西湖大学新国立,多模态大语言模型能指引我回家吗?ReasonMap:基于交通地图的细粒度视觉推理基准研究
- 作者: Sicheng Feng1,2^{1,2}1,2, Song Wang3,2^{3,2}3,2, Shuyi Ouyang3,2^{3,2}3,2, Lingdong Kong2^{2}2, Zikai Song4,2^{4,2}4,2, Jianke Zhu3^{3}3, Huan Wang1^{1}1, Xinchao Wang2^{2}2
- 单位:1^{1}1西湖大学,2^{2}2新加坡国立大学,3^{3}3浙江大学,4^{4}4华中科技大学
- 论文标题:Can MLLMs Guide Me Home? A Benchmark Study on Fine-Grained Visual Reasoning from Transit Maps
- 论文链接:https://arxiv.org/pdf/2505.18675
- 项目主页:https://fscdc.github.io/Reason-Map/
- 代码链接:https://github.com/fscdc/ReasonMap
主要贡献
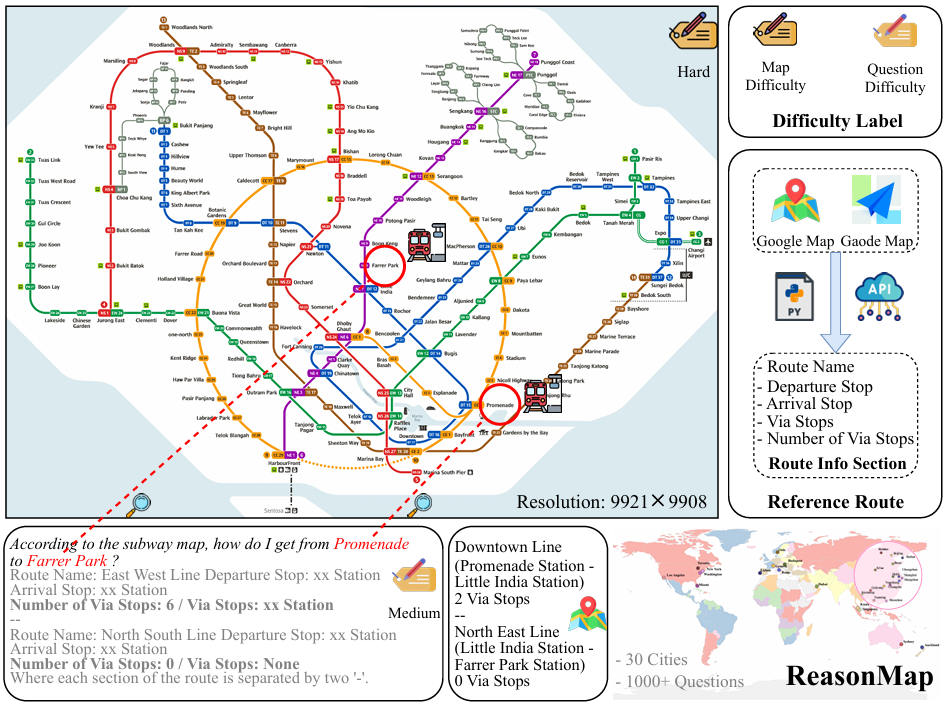
- 开发了可扩展的半自动化数据集构建流程,创建了REASONMAP基准数据集,包含来自13个国家30个城市的高分辨率交通地图以及1008个人类验证的问题-答案对,涵盖了两种问题类型和三种模板。
- 提出了结构化的两级评估框架,分别使用准确率和提出的地图分数独立量化答案的正确性和质量,能够对模型的答案进行细致评估。
- 对15种流行的多模态大模型进行了全面的基准测试研究,提供了关于模型性能、鲁棒性以及视觉和文本线索之间相互作用的见解,为未来多模态模型的研究提供了参考。
研究背景
- 多模态大模型(MLLMs)的发展:近年来,MLLMs在视觉任务中取得了显著进展,如语义场景理解、文本-图像对齐等,并且推理变体在涉及数学和逻辑的复杂任务中提升了性能。然而,MLLMs在涉及细粒度视觉理解的推理任务上的能力尚未得到充分评估。
- 现有基准的局限性:尽管已经提出了多个基准来评估多模态推理,但大多数现有基准仅涉及粗粒度任务,且通常允许模型通过浅层启发式方法成功,而无需真正的视觉基础。对于像高分辨率交通地图这样结构化且信息丰富的图表,缺乏系统性的细粒度视觉推理评估,留下了现有基准的关键空白。
REASONMAP 构建
REASONMAP构建流程
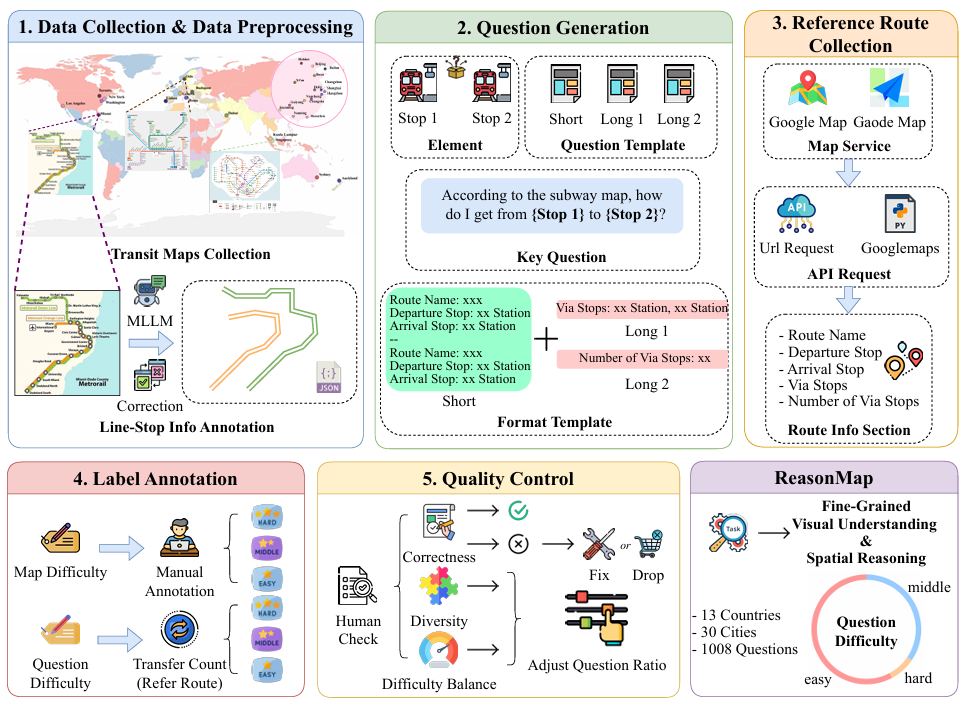
数据收集与预处理
- 数据来源:从公开的在线资源中收集了来自13个国家的30个城市的高分辨率交通地图,确保地图的多样性和难度平衡。
- 地图预处理:
- 使用 MLLMs 提取交通线路名称和对应的站点名称。
- 手动校正提取结果,确保信息的准确性。
- 对于换乘站和分支起点站等特殊站点,进行标准化注释。
- 将所有路线和站点信息保存为统一的 JSON 格式,便于后续使用。
问题-答案对构建
问题生成
- 随机选择两个站点(
stop1和stop2),并根据预定义的模板生成问题。 - 短问题使用一个固定的模板,长问题随机选择两个模板中的一个。
- 短问题模板:
According to the subway map, how do I get from [Stop 1] to [Stop 2]? Provide only one optimal route, with only the line name and the departure and arrival stations.- 长问题模板 1:
According to the subway map, how do I get from [Stop 1] to [Stop 2]? Provide only one optimal route, and include the number of via stops for each route section (excluding the departure and arrival stops).- 长问题模板 2:
According to the subway map, how do I get from [Stop 1] to [Stop 2]? Provide only one optimal route, including all the via stops.
参考路线收集
- 使用地图服务API(如高德地图和谷歌地图)查询两个站点之间的所有有效交通路线。
- 将查询到的路线保存为统一格式,包含路线名称、出发站、到达站、途经站和途经站数量等元数据。
- 丢弃无法在地图上视觉追踪的路线,确保与视觉内容的一致性。
难度标注
- 地图难度:手动将每个地图分为三个难度级别(简单、中等、困难),确保30个地图在难度上平衡分布。
- 问题难度:根据参考路线中的换乘次数进行标注,无换乘为简单,一次换乘为中等,多次换乘为困难。
- 为了保持平衡,每个地图的问题难度分布设置为20:15:5(简单:中等:困难),每种难度级别生成40个问题。
质量控制
- 正确性:手动校正或丢弃错误的问题-答案对。
- 多样性:确保问题覆盖不同的地图和站点组合。
- 难度平衡:通过手动调整,确保每个地图和问题难度级别都有足够的样本。
数据集统计
- 包含30个高分辨率交通地图,平均分辨率 5839×54495839 \times 54495839×5449 像素。
- 总共1008个问题-答案对,涵盖四种语言(英语、匈牙利语、中文和意大利语)的站点名称。
- 问题难度分布:57.7%为简单,34.4%为中等,7.8%为困难。
- 选取312个样本作为测试集,其余样本作为训练集。
评估框架
评估准备
- 答案解析:将模型生成的答案解析为指定格式,不符合格式或无法解析的答案标记为无效,排除在后续评估之外。
- 真值来源:使用地图元数据作为正确性评估的真值,使用收集的参考路线作为质量评估的真值。
正确性评估
- 初始化准确率
acc为1。 - 检查预测路线的第一段的出发站是否为
stop1,最后一段的到达站是否为stop2,否则acc置为0。 - 遍历预测路线的每一段:
- 如果路线名称不在地图元数据中,
acc置为0。 - 如果出发站或到达站不在该路线的站点列表中,
acc置为0。 - 如果不是最后一段,检查当前段的到达站是否与下一段的出发站一致,否则
acc置为0。
- 如果路线名称不在地图元数据中,
- 返回
acc。
质量评估
初始化地图分数 map_score 为0。
短问题评估:
- 如果第一段的出发站和最后一段的到达站正确,
map_score加1。 - 如果路线名称匹配,
map_score加2。 - 如果每段的出发站和到达站匹配,每匹配一个加1分。
- 如果答案根据正确性评估算法被判定为正确,则额外加分。
- 最终分数上限为10分。
长问题评估: - 途经站数量评估(
num_via_stop_score):- 计算答案和参考路线的途经站数量的绝对误差,并将其映射到固定分数(最高4分)。
- 完美匹配得满分,误差越大得分越低。
- 最终分数上限为10分。
- 具体途经站评估(
via_stop_score):- 计算答案和参考路线的途经站集合的交集和并集,计算交并比(IoU)。
- 最终分数为 IoU 分数(缩放到10分)和正确匹配的途经站数量(上限10分)的平均值,再取上限为10分。
- 总分数:将
via_stop_score或num_via_stop_score加到map_score中,具体取决于问题模板。 - 最终分数上限为20分(短问题)或40分(长问题)。
实验
实验设置
评估模型
- 评估了15种流行的多模态大语言模型(MLLMs),分为两类:
- Base Models(基础模型):没有专门的推理训练,直接用于任务的模型。例如Qwen2.5-VL系列、InternVL3系列、Kimi-VL-A3B-Instruct等。
- Reasoning Models(推理模型):经过强化学习或其他推理训练,专门用于提升推理能力的模型。例如Skywork-R1V-38B、QvQ-72B-Preview、OpenAI o3等。
- 涵盖了开源和闭源模型,以全面评估不同类型的模型性能。
推理设置
- 开源模型:使用PyTorch和HuggingFace Transformers库部署,设置最大输出标记限制为2048,其他参数保持与官方HuggingFace配置一致。
- 闭源模型:通过官方API进行评估,遵循每个模型官方文档提供的默认设置。
难度感知加权
- 根据问题难度和地图难度的组合为每个样本分配权重,难度越高的组合权重越高。权重矩阵如下:
- (“easy”, “easy”): 1.0
- (“middle”, “easy”): 1.5
- (“hard”, “easy”): 2.0
- (“easy”, “middle”): 1.5
- (“middle”, “middle”): 2.0
- (“hard”, “middle”): 2.5
- (“easy”, “hard”): 2.0
- (“middle”, “hard”): 2.5
- (“hard”, “hard”): 3.0
- 这种加权方案确保模型在解决更复杂的任务时获得更高的奖励,同时保持评分的稳定性和合理性。
实验结果
完整输入下的性能
- 性能评估指标:使用加权准确率(Weighted Accuracy)和加权地图分数(Weighted Map Score)来评估模型性能,其中加权准确率反映了模型答案的正确性,加权地图分数综合考虑了答案的正确性和质量。
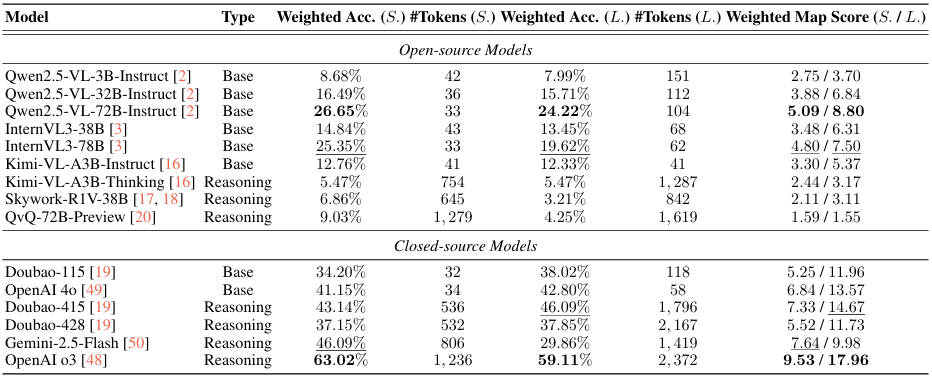
- 开源模型与闭源模型的差异:在开源模型中,推理模型的表现不如基础模型,这可能是因为开源推理模型在训练过程中更倾向于利用内部知识,而不是真正的视觉输入。而在闭源模型中,推理模型的表现优于基础模型,这可能是因为闭源模型在训练过程中更好地整合了视觉和文本信息。
- 模型大小的影响:在相同架构系列中,较大的模型通常表现更好,且生成的标记数量更少,这表明模型规模对性能有一定的提升作用。
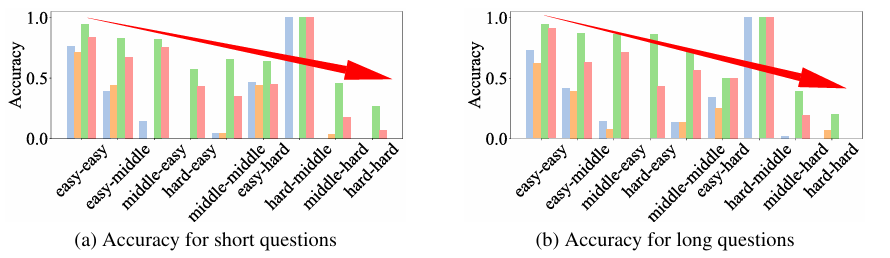
- 任务复杂度的影响:随着任务复杂度的增加,模型性能普遍下降,这说明模型在面对更复杂的细粒度视觉理解任务时面临挑战。
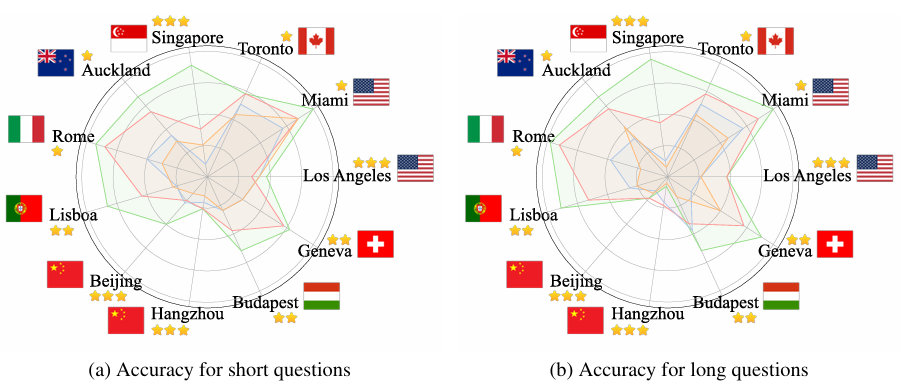
- 城市差异:不同城市的模型性能存在显著差异,这可能与城市的知名度和站点名称的语言有关。例如,OpenAI o3在新加坡等国际知名度高且站点名称为英文的城市表现更好,而在杭州等知名度较低且站点名称为中文的城市表现较差。
无视觉输入下的性能
- 实验方法:选择代表性开源和闭源模型进行实验,将视觉输入屏蔽,仅提供文本输入,观察模型在无视觉信息时的表现。
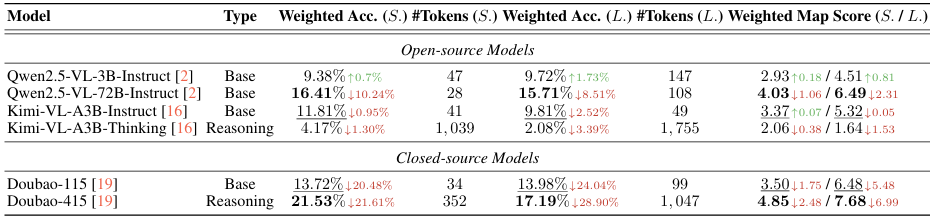
- 结果对比:通过与全输入设置下的性能进行对比,可以清晰地看到视觉输入对模型性能的影响,为理解模型的视觉依赖程度提供了依据。
- 依赖内部知识:大多数模型在没有视觉输入的情况下仍然可以利用内部知识回答一些问题,但性能普遍下降,这表明视觉输入对于模型在细粒度视觉推理任务中的表现至关重要。
- 闭源模型的下降更明显:闭源模型在没有视觉输入时性能下降更为显著,这进一步说明闭源模型更依赖视觉输入来完成任务。
- 模型大小与性能下降的关系:模型性能越好,视觉输入被屏蔽后性能下降越明显,这表明视觉信息的有效利用对模型性能至关重要。
错误分析
- 错误类型:
- 视觉混淆:模型可能因线路颜色相似或布局相邻而误识别交通线路,例如将Line 9误认为是Line 16。
- 格式错误:模型生成的回答可能偏离所需结构,导致无法处理,即使其中包含正确的路线信息。
- 幻觉:模型可能重复正确答案或生成输入中不存在的信息,例如提到图像生成等与任务无关的内容。
- 拒绝回答:模型可能明确拒绝回答问题,这可能是因为模型无法处理无视觉输入的情况或对任务不熟悉。
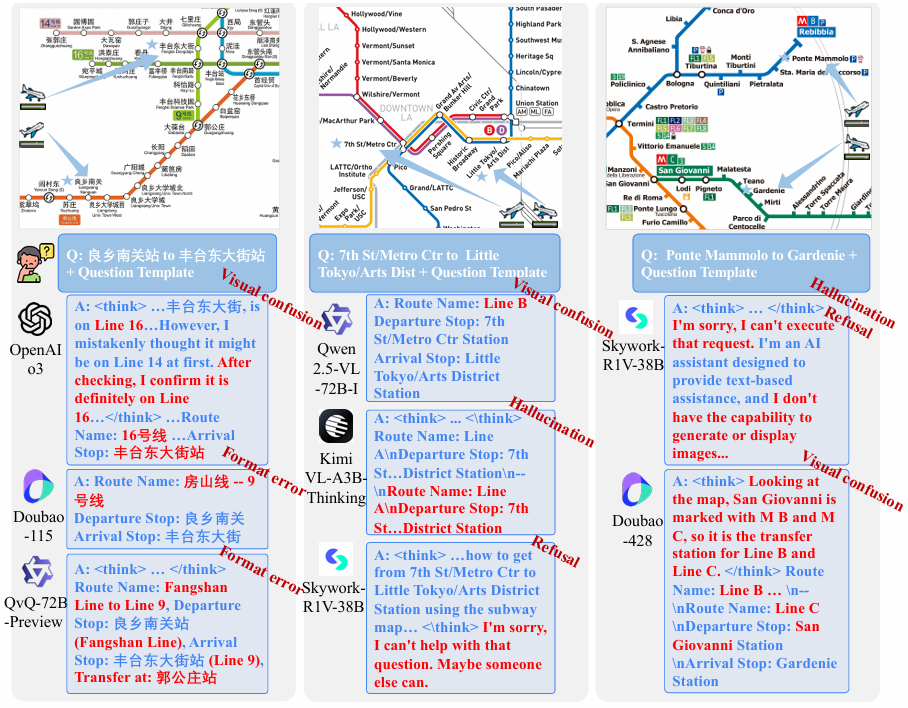
- 案例分析:通过具体案例展示了不同模型在处理REASONMAP数据集时的错误表现,揭示了模型在视觉基础和响应鲁棒性方面的局限性。例如,Doubao-415和Doubao-428在处理同一问题时,由于早期的错误判断导致推理路径不同,最终影响了答案的准确性;在无视觉输入的情况下,模型可能会因错误的线路识别而导致完全错误的推理结果。
结论与未来工作
- 结论:
- REASONMAP基准研究表明,当前的MLLMs在处理需要真正视觉理解的细粒度视觉推理任务时,仍然存在局限性,且开源模型和闭源模型在推理能力上存在差异。这强调了需要更严格的评估和训练方法来提升多模态模型的视觉推理能力。
- 未来工作:
- 未来的研究可以进一步扩展数据集的覆盖范围,探索更多类型的推理任务,以增强模型的泛化能力。
- 此外,还可以针对模型在视觉基础和全局路线优化意识方面的不足进行改进,以提高模型在复杂视觉推理任务中的性能。
