Pulsar存储计算分离架构设计之存储层BookKeeper(上)
一、前言
我们上文说过,Apache Pulsar 采用了一种典型的"存储计算分离"架构设计:消息内容持久化存储在 BookKeeper 分布式日志存储系统中,集群元数据由 ZooKeeper 协调服务统一管理(当然2.10.0版本移除了ZK是题外话了),而 Broker 节点则专注于消息的路由、协议转换等计算密集型任务,完全解耦了存储与计算功能。这种架构通过职责分离实现了水平扩展能力,其中 BookKeeper 负责数据可靠性保障,ZooKeeper 维护系统状态一致性,Broker 作为无状态服务可动态扩缩容。在组件关系上,Broker深度依赖Bookie,内部集成了Bookie的client端,Broker和Bookie之间基于TCP通信,使用protobuf协议。
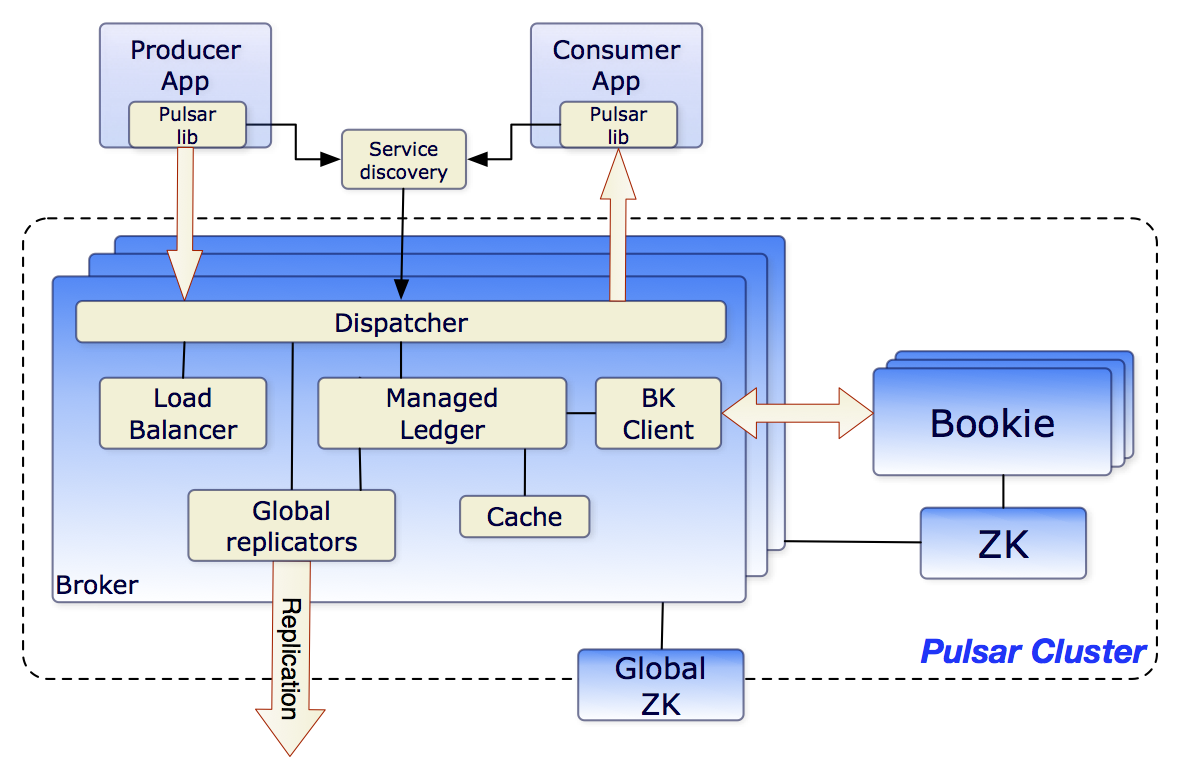
上一篇文章我们说了Broker无状态,这一篇我们来聊聊"存储计算分离"中的存储——BookKeeper。
二、BookKeeper 基本概念
Apache BookKeeper 官网是这么介绍的:
A scalable, fault-tolerant, and low-latency storage service optimized for real-time workloads
针对实时工作负载优化的可扩展、容错、低延迟存储服务
2.1 Bookie
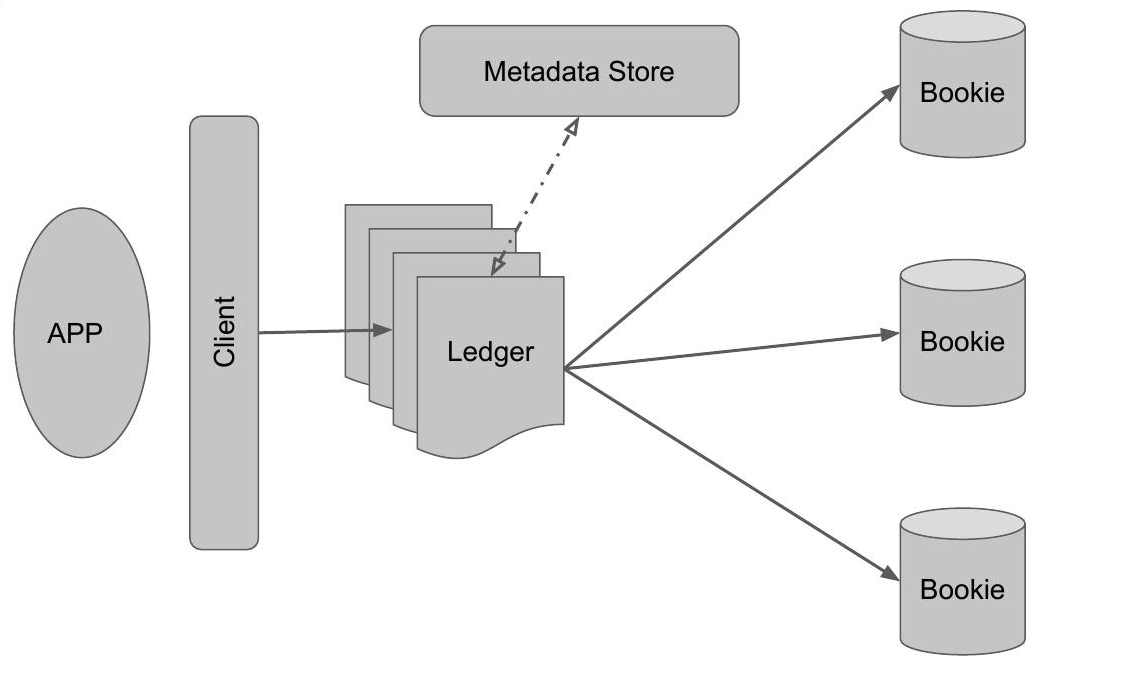
BookKeeper 的存储节点(服务器),负责持久化数据。多个 Bookie 组成无中心节点的集群(Slave/Slave 架构),通过 ZooKeeper 协调元数据。
2.2 Ledger
基本存储单元,代表一个有限的数据流(类似文件的逻辑分段)。由一系列顺序写入、不可修改的 Entry (类似与 Kafka 每条 msg)组成。Ledger 是对一个 log 文件的抽象,Client 在向 BookKeeper 写数据时也是往 Ledger 中写的。
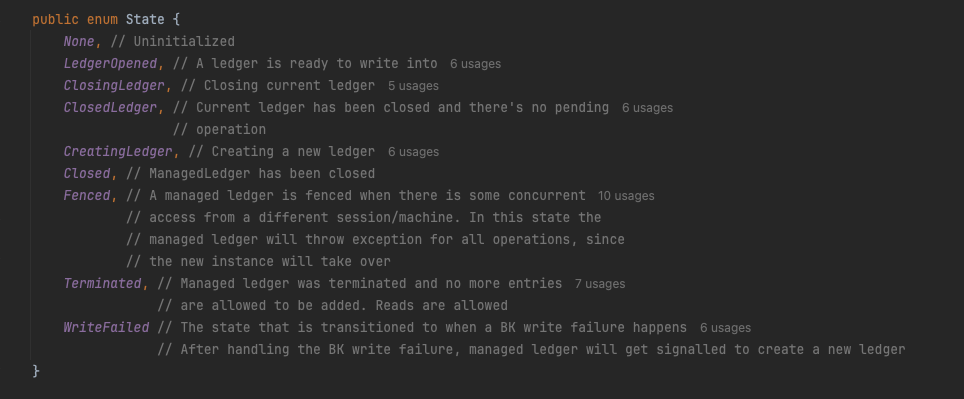
我看网上好几年前写BookKeeper的文章中写到Ledger生命周期:仅支持 OPEN(写入中)、IN_RECOVERY(数据恢复)、CLOSED(不可修改)三种状态。
我一看源码,嚯,有八九种了,所以老周这里还是建议大家多看看源码。
2.3 Entry
单条数据记录,包含以下字段:
- Ledger number(所属 Ledger ID)
- Entry number(唯一 Entry ID)
- Last add confirmed(最新已确认 Entry ID)
- Data(消息内容)
- Authentication code(数据完整性校验码)
2.4 Journal
预写日志(Write Ahead Log),所有写入操作优先记录到 Journal 文件,确保数据持久性。
2.5 Ensemble & 写入策略
- Ensemble:存储某个 Ledger 的 Bookie 集合。
- Write Quorum (WQ):数据副本数(如 3 副本)。
- Ack Quorum (AQ):写入成功所需的最小确认数(如 2/3 副本确认即返回成功)。
2.6 LAC (Last Add Confirmed)
Ledger 中最新被多数副本确认的 Entry ID,用于保证读取一致性。
三、架构设计
3.1 特性
3.1.1 无中心化集群
- 所有 Bookie 对等(无 Master 节点),通过 ZooKeeper 管理元数据(如 Ledger 分配)。
- 容错机制:允许部分 Bookie 故障(需满足 WQ > 故障节点数)。
3.1.2 分层存储模型
- Entry Log:物理存储文件,聚合多个 Ledger 的 Entry 以提升 I/O 效率。
- 索引分离:Entry Log 存储数据,RocksDB 独立存储 Ledger 和 Entry 的索引。
3.1.3 读写分离机制
- 写入优先 Journal 日志,再异步刷入 Entry Log;读取直接访问 Entry Log,降低延迟。
3.1.4 严格写入约束
-
同一 Ledger 仅允许单一写入者,避免脑裂。
-
Entry ID 必须严格递增,确保数据顺序和分片(Fragment)定位准确性。
3.2 Pulsar的整体架构
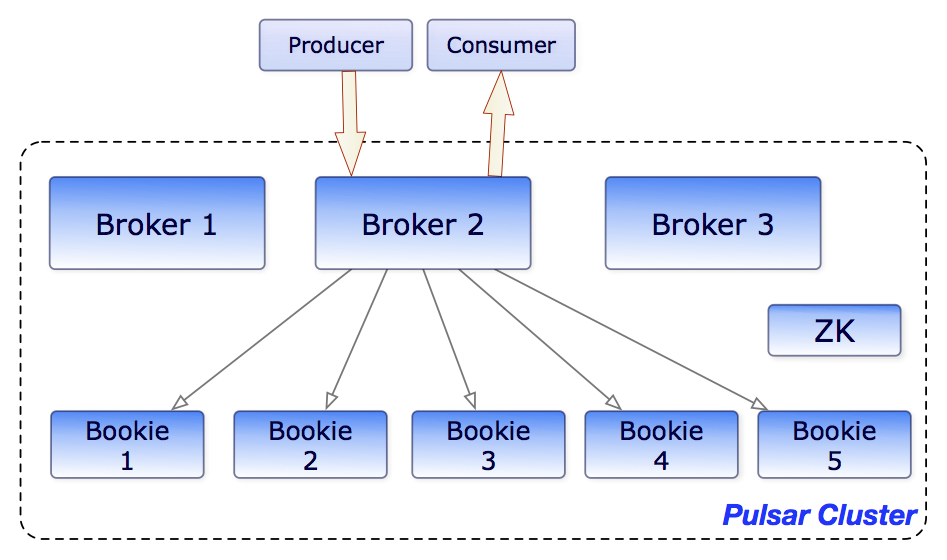
在分布式消息系统中,消息从客户端传输至Broker节点后,需通过计算转换与路由决策最终持久化到Bookie存储集群。值得注意的是:
- 角色分工:Bookie仅作为单机存储引擎,数据高可用性由Broker层保障
- 副本配置:单条消息的存储副本数支持动态配置
主流分发模式对比:
-
主从式串行分发
- 实现原理:主节点接收写入后,顺序转发至从节点(如RocketMQ/MySQL架构)
- 特点:
- ✅ 架构简单,逻辑清晰
- ❌ 写入延迟叠加(主节点延迟 + 从节点延迟)
- ❌ 同步复制时存在性能瓶颈
-
并行多路分发
- 实现原理:Broker同时向多个Bookie节点并发写入(Pulsar采用此模式)
- 特点:
- ✅ 延迟取决于最慢节点(Max(shard1,shard2…))
- ✅ 理论上更高的吞吐量
- ❌ 需实现复杂故障补偿机制
- ❌ 网络带宽消耗更大
技术选型建议:
| 维度 | 主从模式 | 并行模式 |
|---|---|---|
| 延迟敏感性 | 不推荐 | 优先推荐 |
| 开发成本 | 低 | 高 |
| 数据一致性 | 依赖同步机制 | 原子写入保障 |
| 适用场景 | 非实时业务系统 | 金融/物联网场景 |
3.3 Pulsar的数据流架构
3.3.1 Topic分区下的Ledger时序管理机制
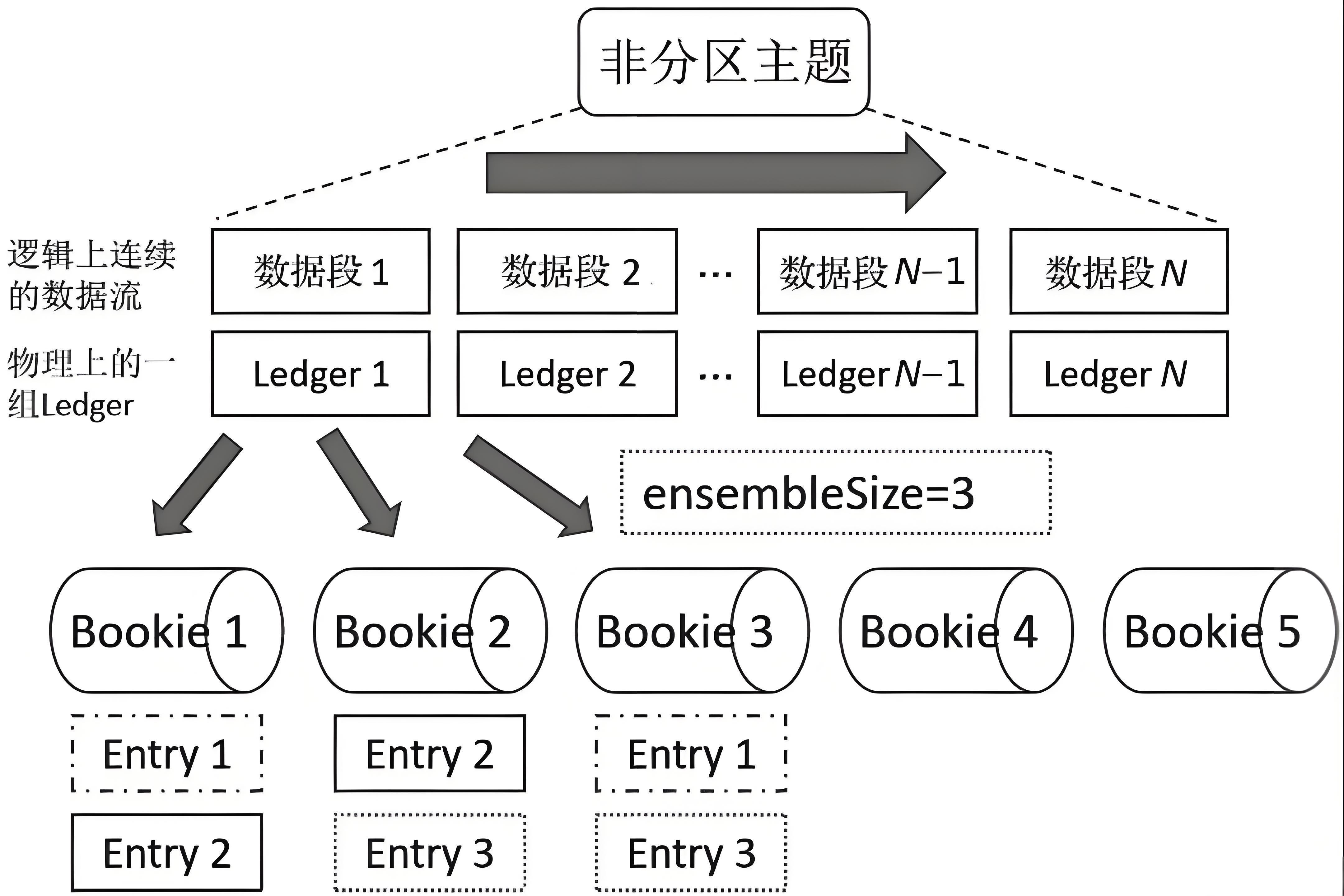
在分布式消息系统中,每个Topic分区(如topicA-partition1)的消息存储被组织为按时间顺序排列的Ledger序列。系统通过全局唯一的LedgerId标识每个物理集群中的Ledger,采用中心化分配策略确保无重复。对于特定分区,仅最新创建的Ledger(如示例中的ledgerN)处于可写入状态,先前所有Ledger(ledger1至ledgerN-1)均被标记为关闭状态禁止写入。
3.3.2 写入拓扑与数据持久化策略
系统比如采用(3,2,2)的写入配置模式:
- 3:表示该Topic分区数据可写入的候选节点数量
- 2:表示每条消息实际写入的副本数(包含主副本)
- 2:表示需要收到至少2个节点(含主节点)的成功写入确认后,才会向客户端返回ACK响应
单个Ledger的默认容量为50,000条消息,达到阈值后将自动关闭并创建新Ledger。这种设计既保证了消息的顺序性(通过Ledger序列),又通过多副本写入确保了数据可靠性。
四、Bookie的架构设计
前面铺垫了这么多前置的知识,终于千呼万唤始出来Bookie的架构设计了。Bookie作为Pulsar的持久化存储的核心引擎,其设计充分考虑了高吞吐与低延迟的平衡。Journal日志作为写入的第一道关口,采用类似Kafka commitlog的乱序追加写机制,允许多主题数据混合写入同一文件,这种设计显著提升了磁盘顺序写的吞吐效率。值得注意的是,通过将journal目录与独立磁盘绑定的部署方式(官方推荐配置),配合多journal目录并行写入的线程隔离策略,实现了基于LedgerId取模的无锁化路由,这种精巧的线程模型既避免了资源竞争,又确保了写入线性化。在可靠性方面,journal支持同步/异步两种刷盘模式,当配置为同步模式时,其行为类似MySQL的innodb_flush_log_at_trx_commit=1的严格持久化保证,而异步模式则通过牺牲部分数据安全性换取更高的吞吐性能。
与journal的即时确认机制不同,entrylog作为消息的最终存储载体,其刷盘策略与写入响应解耦,这种设计使得Bookie在保证写入低延迟的同时,还能通过后台批量刷盘优化IO效率。特别需要指出的是,journal和entrylog的异步刷盘配置会打破传统认知中"先写日志再存数据"的时序关系,这种反直觉的设计实际上是通过现代SSD设备的并行IO能力,实现了日志写入与数据落盘的双管道并发处理。这种架构在金融级消息场景下,可通过适当配置同步刷盘策略来满足强一致性要求,而在物联网等海量数据场景则可采用全异步模式最大化吞吐,展现出极强的场景适配性。
Bookie数据存储架构:
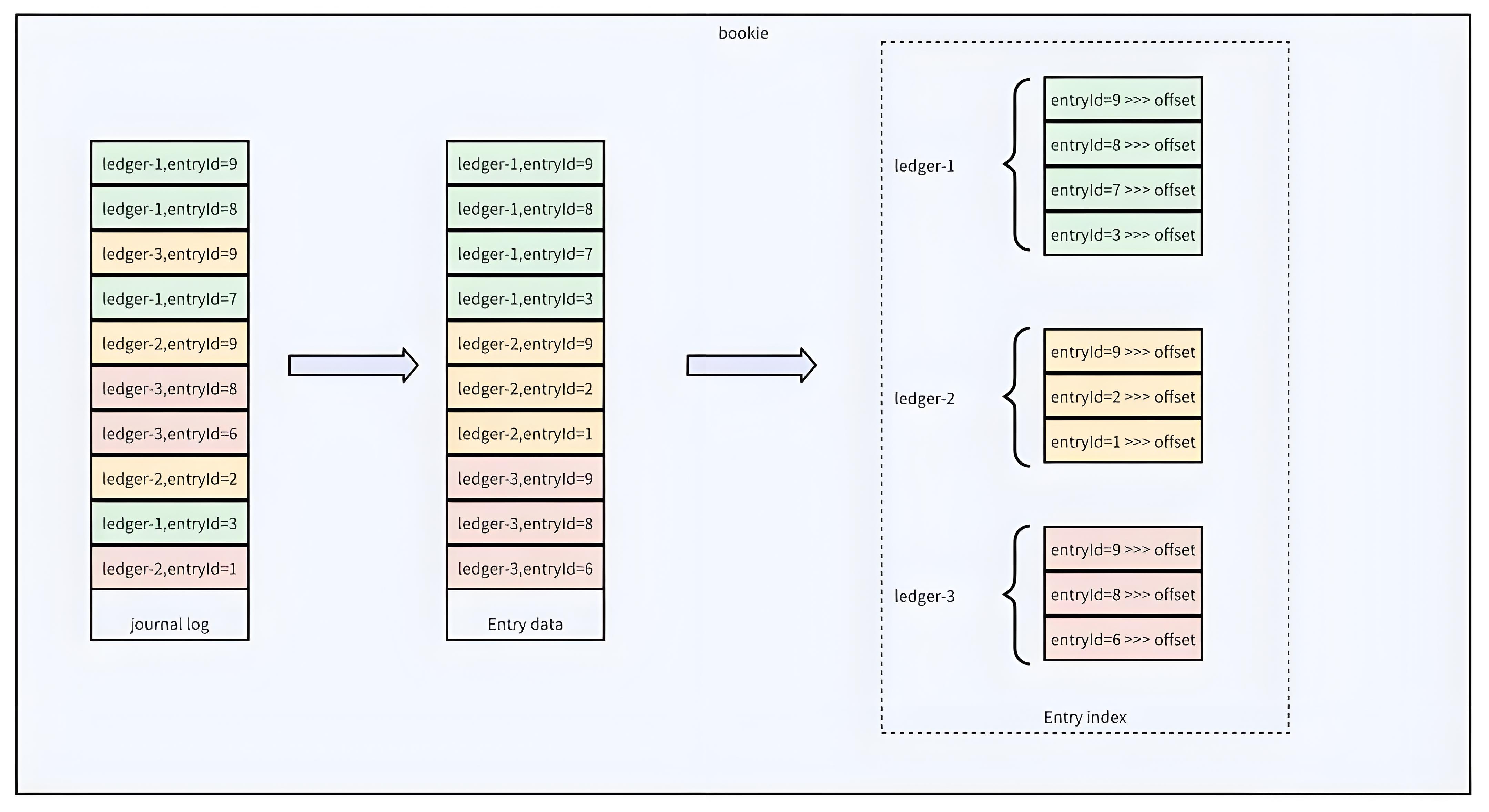
在分布式存储系统BookKeeper中,Journal日志通过混合落盘机制实现了数据持久化与性能的平衡。Journal作为预写日志(WAL),采用顺序追加写入模式确保数据不丢失,同时通过强制刷盘(journalSyncData)保证一致性。但Journal中的数据按写入时间无序排列,若直接读取会导致随机IO,影响消费性能。为此,Bookie设计了二次转写机制:数据首先写入Journal,随后异步转存至EntryLog文件,转存时按LedgerId和EntryId排序后批量刷盘,形成局部有序的数据块。这种设计使得同一Ledger的数据在EntryLog中物理连续,消费时可减少磁头寻道时间,将随机IO转化为顺序IO,吞吐量提升可达10倍以上。
EntryIndex作为关键元数据,维护了LedgerId+EntryId到EntryLog文件偏移量的映射关系。当消费者请求特定条目时,系统先通过内存中的IndexCache快速定位数据在EntryLog中的位置,避免全文件扫描。这种两级存储架构(Journal+EntryLog)与索引优化,既满足了写入时的高吞吐(Journal顺序写),又优化了读取性能(EntryLog局部有序+索引加速)。值得注意的是,EntryLog默认与Journal独立存储在不同磁盘,进一步规避IO竞争,这种设计在金融级低延迟场景中尤为关键。
通过对Bookie架构的上分析,我们发现针对读写场景Bookie做了两件事来支撑:
- 混合Ledger顺序写的journal日志支撑高吞吐低延迟的写入场景
- 局部有序的entry data支撑消费场景下的Ledger级别的顺序读
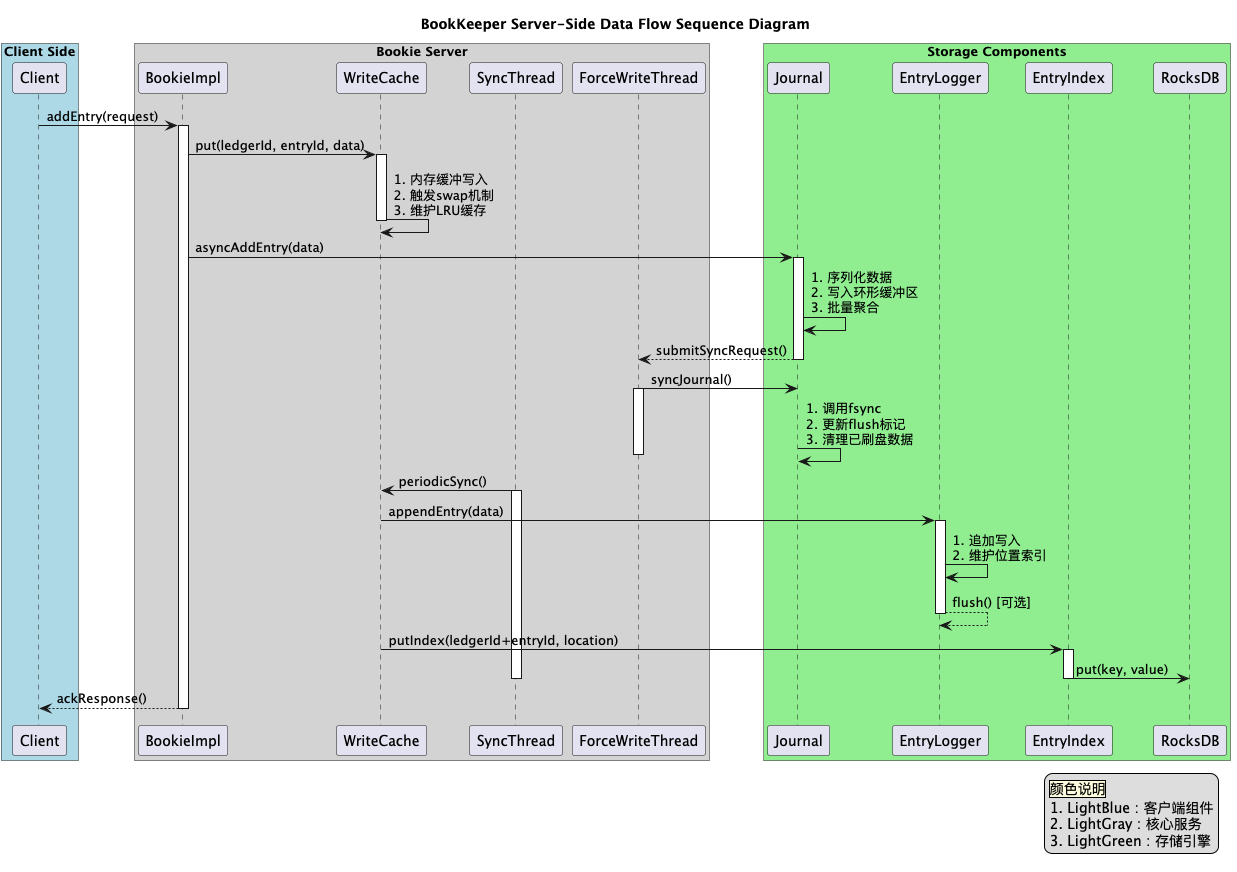
五、Bookie的数据写入流程
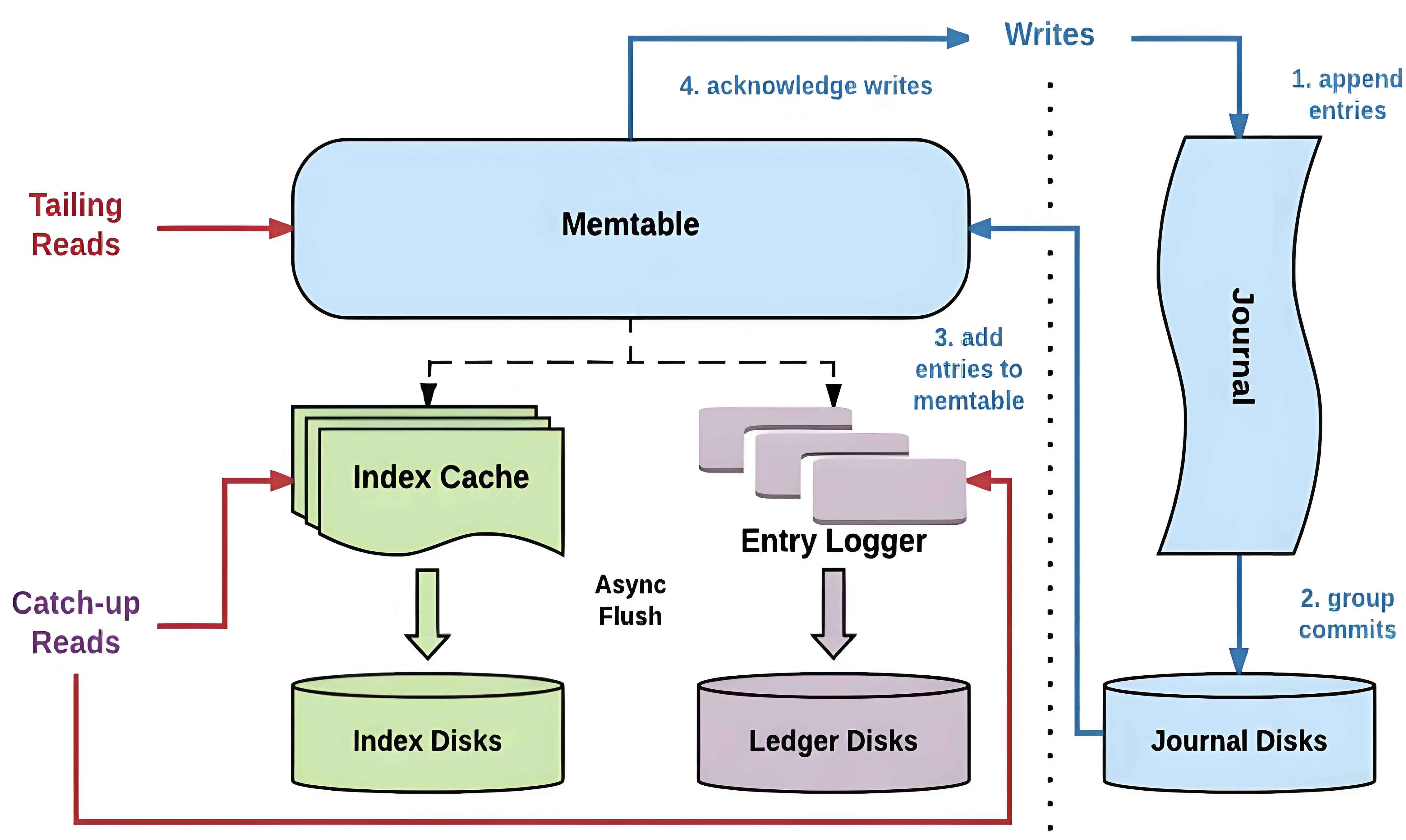
可以说理解这张图,Bookie的数据读取、写入流程基本思想是掌握了。
数据的写入流程:
- 数据首先会写入 Journal,写 Journal 的数据会实时写入磁盘以保证数据不会再重启时丢失
- 数据写入到 Memtable,Memtable 可以看做是一个读写 Cache
- 数据写入到 Memtable之后,就可以对写入请求进行响应
- Memtable 写满之后, 数据会批量的 flush 到磁盘,同时也会将 index cache 中的 index 信息 flush 到磁盘
数据的读取流程:
- 如果是 tailing read 请求(读取位置接近 Ledger 末尾的请求),直接从 Memtable 中读取 Entry
- 如果是 catch-up read 请求(读取内容不在 MemTable 中的请求)
- 读取 Index信息,找到 <ledgerId, EntryId> 对应的文件位置
- 读文件获取数据获取 Entry
Bookie数据写入流程:
client端源码分析,可以找到pulsar的测试代码,具体类在org.apache.bookkeeper.mledger.SimpleBookKeeperTest
这个方法是直接在LedgerHandle里的addEntry方法。LedgerHandle.addEntry: 这是 BookKeeper 客户端 API 的底层方法,直接与单个 BookKeeper ledger 交互。它处理的是单一 ledger 的写入操作。而ManagedLedgerImpl.addEntry: 这是 Pulsar 的 Managed Ledger 抽象层的方法,构建在 LedgerHandle 之上,提供更高级别的功能。
从Pulsar的Managed Ledger层起的话,addEntry的主要流程可以看下面:
- ManagedLedgerImpl#addEntry()方法
- ManagedLedgerImpl#asyncAddEntry()方法
- ManagedLedgerImpl#internalAsyncAddEntry()方法
- OpAddEntry#initiate()方法
- LedgerHandle#asyncAddEntry()方法
- LedgerHandle#doAsyncAddEntry()方法
- BookieClient#addEntry()方法
核心实现在LedgerHandle#doAsyncAddEntry()方法:
protected void doAsyncAddEntry(final PendingAddOp op) {// 1. 流量控制:如果设置了限流器,则获取许可if (this.throttler != null) {this.throttler.acquire();}boolean wasClosed = false;synchronized(this) {// 2. 检查ledger是否可写if (this.isHandleWritable()) {// 3. 分配新的entryId(递增)long entryId = ++this.lastAddPushed;// 4. 更新当前ledger长度统计long currentLedgerLength = this.addToLength((long)op.payload.readableBytes());// 5. 设置操作的entryId和ledger长度op.setEntryId(entryId);op.setLedgerLength(currentLedgerLength);// 6. 将操作添加到待处理队列this.pendingAddOps.add(op);} else {// 7. 如果ledger已关闭,标记wasClosed为truewasClosed = true;}}if (wasClosed) {// 8. 处理向已关闭ledger添加条目的情况try {this.clientCtx.getMainWorkerPool().executeOrdered(this.ledgerId, new SafeRunnable() {public void safeRun() {LedgerHandle.LOG.warn("Attempt to add to closed ledger: {}", LedgerHandle.this.ledgerId);// 回调通知添加失败,返回LedgerClosedException错误码(-11)op.cb.addCompleteWithLatency(-11, LedgerHandle.this, -1L, 0L, op.ctx);}public String toString() {return String.format("AsyncAddEntryToClosedLedger(lid=%d)", LedgerHandle.this.ledgerId);}});} catch (RejectedExecutionException var14) {// 线程池拒绝执行时的异常处理op.cb.addCompleteWithLatency(BookKeeper.getReturnRc(this.clientCtx.getBookieClient(), -15), this, -1L, 0L, op.ctx);}} else {// 9. 正常处理流程:获取写入分布集合(确定要写入哪些bookie)DistributionSchedule.WriteSet ws = this.distributionSchedule.getWriteSet(op.getEntryId());try {// 10. 等待写入集合中的bookie变为可写状态if (!this.waitForWritable(ws, 0, this.clientCtx.getConf().waitForWriteSetMs)) {// 如果等待超时,则允许快速失败op.allowFailFastOnUnwritableChannel();}} finally {// 11. 回收写入集合资源ws.recycle();}try {// 12. 将操作提交到主工作线程池执行this.clientCtx.getMainWorkerPool().executeOrdered(this.ledgerId, op);} catch (RejectedExecutionException var15) {// 线程池拒绝执行时的异常处理op.cb.addCompleteWithLatency(BookKeeper.getReturnRc(this.clientCtx.getBookieClient(), -15), this, -1L, 0L, op.ctx);}}
}主要的点无非就是entryId是lastAddPushed累加而得到的,构造PendingAddOp对象放入到pendingAddOps队列中,该队列与当前Ledger绑定。
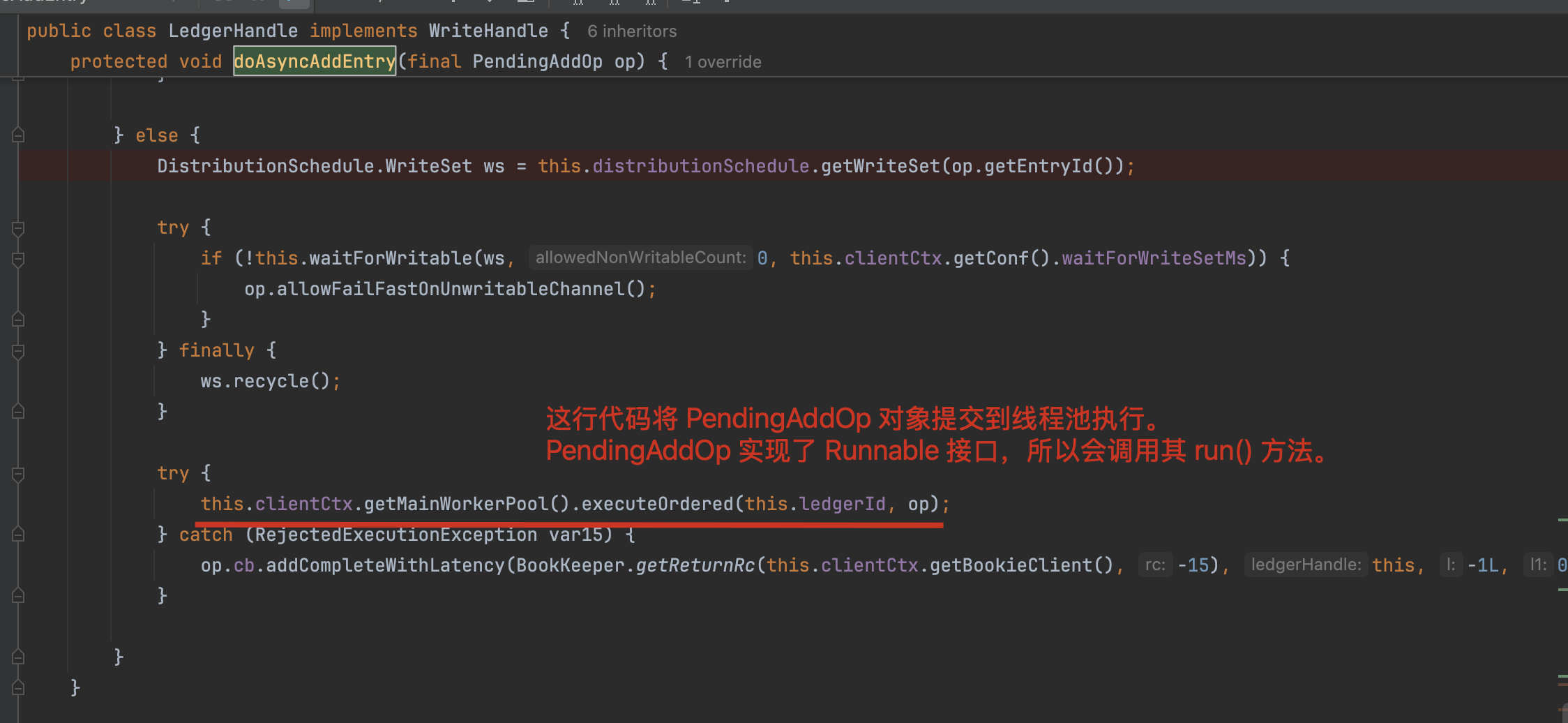
直接找到PendingAddOp#safeRun方法:
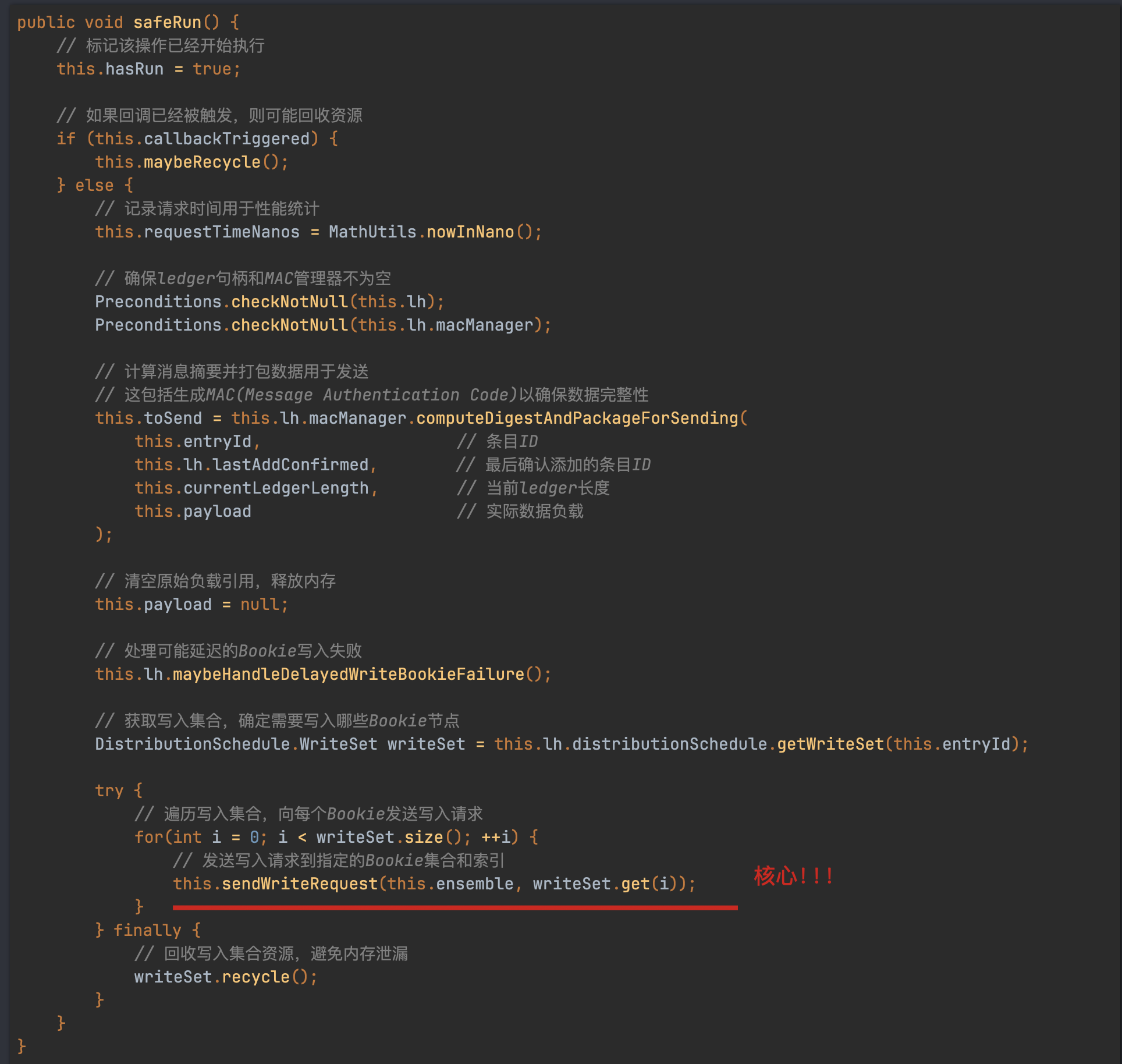
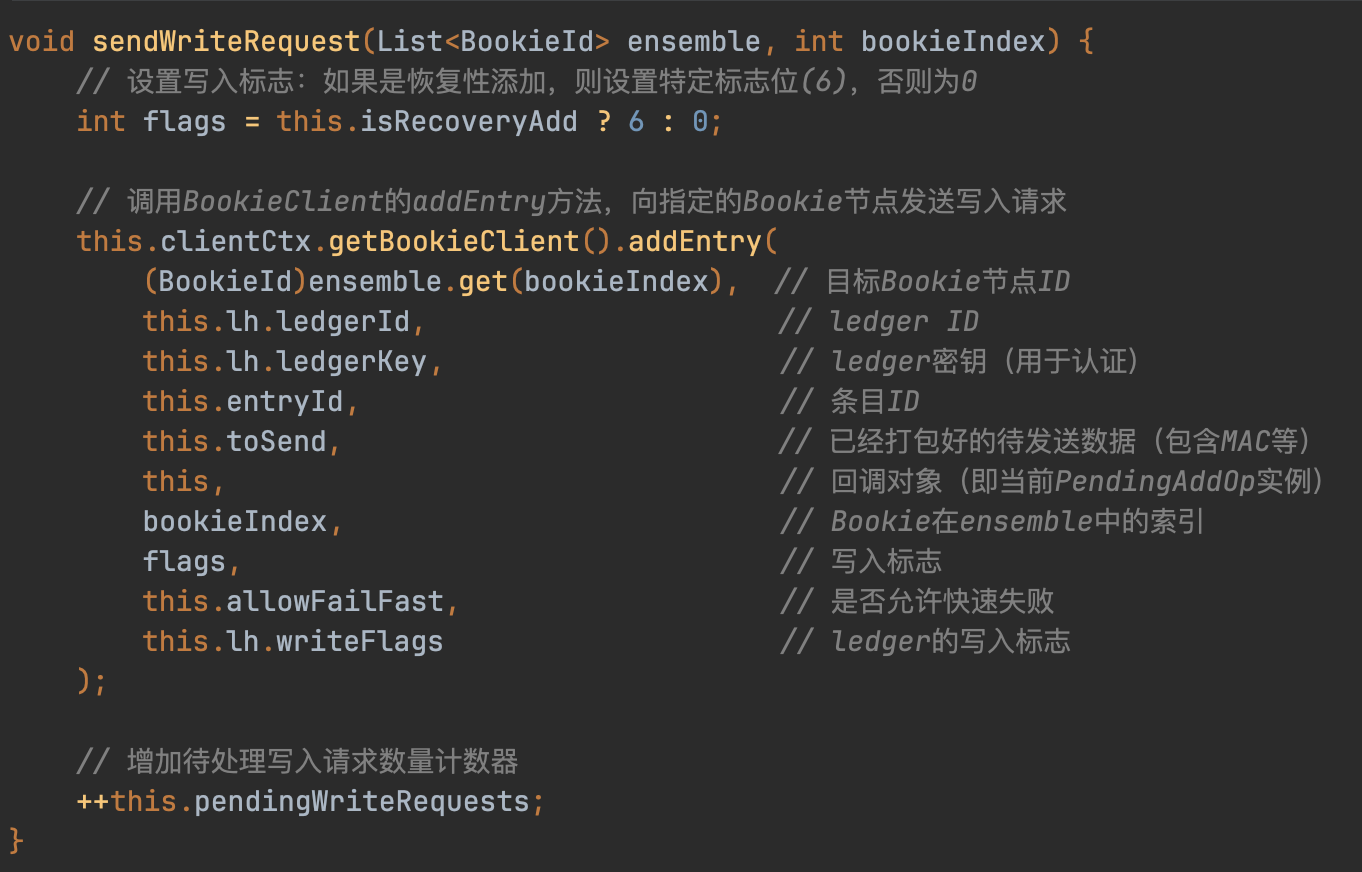
最终会调到BookieClient#addEntry()方法里来,addEntry里封装了很多细节,这里就不一一展开了,但最终会通过网络调用server端的相关接口。client的代码相对来说简单些,主要逻辑在server端。
server端源码分析
bookkeeper server端启动可以看 org.apache.bookkeeper.proto.BookieNettyServer类:
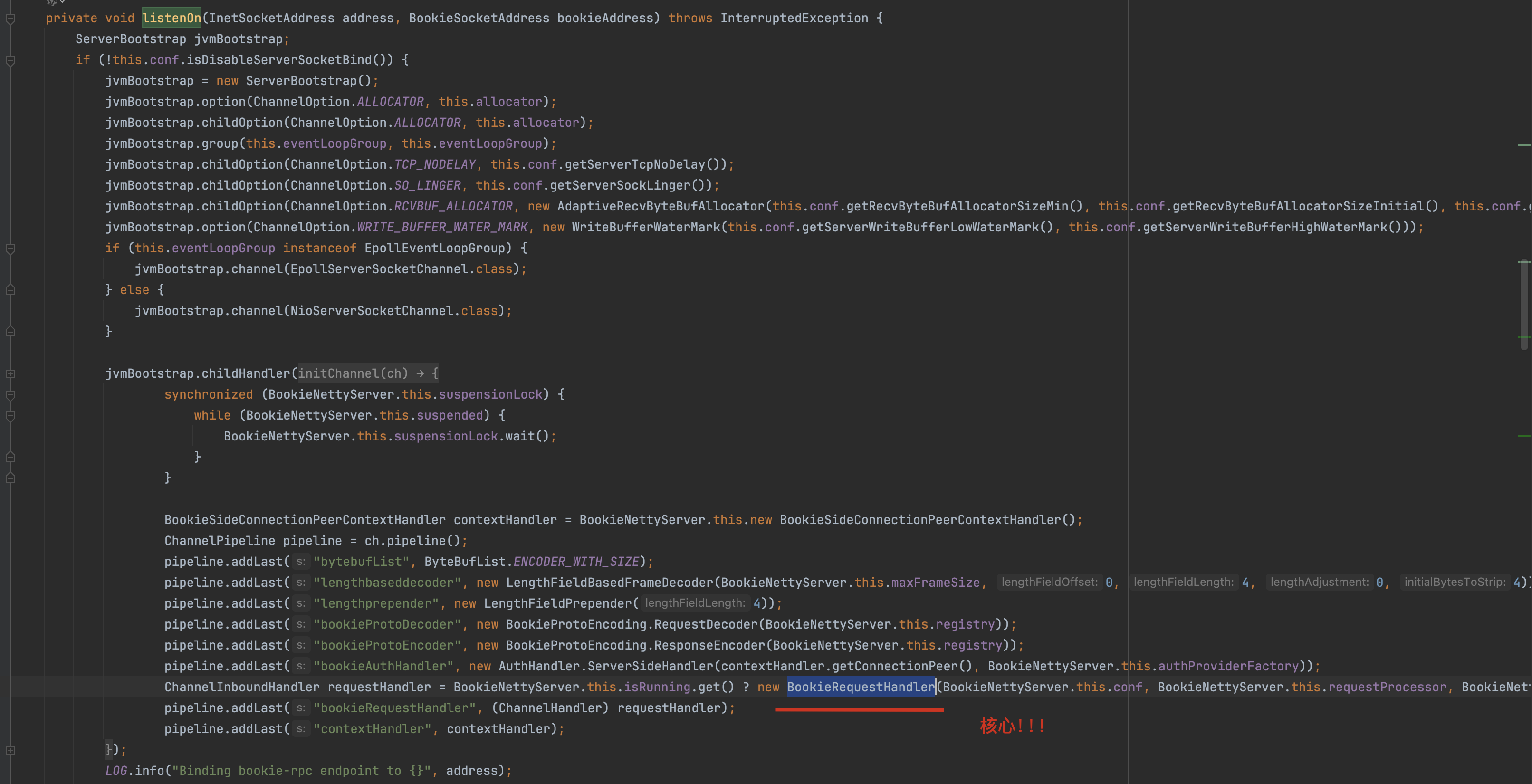
BookieRequestHandler为server端的处理类,其继承了Netty的ChannelInboundHandlerAdapter,是最外层与netty组合工作的handler。
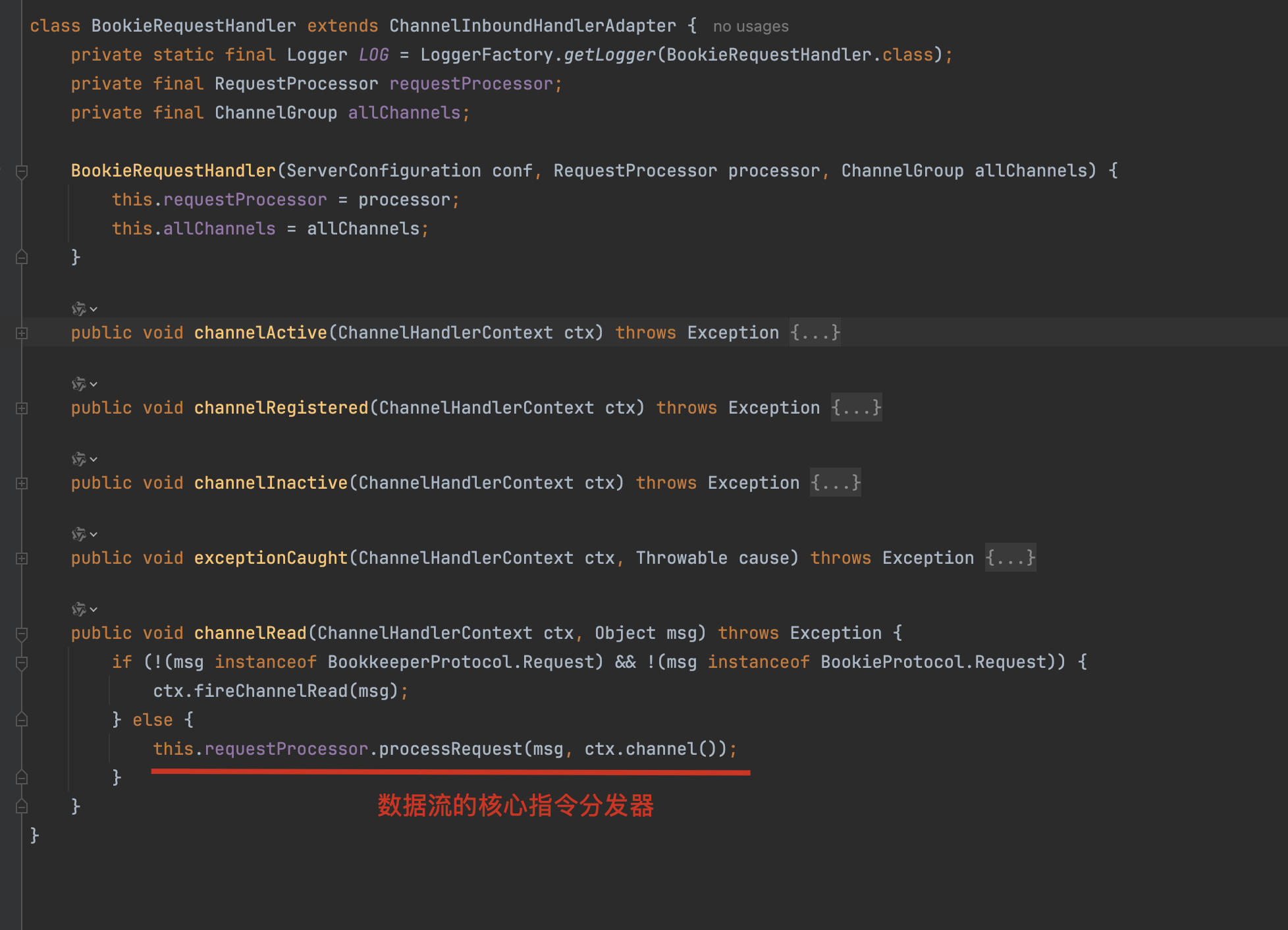
请求路由组件:BookieRequestProcessor
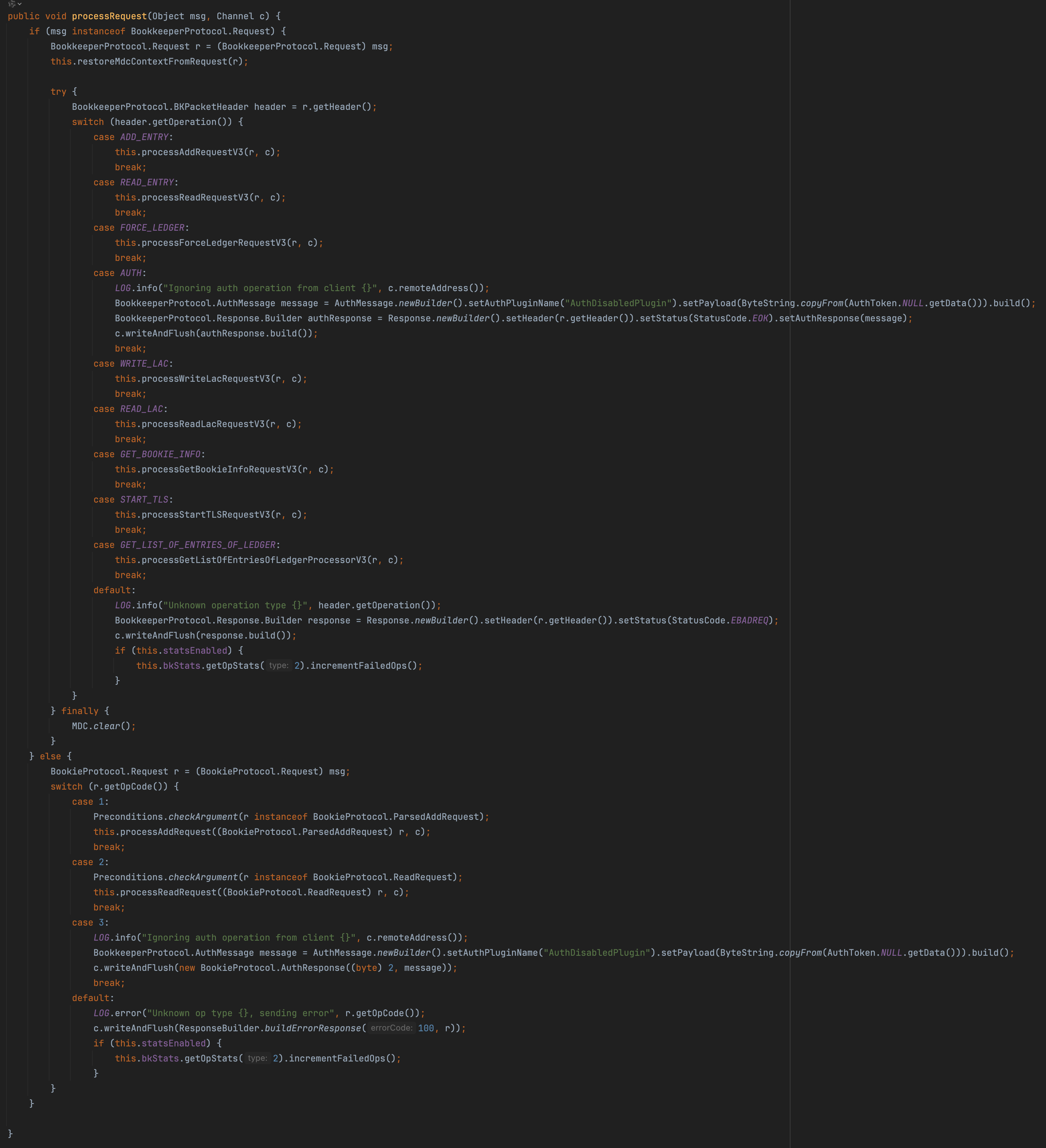
- 判断请求消息类型:V3协议(BookkeeperProtocol.Request)或旧版本协议(BookieProtocol.Request)
- 根据操作类型分发处理不同的请求
直接看 ADD_ENTRY 这个指令,看到 processAddRequestV3 中其实是WriteEntryProcessorV3类
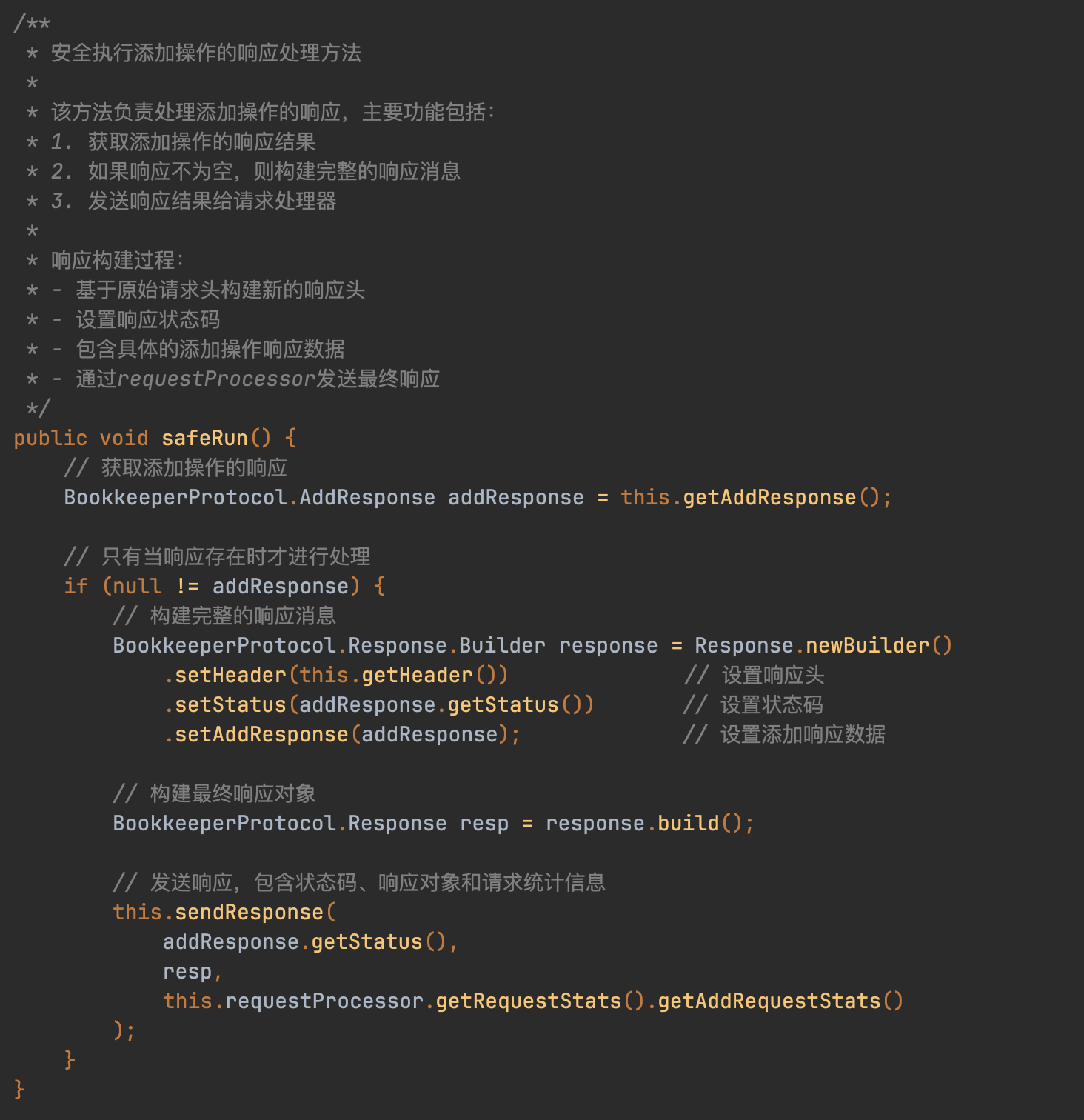
核心线程池任务:WriteEntryProcessorV3
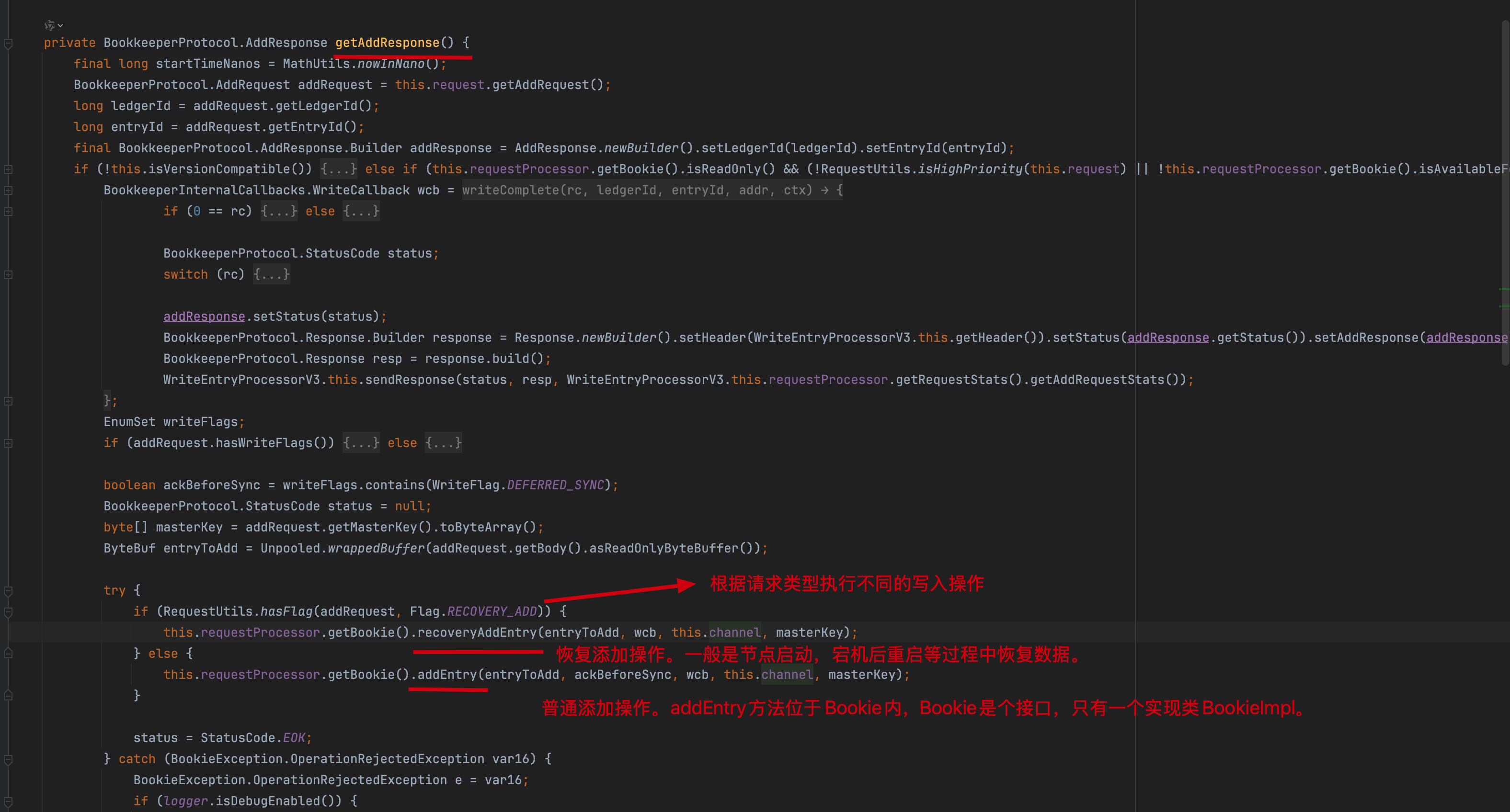
存储引擎接口抽象:Bookie
可以看到我划的红线,针对账本描述符LedgerDescriptor进行了synchronized加锁,同步块确保对同一账本的并发访问安全,也就是说在单个Ledger内部的数据的写入是通过加锁的方式实现串行化写入的。
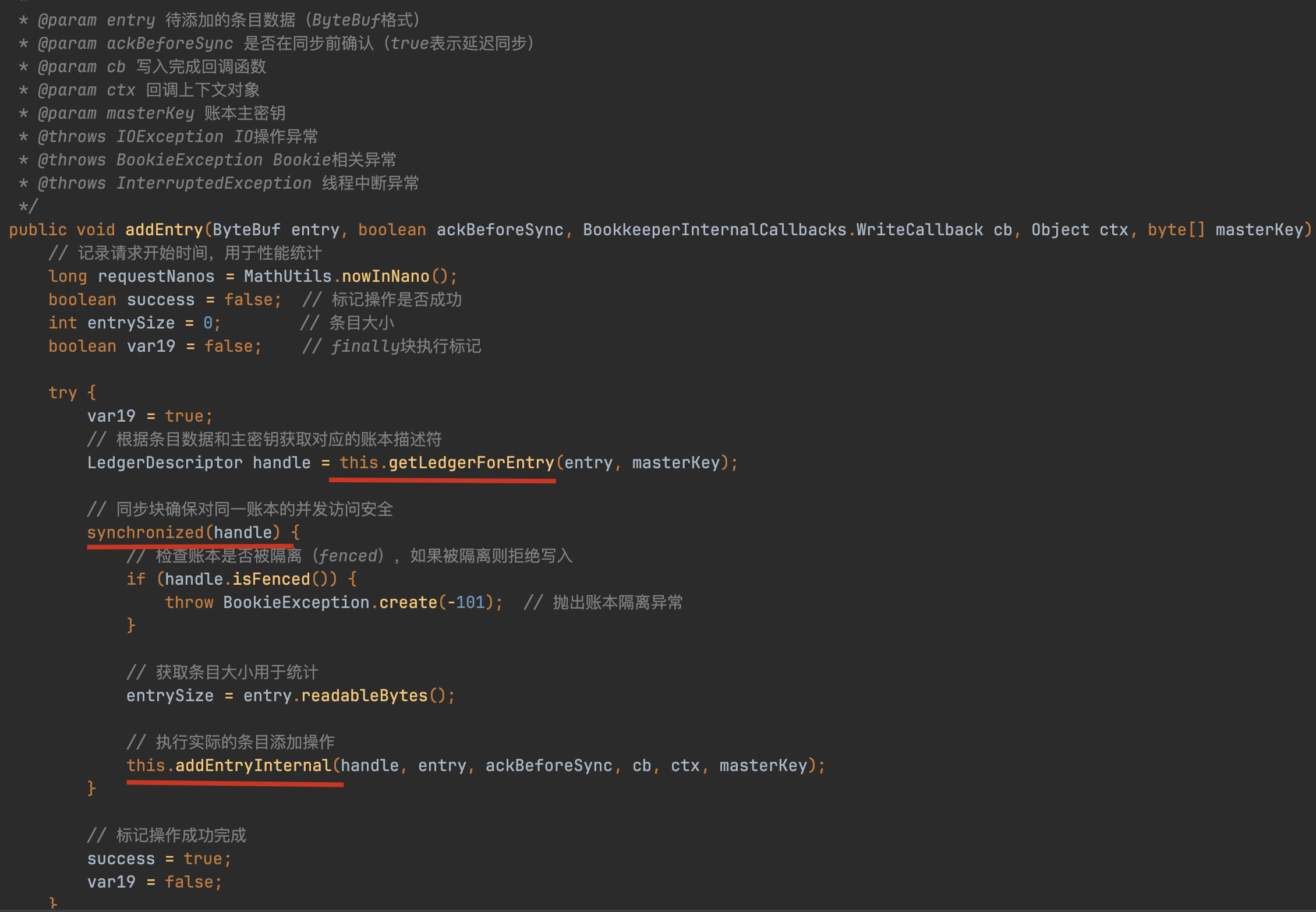
Ledger的管理者:LedgerDescriptor
handles.getHandle() 跟进来:
HandleFactory接口通过Map实现LedgerDescriptor的读写分离,其实现类HandleFactoryImpl维护两个Map分别处理读写操作,getHandle方法从Map中获取可写入的LedgerDescriptor。
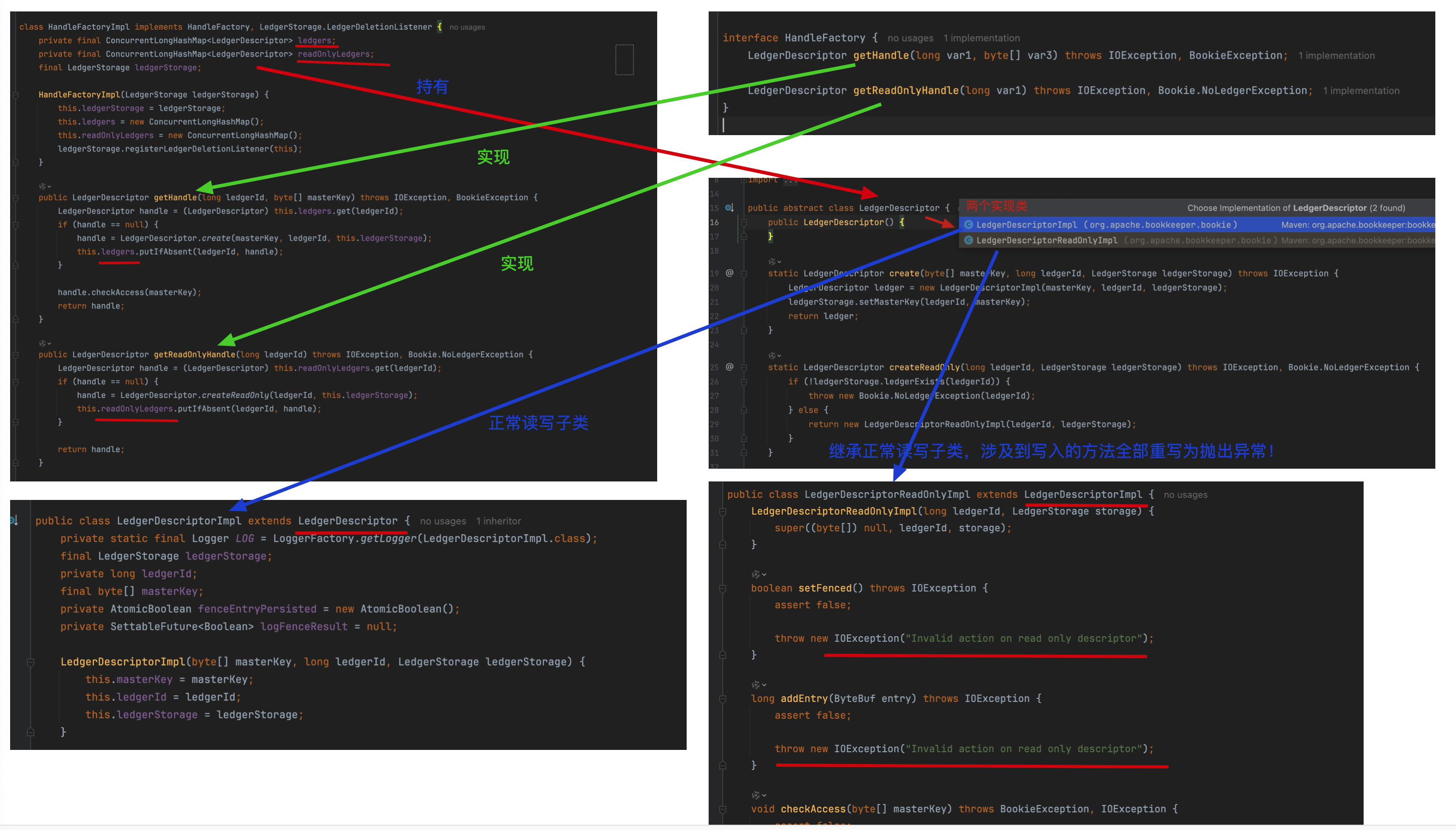
分析完 LedgerDescriptor 后,再回过来 Bookie#addEntryInternal() 方法。
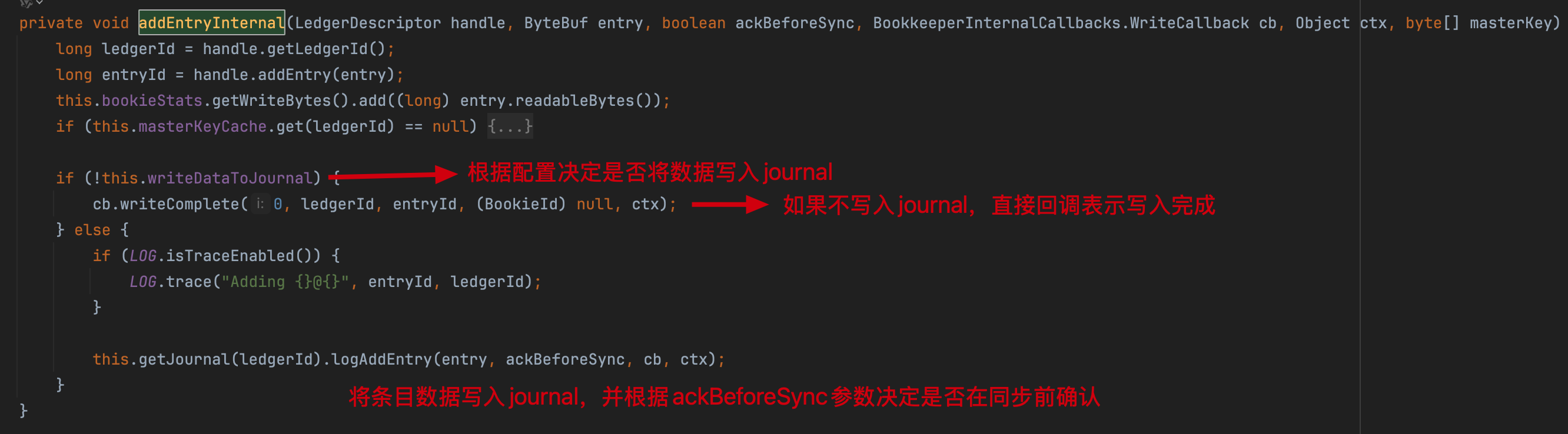
数据entry先持久化到Ledger storage,再异步写入journal日志(默认开启)。关闭journal后将失去磁盘备份功能,但由于消息通常多副本存储,在非全节点宕机场景下仍能保障数据可靠性。
Ledger的接口抽象:LedgerStorage
LedgerDescriptorImpl通过内置的ledgerStorage组件完成entry对象的最终持久化存储,其架构采用分层设计:数据优先写入主存储层,再异步写入可选的journal日志层(默认启用)。当journal关闭时,系统依赖多副本机制保障数据可靠性。
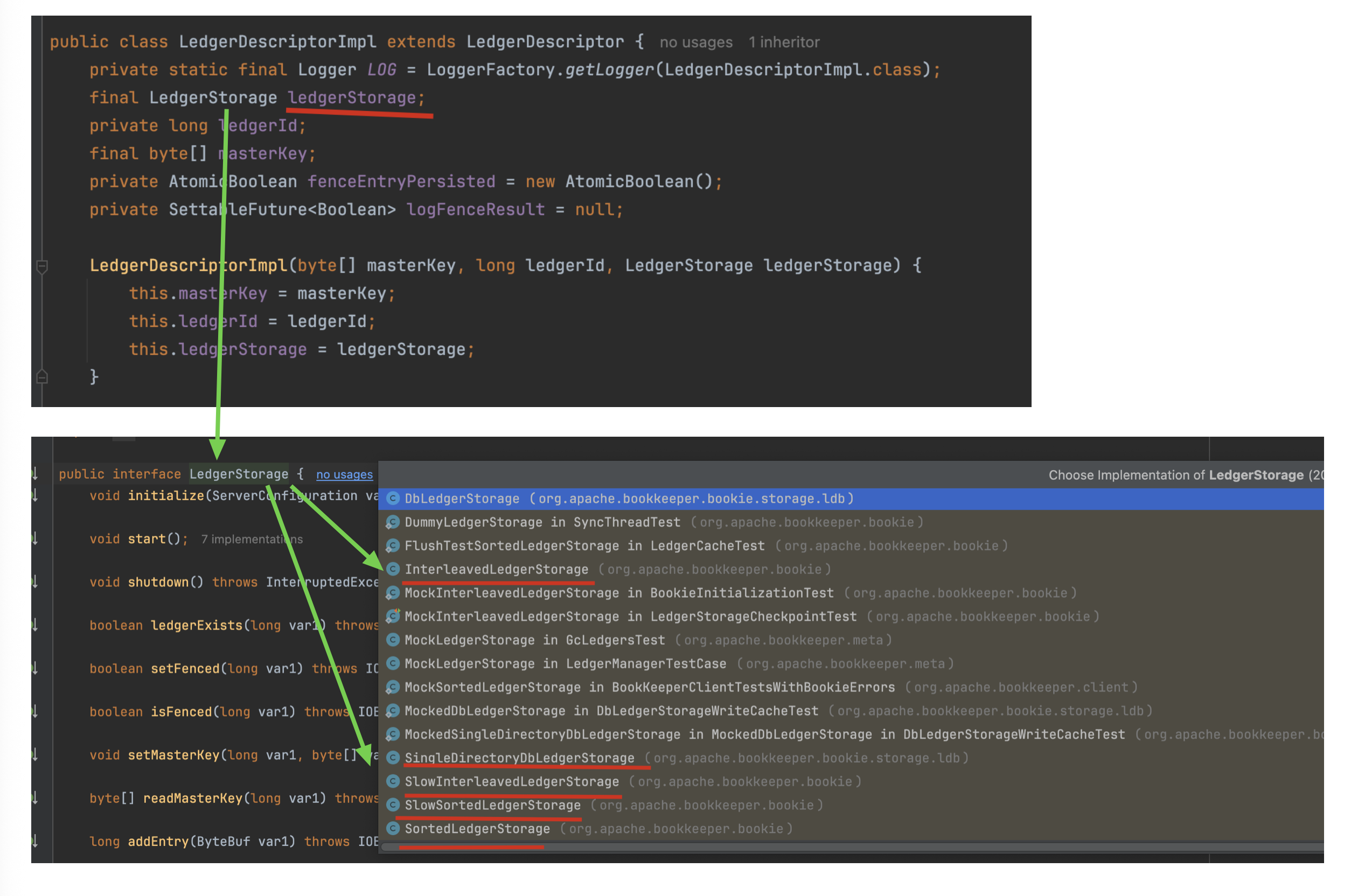
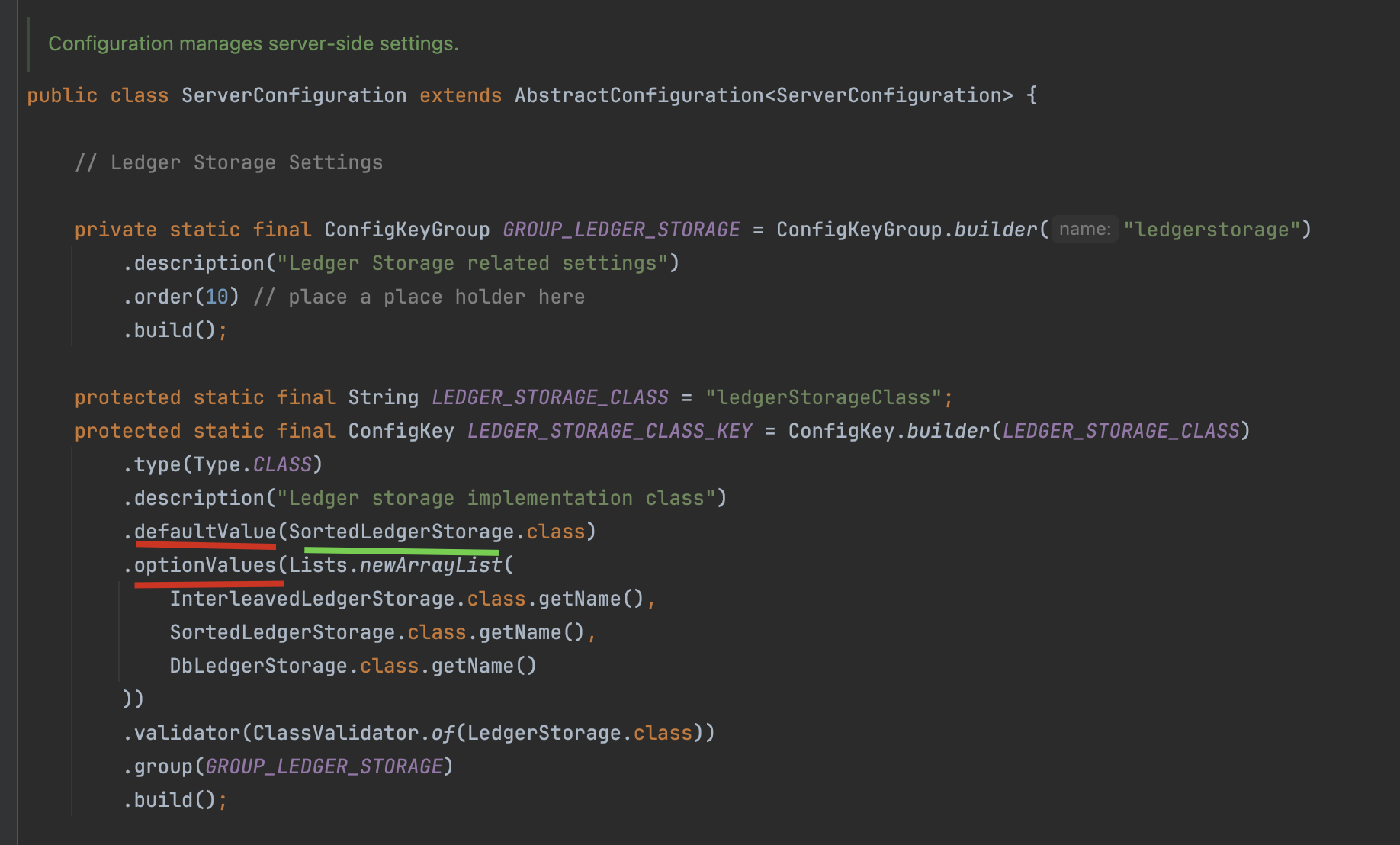
LedgerStorage 存在多个实现类,Bookie默认采用SortedLedgerStorage实现类,而Pulsar则通过DbLedgerStorage管理数据存储。两种存储引擎分别针对不同场景优化,其中DbLedgerStorage通过结合RocksDB提升索引性能。
我们先来分析下Pulsar的DbLedgerStorage存储引擎
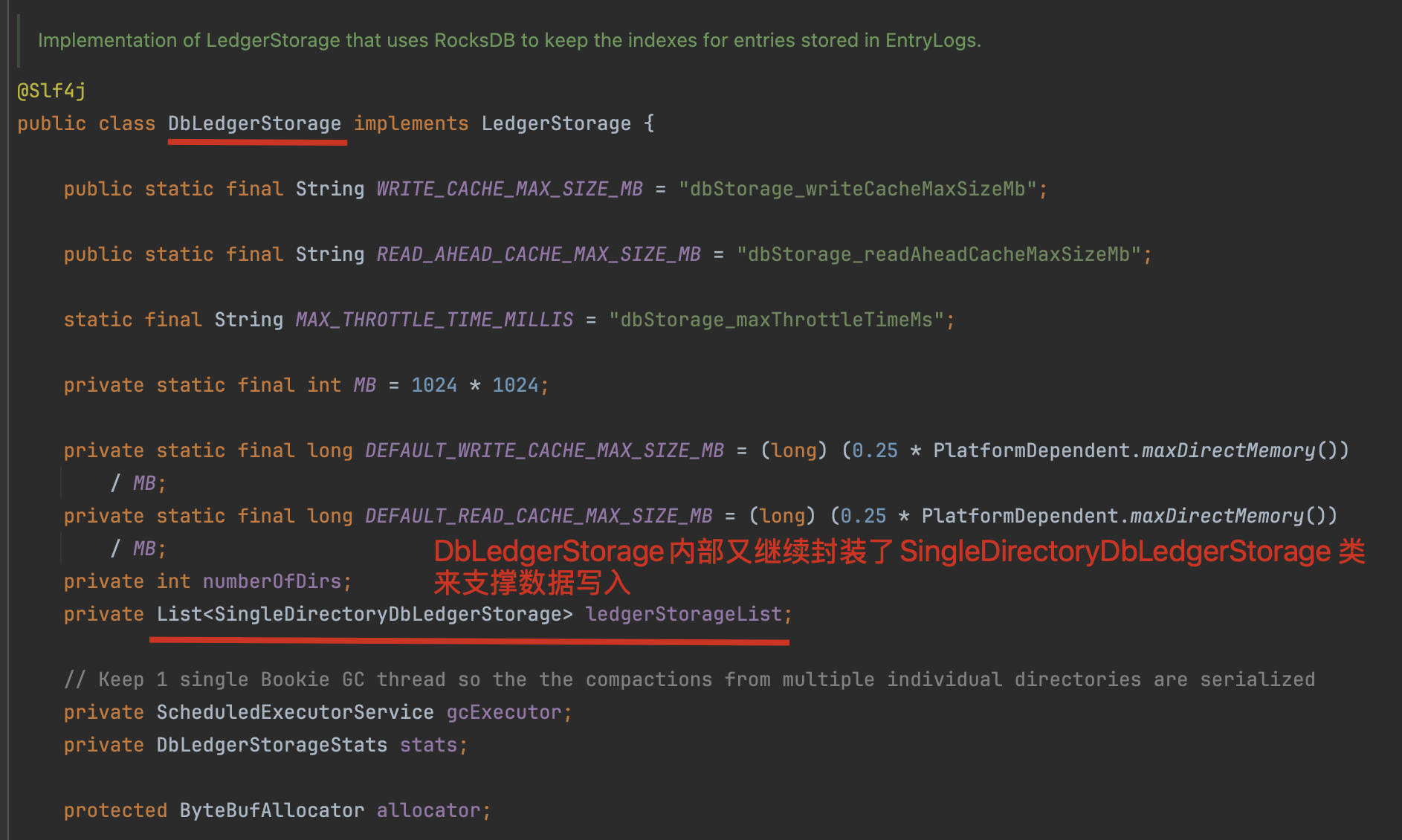
DbLedgerStorage采用RocksDB构建两级索引体系:
- 核心索引层:通过[ledgerId+entryId→location]的KV存储实现快速数据定位
- 实例管理层:LedgerId与具体ledgerStorage实例的动态映射,形成存储资源池
注:该设计通过索引分离和实例复用平衡性能与资源消耗
需要补充说明的是,这种"套娃"结构使得:
- 单个Bookie可同时处理多个Ledger的并发写入
- 不同Ledger可灵活配置差异化的存储策略
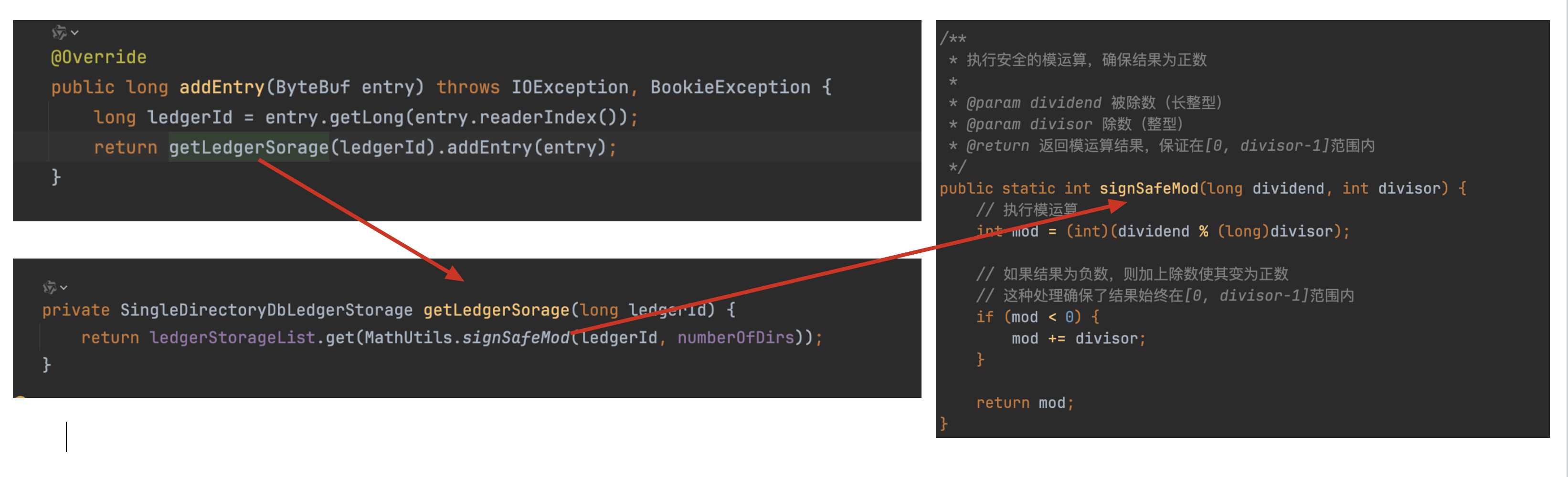
DbLedgerStorage的成员变量
public class SingleDirectoryDbLedgerStorage implements CompactableLedgerStorage {// 条目日志记录器,负责持久化存储账本条目数据private final EntryLogger entryLogger;// 账本元数据索引,管理账本的元信息(如ledgerId等)private final LedgerMetadataIndex ledgerIndex;// 条目位置索引,记录条目在存储中的位置信息,用于快速定位条目private final EntryLocationIndex entryLocationIndex;// 临时账本信息缓存,存储活跃账本的临时状态信息private final ConcurrentLongHashMap<TransientLedgerInfo> transientLedgerInfoCache;// 垃圾回收线程,负责清理无用的账本和存储空间private final GarbageCollectorThread gcThread;// 写入缓存,所有新写入的条目首先插入到这里protected volatile WriteCache writeCache;// 正在刷新的写入缓存,在缓存刷新时与writeCache进行交换protected volatile WriteCache writeCacheBeingFlushed;// 读取缓存,用于预读和缓存条目数据,提高读取性能private final ReadCache readCache;// 写缓存旋转锁,用于控制写缓存的并发访问和刷新操作private final StampedLock writeCacheRotationLock = new StampedLock();// 刷新互斥锁,确保同一时间只有一个刷新操作在进行protected final ReentrantLock flushMutex = new ReentrantLock();// 刷新触发标志,标识是否有刷新操作已被触发protected final AtomicBoolean hasFlushBeenTriggered = new AtomicBoolean(false);// 刷新进行中标志,标识当前是否有刷新操作正在进行private final AtomicBoolean isFlushOngoing = new AtomicBoolean(false);// 单线程执行器,用于处理存储相关的后台任务private final ExecutorService executor = Executors.newSingleThreadExecutor(new DefaultThreadFactory("db-storage"));// 清理执行器,用于定期执行数据库索引清理任务private final ScheduledExecutorService cleanupExecutor = Executors.newSingleThreadScheduledExecutor(new DefaultThreadFactory("db-storage-cleanup"));// 账本删除监听器列表,当账本被删除时通知相关监听器private final CopyOnWriteArrayList<LedgerDeletionListener> ledgerDeletionListeners = Lists.newCopyOnWriteArrayList();// 检查点源,用于生成和管理存储的检查点private final CheckpointSource checkpointSource;// 上一个检查点,用于跟踪存储的一致性状态private Checkpoint lastCheckpoint = Checkpoint.MIN;// 写缓存最大大小限制private final long writeCacheMaxSize;// 读缓存最大大小限制private final long readCacheMaxSize;// 预读缓存批处理大小,控制每次预读的条目数量private final int readAheadCacheBatchSize;// 最大节流时间,控制写入操作的最大等待时间private final long maxThrottleTimeNanos;// 数据库存储统计信息,收集和报告存储性能指标private final DbLedgerStorageStats dbLedgerStorageStats;// 预读缓存批处理大小配置键名static final String READ_AHEAD_CACHE_BATCH_SIZE = "dbStorage_readAheadCacheBatchSize";// 默认预读缓存批处理大小private static final int DEFAULT_READ_AHEAD_CACHE_BATCH_SIZE = 100;// 默认最大节流时间(10秒)private static final long DEFAULT_MAX_THROTTLE_TIME_MILLIS = TimeUnit.SECONDS.toMillis(10);// 最大预读字节数大小限制private final long maxReadAheadBytesSize;// ...
}
DbLedgerStorage采用异步刷盘设计,核心机制如下:
- 写入流程:entry先存入writeCache即返回成功,触发LAC更新和监听通知
- 刷盘策略:
- 异步线程定期检查刷盘条件(数据量/时间阈值)
- 同步刷盘时写入线程会阻塞等待刷盘完成
- 异常处理:put失败会强制flush后重试
- 性能优化:writeCache同时服务读写,特别在tail read场景下会有非常好的性能收益
SingleDirectoryDbLedgerStorage#addEntry()方法:
public long addEntry(ByteBuf entry) throws IOException, BookieException {long startTime = MathUtils.nowInNano();// 从entry中解析账本ID、条目ID和LAC(Last Add Confirmed)long ledgerId = entry.getLong(entry.readerIndex());long entryId = entry.getLong(entry.readerIndex() + 8);long lac = entry.getLong(entry.readerIndex() + 16);if (log.isDebugEnabled()) {log.debug("Add entry. {}@{}, lac = {}", ledgerId, entryId, lac);}// 首先尝试使用乐观读锁获取当前写缓存的访问权// 基于写缓存大约每1分钟才旋转一次的事实,大多数时候可以无干扰地并发访问long stamp = writeCacheRotationLock.tryOptimisticRead();boolean inserted = false;// 尝试将条目插入写缓存inserted = writeCache.put(ledgerId, entryId, entry);// 验证乐观锁期间写缓存是否被旋转过if (!writeCacheRotationLock.validate(stamp)) {// 如果写缓存在此期间被旋转,需要获取正式的读锁并重试插入操作// 因为可能插入到了正在被刷新和清理的写缓存中,无法确定该条目是否被正确刷新stamp = writeCacheRotationLock.readLock();try {inserted = writeCache.put(ledgerId, entryId, entry);} finally {writeCacheRotationLock.unlockRead(stamp);}}// 如果插入失败(缓存已满),触发刷新并将条目添加到新的缓存中if (!inserted) {triggerFlushAndAddEntry(ledgerId, entryId, entry);}// 成功插入条目后,更新LAC缓存并通知观察者updateCachedLacIfNeeded(ledgerId, lac);// 记录成功事件并返回条目IDrecordSuccessfulEvent(dbLedgerStorageStats.getAddEntryStats(), startTime);return entryId;}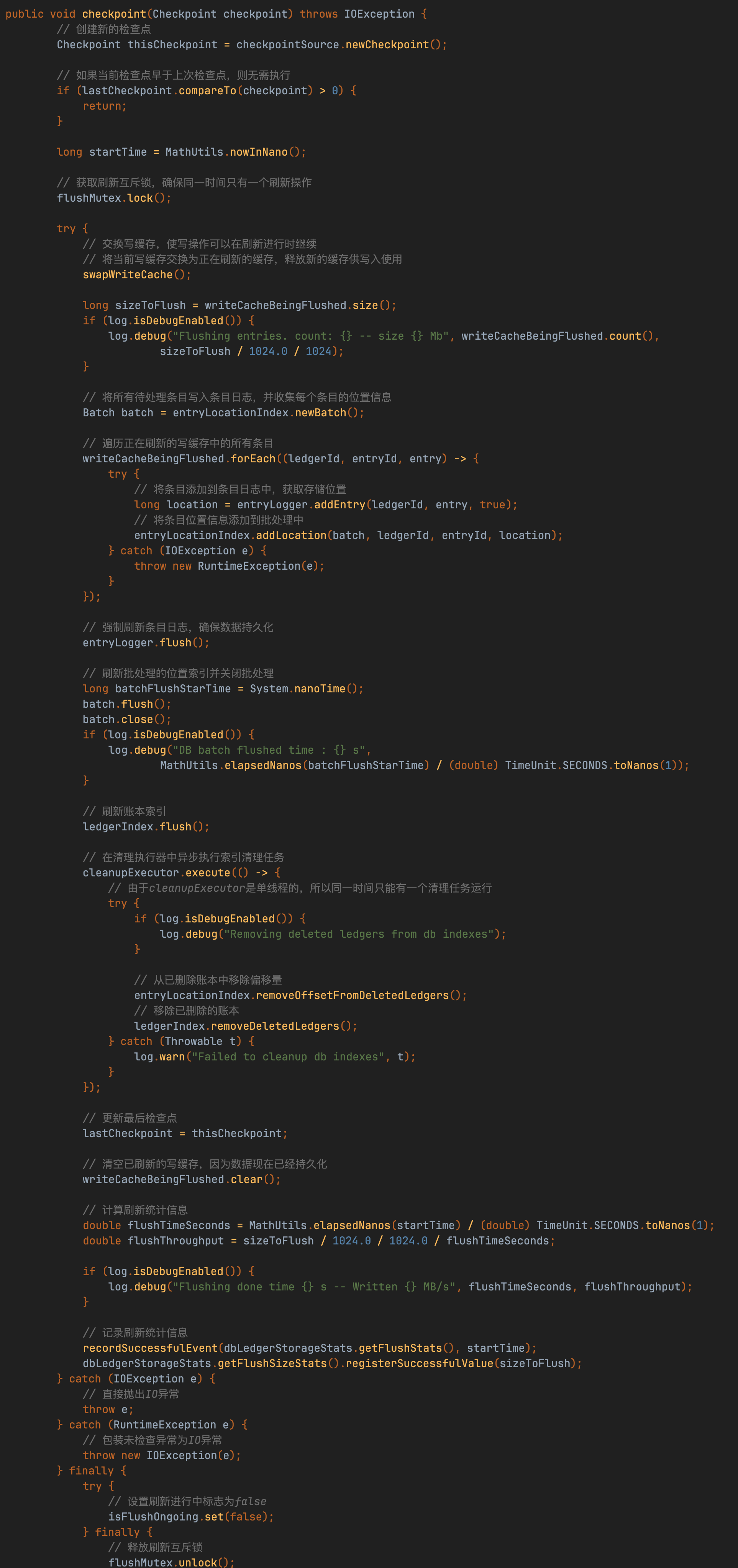
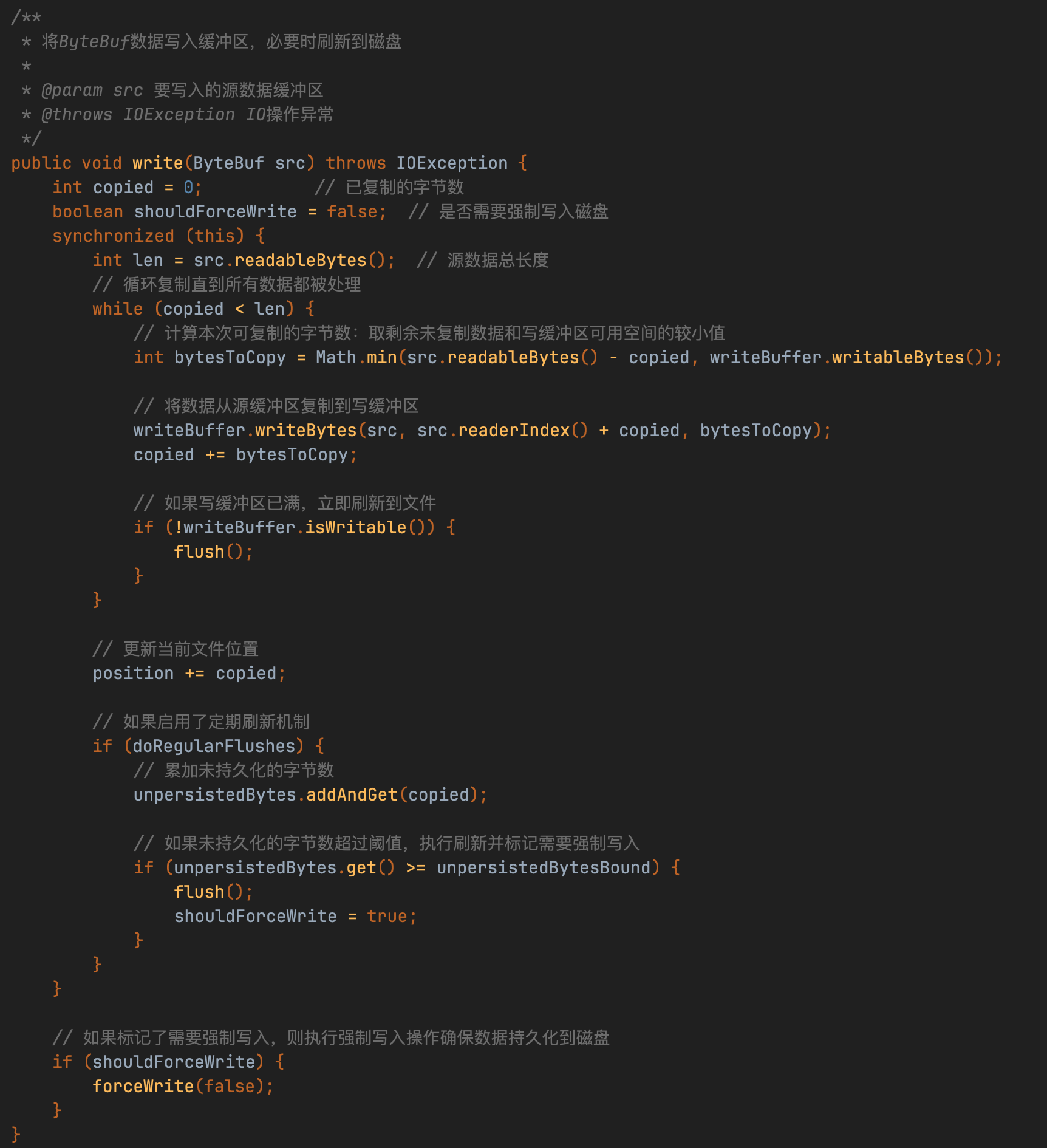
DbLedgerStorage的刷盘机制采用"双缓冲+异步持久化"设计,其核心流程可分解为:
- 内存交换
通过交换writeCache实现读写分离,确保刷盘期间写入不阻塞 - 数据预处理
对交换出的writeCache数据进行排序,形成局部有序结构(类似LSM树的MemTable处理逻辑) - 多级持久化
- 并行调用entryLog和entryIndex的add方法实现数据双写
- 最终通过flush方法完成磁盘同步(强制落盘)
该设计通过三个关键优化实现高性能:
- 写入无阻塞:内存交换避免IO争用
- 局部有序性:排序提升后续合并效率
- 并行持久化:日志和索引分开处理
EntryLocationIndex#addLocation()方法:
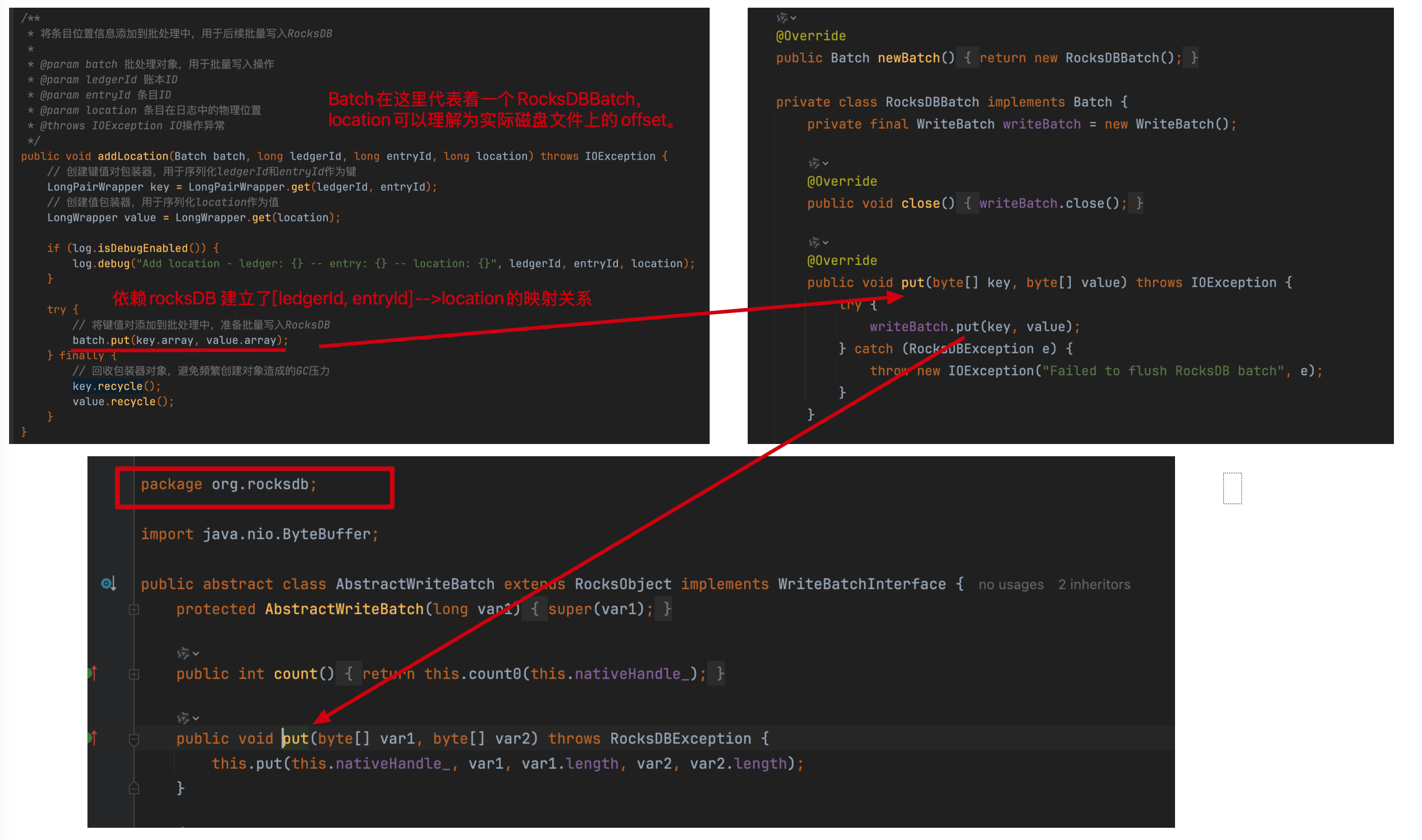
EntryLogger
EntryLogger代表着存储实际数据的组件抽象,调用addEntry(ledgerId, entry)方法完成数据写入。
继续跟addEntry方法,会发现到了底层EntryLogManagerBase#addEntry()方法里来
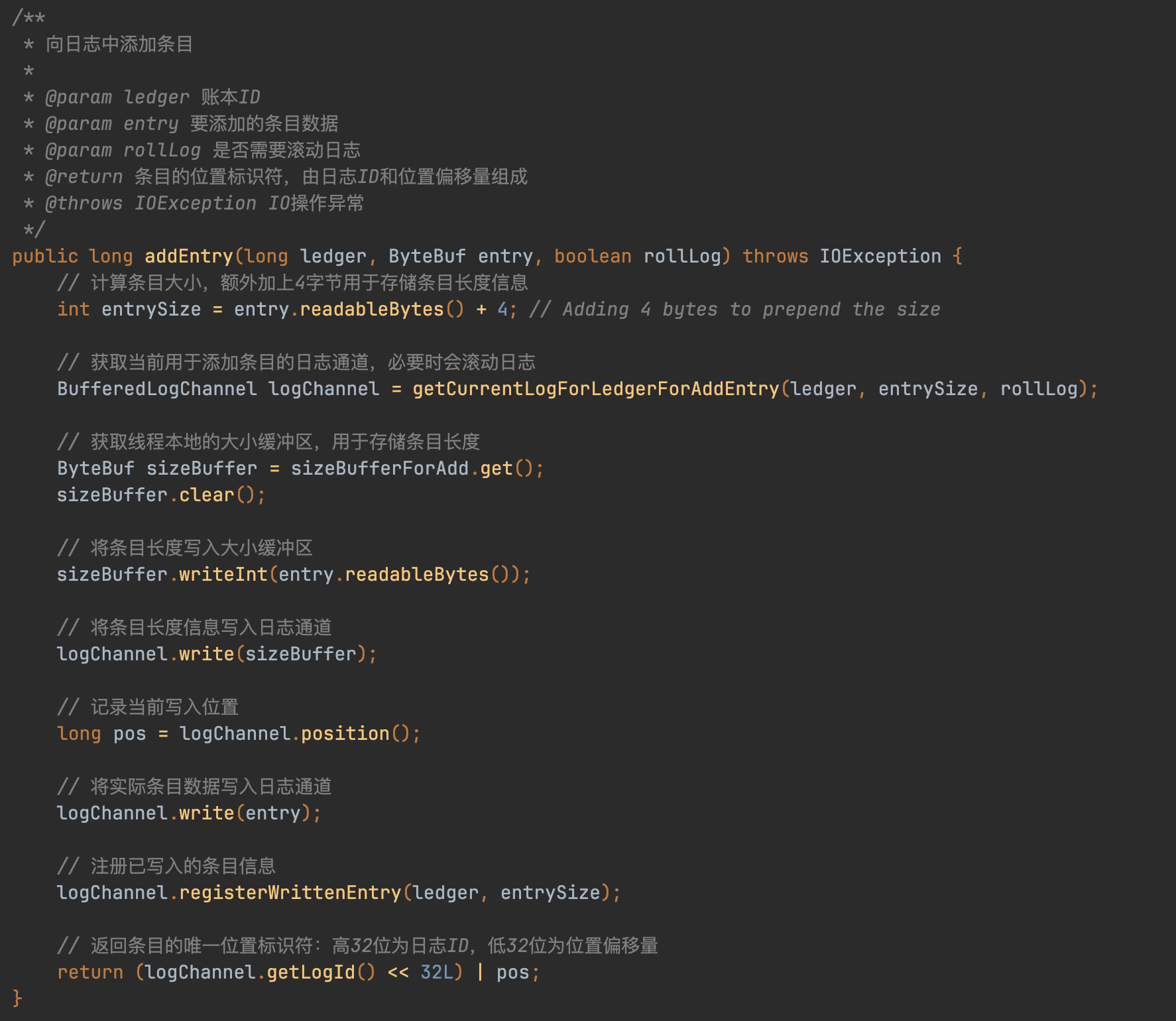
只在满足下面两种情况时数据才会刷盘:
- 写缓冲区已满时:
当 writeBuffer.isWritable() 返回 false,即写缓冲区没有可写空间时,会立即执行 flush() 将数据刷盘 - 未持久化字节数超过阈值时:
当 unpersistedBytes.get() >= unpersistedBytesBound,即累积的未持久化数据量达到预设边界值时,会执行 flush() 并标记 shouldForceWrite = true,随后调用 forceWrite(false) 强制将数据写入磁盘
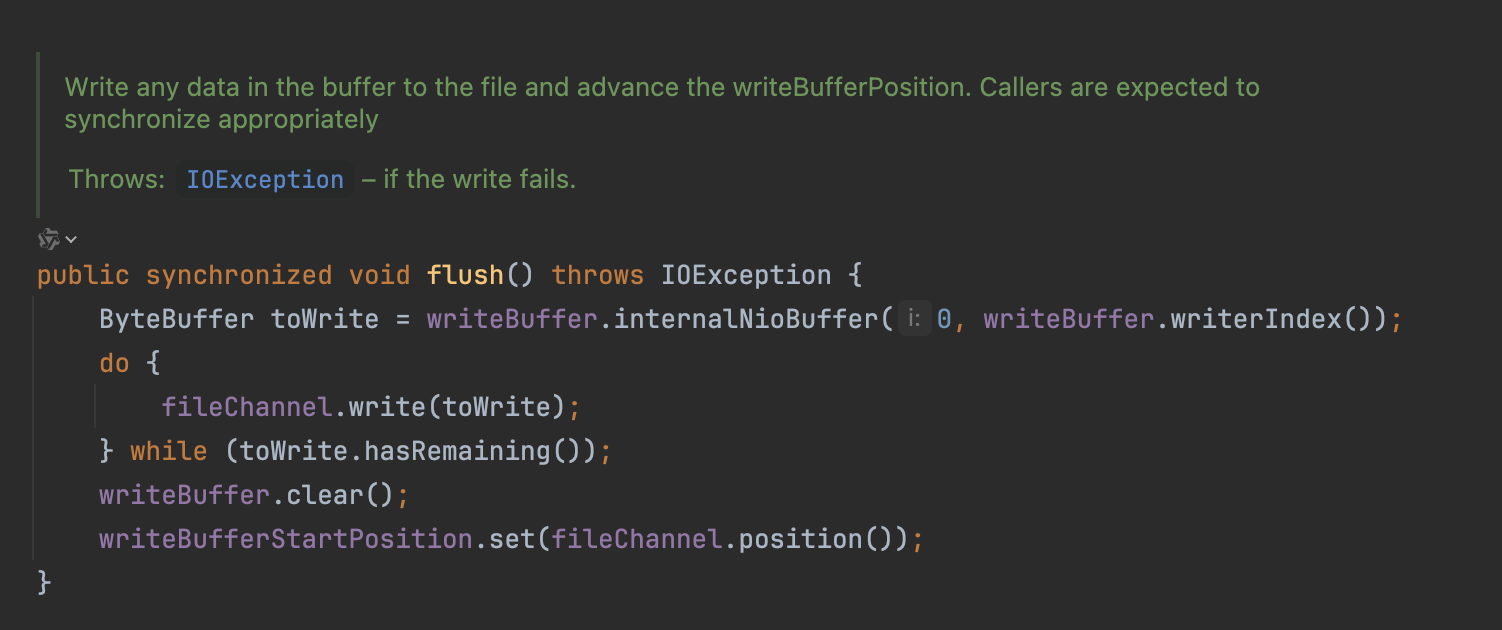
DbLedgerStorage的刷盘机制采用分层控制策略:
-
基础刷盘层
flush()仅通过FileChannel提交数据到文件系统缓冲区,不保证物理落盘。
-
强制持久化层
forceWrite()调用fileChannel.force()确保数据同步到磁盘介质
我们再来分析下Bookie采用的SortedLedgerStorage存储引擎
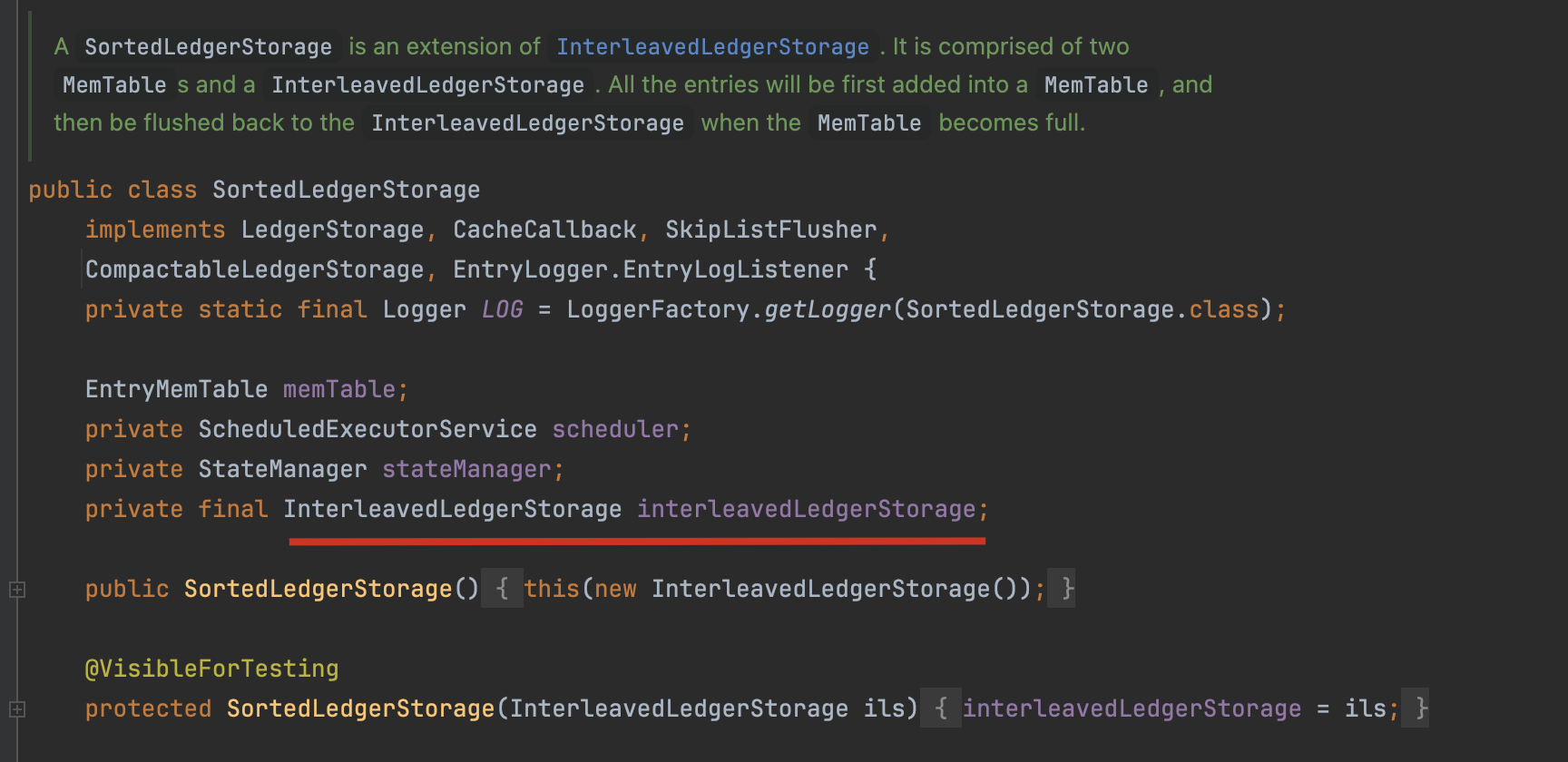
SortedLedgerStorage采用代理模式+跳表优化设计,通过InterleavedLedgerStorage代理基础存储操作(委托模式),写入时通过跳表(SkipList)维护数据有序性,相比普通链表,跳表查询效率达O(logN)。

memTable是SortedLedgerStorage类的成员变量EntryMemTable
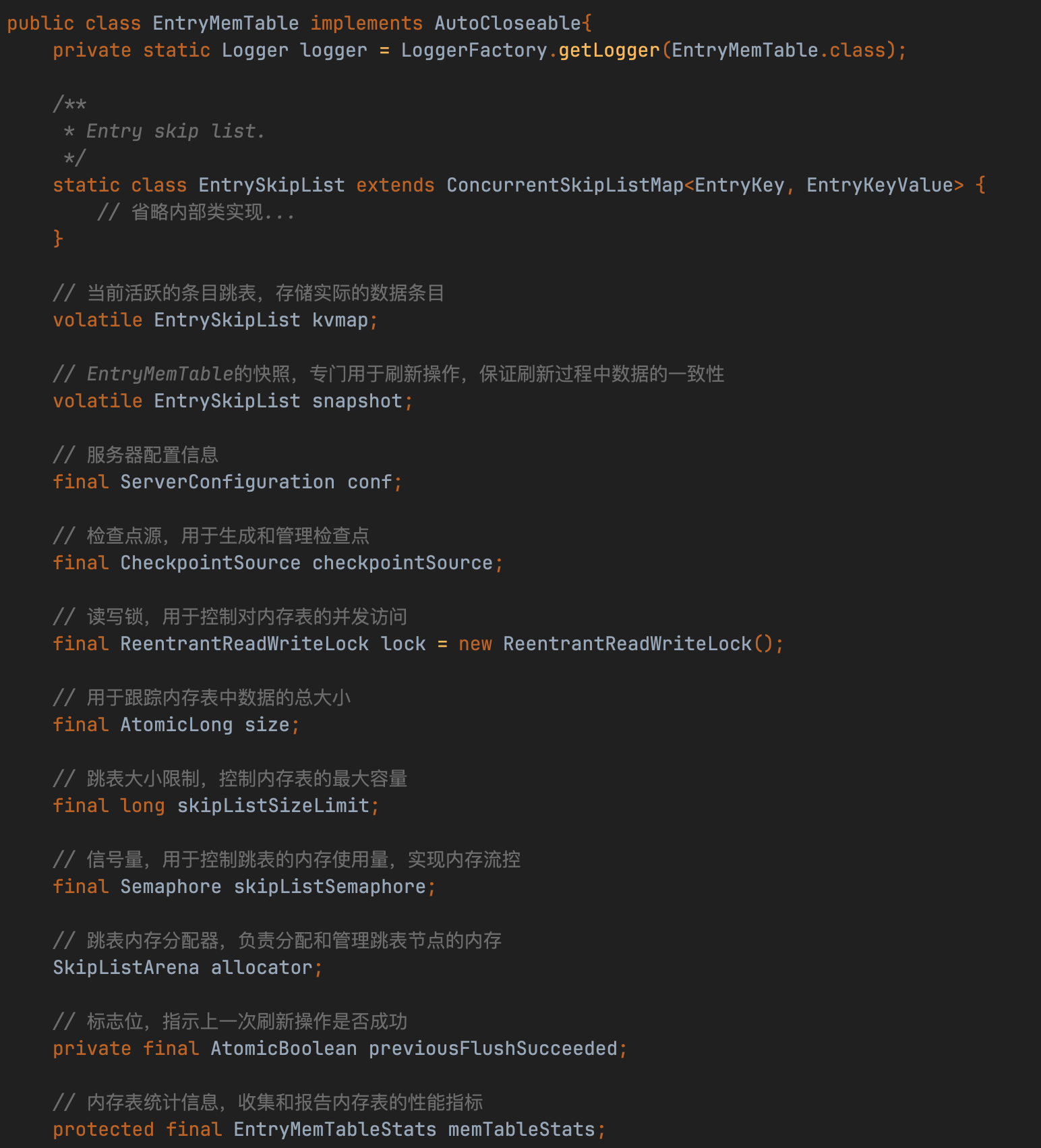
EntryMemTable采用双跳表轮换机制实现高效内存管理:
- 核心结构
- kvmap和snapshot均为EntrySkipList(基于ConcurrentSkipListMap封装)
- 自定义排序规则:优先比较LedgerId,其次EntryId
- 工作流程
- 写入阶段:数据写入kvmap(默认64M容量)
- 交换触发:kvmap写满后与snapshot原子交换
- 异步刷盘:后台线程处理snapshot数据持久化
- 性能保障
- 双缓冲设计支持128M峰值写入(64M×2)
- 跳表结构保证O(logN)查询效率
(注:类似Kafka的PageCache设计思想)
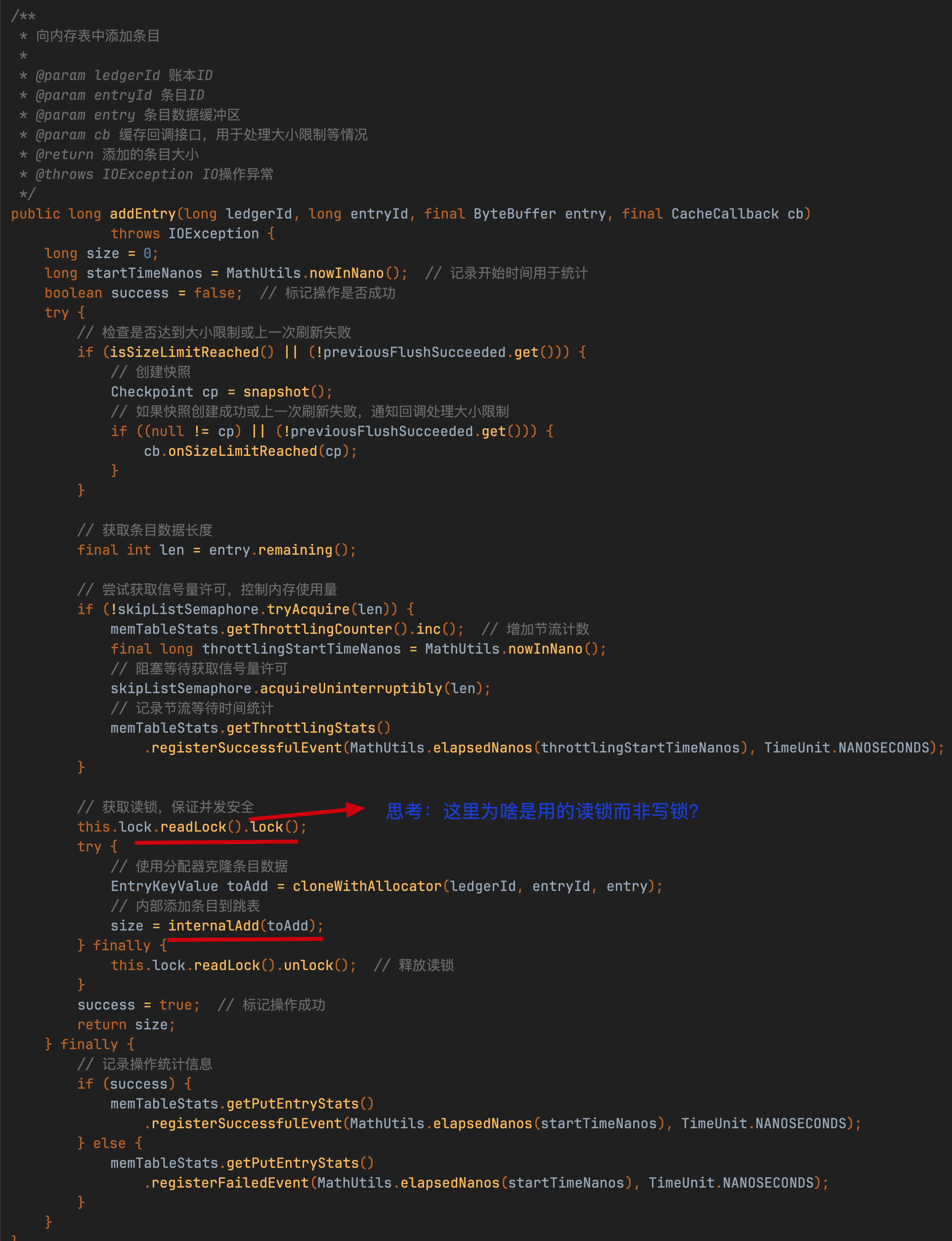
图片中的思考你停一两分钟思考下再往下看,我这里假装你思考好了。
EntryMemTable的写入操作使用读锁而非传统写锁,核心原因在于其内部依赖ConcurrentSkipListMap的线程安全机制实现并发控制,读取锁仅作为轻量级屏障以减少竞争开销,而非实际数据保护。
关键设计原理:
- 底层数据结构保证原子性
- kvmap(基于跳表封装)的putIfAbsent方法自身通过CAS等无锁技术确保操作的线程安全
,因此无需通过写锁额外加锁。
- kvmap(基于跳表封装)的putIfAbsent方法自身通过CAS等无锁技术确保操作的线程安全
- 读写锁的优化策略
- 读取锁允许多线程并发写入kvmap,避免了写锁导致的线程阻塞。
- 当kvmap写满并触发与snapshot的交换时,需短暂升级为写锁保证原子交换,但写入阶段仅需读锁即可维持高吞吐。
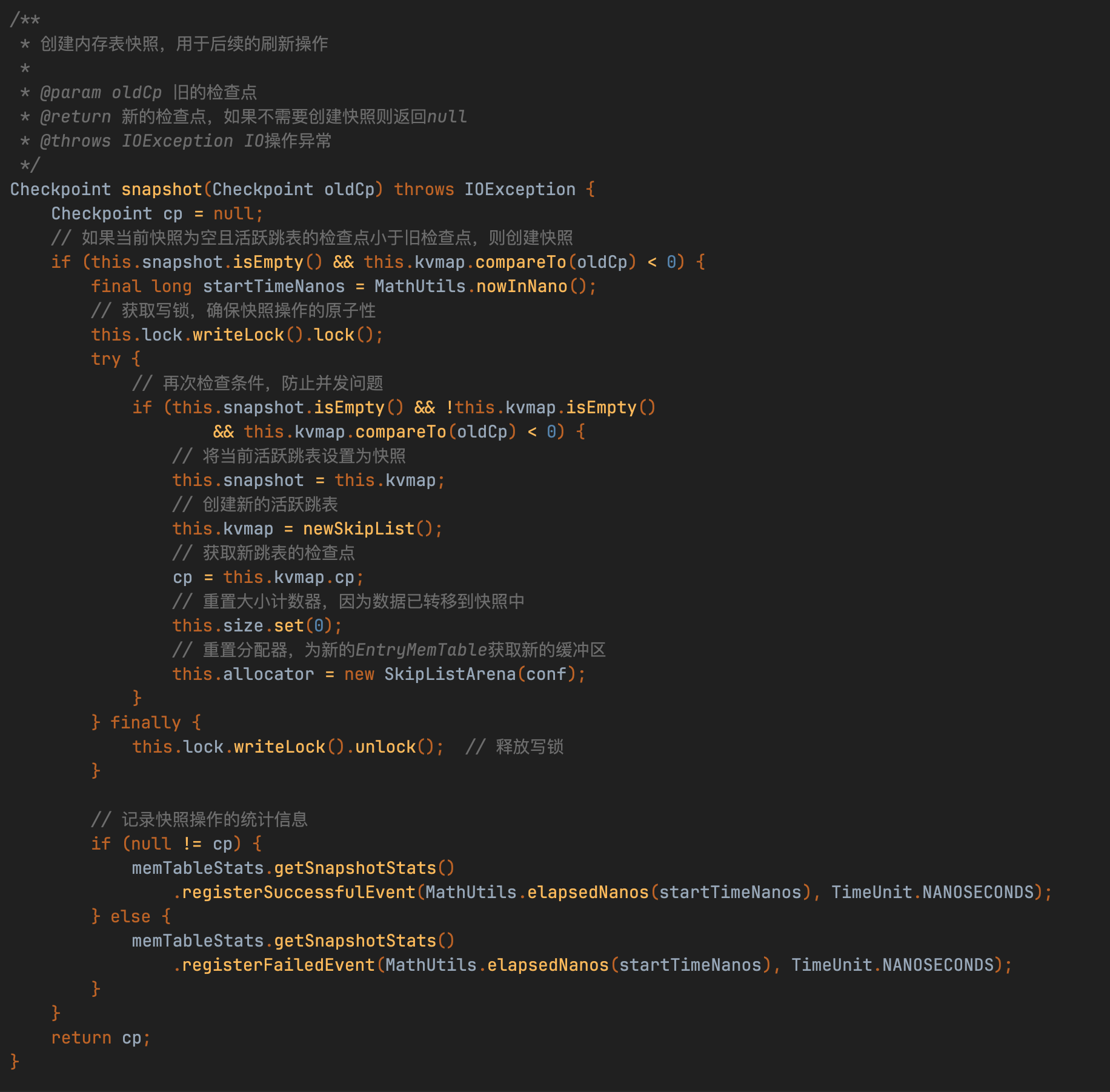
EntryMemTable的刷盘机制通过读写锁隔离关键操作:刷盘前获取写锁创建快照(交换kvmap与snapshot引用),此时阻塞写入操作确保数据一致性;刷盘线程处理完快照数据后再次加写锁清理旧数据。整个过程通过读锁(常规写入)与写锁(快照操作)的交替使用,在保证线程安全的同时最大化并发性能。
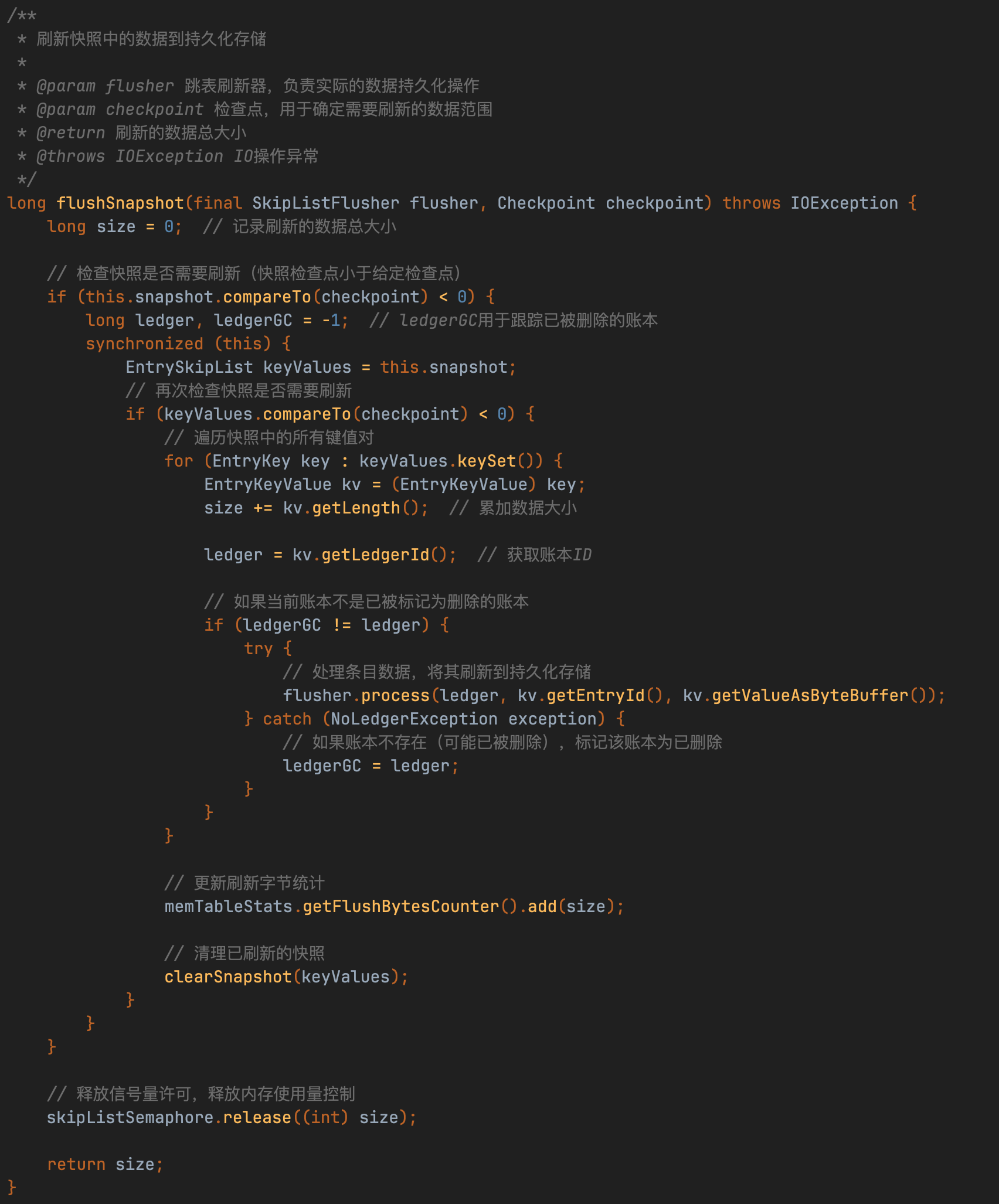
SortedLedgerStorage#process() ——> InterleavedLedgerStorage#processEntry()
EntryMemTable的flushSnapshot操作本质上是将内存数据通过SortedLedgerStorage中转至InterleavedLedgerStorage组件,而非直接落盘。该过程通过调用processEntry方法实现数据流转,但最终磁盘持久化由存储引擎异步完成。
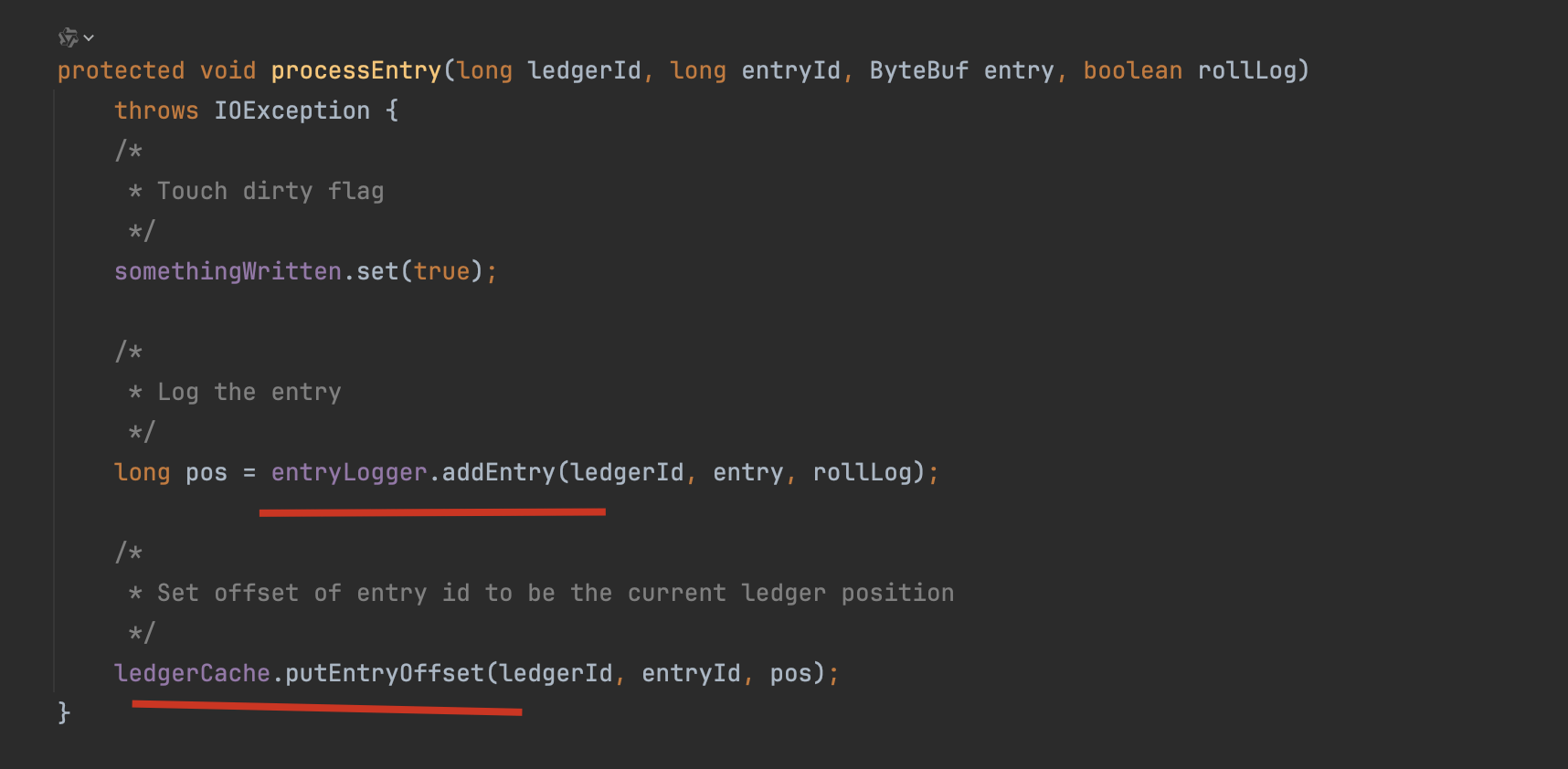
继续看ledgerCache.putEntryOffset()方法
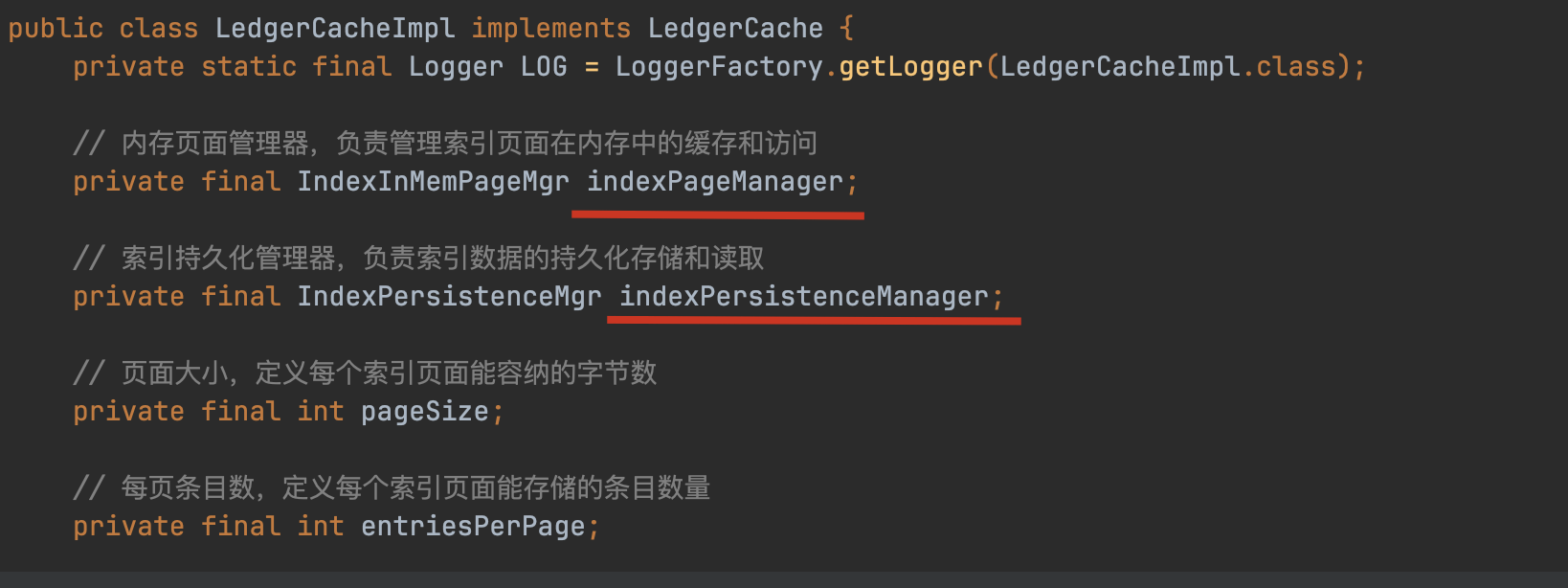
LedgerCacheImpl通过双组件架构实现索引管理:IndexInMemPageMgr负责内存缓存,采用8K页大小和1K条目/页的LRU结构;IndexPersistenceMgr处理磁盘持久化,通过entryId模运算定位页内偏移量,实现内存优先加载策略。
内存页管理采用InMemPageCollection缓存LedgerEntryPage对象,未命中时触发grabLedgerEntryPage磁盘加载,这种分层设计有效平衡性能与持久化需求。Bookie的页抽象与操作系统页机制隔离,形成独立的存储管理单元。
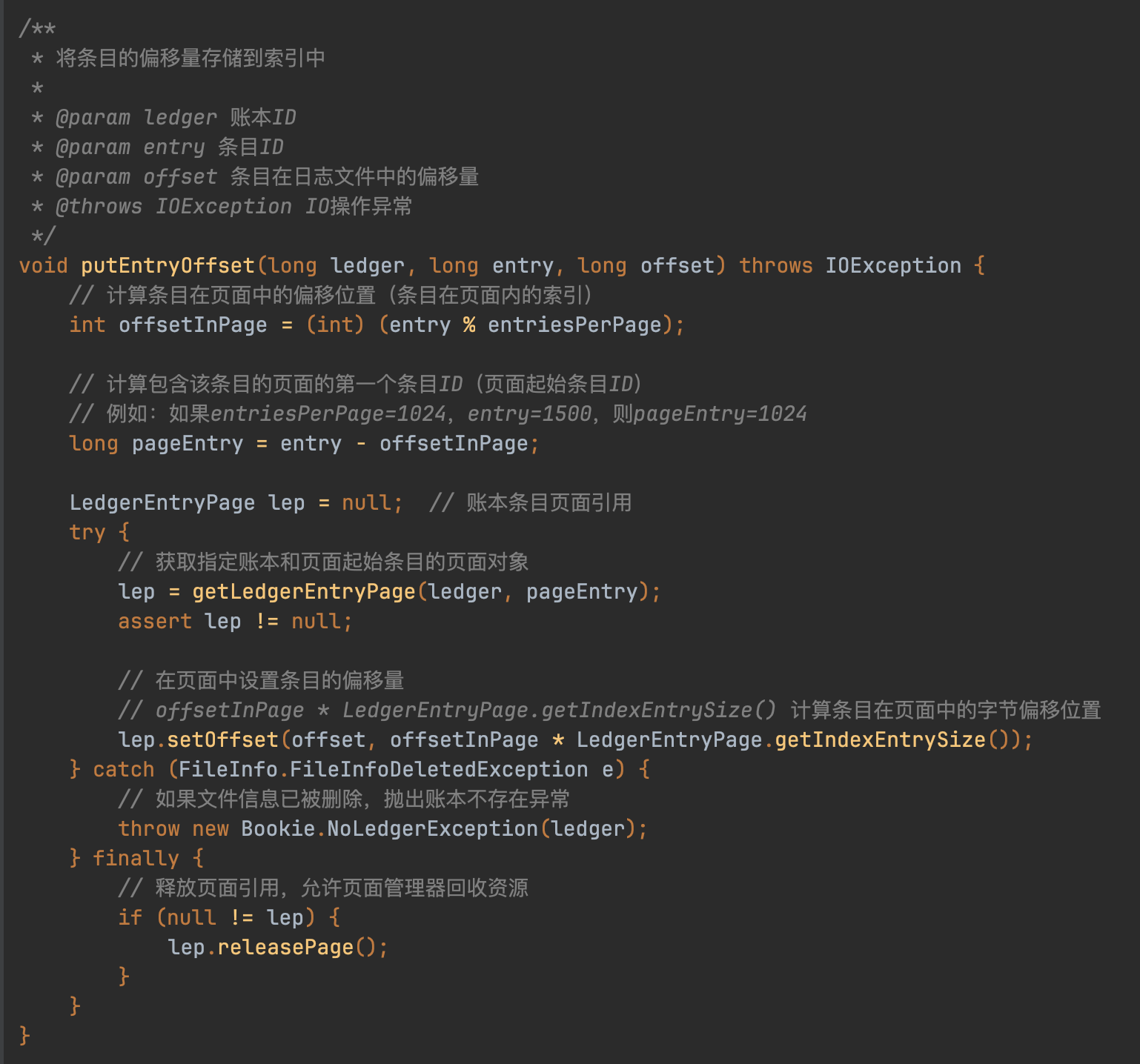
LedgerCache的读取流程通过双级定位实现:首先根据LedgerId和entryId确定目标LedgerEntryPage,再通过页内偏移计算获取物理位置参数。该机制延续了写入时的内存优先策略,内存未命中时触发磁盘加载,保持索引查询的高效性。
顺序写入的WAL日志:Journal
Journal日志写入采用混合Ledger模式,通过hash算法确保相同LedgerId始终路由到固定journal处理。logAddEntry核心逻辑包含引用计数维护、队列统计和内存限速三步骤,最终将数据压入内存队列。
后台线程通过run方法持续消费队列,takeAll/pollAll方法负责批量提取待刷盘数据,形成生产-消费闭环。该设计通过异步化处理实现高吞吐,内存队列作为缓冲层有效解耦实时写入与磁盘IO操作。
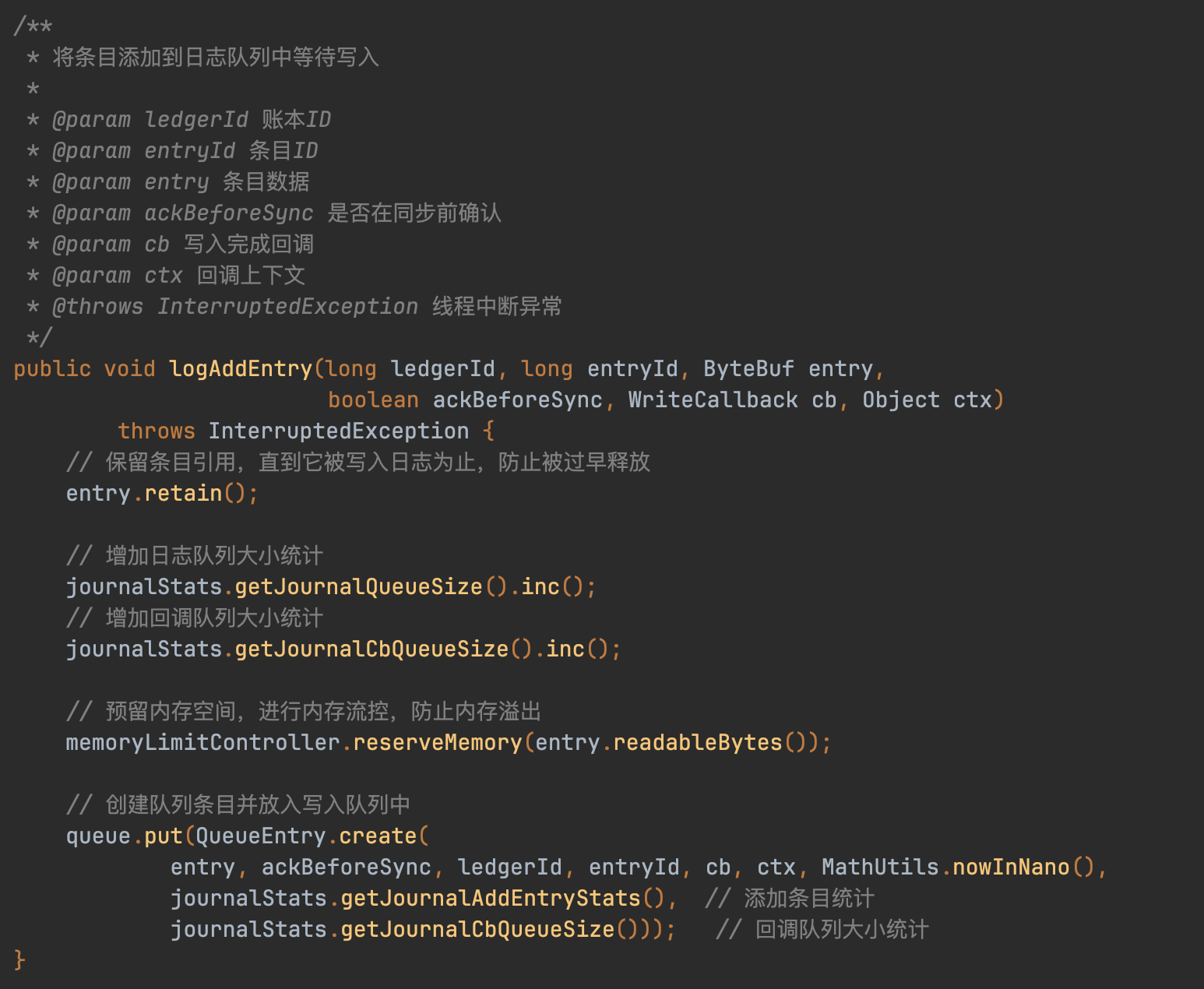
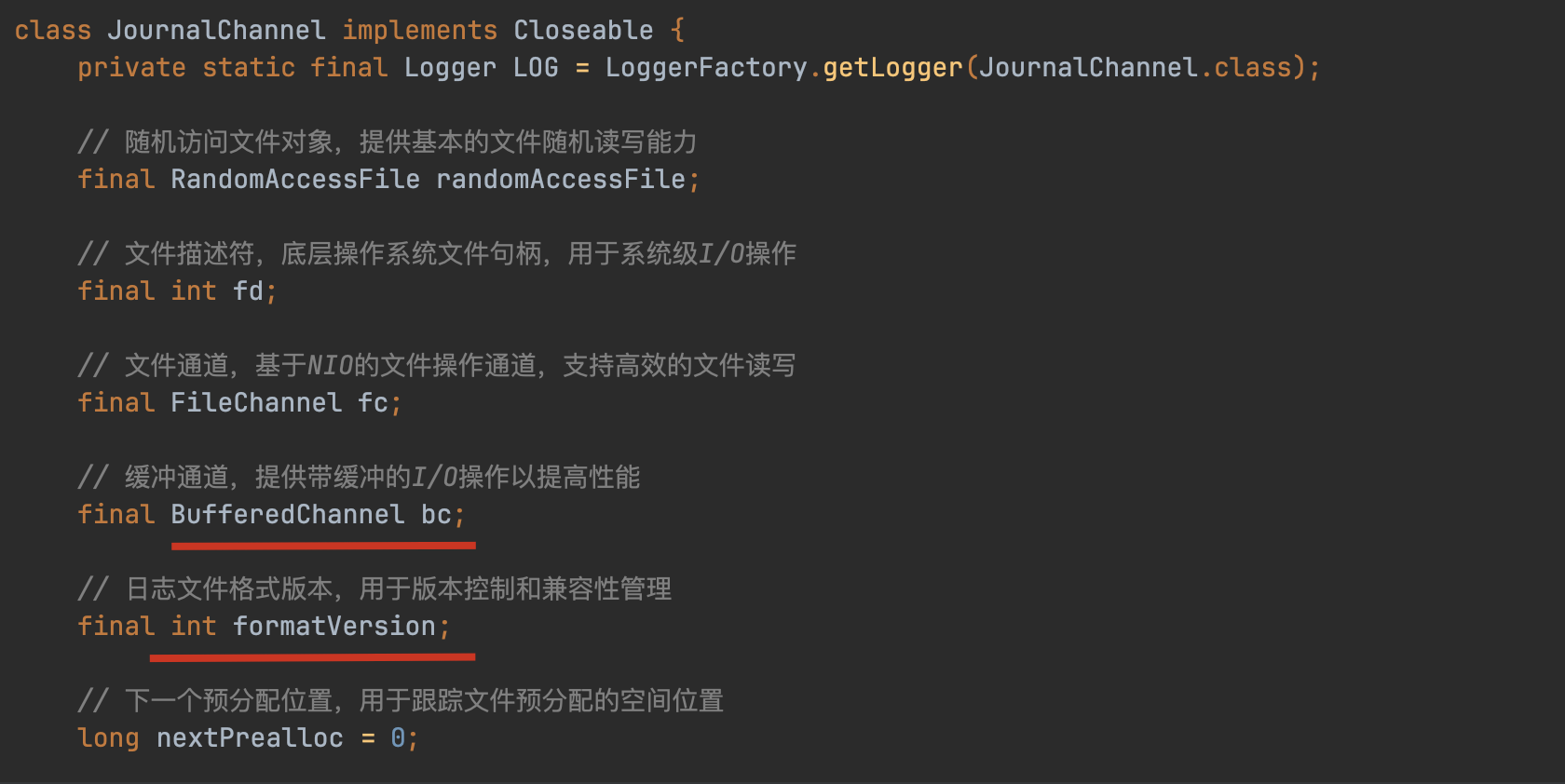
Journal部分成员变量含义:
// 日志文件最大大小限制
final long maxJournalSize;// 日志文件预分配大小,用于提高写入性能
final long journalPreAllocSize;// 日志文件写入缓冲区大小
final int journalWriteBufferSize;// 保留的备份日志文件数量
final int maxBackupJournals;// 日志文件存储目录
final File journalDirectory;// 服务器配置信息
final ServerConfiguration conf;// 强制写入线程,负责将数据强制刷新到磁盘
final ForceWriteThread forceWriteThread;// 最大分组等待时间,超过此时间后停止分组并触发刷新
private final long maxGroupWaitInNanos;// 缓冲条目阈值,超过此数量时刷新缓冲的日记条目
private final long bufferedEntriesThreshold;// 缓冲写入阈值,超过此字节数时刷新缓冲的日记写入
private final long bufferedWritesThreshold;// 队列为空时是否应该刷新
private final boolean flushWhenQueueEmpty;// 强制写入后是否应该提示文件系统从缓存中移除页面
private final boolean removePagesFromCache;// 要写入的日志格式版本
private final int journalFormatVersionToWrite;// 日志对齐大小,用于优化存储
private final int journalAlignmentSize;// 控制PageCache刷新间隔,当syncData禁用时减少磁盘IO使用
private final long journalPageCacheFlushIntervalMSec;// 数据在触发回调前是否应该fsync到磁盘
private final boolean syncData;// 最后日志标记,记录最后处理的日志位置
private final LastLogMark lastLogMark = new LastLogMark(0, 0);// 默认最后标记文件名
private static final String LAST_MARK_DEFAULT_NAME = "lastMark";// 最后标记文件名
private final String lastMarkFileName;// 用于处理回调的线程池
private final ExecutorService cbThreadPool;// 提交的日志条目队列
final BlockingQueue<QueueEntry> queue;// 强制写入请求队列
final BlockingQueue<ForceWriteRequest> forceWriteRequests;// 运行状态标志
volatile boolean running = true;// 账本目录管理器
private final LedgerDirsManager ledgerDirsManager;// 字节缓冲区分配器
private final ByteBufAllocator allocator;// 内存限制控制器,用于控制内存使用
private final MemoryLimitController memoryLimitController;// 日志统计信息,用于监控和暴露统计指标
private final JournalStats journalStats;
public class Journal extends BookieCriticalThread implements CheckpointSource
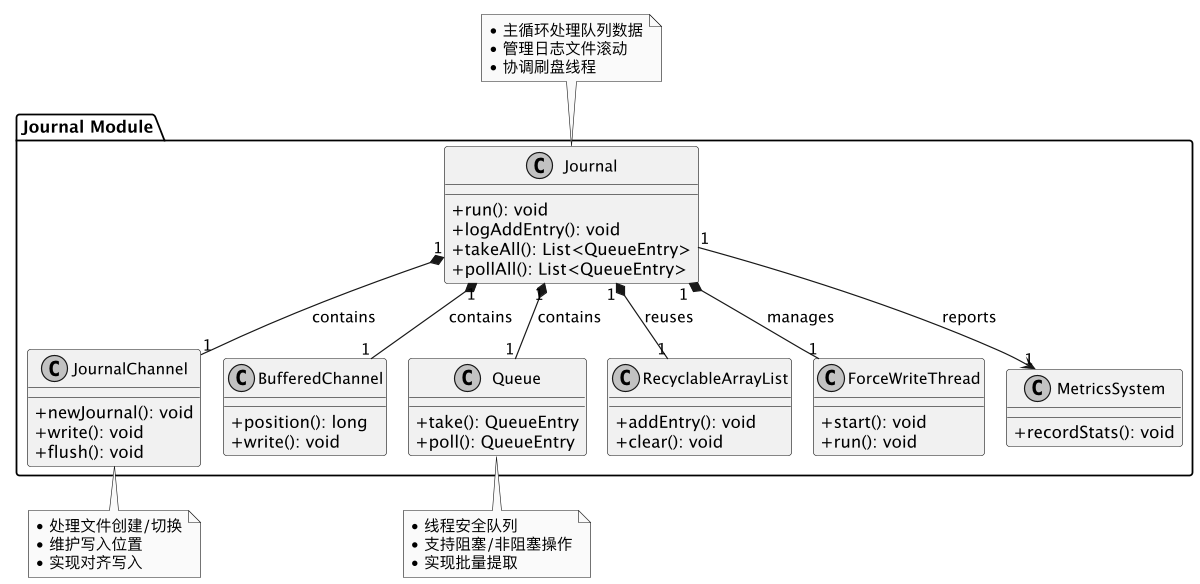
看这个类的签名就知道了,Journal继承自BookieCriticalThread,嚯,Thread结尾,大概就知道其中的奥妙了。跟进去看BookieCriticalThread的UML图如下:
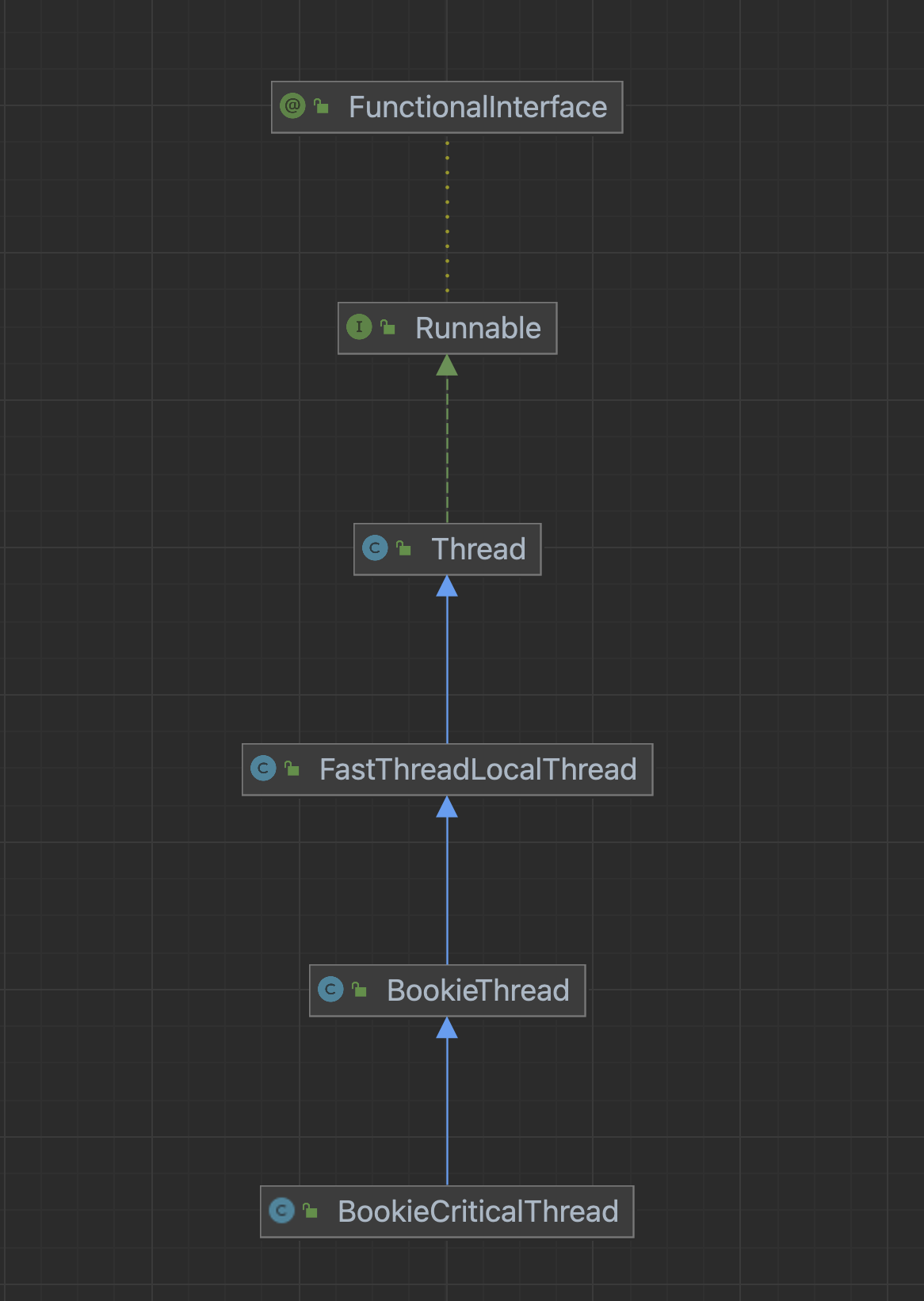
Journal模块采用线程化设计,将日志持久化与文件滚动机制整合在run方法中。当journal文件达到阈值时,基于时间戳创建新文件,旧文件进入回收流程,实现存储空间的动态管理。该设计通过单线程顺序写入保障数据一致性,文件滚动机制则确保日志可扩展性。
这么看journal既是顺序写入日志逻辑的抽象也是后台的刷盘线程的抽象
我们重点来看下后台的刷盘线程,在org.apache.bookkeeper.bookie.Journal#run
这段代码有点长,老周这里就不贴出来了。主要的逻辑如下:
1.线程分工机制
- forceWriteThread作为核心刷盘线程,负责数据持久化到物理磁盘
- journal线程仅负责内存级操作:将QueueEntry对象写入FileChannel缓冲区,不保证磁盘同步
2.批处理写入流程
- 从队列获取QueueEntry对象组存入localQueueEntries数组
- 通过BufferedChannel#write将有效数据(通过entryId/版本校验)写入内存缓冲区
- 将处理后的对象加入toFlush队列并递增numEntriesToFlush计数器
3.刷盘触发条件
- 基础条件:numEntriesToFlush>0且满足以下任一情况:
- 当前处理对象qe为空或超时(maxGroupWaitInNanos)
- 队列空且flushWhenQueueEmpty启用
- 对象数量超过bufferedEntriesThreshold
- 位点间隔超过bufferedWritesThreshold
4.刷盘执行阶段
- 调用BufferedChannel#flush将缓冲数据提交至OS文件系统
- 底层通过FileChannel#write实现系统调用
- 重置toFlush索引和计数器,触发回调逻辑,更新lastFlushPosition
5.强制刷盘提交
- 提交条件:
- syncData全局开关启用
- 需要滚动创建新journal文件
- 距上次刷盘超过journalPageCacheFlushIntervalMSec阈值
- 封装toFlush对象为请求提交至forceWriteThread
- 更新lastFlushTimeMs时间戳
当真实刷盘请求被提交到forceWriteThread线程后,我们可以来看下该线程的核心工作流程:
接收刷盘请求后,首先解包请求数据,随后调用底层syncJournal方法执行强制刷盘操作。过程中会复用localRequests临时数组优化内存使用,并在刷盘完成后执行资源回收、触发回调通知及更新统计指标。整个设计通过职责分离(内存操作与磁盘IO分离)和资源复用机制,在保证数据持久化的同时兼顾系统性能。
核心代码实现在 org.apache.bookkeeper.bookie.Journal.ForceWriteThread#run
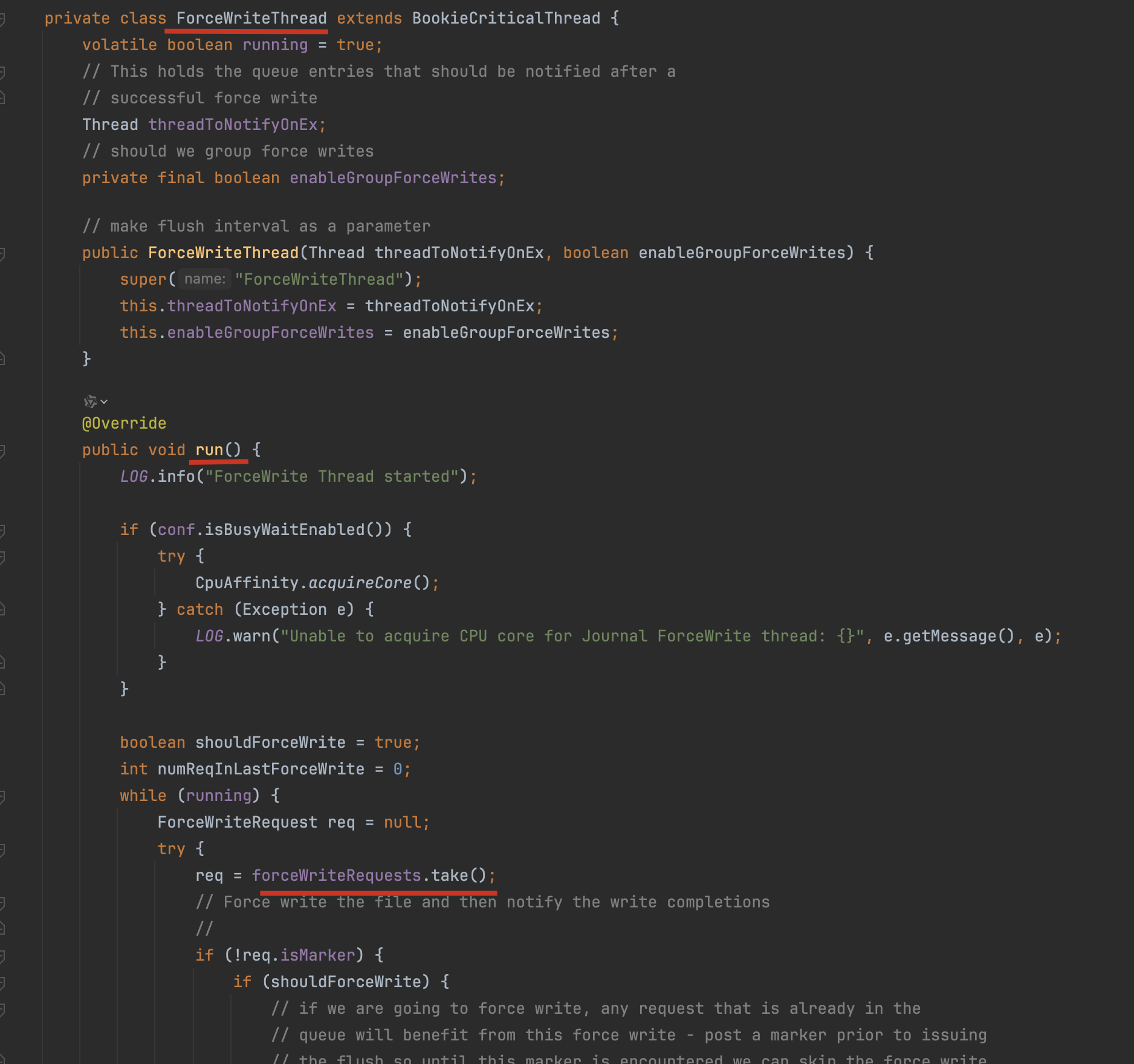
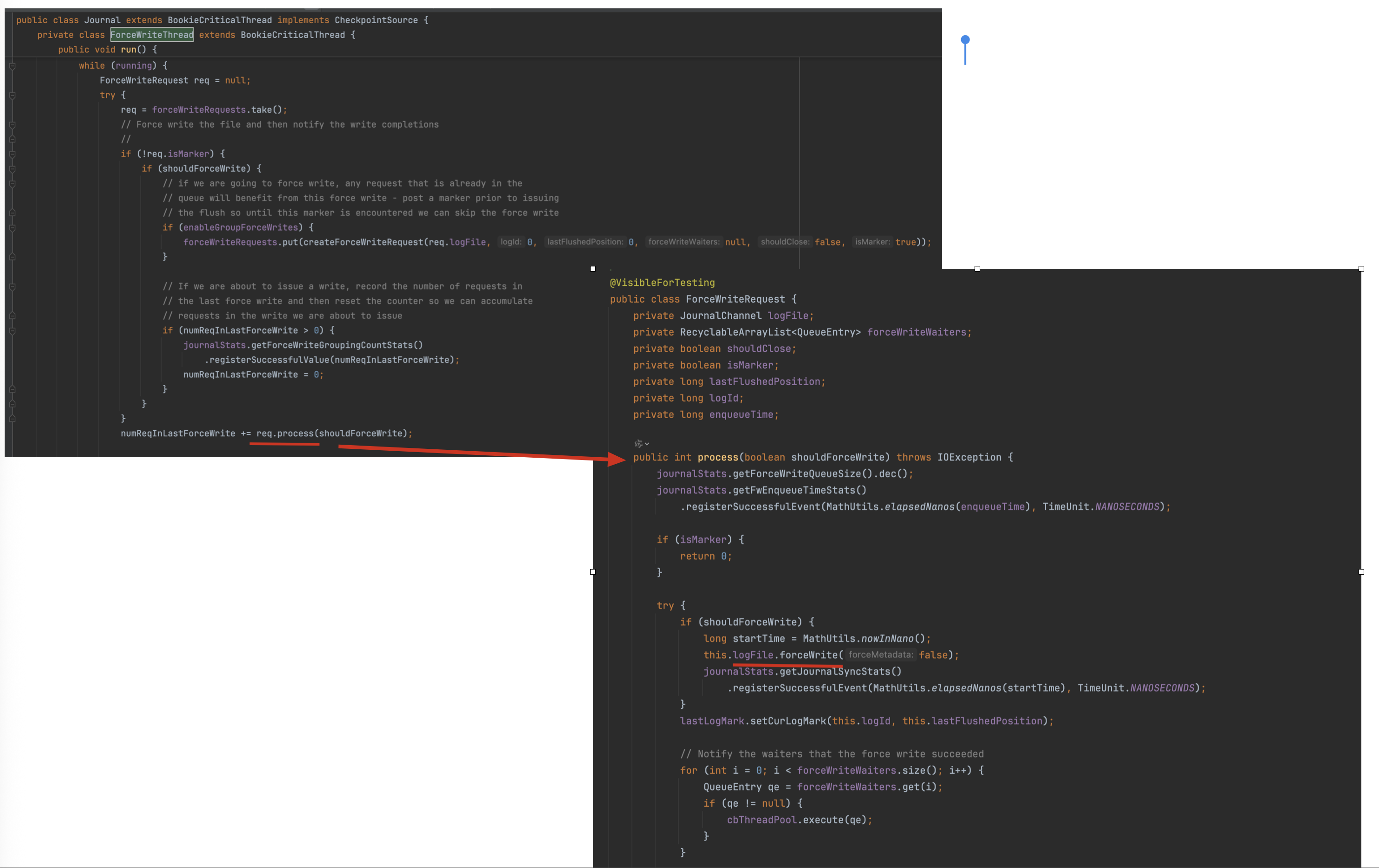
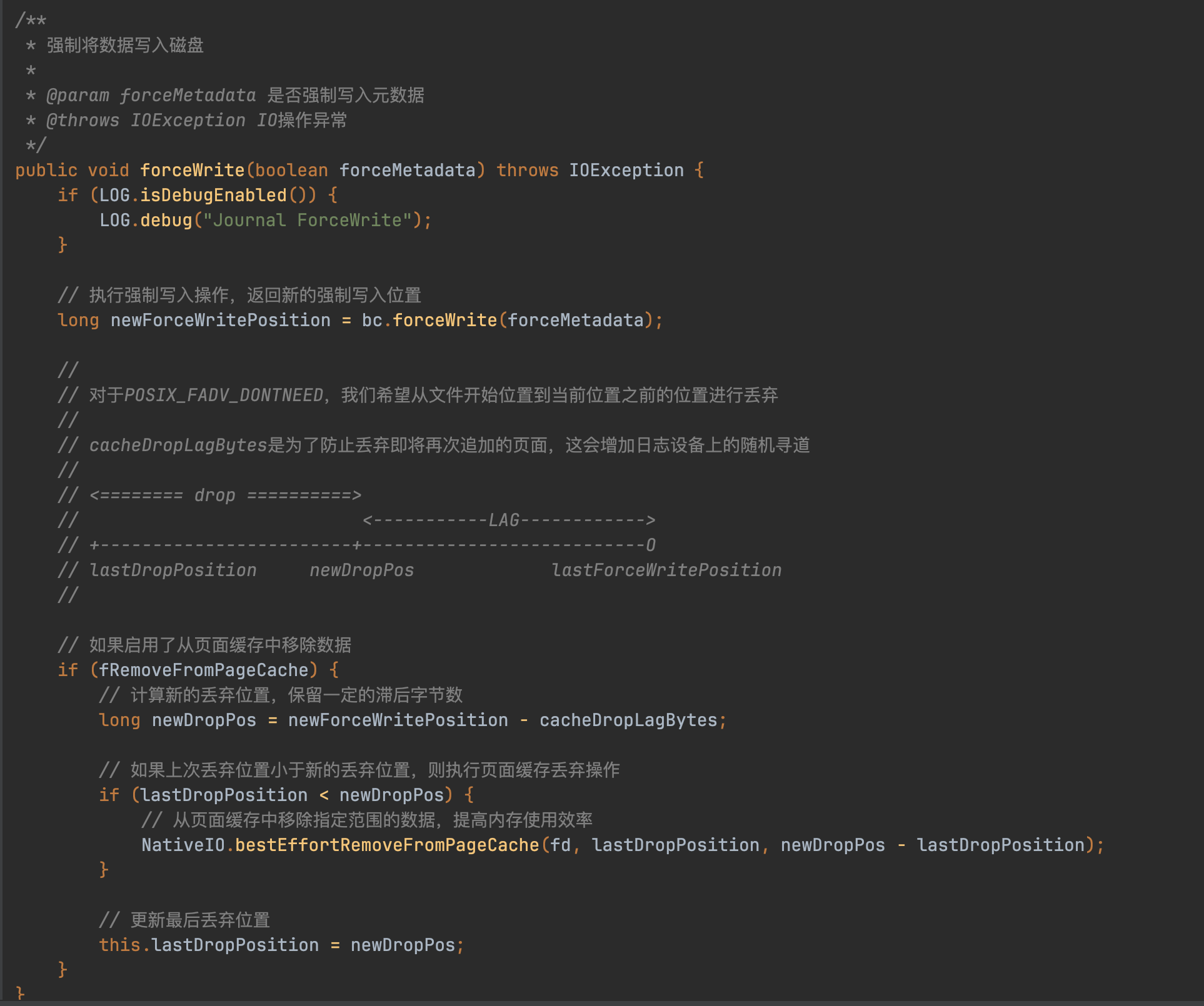
跟进去发现是在JournalChannel类
Journal的主要UML图:
server端时序图:
基于篇幅的原因,老周把Bookie的数据读取流程和BookKeeper的存储架构分析放到下篇去讲,敬请期待。