【AI论文】序曲(PRELUDE):一项旨在考察对长文本语境进行全局理解与推理能力的基准测试
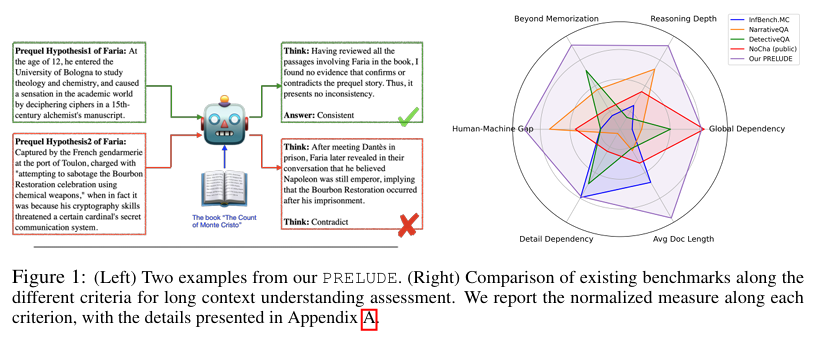
摘要:我们推出了一项名为PRELUDE的基准测试,该测试通过判断某角色前传故事是否与原著正传的经典叙事一致这一任务,来评估对长文本语境的理解能力。与现有基准测试相比,我们的任务对全局理解和深度推理提出了更高要求——由于前传并非原著故事的一部分,评估其合理性通常需要搜索并整合仅间接相关的信息。经验性研究表明,88%的案例需要从叙事的不同部分提取证据。实验结果表明,我们的任务颇具挑战性:利用最先进大语言模型(LLMs)进行的情境学习、检索增强生成(RAG)和领域内训练,以及商业DeepResearch服务,其表现均落后人类15%以上。进一步的人为研究揭示,模型常常在推理有误的情况下给出正确答案,与人类相比,推理准确率差距超过30%。这些发现凸显了在长文本语境理解和推理方面仍有巨大的改进空间。Huggingface链接:Paper page,论文链接:2508.09848
一、研究背景和目的
研究背景
随着大型语言模型(LLMs)在多文档分析、个人助手聊天历史记录管理、自主代理以及代码仓库级编码工具等领域的广泛应用,对长文本语境的稳健理解和推理能力提出了越来越高的要求。尽管已有多种技术被提出来支持长文本输入,如高效注意力机制和检索增强生成(RAG),但如何有效评估长文本语境理解和推理能力仍然是一个挑战。现有的基准测试在评估全局理解、深度推理以及避免记忆化等方面存在局限性,难以全面反映模型在长文本语境下的真实能力。
研究目的
本研究旨在通过引入一项新的基准测试——PRELUDE,来解决上述问题。PRELUDE旨在评估模型在长文本语境下的全局理解和推理能力,具体任务是判断某角色前传故事是否与原著正传的经典叙事一致。与现有基准测试相比,PRELUDE对全局理解和深度推理提出了更高要求,因为它要求模型不仅理解原著故事的内容,还要能够判断前传故事是否与原著的叙事逻辑和设定相吻合。这一任务设计有助于揭示模型在长文本语境理解和推理方面的真实能力,推动相关研究的深入发展。
二、研究方法
1. 基准测试设计
PRELUDE基准测试通过以下步骤构建:
- 任务定义:判断某角色前传故事是否与原著正传的经典叙事一致。
- 数据集构建:从多部经典文学作品中选择重要配角,生成其前传故事,并由人类专家进行标注,判断前传故事是否与原著一致。标注过程遵循严格的标准,确保标注质量。
- 标签定义:定义了五种标签类型,包括直接矛盾(Contradict-Local)、全局矛盾I(Contradict-Global I)、全局矛盾II(Contradict-Global II)、无关一致(Consistent-Irrelevant)和核心一致(Consistent-Core),以细化标注结果。
2. 模型评估
为了全面评估模型在PRELUDE基准测试上的表现,研究采用了以下几种方法:
- 少样本情境学习(Few-Shot In-Context Learning, ICL):在不提供原著上下文的情况下,仅通过少量示例来评估模型的内在参数知识。
- 检索增强生成(RAG):允许模型访问原著文本,通过检索相关信息来辅助判断。
- 领域内微调(In-Domain Training):在标注数据集上进行微调,以激发模型的特定能力。
- 多样本情境学习(Many-Shot ICL):在输入上下文中提供大量示例,以激发模型的潜在能力。
3. 人类基线评估
为了比较模型与人类的表现,研究还邀请了未参与标注的人类受试者对部分样本进行判断,并计算了人类的准确率和推理准确率。
三、研究结果
1. 模型表现
实验结果表明,即使是最先进的LLMs在PRELUDE基准测试上的表现也显著落后于人类:
- 少样本情境学习:模型在不提供原著上下文的情况下,表现普遍较差,准确率远低于人类。
- 检索增强生成(RAG):虽然RAG提高了模型在部分类别上的表现,但整体准确率仍低于人类,且存在过度拒绝(over-rejection)现象。
- 领域内微调和多样本情境学习:这两种方法并未显著提高模型的表现,表明模型在长文本语境理解和推理方面仍存在根本性局限。
2. 人类与模型对比
- 准确率对比:人类在PRELUDE基准测试上的准确率达到81.7%,而最佳模型表现仅为66.7%,落后超过15%。
- 推理准确率对比:进一步分析发现,模型在给出正确答案时,推理过程往往存在缺陷,导致推理准确率与人类相比存在超过30%的差距。
3. 案例分析
通过具体案例分析,研究发现模型在处理长文本语境时存在以下问题:
- 依赖局部信息:模型往往仅根据局部信息做出判断,忽视了全局依赖关系。
- 浅层推理:模型倾向于进行浅层推理,如分解或枚举事实,而非多步深度推理。
- 记忆化倾向:模型可能依赖于训练数据中的记忆化知识,而非真正理解长文本语境。
四、研究局限
尽管PRELUDE基准测试在评估长文本语境理解和推理能力方面具有显著优势,但仍存在以下局限:
1. 主观性和一致性
由于文学叙事的复杂性和主观性,人类标注者在某些案例上可能存在分歧,导致标注结果的不一致性。尽管研究通过严格的标注流程和规则尽量减少了这种不一致性,但仍无法完全避免。
2. 数据集规模和多样性
尽管PRELUDE基准测试包含了来自多部经典文学作品的重要配角前传故事,但数据集规模和多样性仍有限。未来研究可以进一步扩大数据集规模,增加更多类型的文学作品和角色,以提高基准测试的普适性和挑战性。
3. 模型评估的局限性
本研究主要评估了现有LLMs在PRELUDE基准测试上的表现,但未深入探讨模型表现不佳的根本原因。未来研究可以进一步分析模型在处理长文本语境时的具体困难,如注意力机制、记忆能力等方面的局限。
五、未来研究方向
1. 改进模型架构和训练策略
针对模型在长文本语境理解和推理方面的局限,未来研究可以探索更先进的模型架构和训练策略。例如,可以设计专门用于处理长文本语境的注意力机制,或采用多任务学习、对比学习等方法来提高模型的全局理解和推理能力。
2. 扩大数据集规模和多样性
为了进一步提高基准测试的普适性和挑战性,未来研究可以扩大数据集规模,增加更多类型的文学作品和角色。同时,可以考虑引入其他类型的长文本数据,如新闻报道、历史文献等,以丰富基准测试的内容。
3. 深入分析模型表现
未来研究可以进一步分析模型在处理长文本语境时的具体表现,揭示模型表现不佳的根本原因。例如,可以通过可视化工具分析模型的注意力分布,或采用解释性AI技术来揭示模型的决策过程。
4. 探索跨语言和跨文化评估
目前PRELUDE基准测试主要基于英文和中文文学作品,未来研究可以探索跨语言和跨文化的评估方法。通过引入不同语言和文化的文学作品,可以评估模型在不同语境下的理解和推理能力,推动跨语言和跨文化AI研究的发展。
5. 结合其他评估方法
除了PRELUDE基准测试外,未来研究还可以结合其他评估方法来全面评估模型的长文本语境理解和推理能力。例如,可以结合用户研究、眼动追踪等方法来评估模型在实际应用中的表现,或采用对抗性测试来揭示模型的鲁棒性问题。
总之,PRELUDE基准测试为评估长文本语境理解和推理能力提供了一个有效的平台。未来研究可以在此基础上进一步探索模型改进、数据集扩大、表现分析以及跨语言和跨文化评估等方向,推动相关研究的深入发展。