Leetcode 15 java
今天复习一下翻转二叉树
226. 翻转二叉树
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
示例 1:
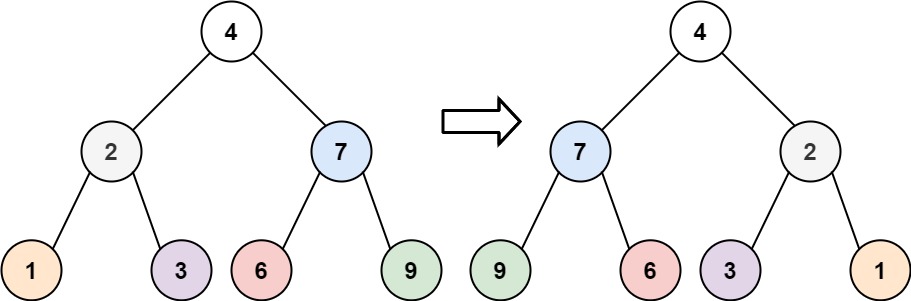
输入:root = [4,2,7,1,3,6,9] 输出:[4,7,2,9,6,3,1]
示例 2:
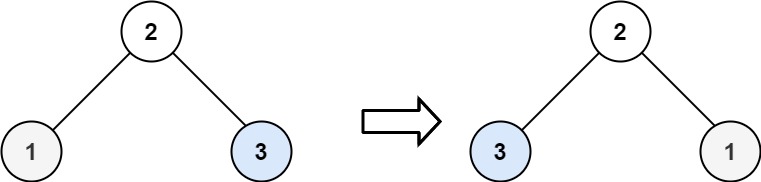
输入:root = [2,1,3] 输出:[2,3,1]
示例 3:
输入:root = [] 输出:[]
提示:
- 树中节点数目范围在
[0, 100]内 -100 <= Node.val <= 100
1 我的想法以及分析
翻转以后的二叉树对于每一个子节点来说就是左右互换了。
但是我不知道具体要怎么实现这个,而且返回的root是有顺序的,不知道怎么弄啊。
借鉴了一下题解,要用递归,那么。。算了一点看不懂,找一下以前写的博客。
好难啊不知道这个递归什么鬼,也没有个while for循环的,结束条件在哪里?也没把判断null放里头啊。
我是猪。
2 解析
别慌!递归看起来 “没有循环”,其实是把循环的逻辑交给了函数自身调用,咱们一步步拆解,保证能懂。
一、核心思路:为什么是 “左右互换”?
翻转二叉树的本质,是对每一个节点,交换它的左子树和右子树。
- 比如示例 1 中的根节点
4,要交换它的左子树(以2为根)和右子树(以7为根); - 接着处理
2这个节点,交换它的左子树(1)和右子树(3); - 再处理
7这个节点,交换它的左子树(6)和右子树(9); - 直到遇到 “空节点”(没有子树可交换),就停止。
二、递归怎么写?3 步理清逻辑
递归的核心是 “明确函数做什么、终止条件是什么、子问题怎么拆”,咱们对应到这道题:
1. 明确函数功能
定义函数invertTree(root):
- 输入:一个节点
root(可能是根,也可能是子树的根); - 输出:翻转该节点所在子树后,新的根节点(其实就是原
root,因为只是交换子树,根不变)。
2. 终止条件(“什么时候停”)
当root是null时(比如叶子节点的左 / 右子树,或者空树),没有子树可交换,直接返回null即可。
这就是递归的 “出口”,避免无限调用。
3. 子问题拆解(“当前节点要做什么”)
对一个非空节点root,只需要 3 步:
- 暂存左子树:因为交换后会覆盖左子树,先把
root.left存起来(比如叫leftTemp); - 交换左右子树:
- 把
root的左子树,改成 “翻转后的右子树”(即调用invertTree(root.right)); - 把
root的右子树,改成 “翻转后的左子树”(即调用invertTree(leftTemp));
- 把
- 返回当前节点
root(它的子树已经翻转完成)。
三、代码实现(Java 示例)
java
运行
// 二叉树节点定义
class TreeNode {int val;TreeNode left;TreeNode right;TreeNode() {}TreeNode(int val) { this.val = val; }TreeNode(int val, TreeNode left, TreeNode right) {this.val = val;this.left = left;this.right = right;}
}class Solution {public TreeNode invertTree(TreeNode root) {// 终止条件:遇到空节点,直接返回nullif (root == null) {return null;}// 1. 暂存左子树(避免交换时被覆盖)TreeNode leftTemp = root.left;// 2. 交换:左子树 = 翻转后的右子树,右子树 = 翻转后的左子树root.left = invertTree(root.right);root.right = invertTree(leftTemp);// 3. 返回当前节点(子树已翻转)return root;}
}
四、用示例 1 验证流程(帮你 “看见” 递归)
输入:root = [4,2,7,1,3,6,9](结构如下)
plaintext
4/ \2 7/ \ / \
1 3 6 9
递归执行步骤(简化):
- 处理
4:暂存左子树2,调用invertTree(7)(先翻转右子树)、invertTree(2)(再翻转左子树); - 处理
7:暂存左子树6,调用invertTree(9)(返回9)、invertTree(6)(返回6),交换后7的左 = 9、右 = 6; - 处理
2:暂存左子树1,调用invertTree(3)(返回3)、invertTree(1)(返回1),交换后2的左 = 3、右 = 1; - 回到
4:交换后4的左 = 7(已翻转)、右 = 2(已翻转),最终返回4。
最终结果就是[4,7,2,9,6,3,1],和示例一致。
五、关键误区纠正!!!!!!!!!!!
- 不是 “没有循环”:递归的 “循环” 是通过函数调用实现的,每个节点都会被处理一次,终止条件
if (root == null)就是 “循环停止” 的信号; - 不用纠结 “返回顺序”:递归会自动处理所有子节点,我们只需要关注 “当前节点要交换左右子树”,剩下的交给子调用即可。
多拿几个简单例子(比如示例 2)走一遍流程,很快就能理解递归的 “自下而上” 处理逻辑啦!
3 自己重新理一遍
题目已给代码
/*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val = val; }* TreeNode(int val, TreeNode left, TreeNode right) {* this.val = val;* this.left = left;* this.right = right;* }* }*/
class Solution {public TreeNode invertTree(TreeNode root) {}
}if (root == null){
return null;
}
TreeNode left = invertTree(root.left);
//【我感觉有点像套娃?】
插播一条。
“套娃” 这个比喻特别精准!递归的核心逻辑其实就是 “套娃”,咱们可以顺着这个比喻再拆解一层,帮你彻底打通思路:
一、递归 = “拆解套娃” + “组装套娃”
翻转二叉树的递归过程,完全可以对应成处理一套嵌套的玩具:
- 目标:把一套 “二叉树套娃” 的每一层左右反过来(比如大娃里的中娃左右互换,中娃里的小娃也左右互换);
- 处理方式:
- 拿到一个娃(比如根节点
4),先不管它本身,先把它左手里的小套娃(左子树2)和右手里的小套娃(右子树7)拆下来; - 分别把这两个小套娃各自翻好(递归调用
invertTree(2)和invertTree(7),相当于把小套娃的内部全翻完); - 再把翻好的两个小套娃 “左右对调”,塞回大娃的手里;
- 拿到一个娃(比如根节点
- 终止:拆到最后发现是个 “空壳”(
root == null),没有小套娃可拆,直接停下来。
二、用 “套娃” 看示例 1 的执行
原套娃结构(从外到内):4(外层)→ 左手2、右手7 → 2的左手1、右手3;7的左手6、右手9。
-
先拆
4的右手7(先处理右子树):- 拆
7的右手9:9没有小套娃(左右都是null),翻完还是9,塞回7的左手; - 拆
7的左手6:6没有小套娃,翻完还是6,塞回7的右手; - 现在
7的左右反过来了(左手9、右手6),整体塞回4的左手;
- 拆
-
再拆
4原来的左手2:- 拆
2的右手3:翻完还是3,塞回2的左手; - 拆
2的左手1:翻完还是1,塞回2的右手; - 现在
2的左右反过来了(左手3、右手1),整体塞回4的右手;
- 拆
-
最后
4的左右(7和2)都翻好了,整个套娃就翻完了。
三、为什么 “套娃” 能 work?
因为翻转二叉树的每一层逻辑都完全相同—— 不管是外层的4,还是中间的2/7,甚至最内层的1/3,要做的事都是 “拆左右小套娃→翻小套娃→对调塞回去”。
递归之所以不用for/while,就是因为它把 “一层一层拆套娃” 的重复工作,交给了函数自己调用自己,而if (root == null)就是 “拆到最里面空壳” 的停止信号。
你能想到 “套娃” 这个比喻,其实已经抓住了递归的核心 ——重复处理相似的子问题,直到没有子问题可处理,接下来只要多走几遍简单案例,就能从 “感觉像” 变成 “完全懂” 啦!
TreeNode left = invertTree(root.left);
TreeNode right = invertTree (root.right);
root.left = right; root.right = left;
//这一段代码是按顺序执行的话,那么后面的root.left经一次调用的时候,第二次是不是这个root已经变了?
这个问题问到了递归执行顺序的关键 ——代码会先完整执行完前两行的递归调用,再执行后面的赋值操作,所以不存在 “后面调用时 root 已经变了” 的情况。咱们一步步拆解:
一、核心结论
这三行代码的执行顺序是 “先算完左右子树的翻转结果,再给当前 root 的左右赋值”,前两行的递归调用不会受后两行赋值的影响。
二、用 “执行步骤拆解” 看为什么
咱们把代码拆成 “计算结果” 和 “修改当前节点” 两个阶段,对应到具体执行:
阶段 1:计算 “翻转后的左右子树”(前两行代码)
java
运行
// 1. 先计算“翻转后的左子树”:调用invertTree处理root原本的left
TreeNode left = invertTree(root.left);
// 2. 再计算“翻转后的右子树”:调用invertTree处理root原本的right
TreeNode right = invertTree(root.right);
- 这两步的核心是 “获取结果”:不管递归调用多深,都会先把
root原本的左子树翻转完,把结果存在left变量里;再把root原本的右子树翻转完,把结果存在right变量里。 - 此时,
root本身的left和right还没被修改(还是原来的样子),因为第三、四行的赋值代码还没执行。
阶段 2:修改当前 root 的左右子树(后两行代码)
java
运行
// 3. 用之前算好的“翻转后的右子树”,覆盖当前root的left
root.left = right;
// 4. 用之前算好的“翻转后的左子树”,覆盖当前root的right
root.right = left;
- 这两步才是 “修改当前节点”,而且用的是阶段 1 已经算好的固定结果(
left和right变量),和后续递归无关。
三、用 “套娃” 比喻再验证
假设当前处理的是根节点4(原左 = 2,原右 = 7):
- 执行
TreeNode left = invertTree(4.left):其实就是去翻 “2这个套娃”,翻完后把结果(翻好的2,左 = 3、右 = 1)存在left里; - 执行
TreeNode right = invertTree(4.right):去翻 “7这个套娃”,翻完后把结果(翻好的7,左 = 9、右 = 6)存在right里; - 这时候才执行
4.left = right(把翻好的7塞给4的左)、4.right = left(把翻好的2塞给4的右)。
整个过程中,翻2和翻7的时候,4的左右还是原来的2和7,完全没被修改 —— 因为赋值操作是最后才做的。
四、关键误区澄清
你担心的 “第二次调用时 root 已经变了”,本质是误以为 “执行第二行invertTree(root.right)时,第一行已经修改了 root”。但实际是:
- 前两行都是 “读取并处理 root 原本的左右子树”,不修改 root;
- 只有等前两行的递归全执行完,才会修改 root 的左右。
所以递归过程中,每个节点的 “原始左右子树” 都是固定的,不会被提前修改,放心就好~
【我的意思是第一次交换过了左右节点,第二次回头再来一遍这里的root就变了?】
你的疑问核心是 “会不会有第二次回头处理同一个 root”—— 答案是不会!递归的逻辑是 “处理一个节点时,只处理一次,且处理完就不再回头”,每个节点的 “左右交换” 只执行 1 次,不存在 “第二次再来一遍” 的情况。咱们从 “递归的调用链路” 和 “节点处理次数” 两个角度说透:
一、递归是 “向下拆解,向上组装”,每个节点只被 “处理一次”
递归处理二叉树的过程,像 “从根节点往下拆套娃,拆到最内层后,再从内往外组装”——每个节点只会在 “组装到它” 的时候,执行一次交换逻辑,之后再也不会被这个递归流程重新处理。
用示例 1 的根节点4举例,完整链路是:
- 向下拆:处理
4时,先去拆它的左子树2→ 拆2时,再去拆它的左子树1→1没有子节点(拆到最内层),直接返回1; - 向上装:回到
2,处理2的右子树3(拆完返回3)→ 此时2的左右子树都拆完,执行2的交换(左 = 3,右 = 1)→2处理完,返回给4; - 再处理
4的右子树7(同样 “拆→装”,交换后返回7); - 最后回到
4,执行4的交换(左 = 7,右 = 2)→4处理完,整个流程结束。
整个过程中,4、2、7、1、3、6、9每个节点都只被 “处理一次”(只执行一次自己的 “交换左右” 逻辑),处理完就作为结果返回给父节点,不会有 “第二次回头处理同一个节点” 的情况。
二、为什么不会 “回头”?因为递归的 “调用栈” 是 “先进后出”
递归的执行依赖 “调用栈”,每个函数调用会入栈,执行完会出栈,出栈后就不会再重新入栈(除非有新的调用,但这道题没有)。
还是以4和2为例:
- 当调用
invertTree(4)时,4的函数入栈; - 然后调用
invertTree(2)(处理4的左子树),2的函数入栈; - 再调用
invertTree(1)(处理2的左子树),1的函数入栈; 1处理完(无交换),出栈,回到2的函数;2处理完(交换左右),出栈,回到4的函数;4处理完(交换左右),出栈,整个流程结束。
每个节点的函数一旦出栈,就意味着它的 “处理已完成”,后续不会再重新入栈处理 —— 所以不存在 “第二次回头,root 已经变了” 的场景。
三、一句话总结
递归处理二叉树时,每个节点只被 “访问并交换一次”,处理顺序是 “先处理所有子节点,再处理当前节点”,子节点处理完不会回头,当前节点处理完也不会再被重新处理,因此无需担心 “root 被修改后再次调用” 的问题。
【有点像祖玛游戏一个一个珠子过去,root只走一遍,但是每一次左右都换了】
这个比喻太形象了!完全命中了递归处理的核心 ——每个 “珠子”(节点)只走一遍,走的时候就把自己的 “左右装饰”(左右子树)换好,之后再也不回头。咱们再顺着这个比喻补一层细节,帮你彻底敲定逻辑:
一、“祖玛珠子” 对应递归的 “节点处理顺序”
把整棵二叉树想象成一串 “祖玛珠子”,珠子的顺序是「从根到最左子树→回退到父节点→再到右子树」(也就是递归的 “深度优先” 顺序),每个珠子只被 “捏过一次”:
- 捏到一个珠子(比如节点
2),先不换它的左右,而是先顺着线捏它左边的小珠子(1); - 小珠子
1没有更小的珠子了(左右都是null),捏完直接放回去(无交换); - 再捏
2右边的小珠子(3),同样捏完放回去; - 现在回到
2这个珠子,这时候才把它的 “左珠” 和 “右珠”(1和3)对调,换完后2就处理完了,再也不碰; - 接着回到上一颗大珠子(
4),等它右边的珠子(7)也按同样逻辑捏完、换完,再把4的 “左珠”(换好的2)和 “右珠”(换好的7)对调。
二、“只走一遍” 对应 “节点不重复处理”
祖玛游戏里珠子滚过就不会倒回来,递归里的节点也一样:
- 每个节点的 “交换左右” 操作,只会在 “所有子节点都处理完” 后执行一次;
- 执行完交换,这个节点就作为 “处理好的成品”,传递给上一级节点(父节点),之后再也不会被这个递归流程重新访问。
比如节点2换完左右后,就变成了 “左3、右1” 的状态,后续只有父节点4会把它当作 “成品珠子” 来用,不会再单独拿出来重新换一次。
三、“每一次左右都换了” 对应 “递归的核心动作”
没错!每个珠子(非空节点)被 “捏到” 时,核心动作就是 “换左右”—— 但这个 “换” 是有前提的:
- 必须等它左右两边的 “子珠子串” 都先换好(递归处理完左右子树),再换自己的左右;
- 换的时候用的是 “已经换好的子珠子串”(前两行递归得到的
left和right变量),不是没处理过的原始子树。
就像祖玛里换珠子装饰,得先把左右两边的小装饰串做好,再往当前珠子上装,装完就固定了。
一句话收尾
你说的 “祖玛珠子” 逻辑,完美对应了递归的「深度优先、节点唯一处理、先子后父交换”—— 每个节点只走一趟,走的时候就把左右换好,整个流程顺下来,树自然就翻过来了~
----------------------------------
最后手敲一遍吧!
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode invertTree(TreeNode root) {
if (root == null){
return null;
}
TreeNode left = invertTree(root.left);
TreeNode right = invertTree(root.right);
root.left = right;
root.right = left;
return root;
}
}
加油!(ง •_•)ง