详解flink java基础(一)
文章目录
- 1.流式处理flink介绍
- 2.Flink SQL介绍
- 3. Flink Runtime
- 4.使用flink集成kafka
- 5.使用Flink SQL进行有状态流处理
- 6.Event time & Watermarks
- 7. flink Checkpoints & recovery
1.流式处理flink介绍
实时服务依赖流式处理:
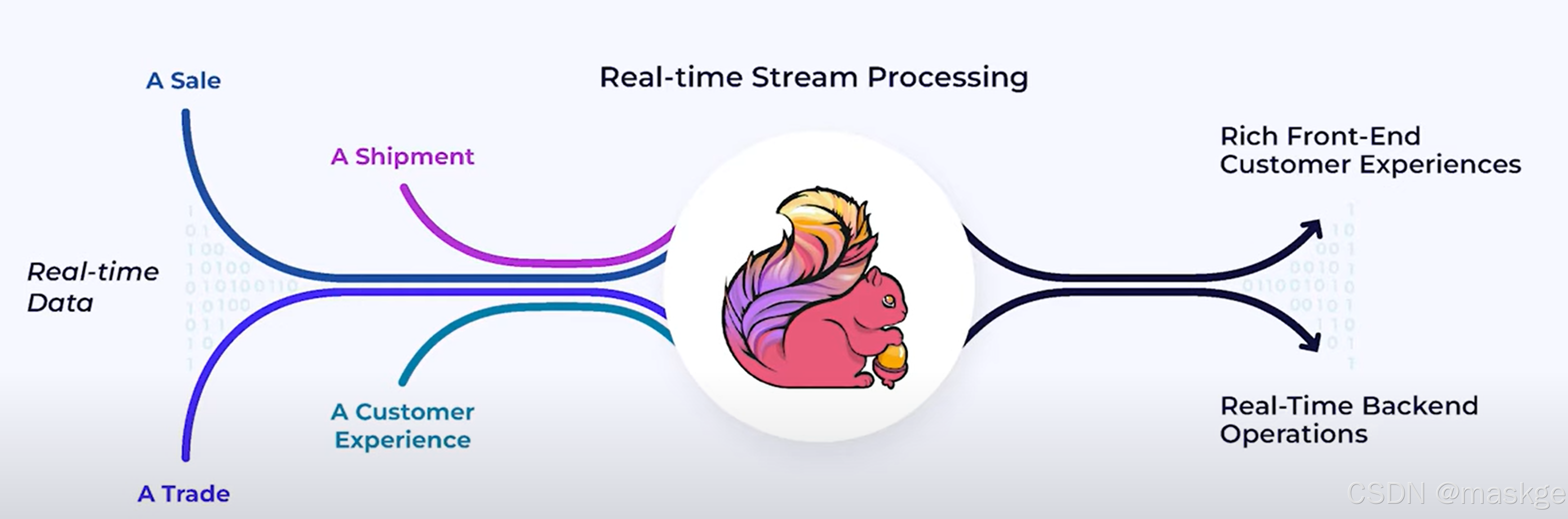
flink优点:
- 高性能
- 丰富的特性:

构建flink的4个基础:

Streaming:
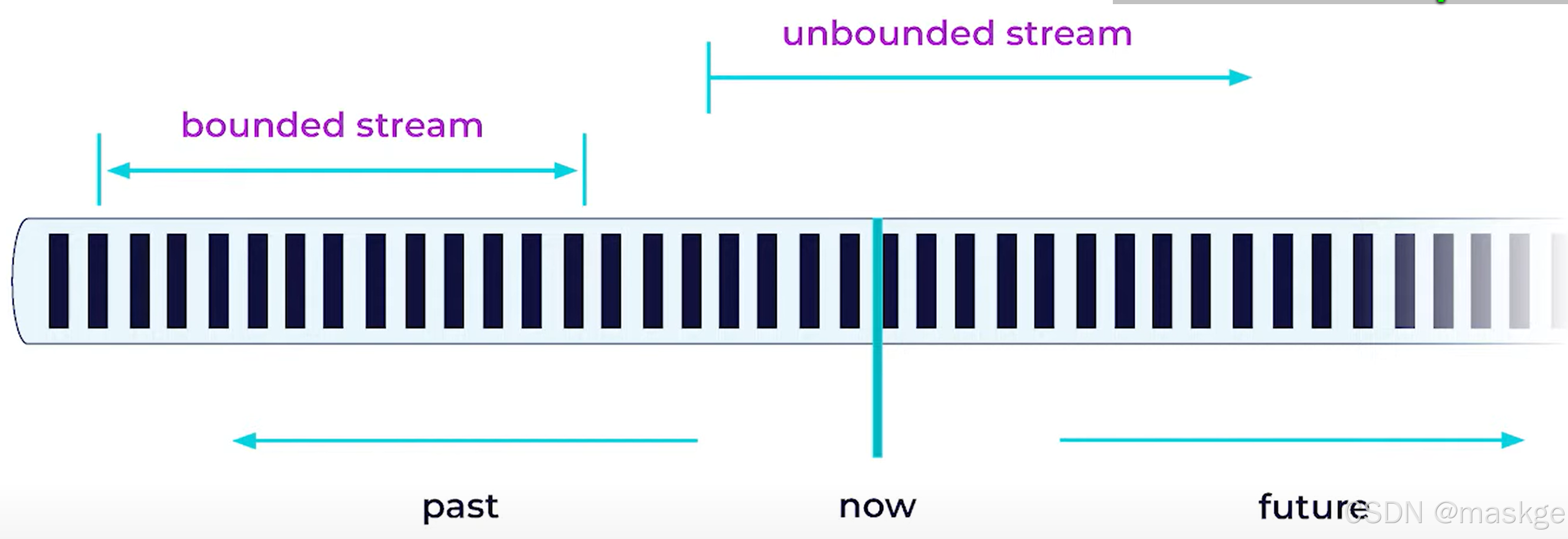
- 流是有序的事件
- 业务数据总是一个流:有界流 或无界流
- 对于flink,批处理仅是一个特殊的场景,在流运行时
The job Graph(Topology):- 运行中的flink 应用称作job
- 运行中的flink应用(job)以及通过数据管道处理称作JobGraph(工作图)
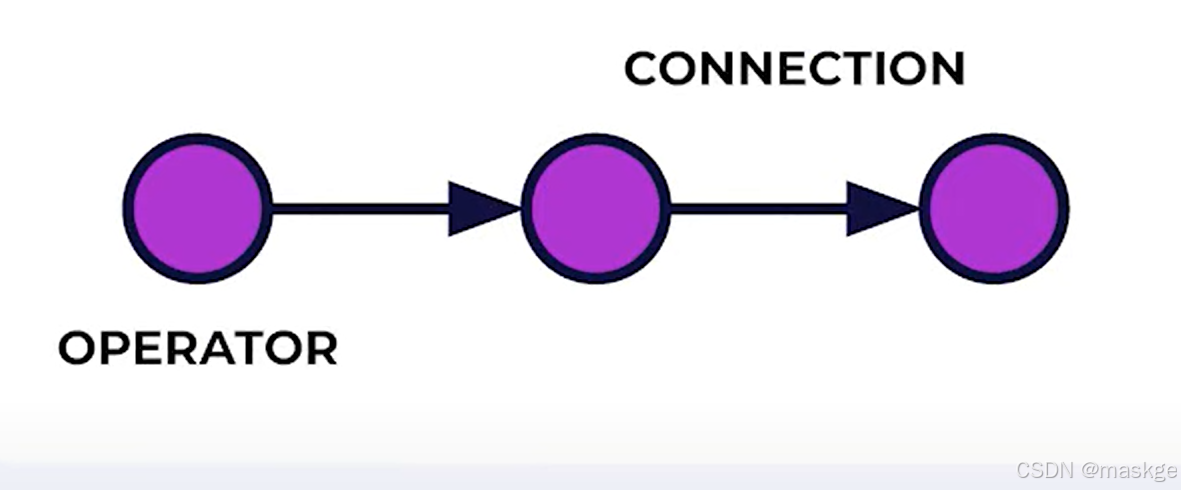
- Job Graph是一个有向图(DAG),数据流从source流向sink,被operator处理
Stream processing:
-
Parallel:是由于分隔事件流成并行sub-stream,各自可以独立处理
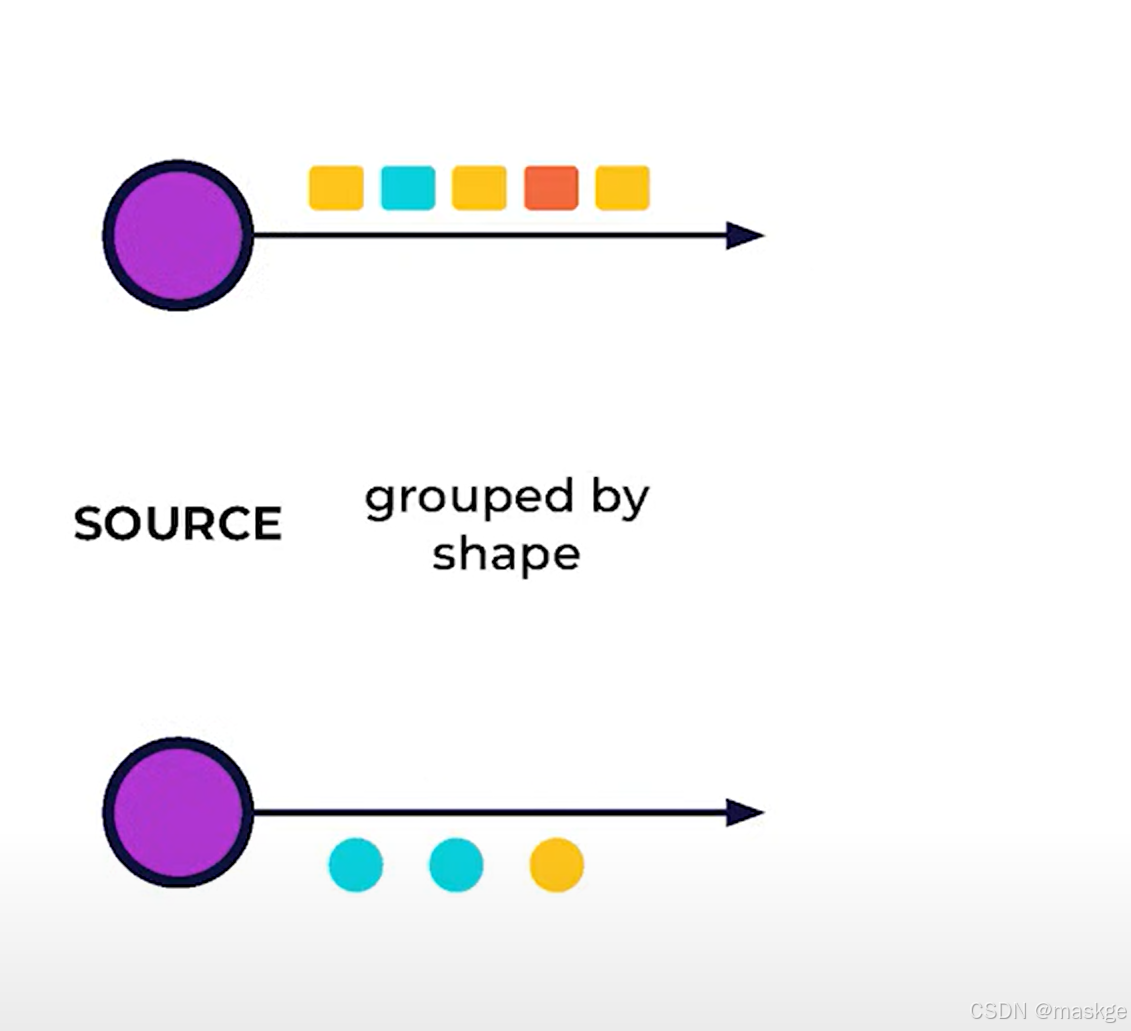
-
Forward:重定向一个事件流,优化上下游衔接非常有效
-
Repartition(分隔)
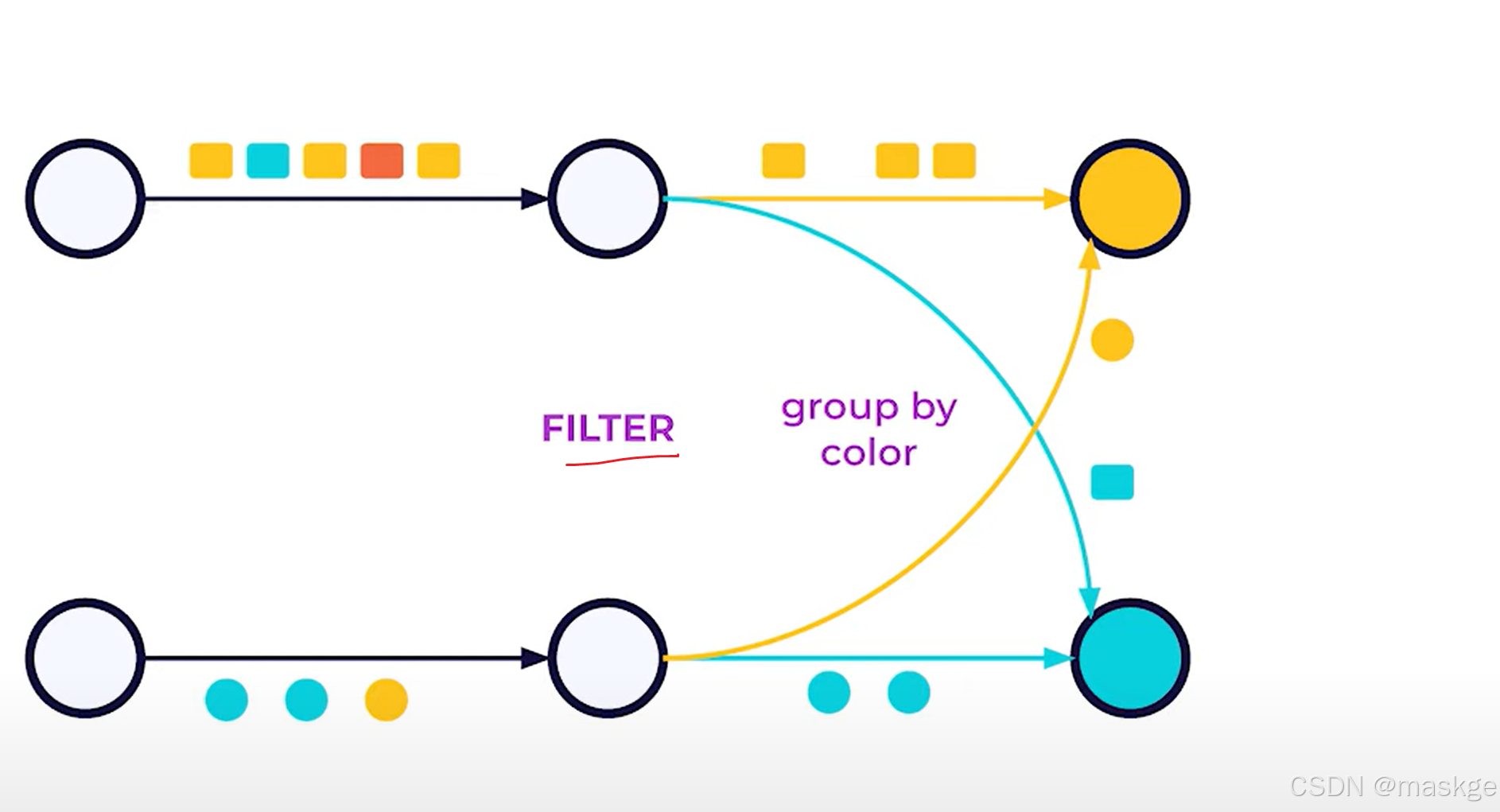
-
Rebalance: rebalance非常昂贵,就像网络抖动一样,需要序列化每个事件,并且使用网络
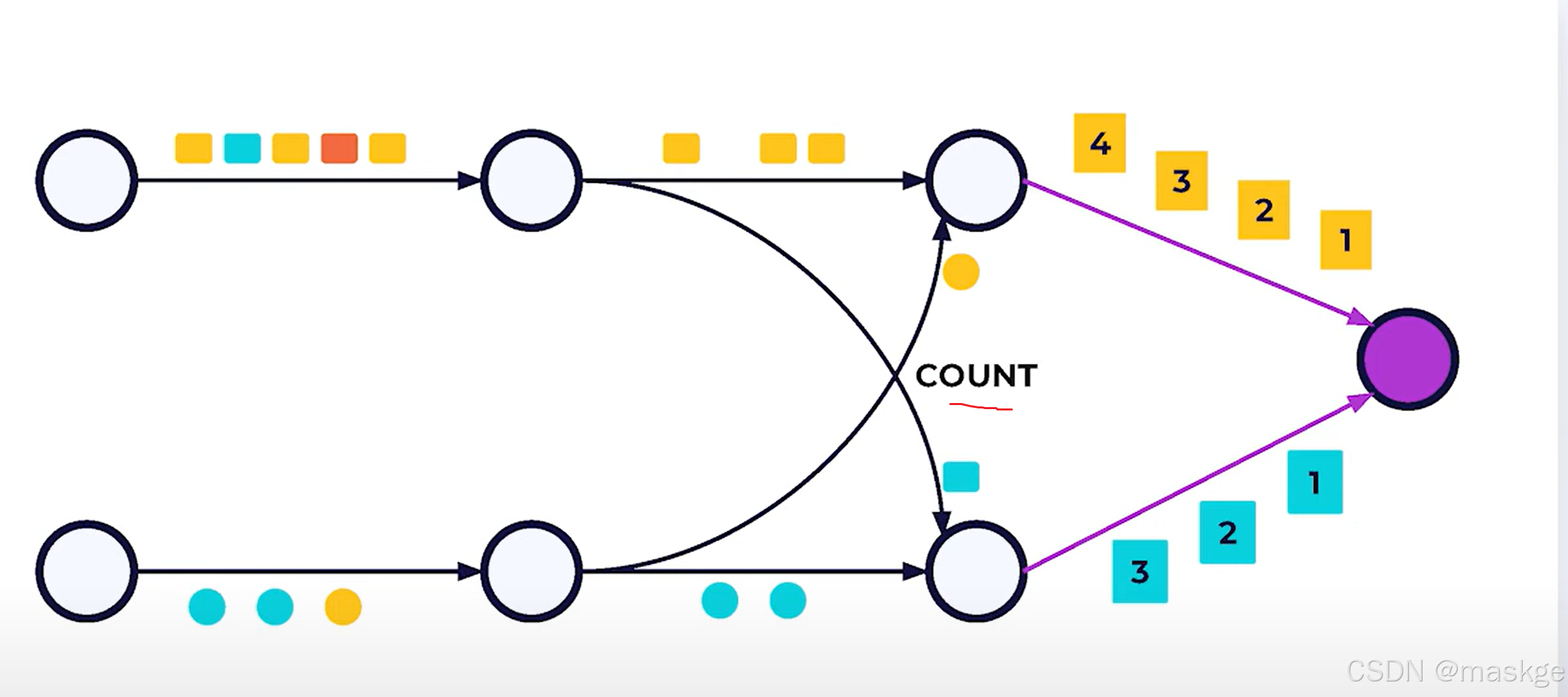
-
broadcasting :广播数据到分布式系统集群
Stream processing with SQL:
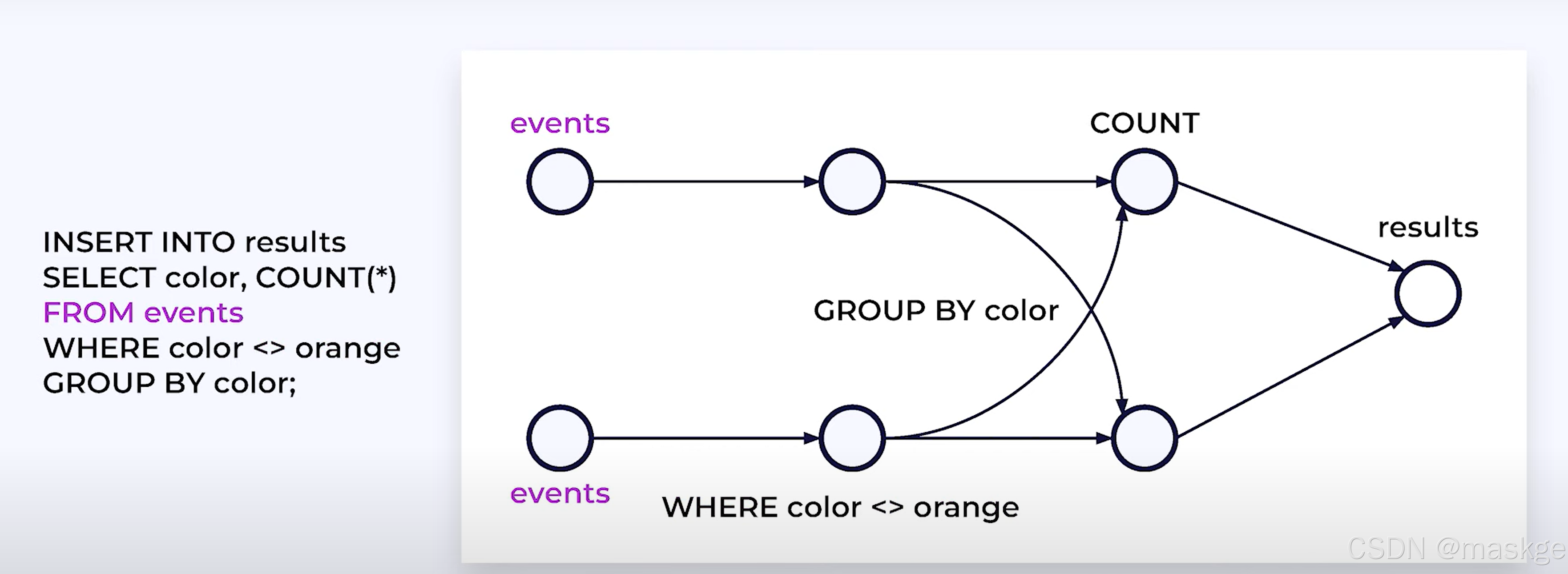
2.Flink SQL介绍
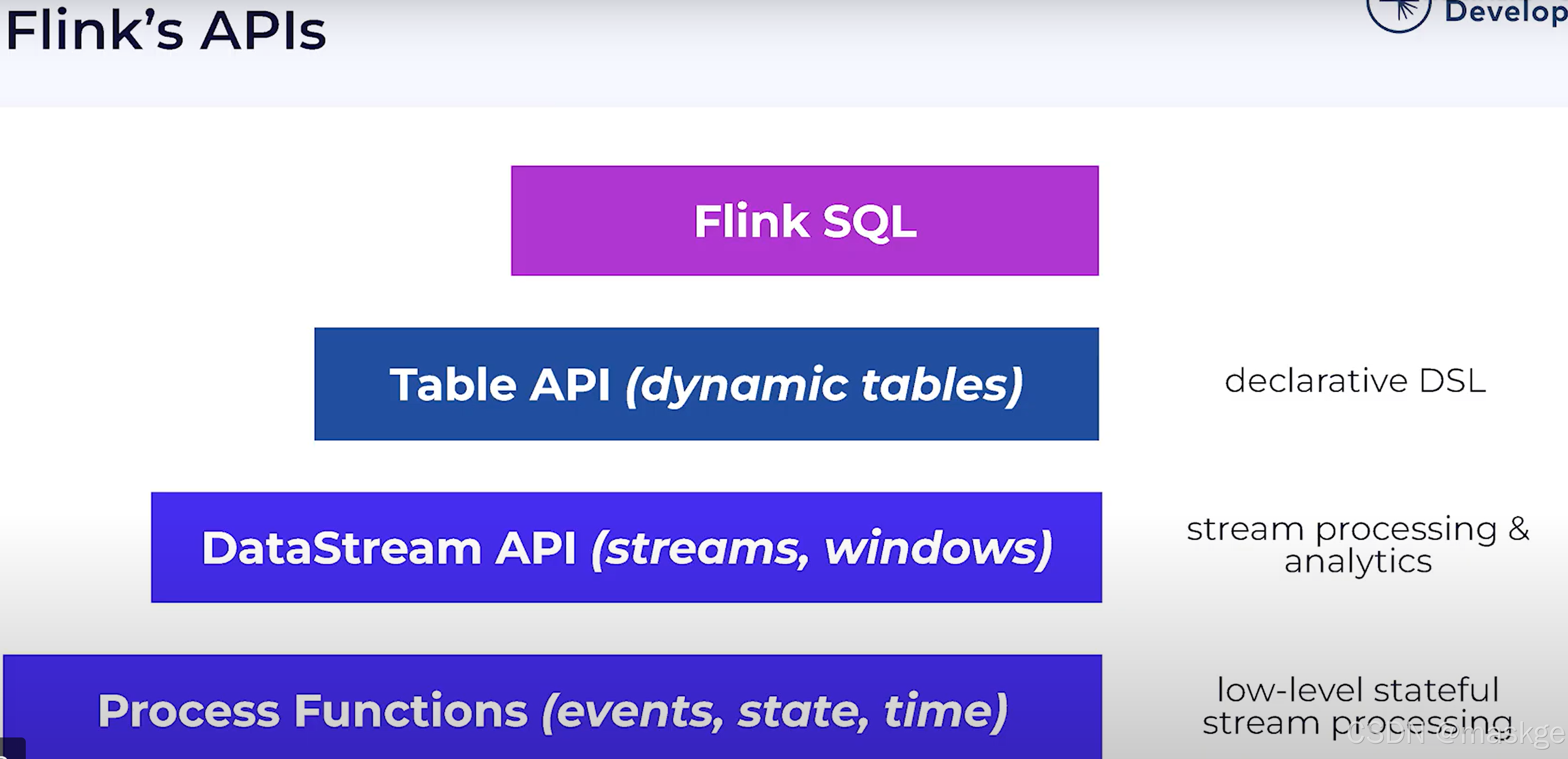
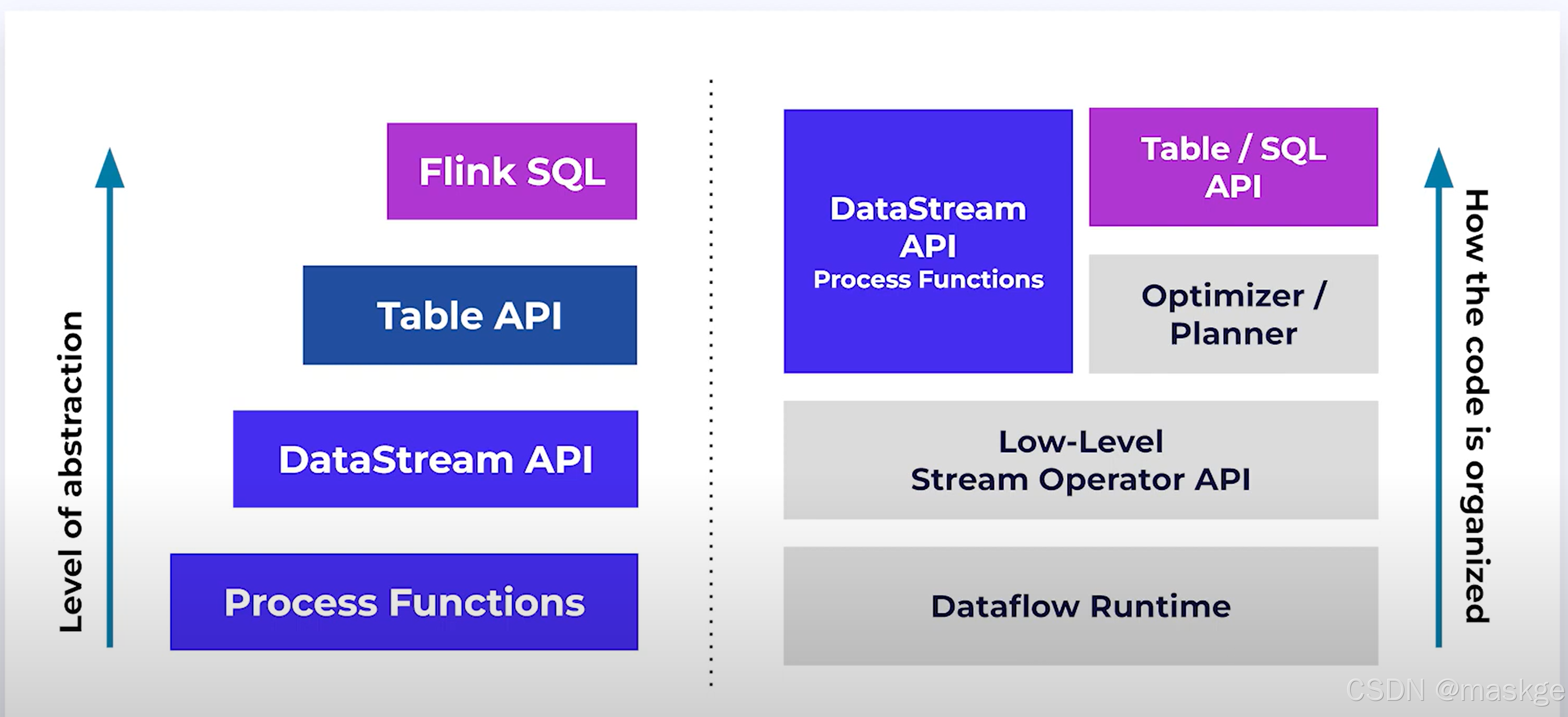
例子:
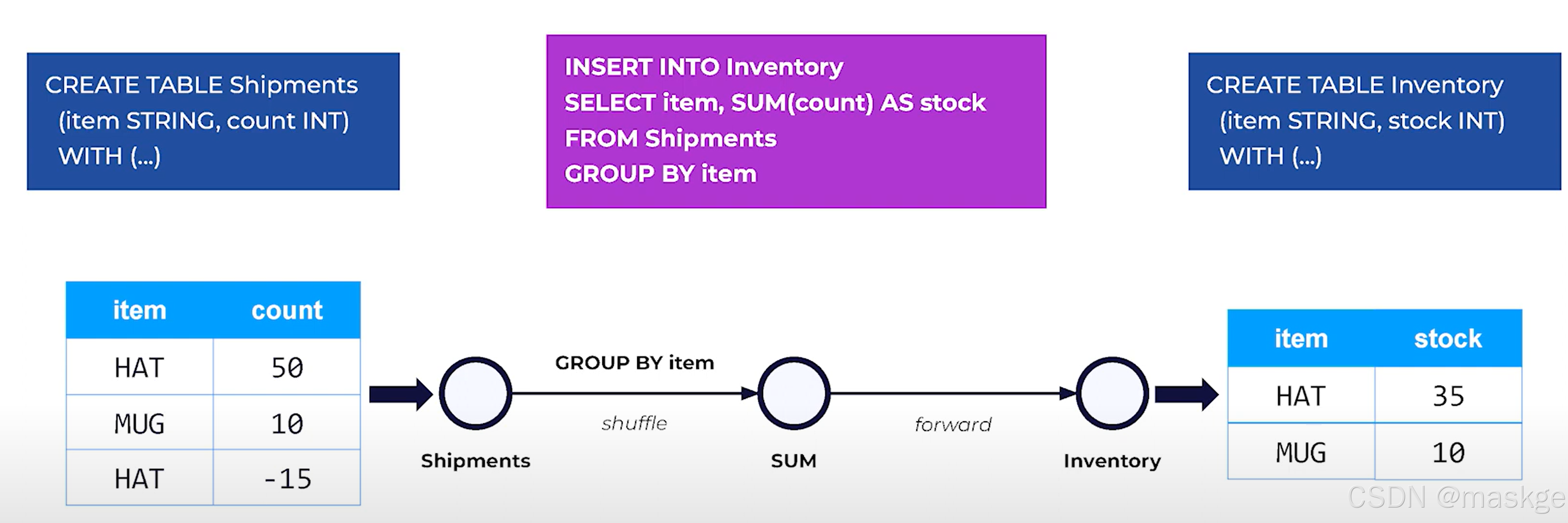

Flink SQL的特点:


append-only 、insert-only
Flink SQL 模式:
1. Streaming and Batch

2. Streaming only模式

3.Batch only 模式:

通过docker运行flink SQL CLI
-
安装dockerdesktop
-
执行 docker compose version
-
克隆 flink练习代码仓:https://github.com/confluentinc/learn-apache-flink-101-exercises.git
-
进入本地clone项目的根目录,执行构建docker compose命令:
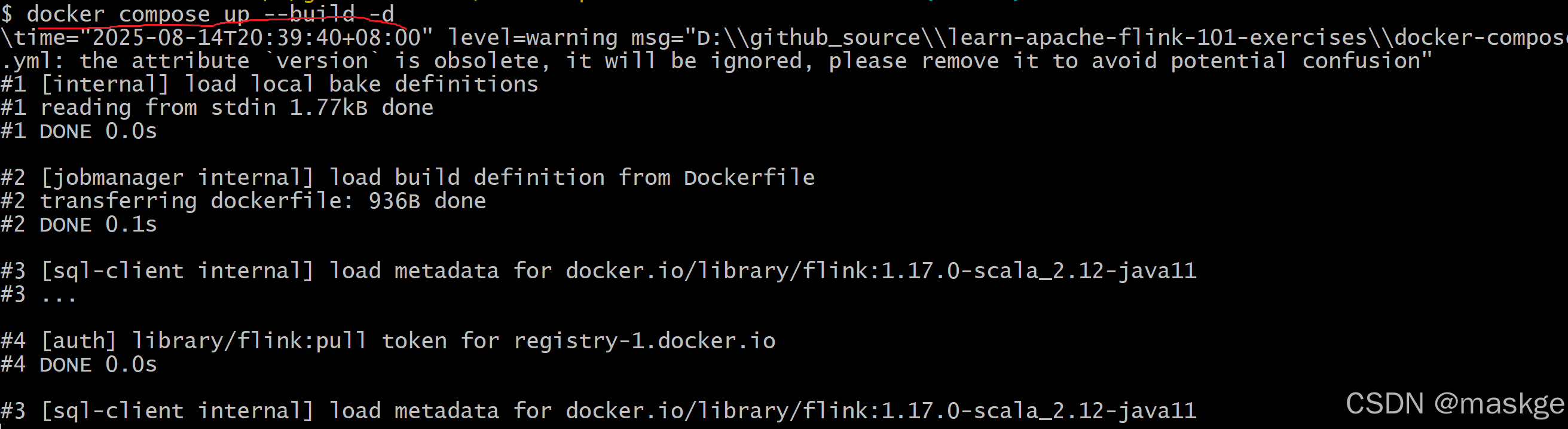
-
运行sql-client
docker compose run sql-client -
但sql-client启动成功,可以看到flink SQL CLi提示
Flink SQL> -
然后可以进行 Flink SQL的一些操作
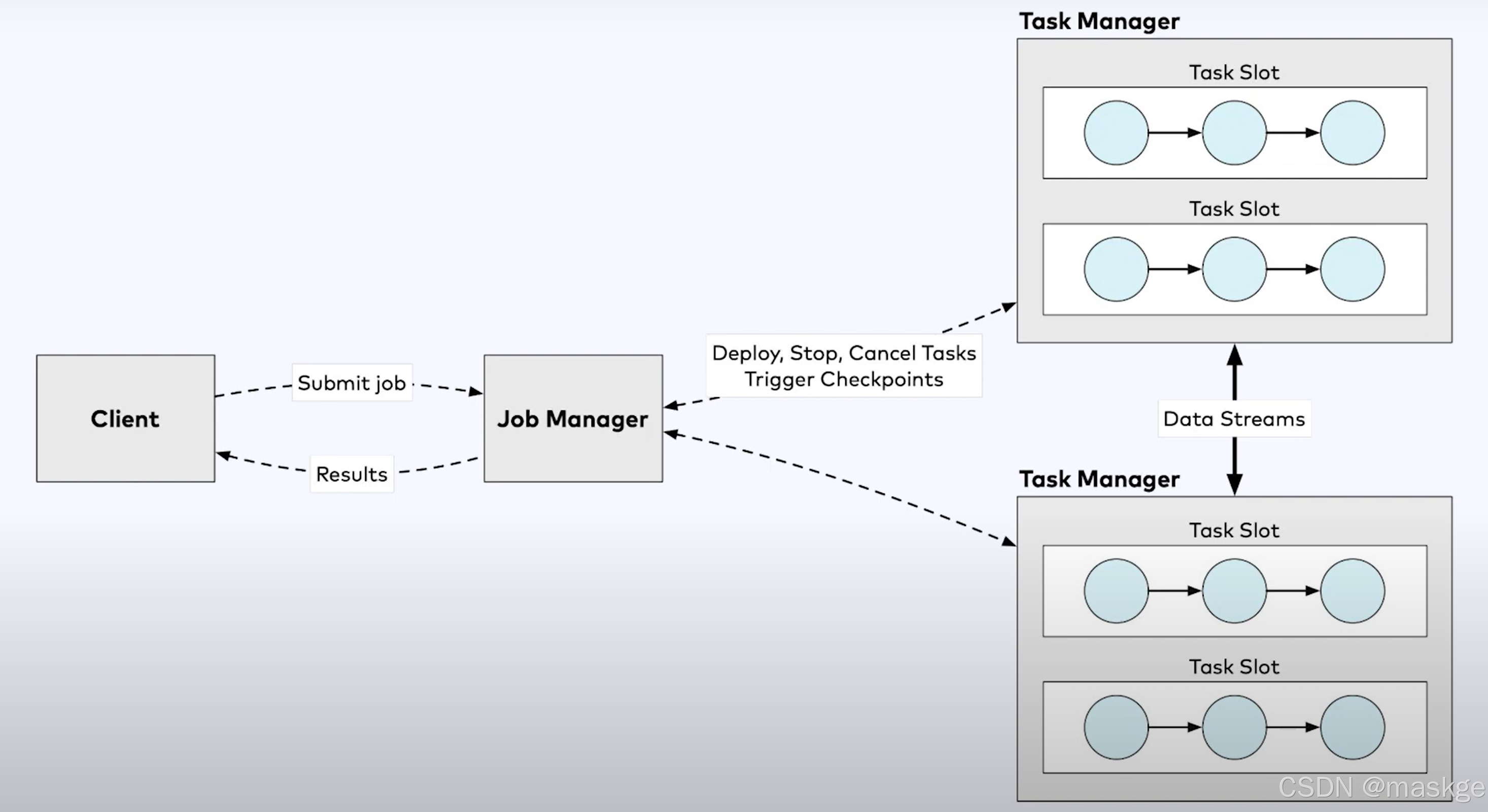
3. Flink Runtime
运行时架构(runtime Architecture)
Flink streaming VS Batch
| Streaming | Batch |
|---|---|
| Bounded or unbounded streams | only bounded streams |
| Entrie pipeline must always be running | Execution proceeds in stages,running as needed |
| Input must be processed as it arrives | Input may be pre-sorted by time and key |
| Results are reported as they become ready | Results are repored at the end of the job |
| Failure recovery resumes from a recent snapshot | Failure recovery does a reset and full restart |
| Flink guarantees effectively exactly-once result ,despite out-of-order data and restarts due to failures. | Effectively exactly-once gurantees are more straightforward |
flink task有三种状态:
- idle
- busy
- backpressured:the task is unable to send output downstream because the downstream task is busy
总结
streaming 提供了立刻响应的场景,如下:
- 监控告警
- 欺诈检测(fraud detection)
Batch processing 更好,因为它效率更高效
4.使用flink集成kafka
kafka主要组件
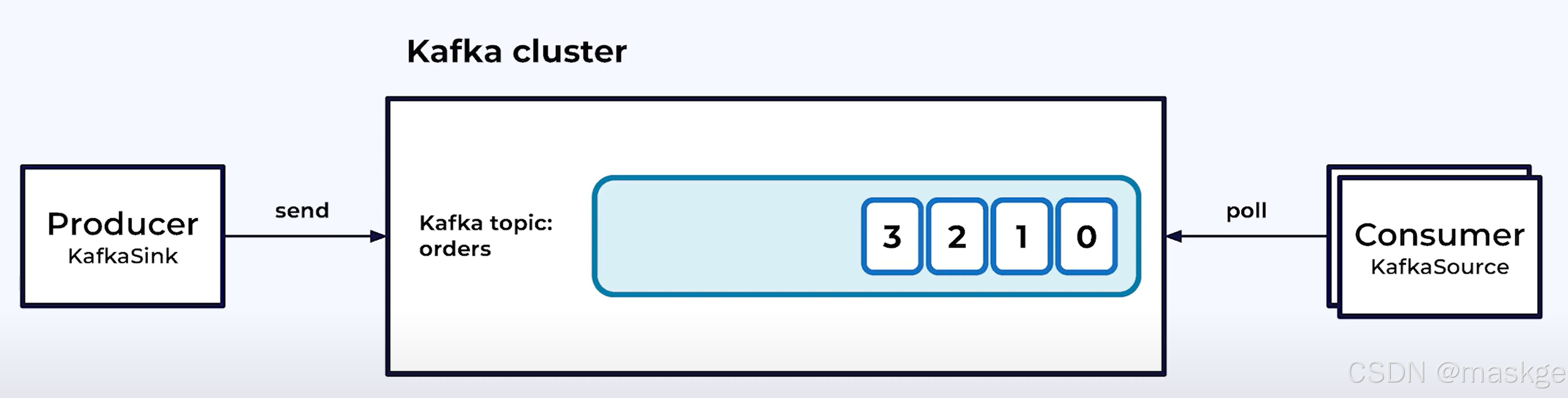
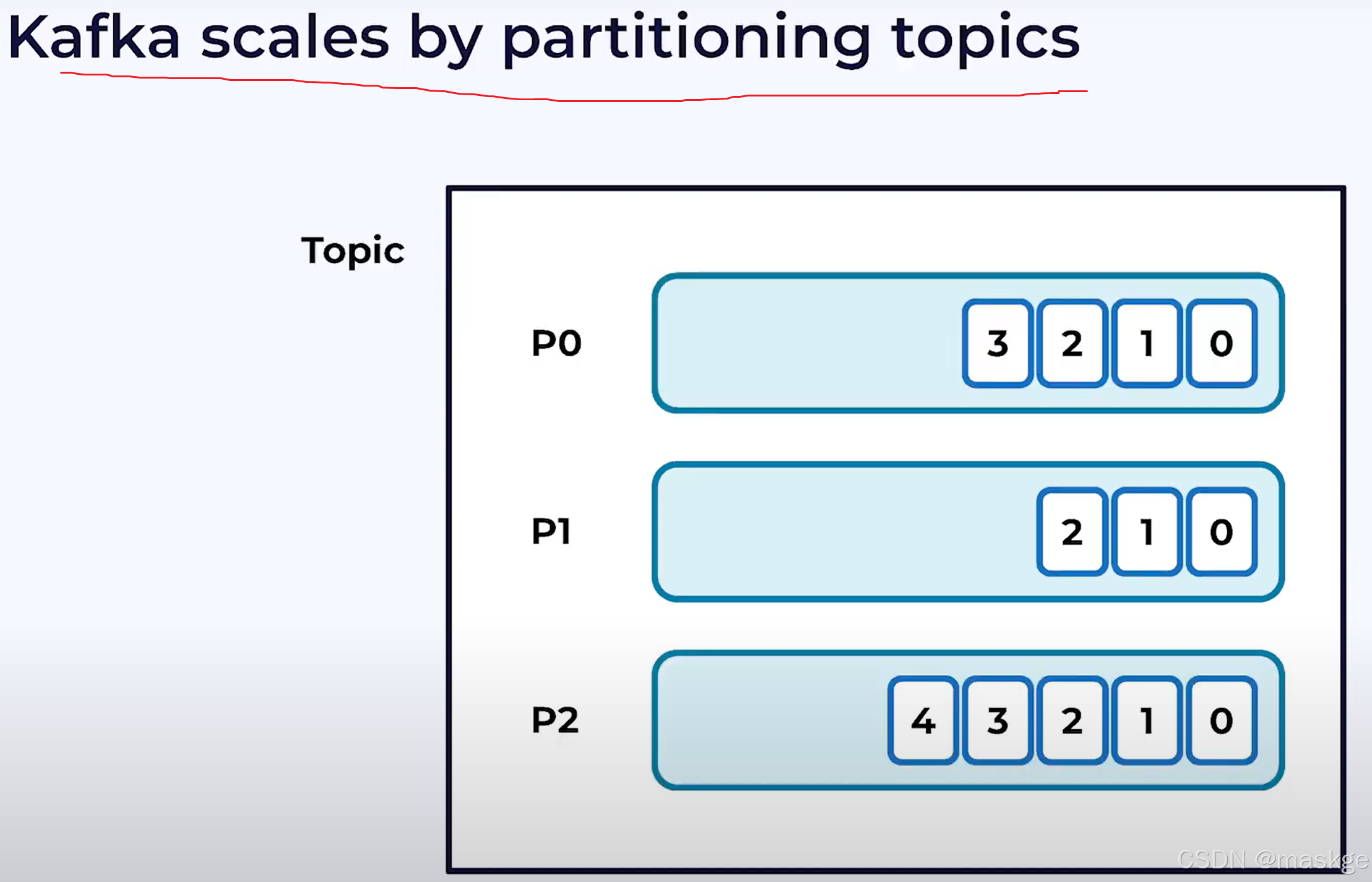
kafka架构
kafka事件结构:

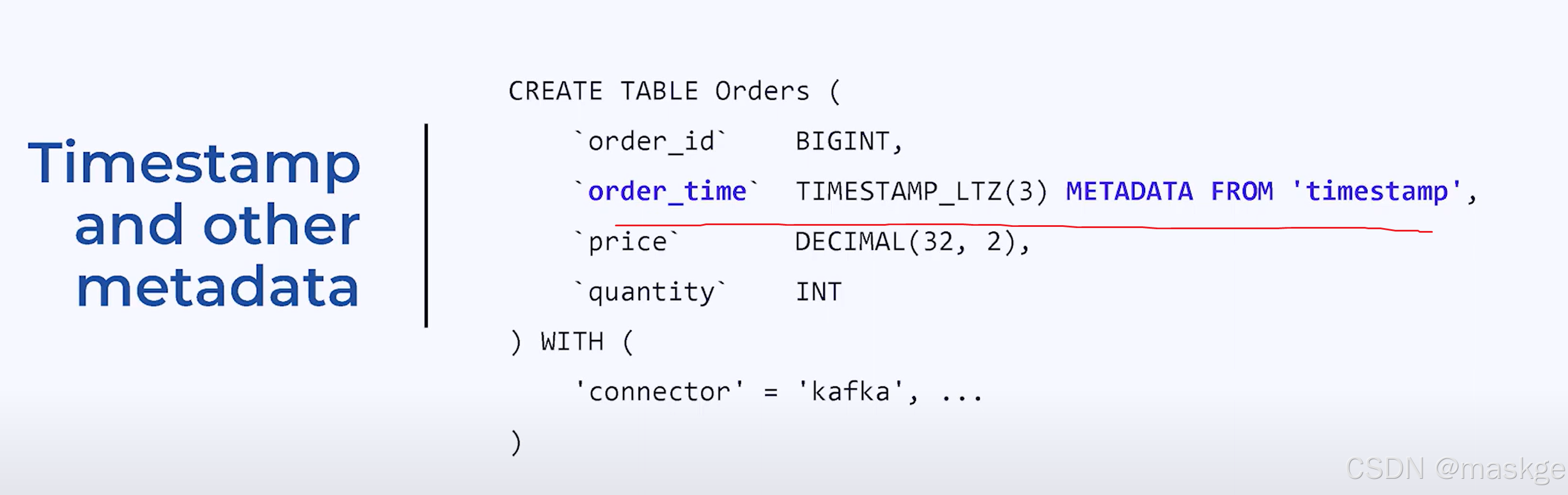
flink table 与topic的映射关系

映射kafka topics成flink table
flink format

flink需要知道协作的kafka topic的数据格式是什么
Flink可以作为kafka,实时应用、流水线的计算层
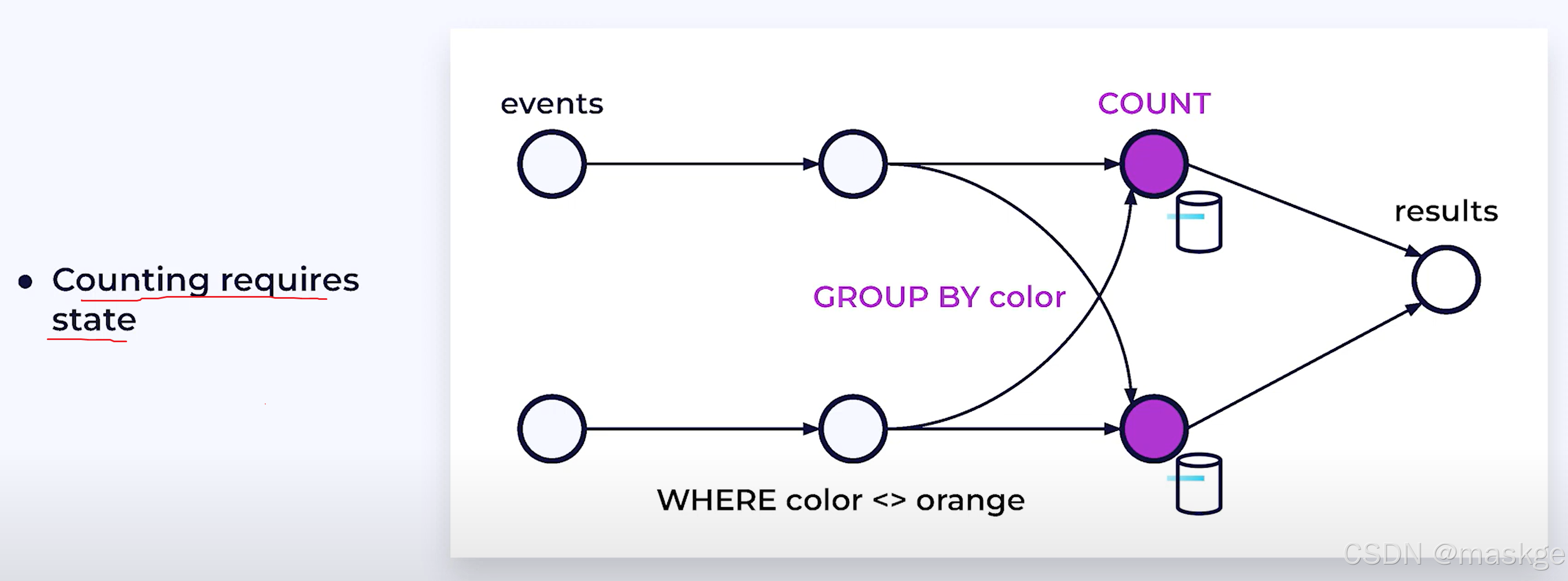
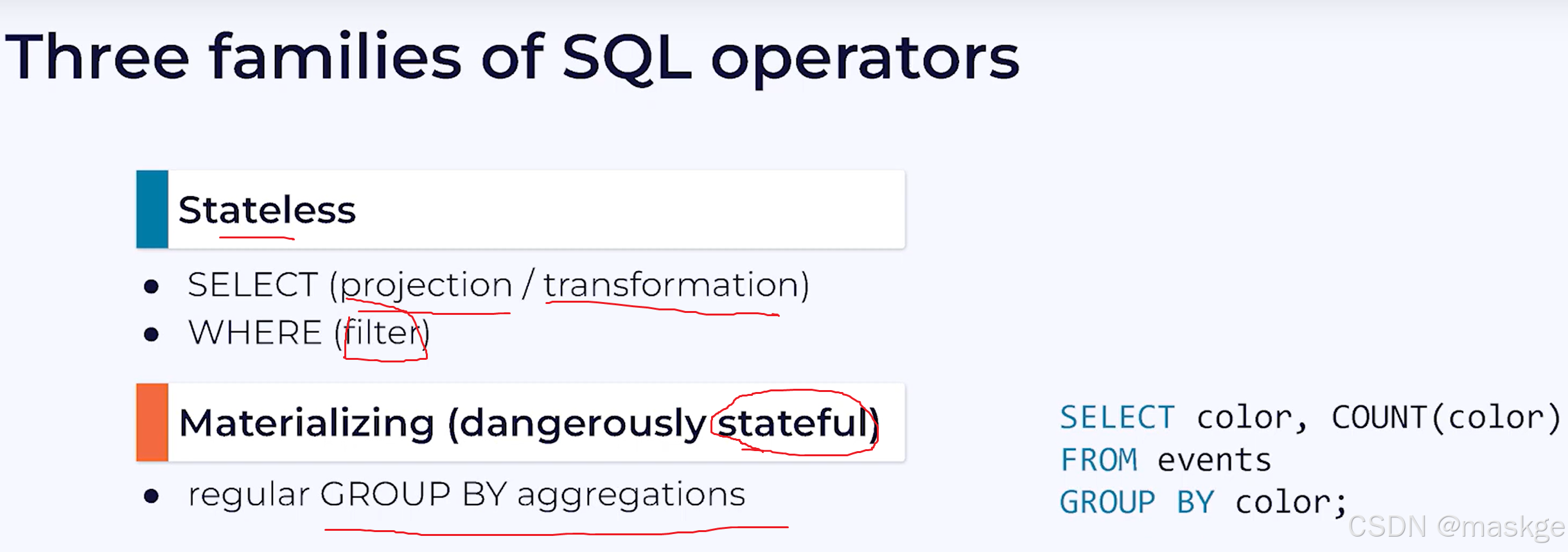
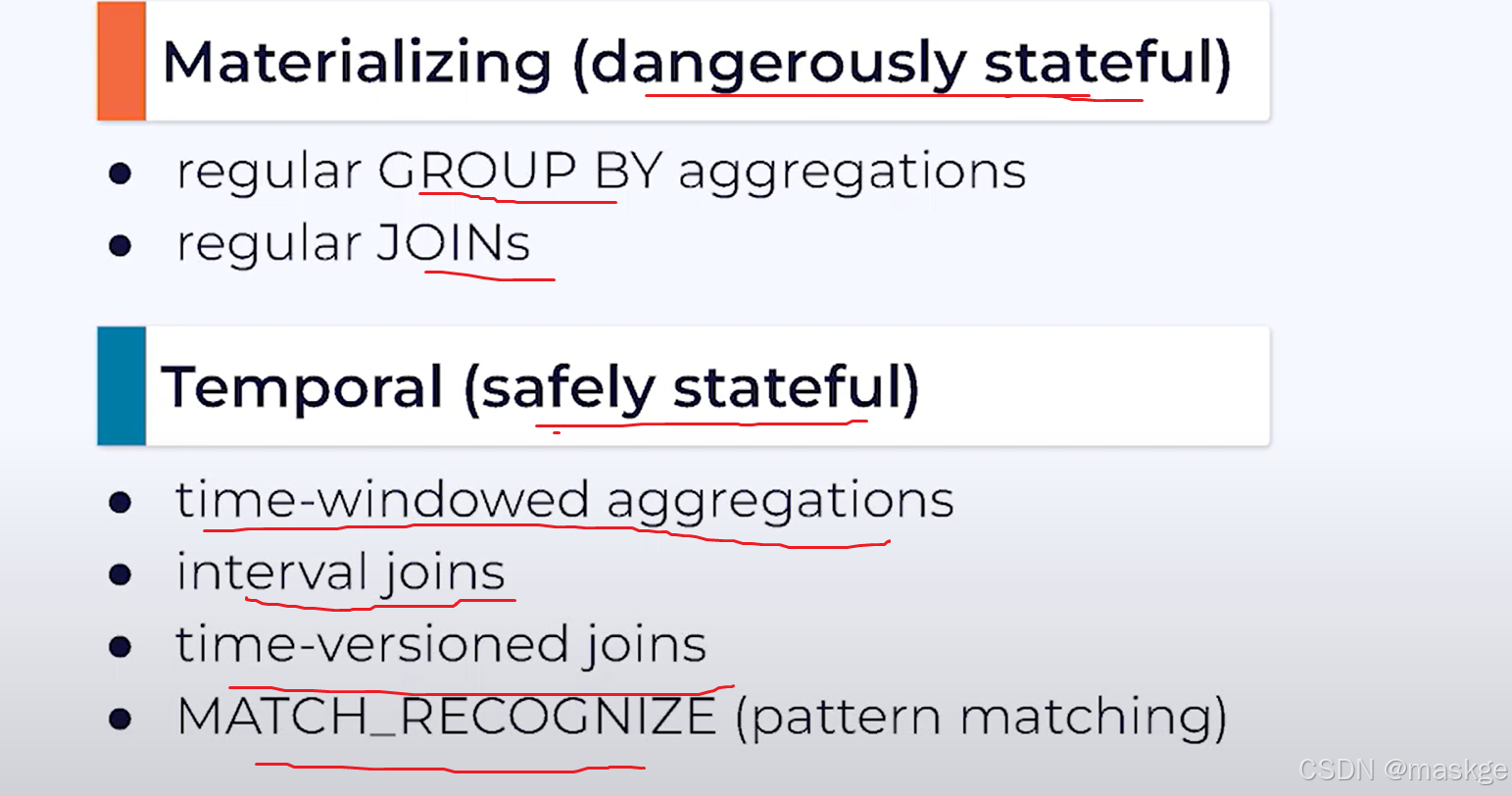
5.使用Flink SQL进行有状态流处理


6.Event time & Watermarks
Time
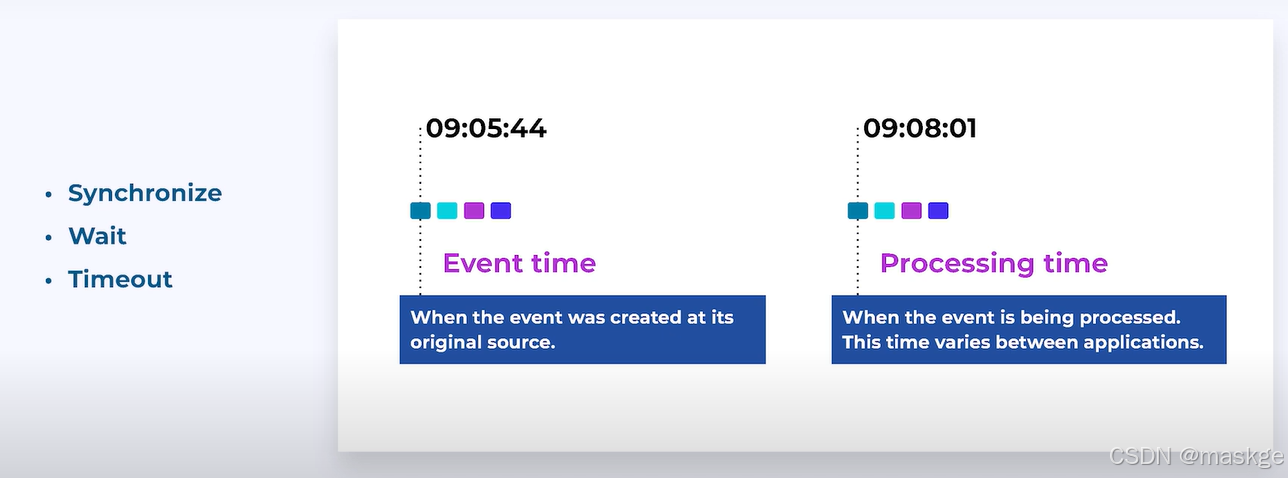
out-of-order event time
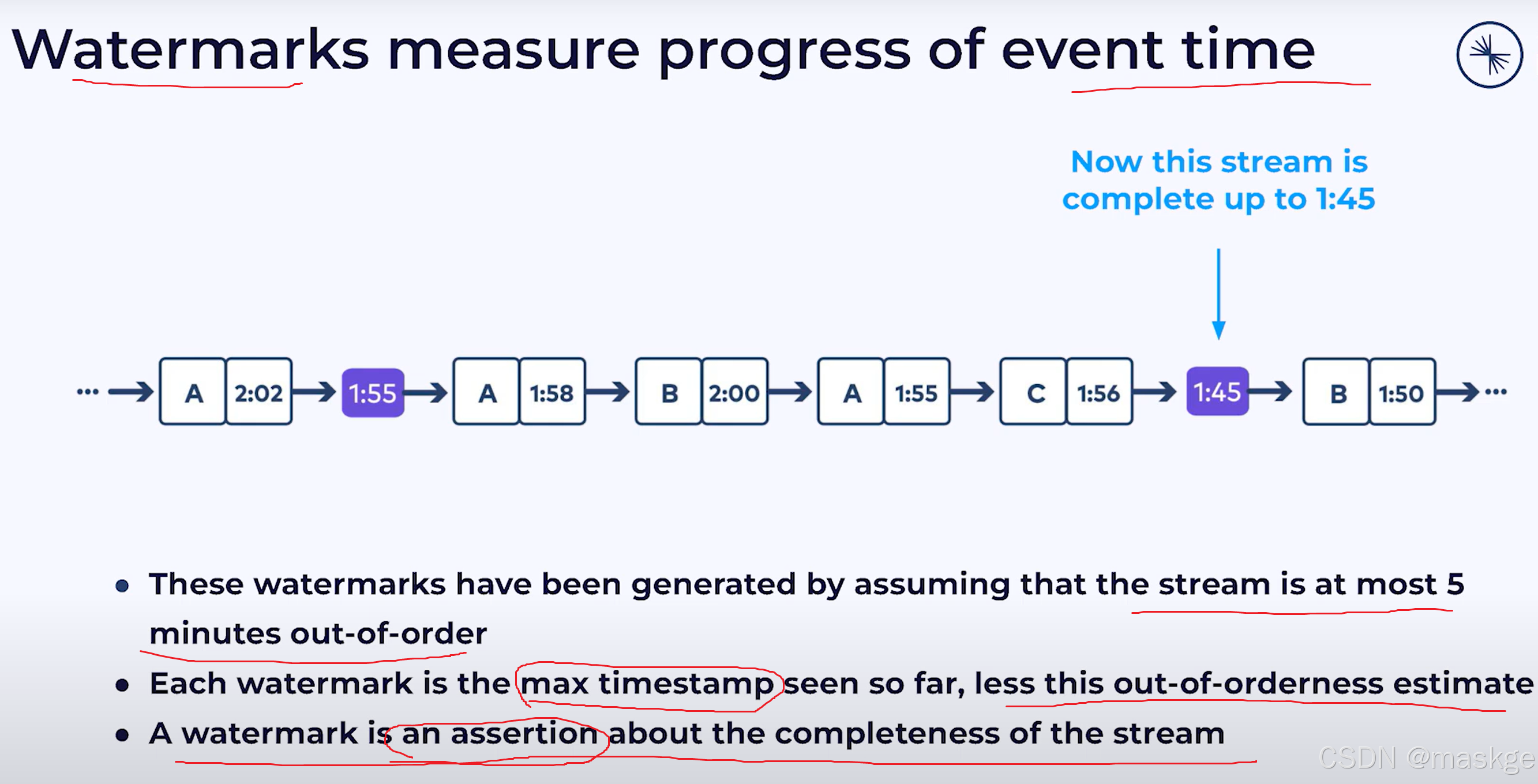
watermarks

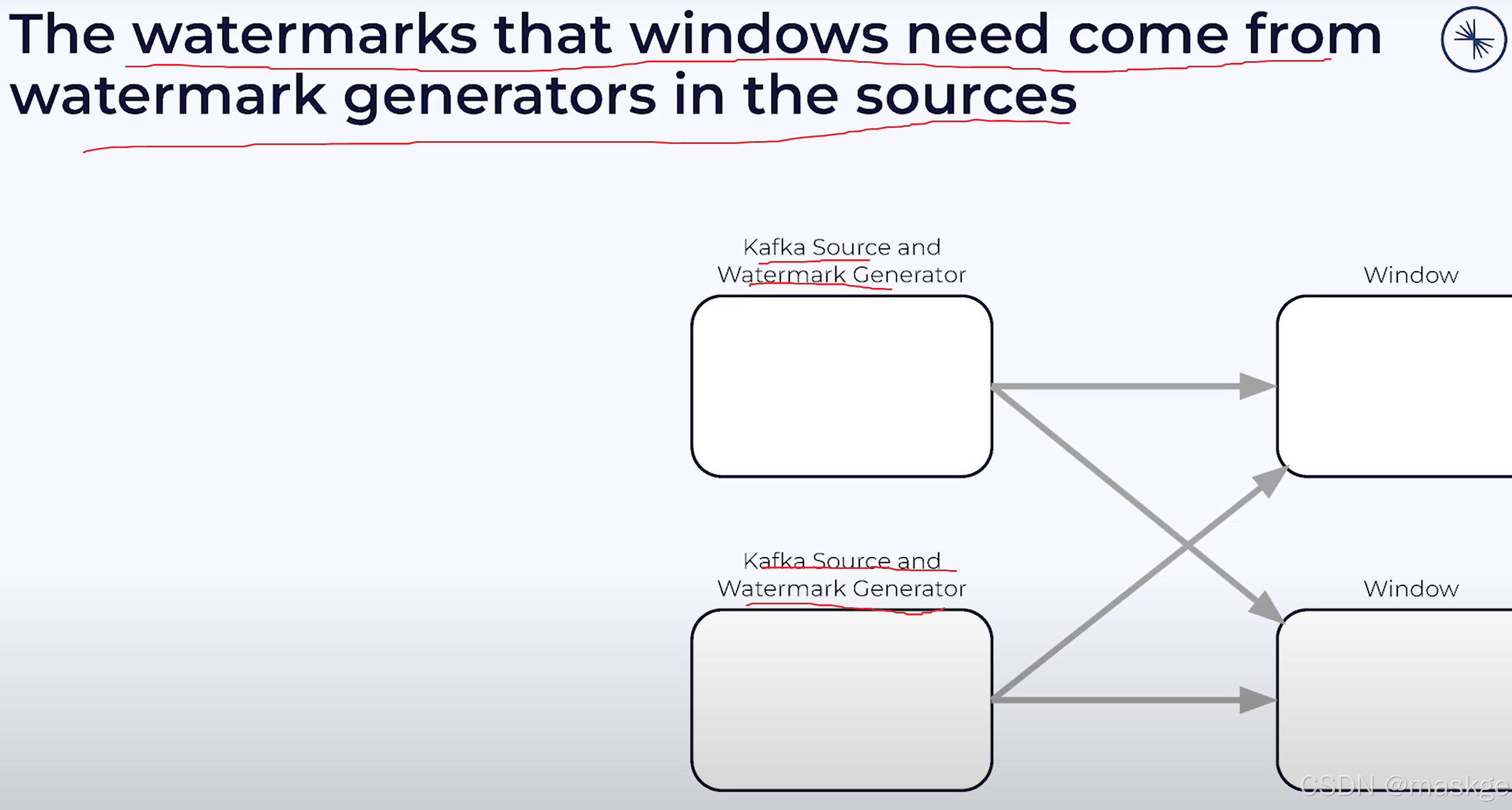
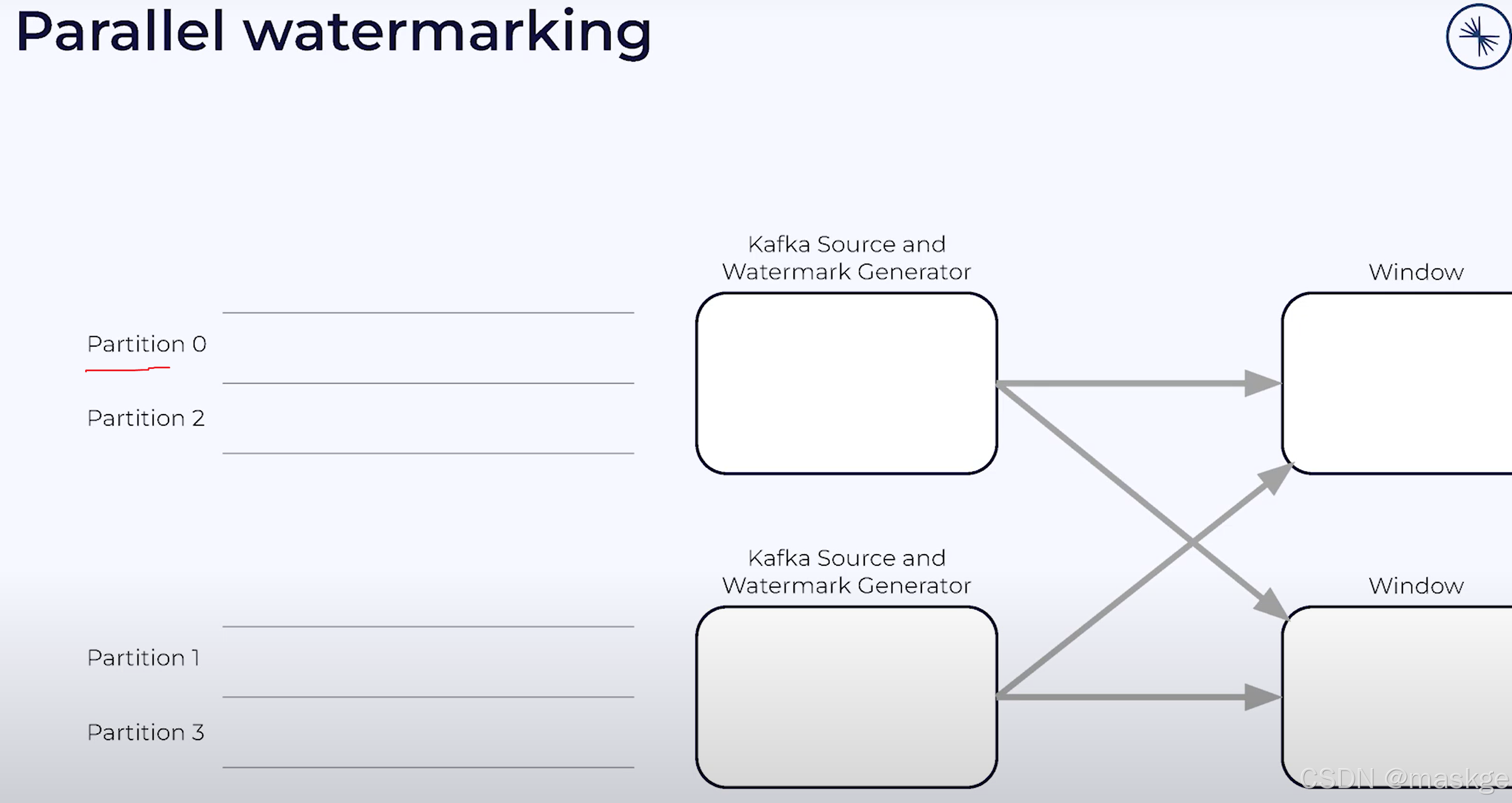
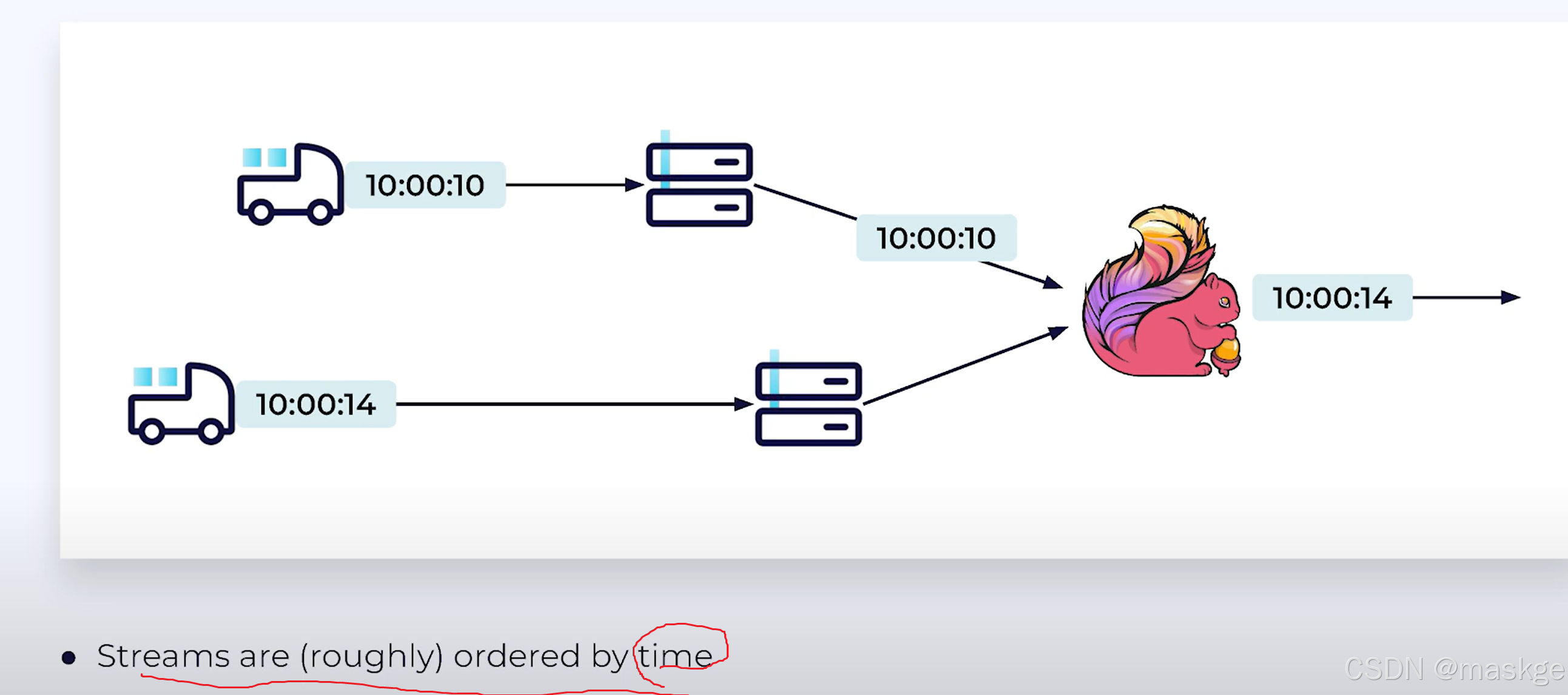
kafka source operator 从kafka partition 读取
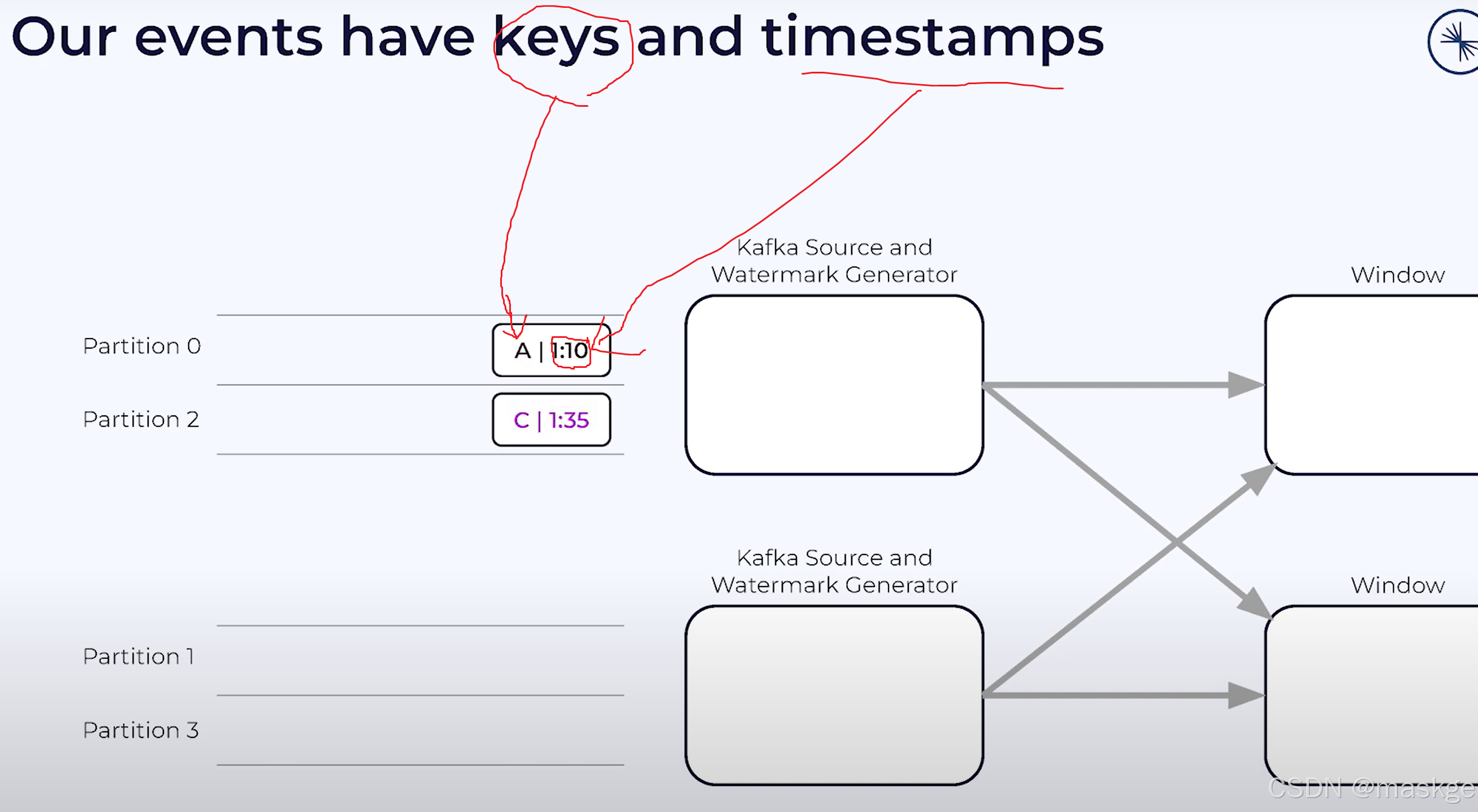
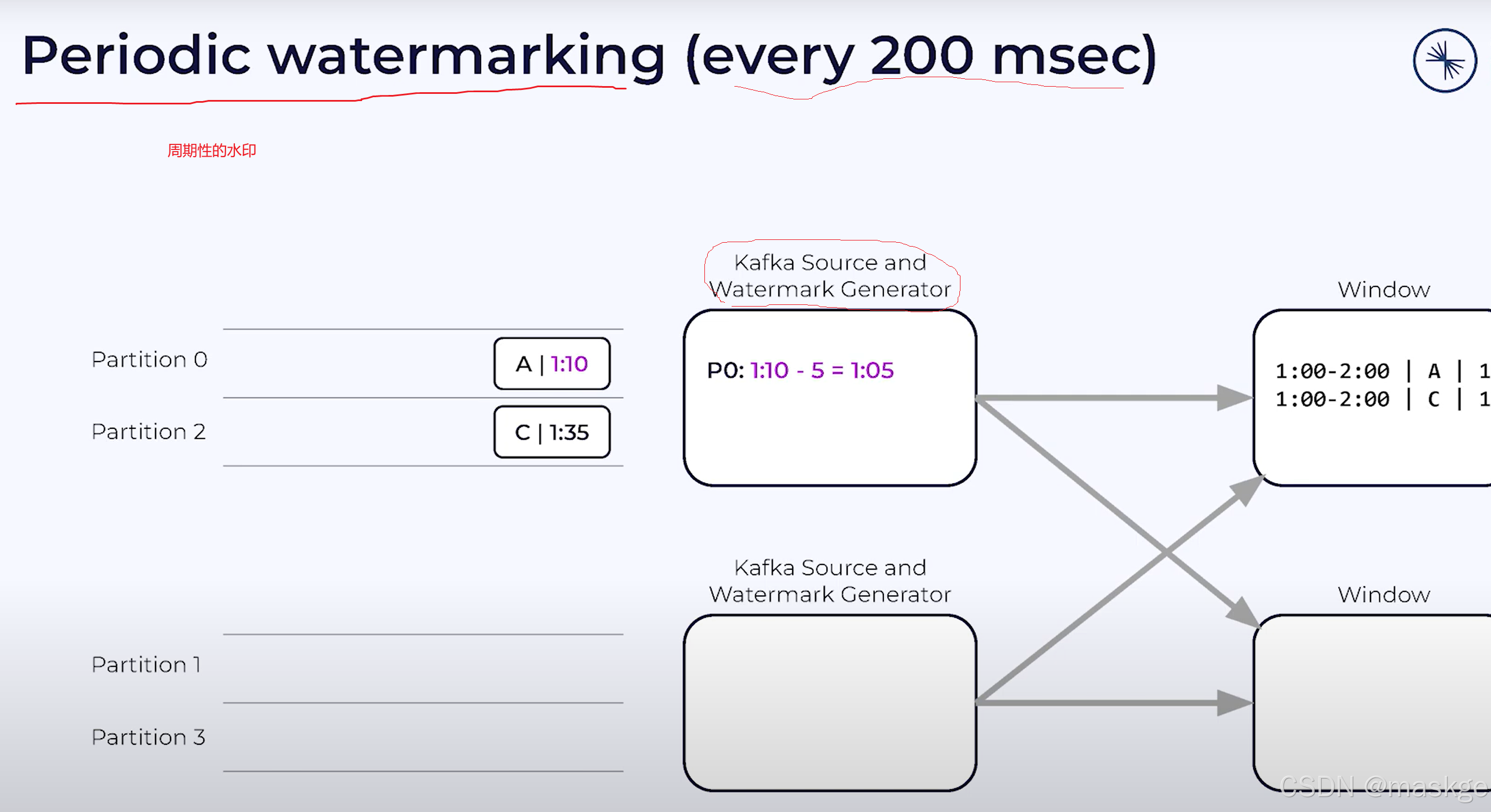
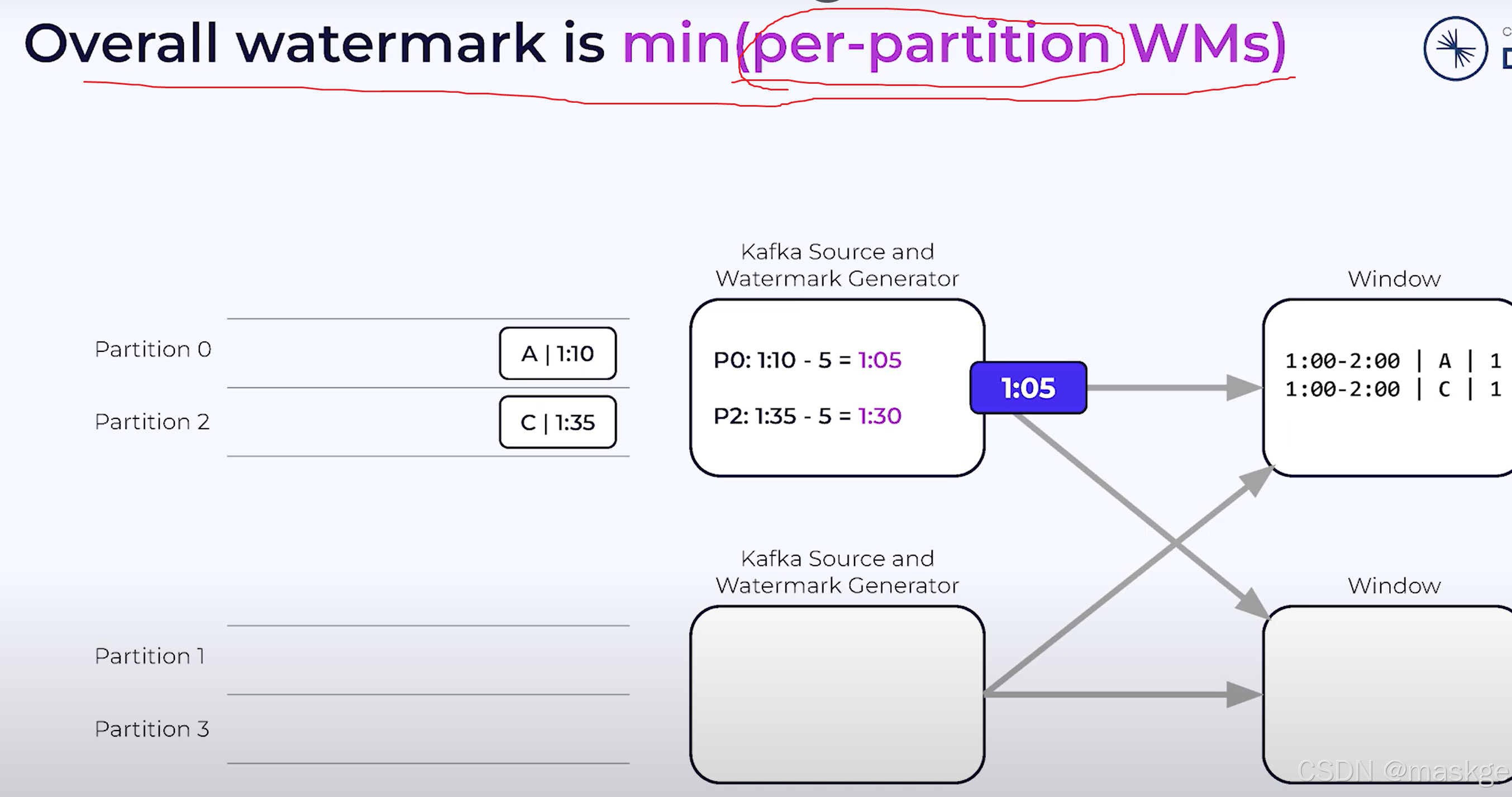
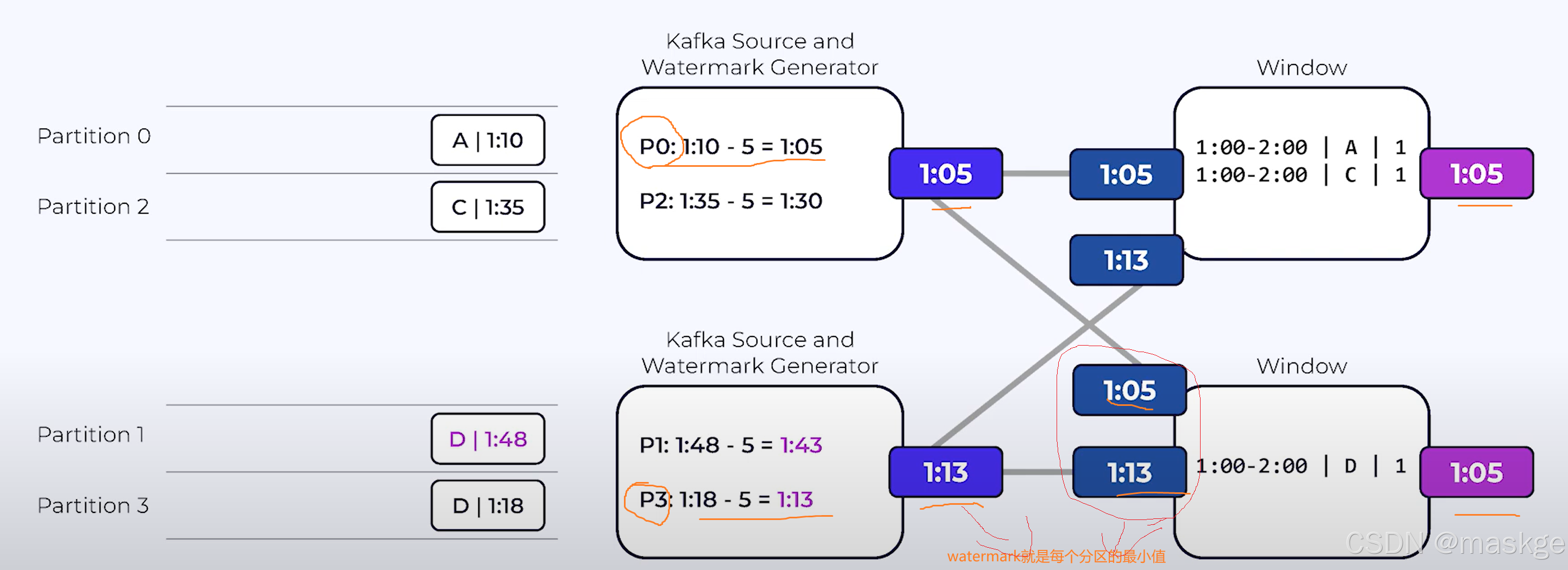
waermarkark就是分区的最小值,如:1:05
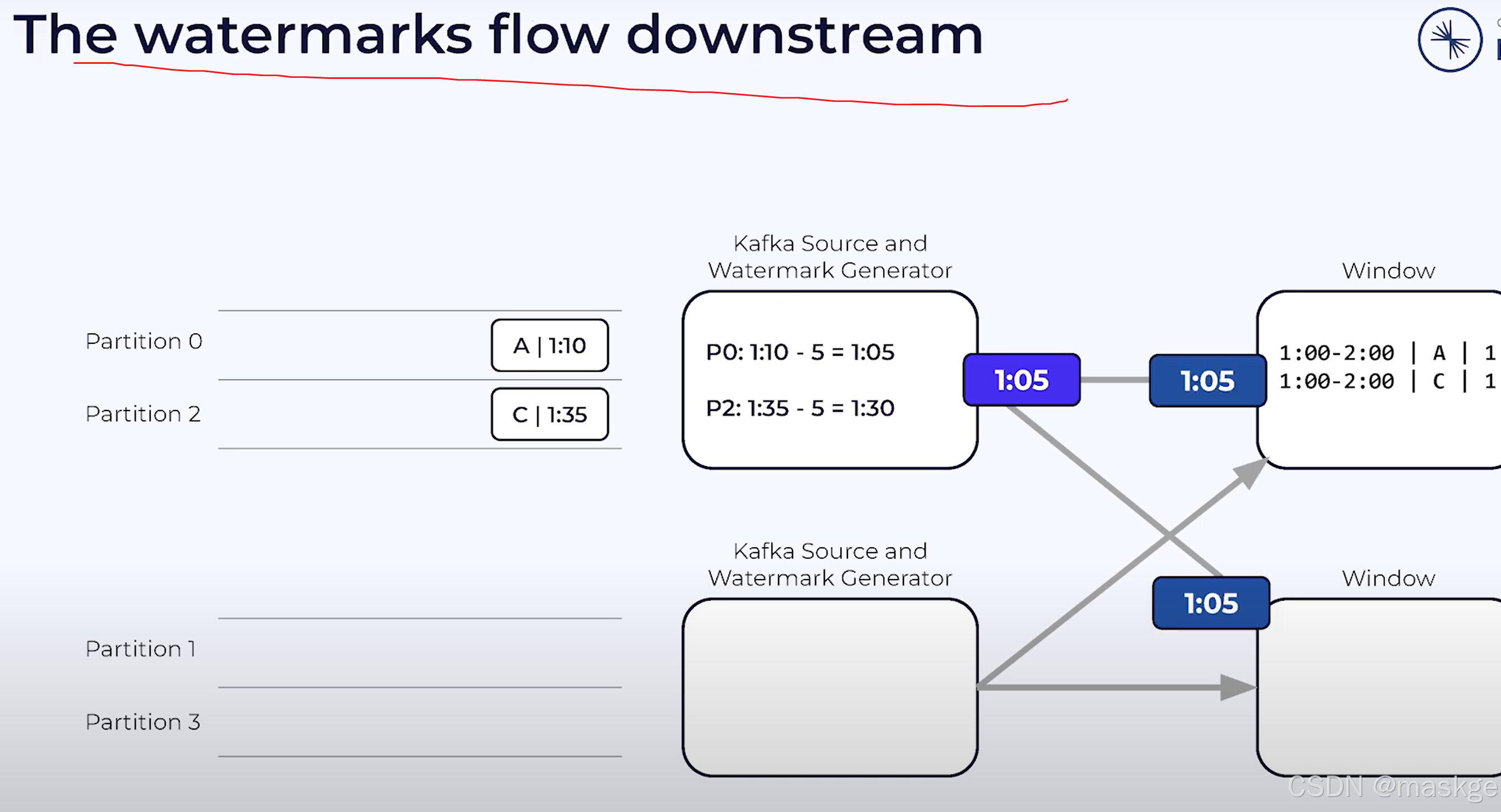
一旦watermark被生成,source会发送它到下游

flink job不产生结果的原因分析以及解决方法:



水印的使用(watermark):

7. flink Checkpoints & recovery
1.checkpoint
- checkpoint就是flink自动产生的快照,主要用于失败恢复
- savepoint是一种手动创建的快照,主要为了运维的目的,如:有状态的升级->升级flink到最新的版本
flink使用Chandy-Lamport 分布式快照算法解决以下问题:
- flink生成不是期望的结果
- flink生成重复
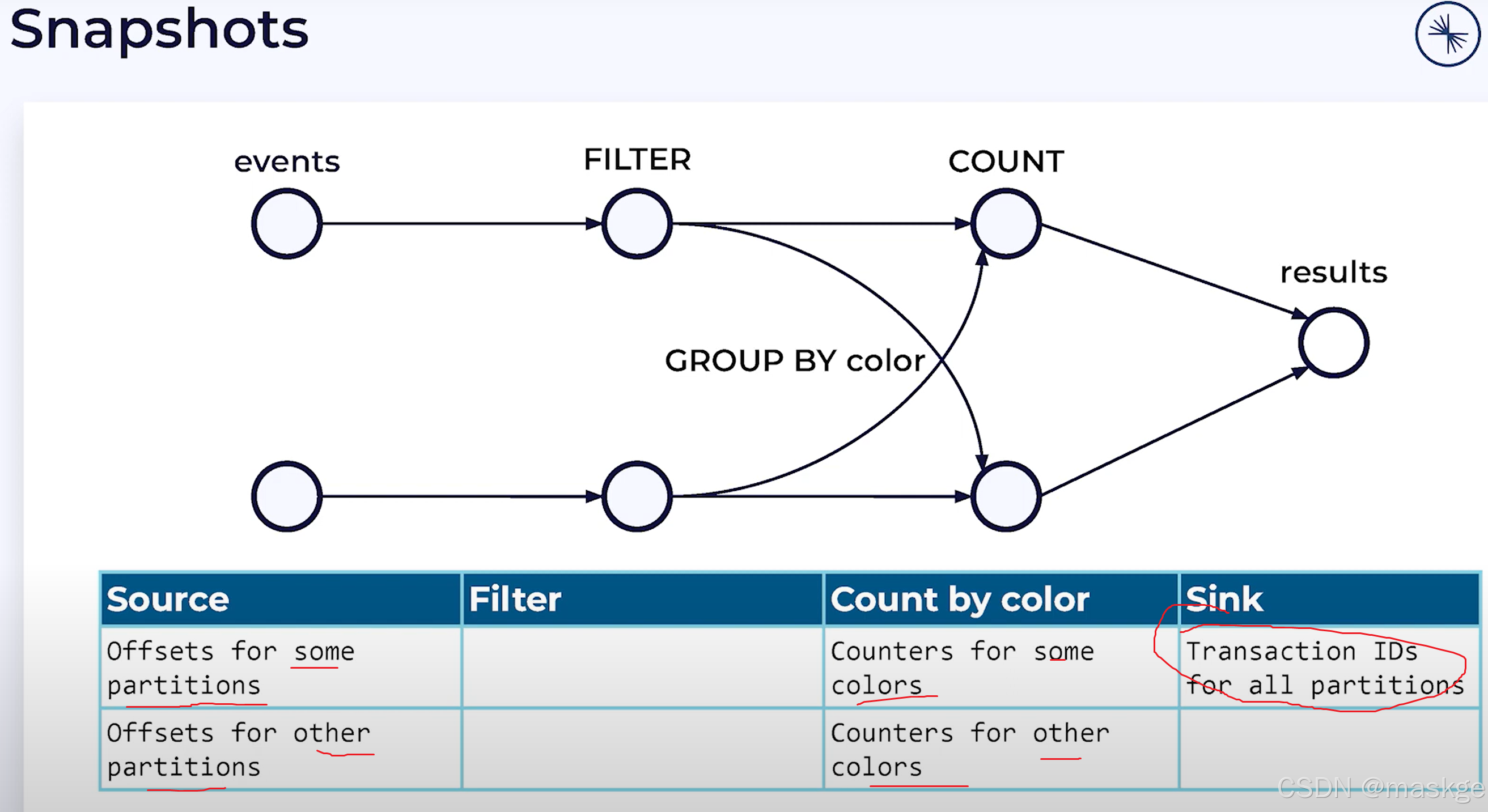
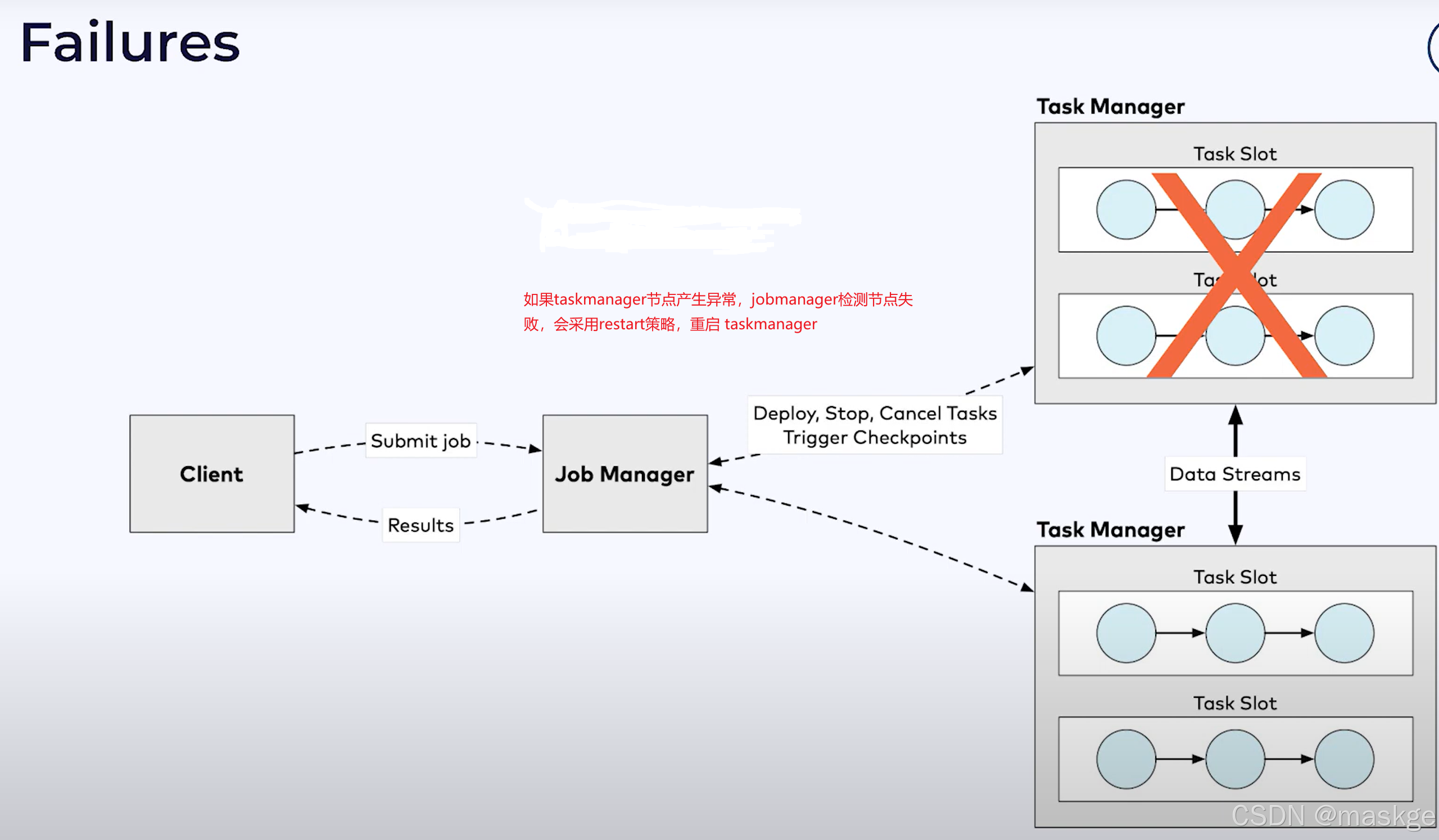
2.故障恢复(recovery)

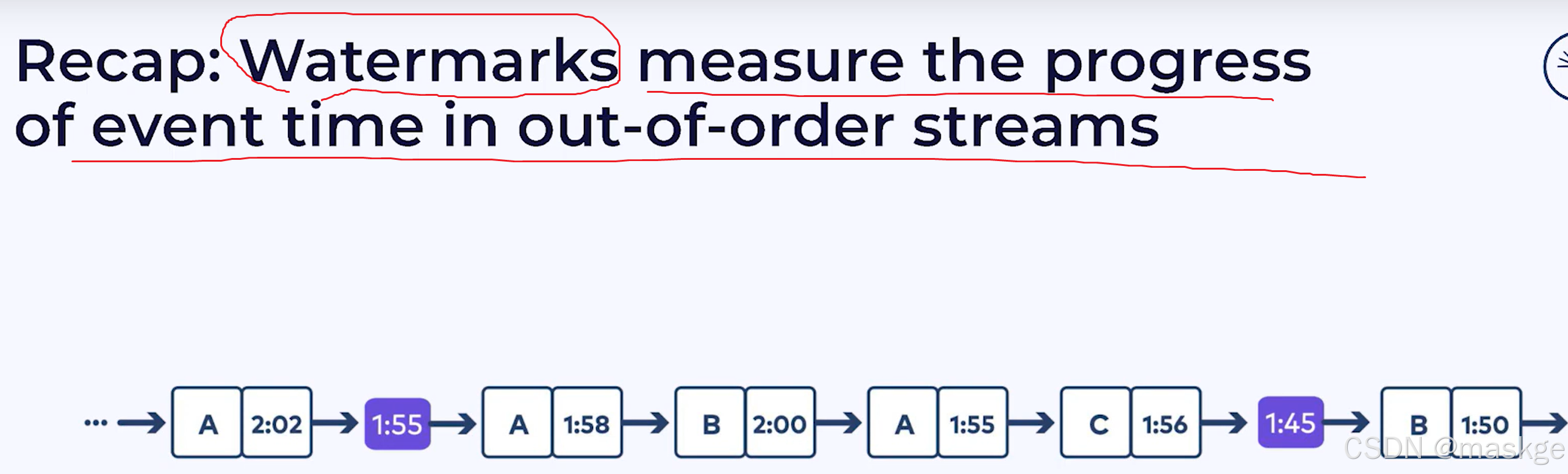
水印衡量着无序流中事件时间的进度
