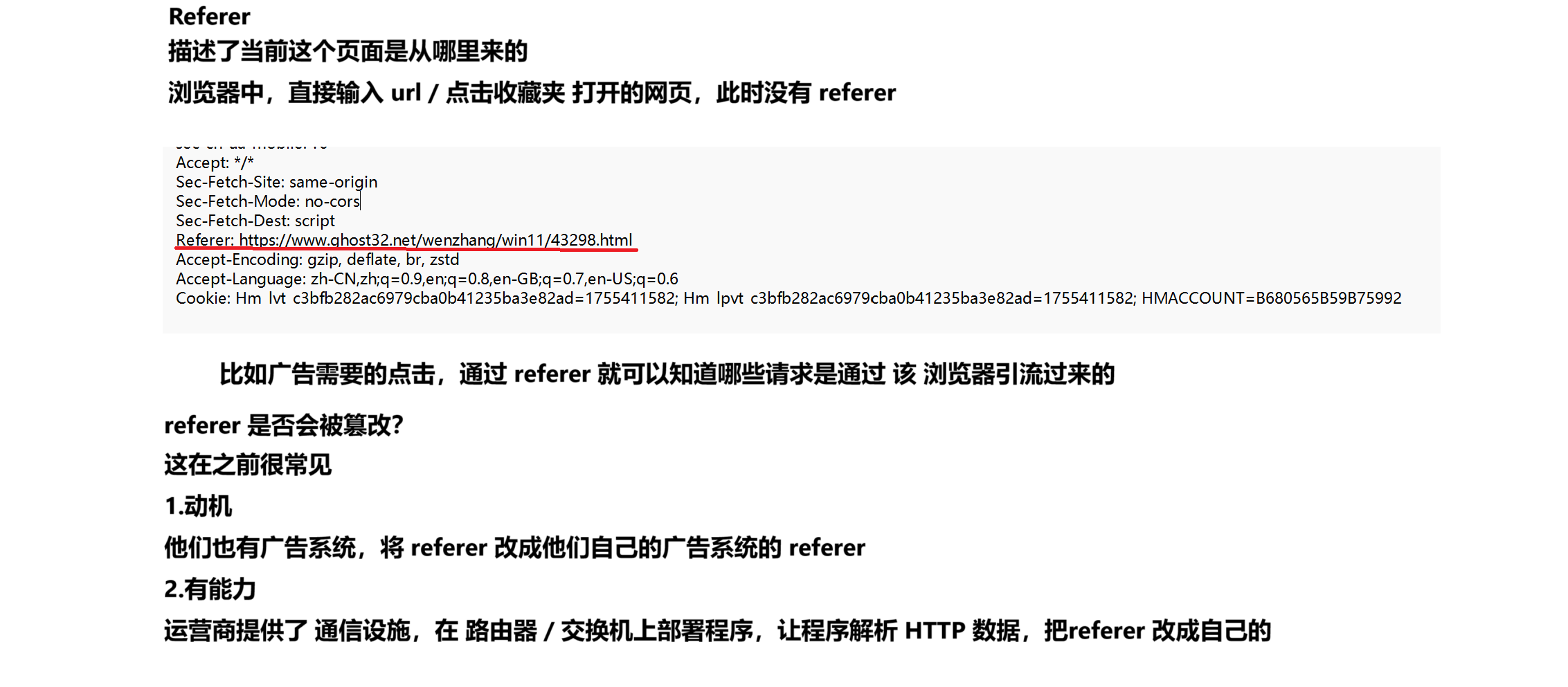

Cookie
Cookie 本质上是一个,浏览器这边本地持久化存储数据的机制
浏览器作为一个程序可以调用 api 来读写本地磁盘文件
浏览器上运行的网页,能否通过浏览器提供的 api 来读写本地磁盘文件呢?
浏览器禁止禁止了这种方法(浏览器没有给 网页提供这样的 api)
一个网页不能直接读写 我们自己的硬盘文件
浏览器给网页提供这样的 API,能够有限度的存储数据(按照键值对的格式),而不能随意的访问文件系统


就诊卡本身就是客户端手里拿着的持久化存储数据的机制,就是 cookie
关于 cookie 几个重要结论
1.Cookie 从哪里来?服务器返回给浏览器的,通常都是首次访问 / 登录成功之后
2.Cookie 到哪里去?Cookie 会存储在浏览器本地主机的硬盘上,后续每次访问都会带上 Cookie
不同客户端,保存的 Cookie 是不同的,即使是同一个主机,使用不同的浏览器,Cookie 大概率不同
3.Cookie 中存什么?键值对格式的数据,这里的内容都是程序员自定义的,和 query string 一样

不同网站的 Cookie 都是不一样的
4.Cookie 在浏览器这边如何组织?
在硬盘本地保存,是按照不同的域名为维度分别存储
5.Cookie 的用途是什么?
用来在客户端保存数据
最为主要的是保存用户的身份标识,服务器就可以通过标识来区分用户了
一些其他的业务数据一般不会存储在 cookie中
cookie 随时可以删除掉,把业务数据存储在服务器,通过 cookie 中的身份标识找到对应的数据
浏览器的另一个保存机制,一般账号密码不会在 cookie 中保存,cookie 是要传输给服务器的
一般浏览器保存的密码都是明文密码,明文密码放到 cookie 是不合适
虽然 https 能加密,https 侧重于是“不能被篡改”,而不是“不能被解密”
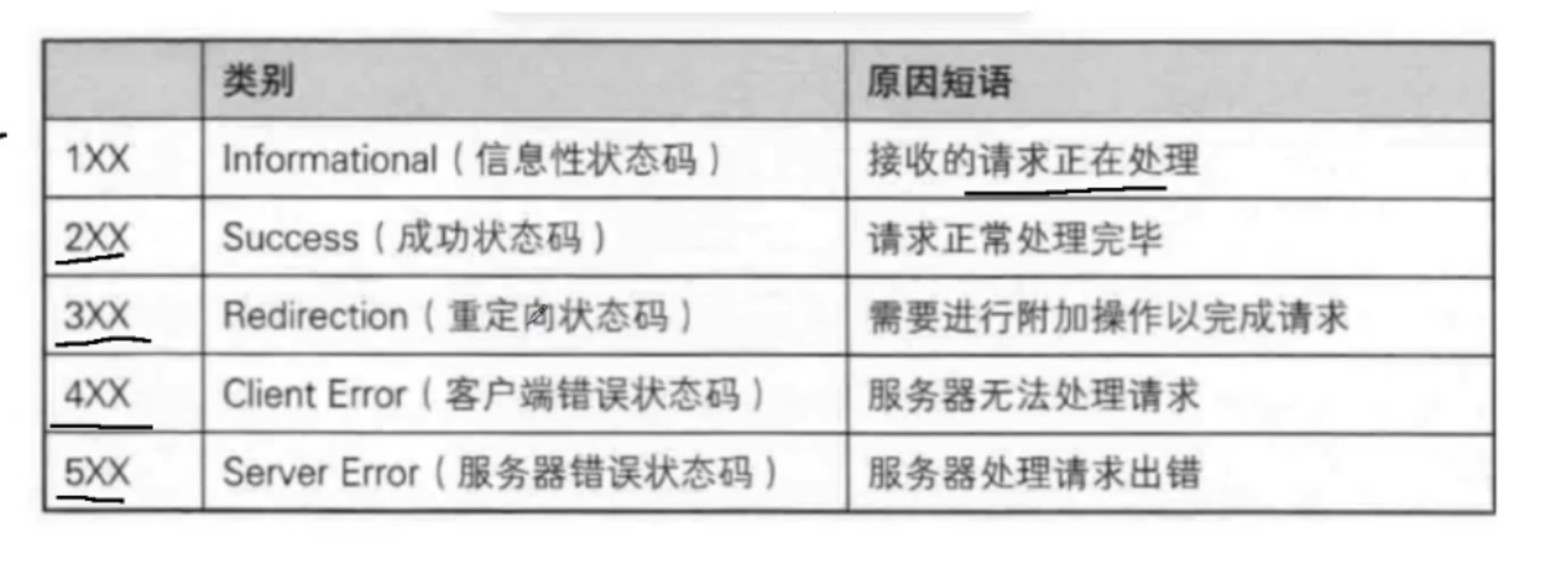
状态码
用于响应中的,表示响应的结果如何
1.200 OK
2.404 NOT Found 访问的资源没找到(url 中的路径)
3.403 Forbidden
请求的资源没有权限访问
4.405

你的服务器只支持 GET 请求,但是你只发了个 POST
5. 500 Internal Server Error
服务器内部错误了
6.504 Gateway Timeout
访问服务器超时了
可能是服务器挂了,也可能是网挂了
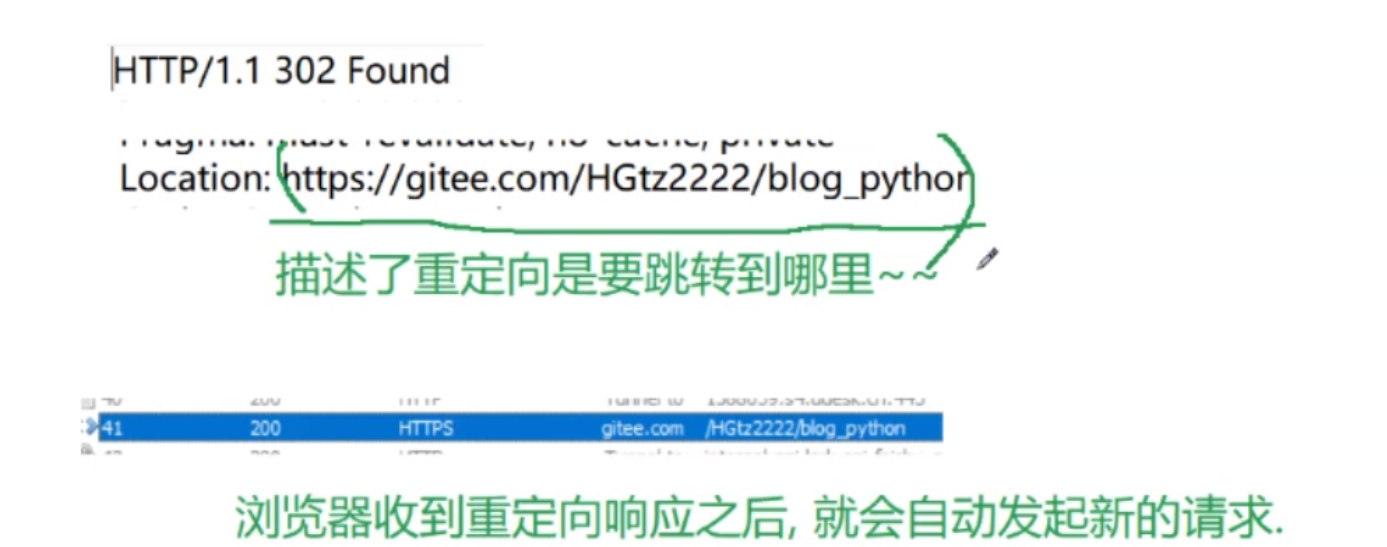
7.302 Move temporarily 重定向(临时重定向)
明明访问的是网站 A,A就会让浏览器帮你跳转到 B
状态码,还有一个 特殊了,418
418 在 HTTP 协议的标准文档是存在的(但是没有实际意义)
如何构造出 HTTP 请求
1.通过代码构造
任何一种编程语言,只要能够操作网络,都可以构造 HTTP 请求
对于 Java 来说,需要使用 ServerSocket / Socket (Tcp 的 socket api 来编程)
本质上就是基于 Socket 写一个 TCP 客户端,然后往 socket 中按照 HTTP 协议的格式写入字符串即可
OkHttpClient(比较知名的 Java 的 HTTP 客户端库)
2.通过第三方工具构造
构造 HTTP 请求的第三方工具
postman
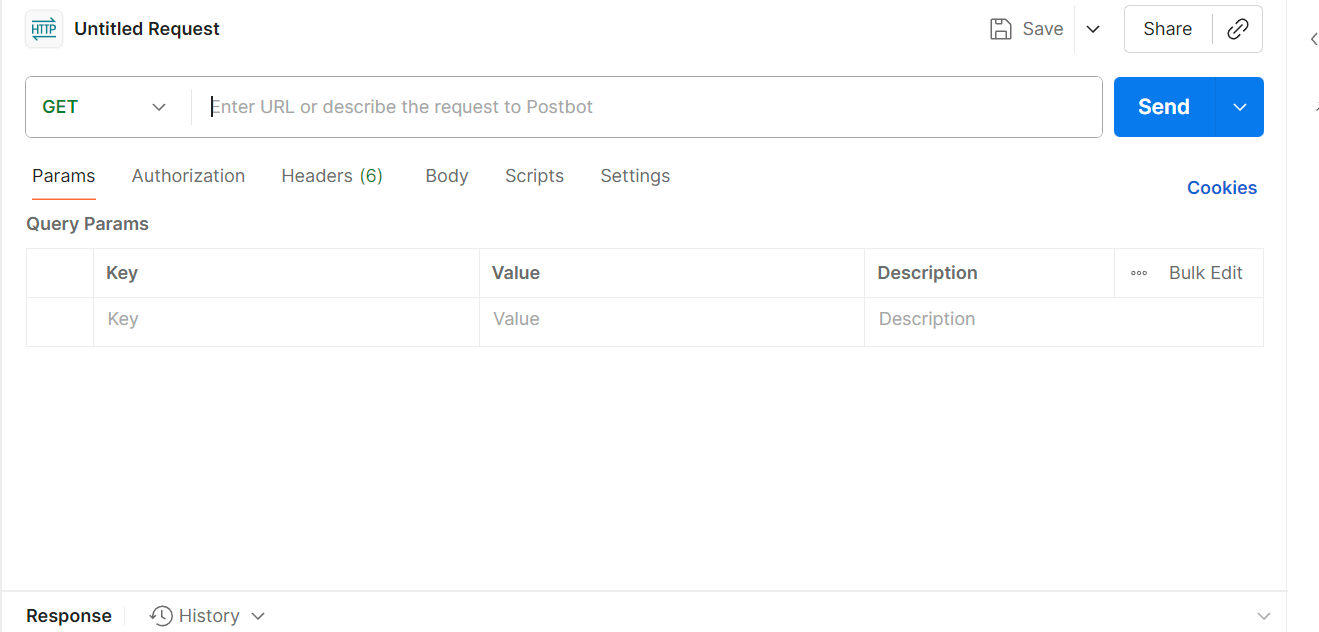
可以填写一些属性,通过send就可以发送请求到目标服务器了
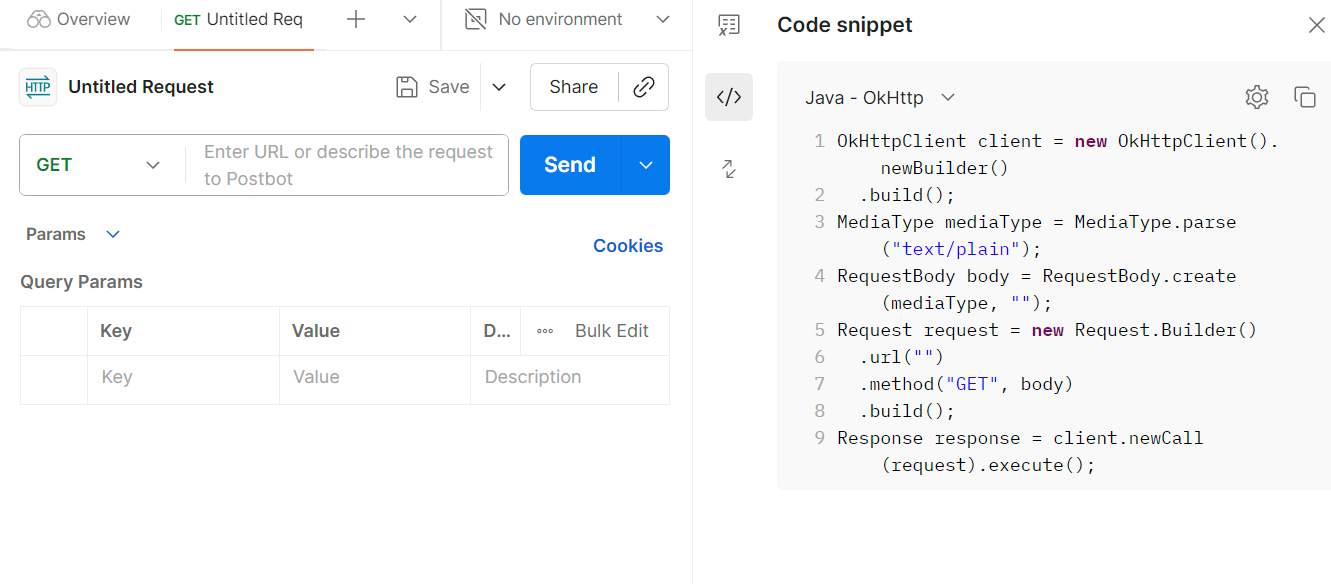
还可以找到相应语言的代码
网页中构造 HTTP 请求
需要通过 HTML / JS 来构造 HTTP 请求了
比较经典的方式
1.form 表单
2.ajax
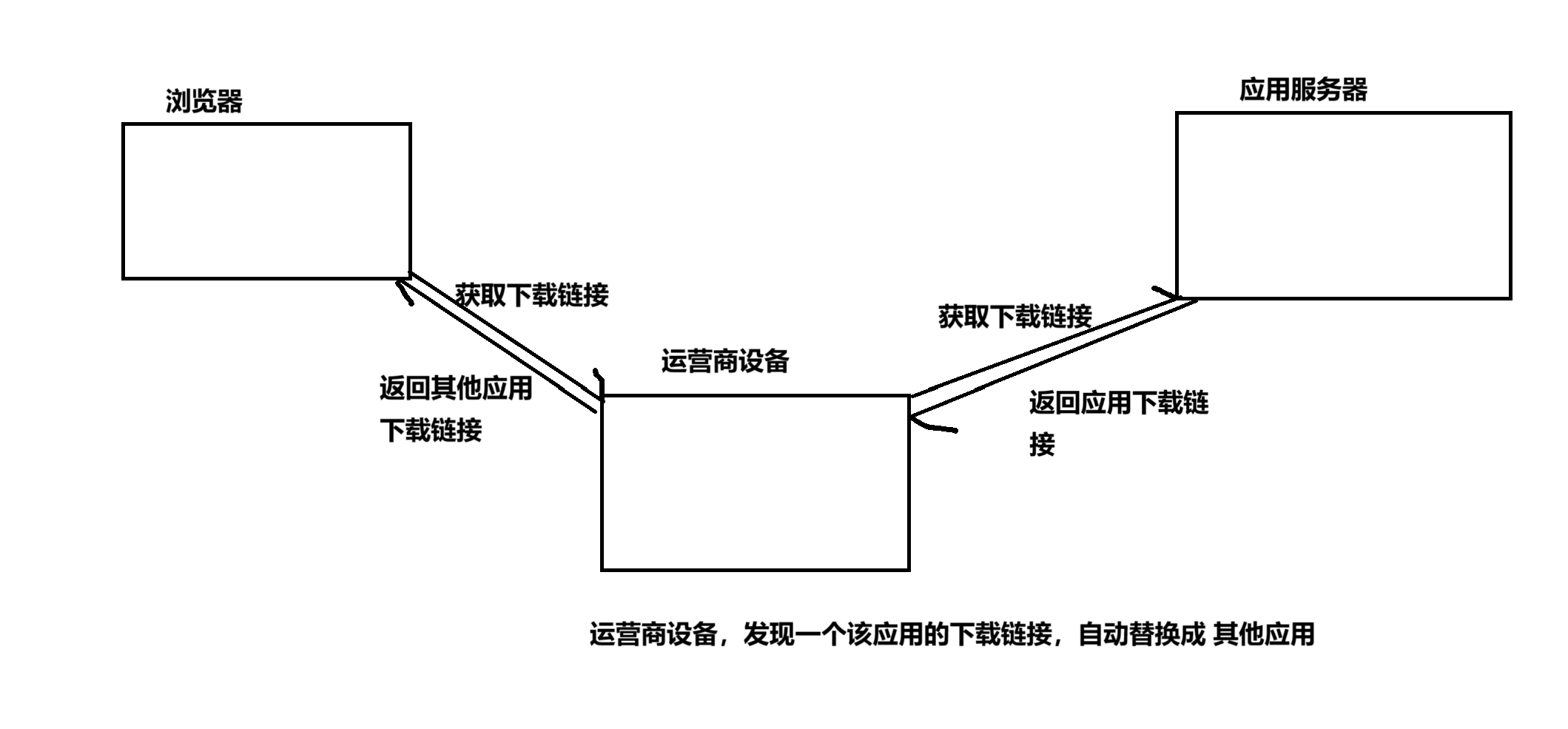
解决安全问题,最核心的要点,就是“加密”
引入加密是保证数据安全的有效手段
这样破解的成本就很高,加密的成本很低,破解的成本很高
HTTPS 工作过程
只要针对 HTTPS 的数据进行解密了,就能得到 HTTP 格式的数据
上述的运营商劫持,无论是修改 referer 还是修改返回的 链接(body),本质上都是 明文传输惹的祸
需要引入加密,对上述传输的数据进行保护
主要就是要针对 header 和 body 进行加密
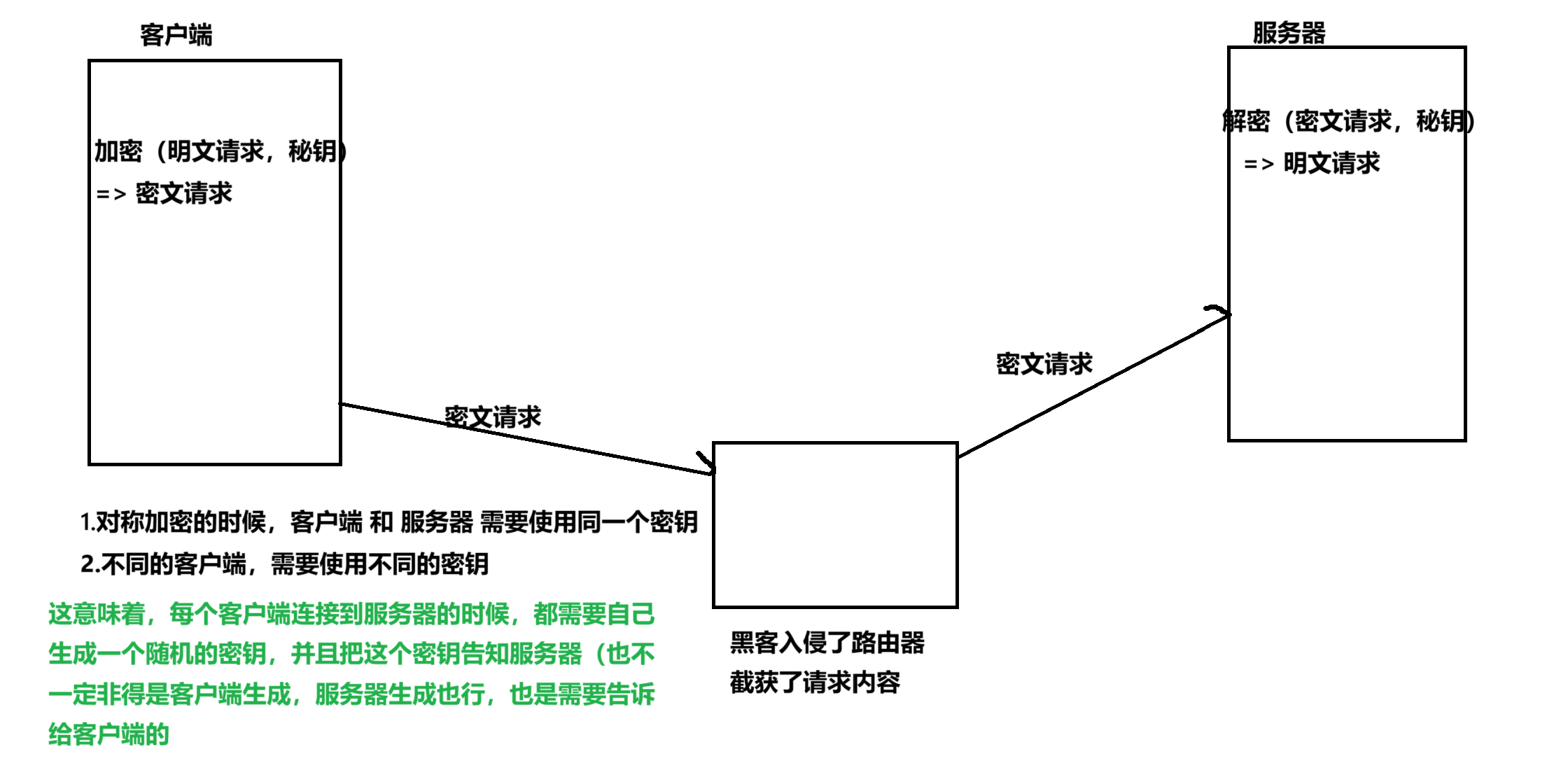
1.引入对称加密
通过对称加密的方式,针对传输的数据进行加密操作
2.引入非对称加密
使用非对称加密,主要目的就是为了对称密钥进行加密,确保对称密钥的安全性
不能使用非对称加密,针对后续传输的各种, header body 等进行加密,而是只能使用非对称加密去加密对称密钥
非对称加密的加密解密成本(消耗的 CPU 资源)要远远高于对称加密
如果大规模使用,就难以承担了
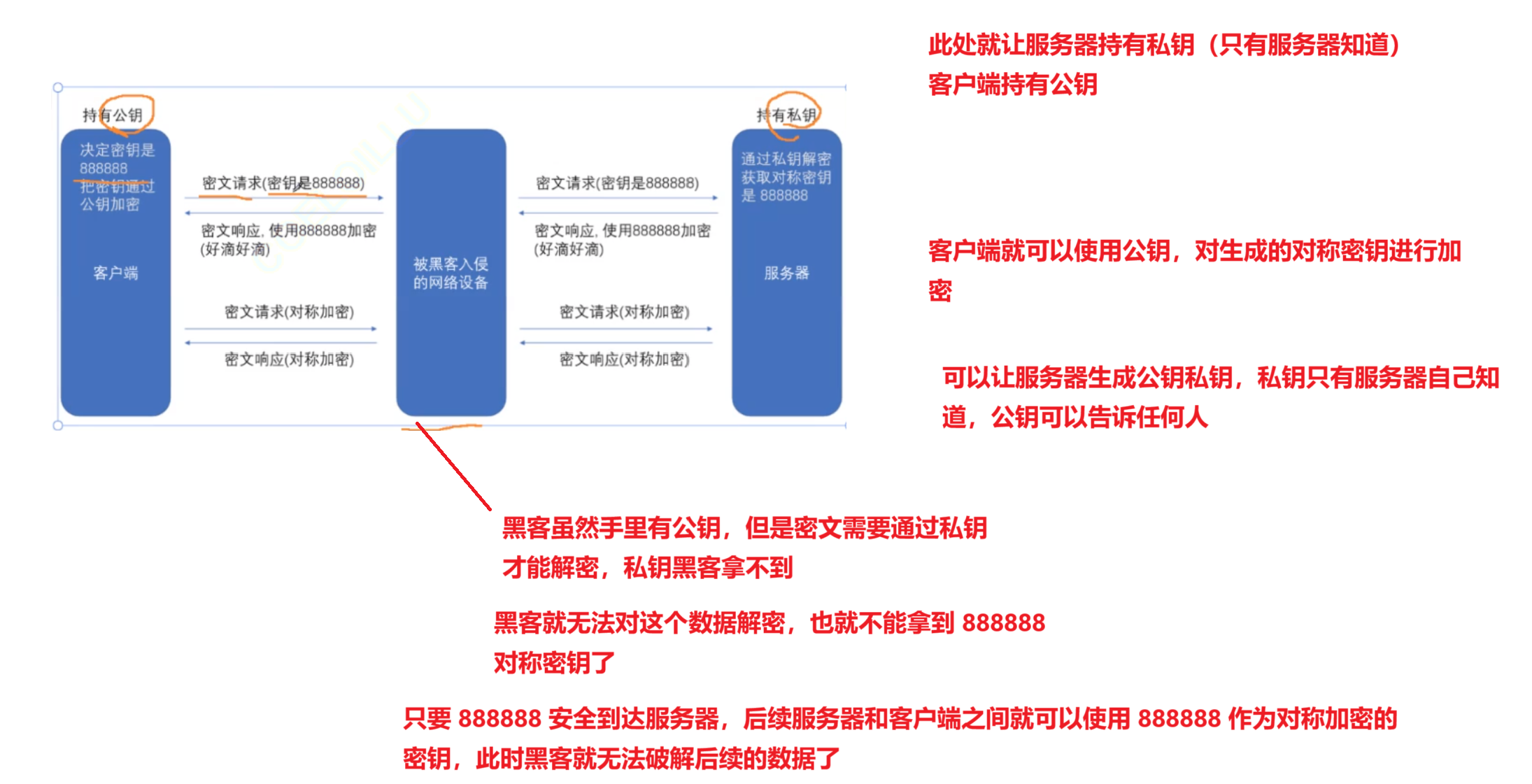
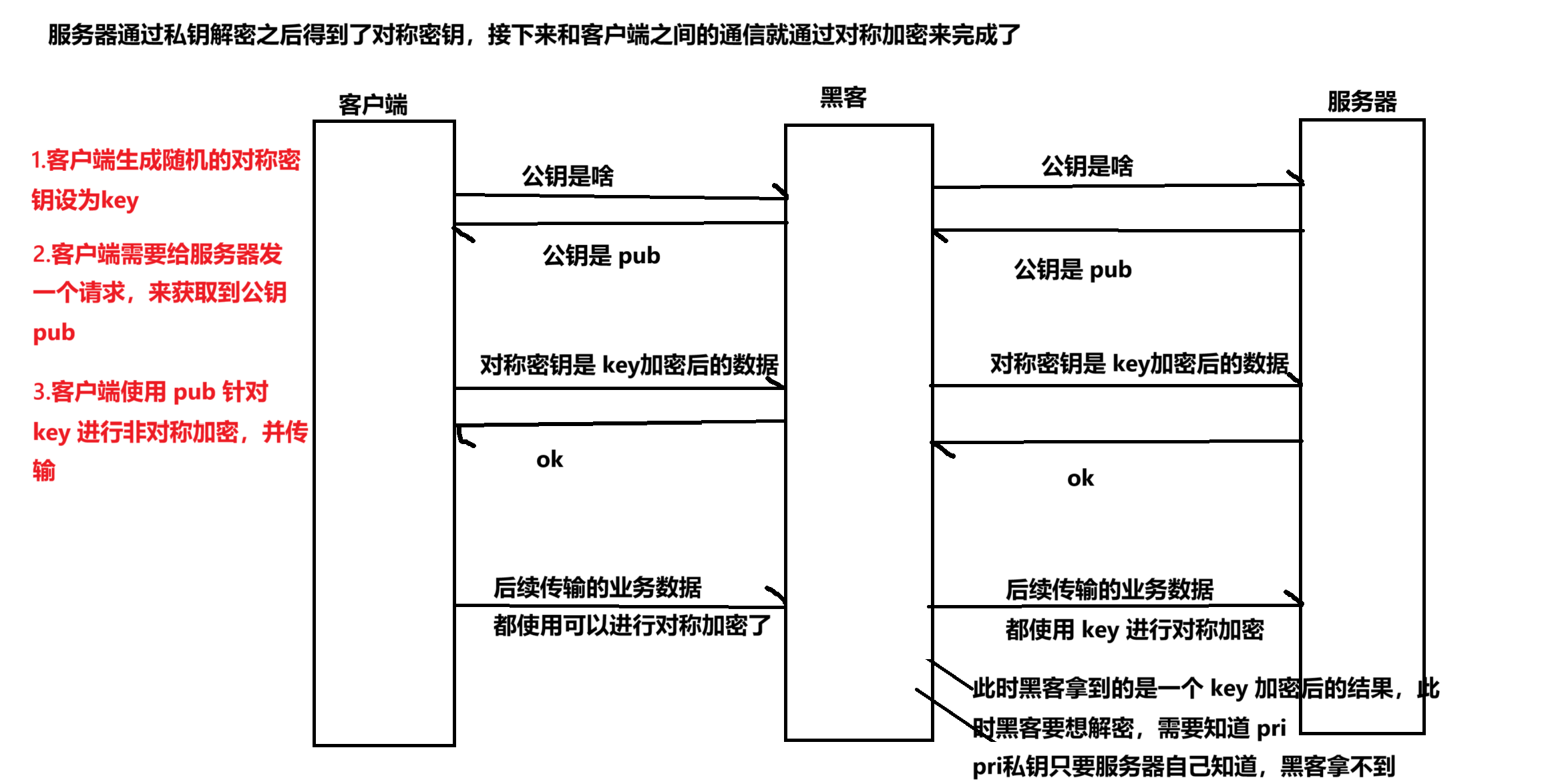
SSL 内部完成工作,使用 HTTPS 的时候,底层也是 TCP,先进行 TCP 三次握手,TCP 连接打通之后,就要进行 SSL 的握手了(交换密钥的过程)
后面才是真正传输业务数据(完成的 HTTPS 的请求/ 响应)
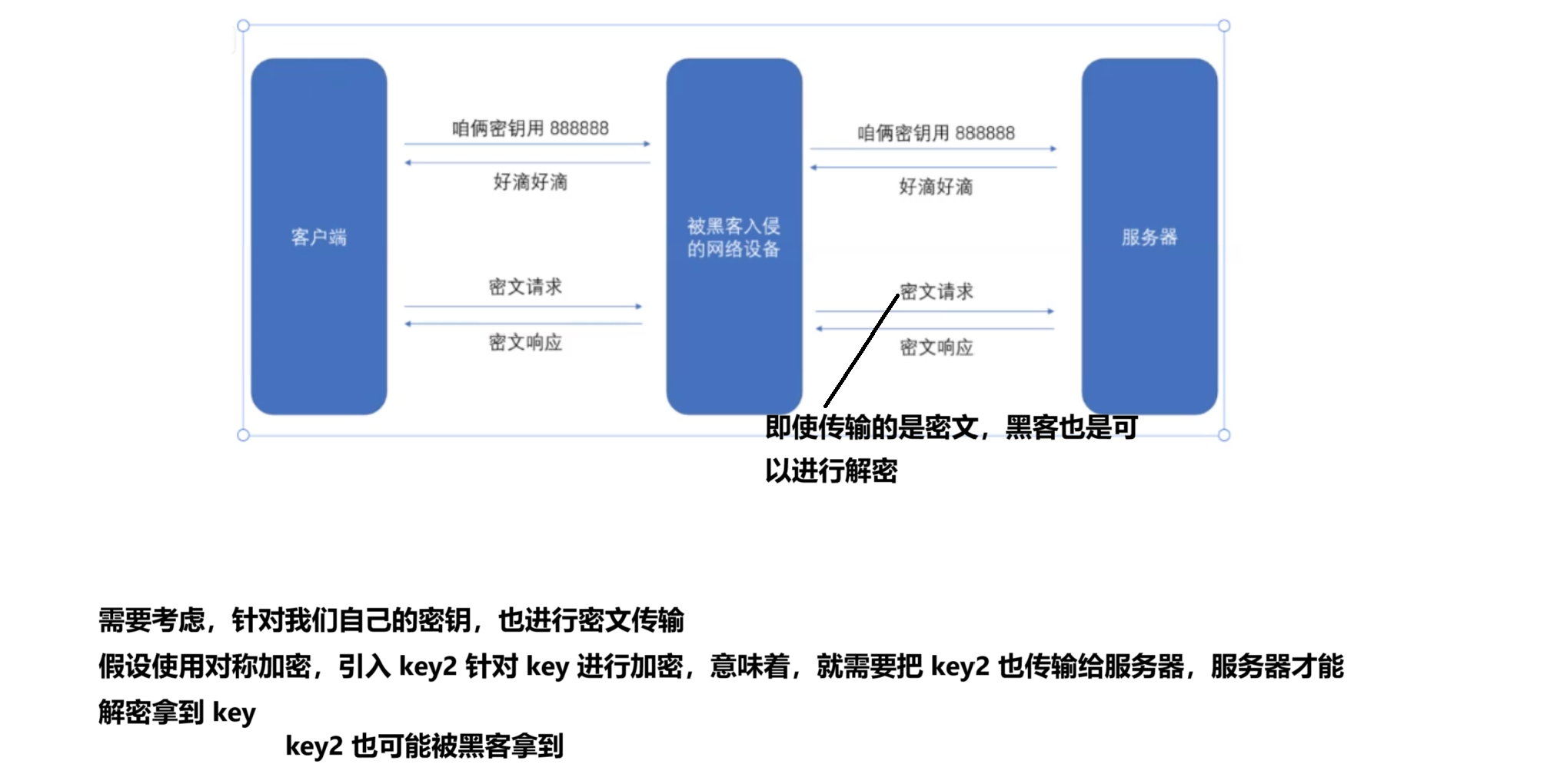
上述操作下,仍然存在重要的安全漏洞,黑客仍然是有办法获取到对称密钥 key的
服务器可以创建出一对公钥 和 私钥,黑客,也可以按照同样的方式,创建出一对 公钥 和 私钥冒充自己是服务器
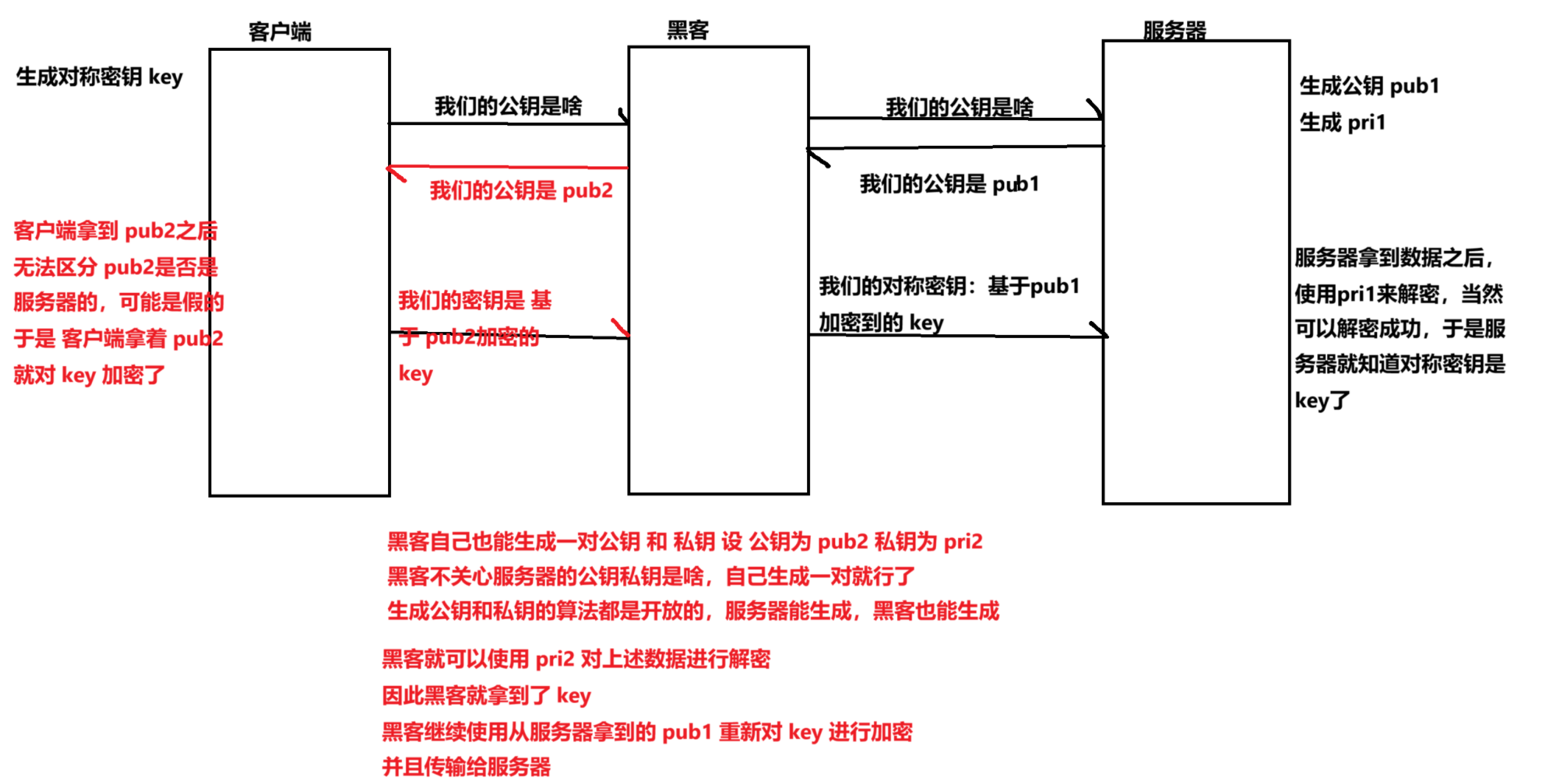
针对上述问题,如何解决?
最关键的一点,客户端拿到公钥的时候,要能有办法验证,这个公钥是否是真的,而不是黑客伪造的
要求服务器这边要提供一个“证书”
证书是一个结构化的数据(里面包含很多属性,最终以字符串的形式提供)
证书中会包含一系列的信息
比如,服务器的主域名,公钥,证书有效期
证书是搭建服务器的人,要从第三方的公正机构进行申请的
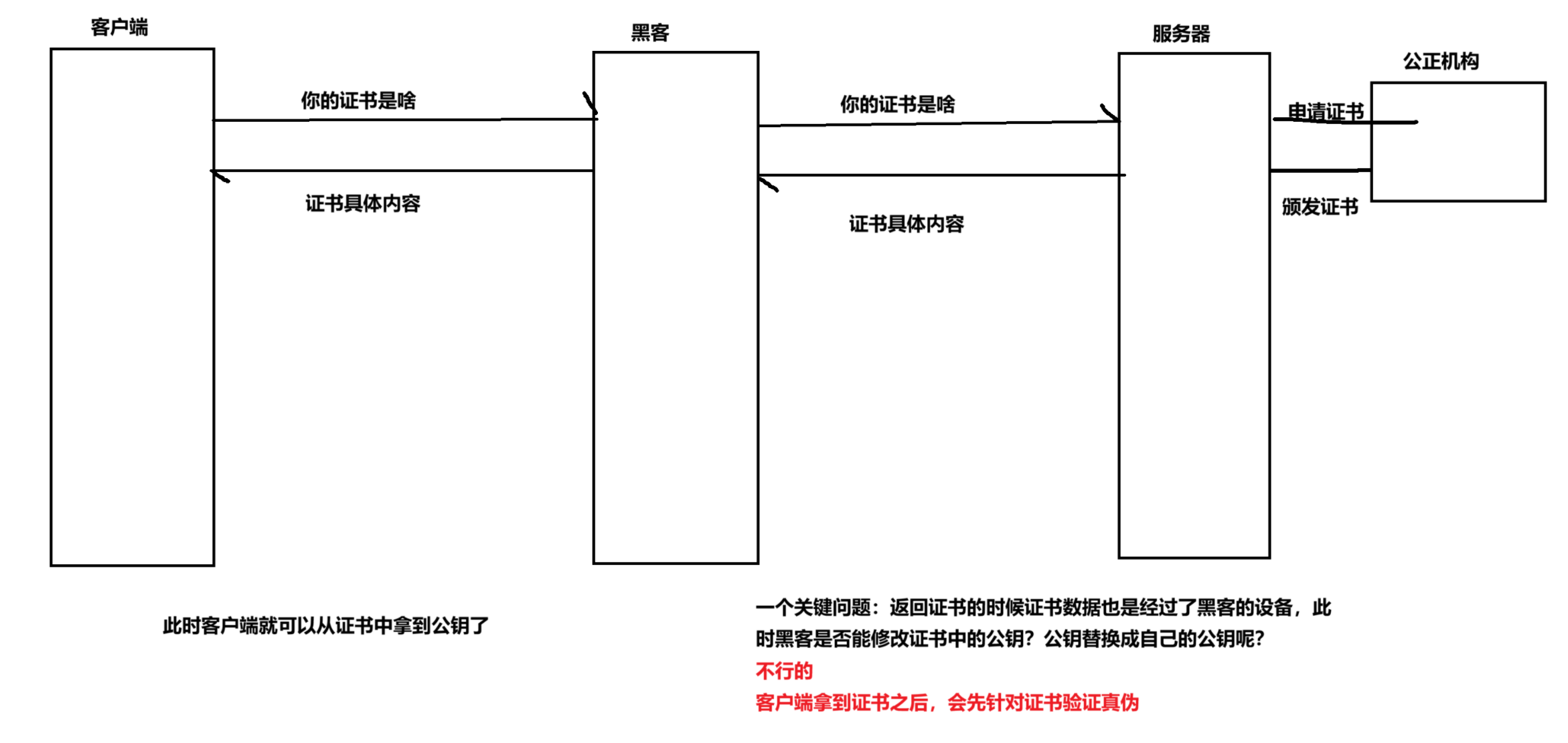
证书验证的过程
证书:
服务器的域名:
证书的有效时间:
服务器的公钥:
公正机构的信息:
。。。。。
证书的签名:
此处所谓的“签名”,本质上是一个经过加密的校验和
把证书中其他的字段通过一系列的算法(CRC,MD5等),得到一个较短的字符串 => 校验和
如果两份数据内容一样,此时校验和,就一定是相同的
如果校验和不同,两份数据的内容则一定不同
客户端拿到证书之后,主要做两件事:
1.按照同样的校验和算法,把证书的其他字段都重新算一遍,得到 校验和1
2.使用系统中内置的公正机构公钥,对证书中的签名进行解密,得到校验和2
此时,就可以对比,看这俩校验和是否一致
如果一致,说明证书是没有被修改过的,就是原版证书
如果不一致,说明证书被别人篡改过了,此时客户端就能识别出来了