模型量化(Model Quantization)
目录
一、基础概念
1、计算的核心——数字、存储与计算
(1) 所有数字任务最终都归结为数字计算
(2)数值精度
(3)混合精度
2、什么是模型量化?
3、why do?
二、量化原理及类型
1、量化原理
2、量化类型
(1)按量化位宽分类
(2)按量化方法分类
(3)按量化对象分类
3、实现步骤
三、举例
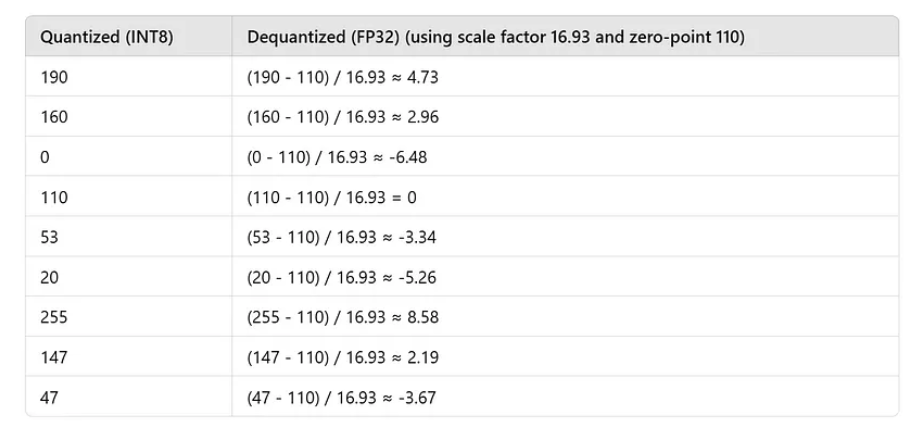
1、对称量化 +FP32-->INT8
2、非对称量化 +FP32-->INT8
四、典型模型量化方法
随着人工智能技术兴起,学术界和工业界逐渐开始重视复杂神经网络模型在边缘计算硬件部署困难的问题. 如何能够有效地降低深度神经网络模型的空间和时间复杂度,达到模型压缩和推理加速的目的.?目前流行的方法主要分为模型剪枝、知识蒸馏、神经网络结构搜索(NAS)、张量分解和模型量化(Quantization)等。
基于量化的方法可以通过减少网络模型运算数值的位宽来达到压缩和加速深度神经网络的目的,从而使深度神经网络具有部署在资源受限、低位宽的边缘设备的条件,一种在模型训练和推理方面都取得了巨大成功的方法。
一、基础概念
1、计算的核心——数字、存储与计算
(1) 所有数字任务最终都归结为数字计算
本质上计算机只理解数字。提供给计算机的每一幅图像、每一个单词或每一条指令,最终都会被转化为二进制数字(0 和 1)来表示【例如,一张黑白图像(灰度图),每个像素的亮度用 0-255 的整数表示(0 为纯黑,255 为纯白)。假设某像素亮度为「128」,其二进制表示为 10000000】。我们编写的软件指令(代码)最终会被转化为 CPU 或 GPU 执行的数值运算。这些硬件单元每秒钟会执行数百万甚至数十亿次加法、乘法以及其他算术运算,以完成各种任务。
由于计算中的所有内容最终都归结为数字,因此存储和处理效率至关重要。较大的数字(或高精度数字)需要更多的比特来存储,并且需要更多的时间来处理。如果我们使用比必要的更多的比特来表示数据,我们就会浪费内存和计算能力。相反,使用更少的比特(低精度)可以节省空间,并且有可能加速计算-------只要我们能够在不丢失重要信息的情况下做到这一点,挑战在于找到数值精度与效率之间的正确平衡。
同样人工智能模型(CNN 或 LLM),这些模型只处理数字。神经网络需要数值输入,因此我们提供给它们的任何数据(图像、音频、文本)都必须首先被编码为数字。
- 图像变为像素张量——即代表亮度或颜色通道的数字网格。
- 文本被转化为标记 ID 和嵌入向量,将单词转换为有意义的数值向量。
- 音频被处理为数字信号,其中样本值捕获声音以供模型解释。
(2)数值精度
并非所有数字在计算中都是平等的。存在不同的精度类型,定义了数字在二进制中如何存储。 数值精度发挥作用的地方:较小的低精度数字通常可以被更快地处理,并且占用更少的内存,从而提升整体模型性能。【如,使用 8 位整数(而不是 32 位浮点数)可以为深度学习模型提供高达 4 倍的速度和内存使用改进】
主要的几种类型:
- FP32【32位浮点数】:每个数字使用 32 位,因为提供了高精度和范围,多年来,FP32 一直是训练神经网络的标准,然而,FP32 占用大量内存和计算资源。每个权重、激活值和梯度都是 4 字节。
- FP16【16位浮点数】:也称半精度浮点数,每个数字仅使用 16 位(1 位符号位、5 位指数位和 10 位尾数位),为了减小尺寸而牺牲了一些精度,使用的内存是 FP32 的一半,并且可以在支持的硬件上显著加速计算【例如,在 NVIDIA A100 GPU 上,float16 矩阵乘法的峰值吞吐量是 float32 的 16 倍。使用 FP16 可以允许以更大的批量进行训练,或者部署具有更低延迟的模型】,缺点是精度和动态范围降低。
- BF16【16位脑浮点数】:BF16 是一种在张量处理单元(TPU)和较新的 GPU 上广泛使用的替代 16 位浮点格式(1 位符号位、8 位指数位和 7 位尾数位),与 FP32 相同的范围(因为它有 FP32 的大指数),但精度较低(只有 7 位小数)。
- INT8【8位整数】:固定点 8 位表示(每个数字 1 字节)。与浮点数不同,整数没有“小数”位或指数的概念,一个 INT8 数字比 FP32 值小 4 倍,因此模型的大小会缩小到原来的四分之一,且整数数学可以并行执行,具有更高的吞吐量&&需要在内存和处理器之间移动的数据更少。 INT8 广泛用于部署训练好的模型(特别是在边缘设备和生产环境中),因为它可以显著降低推理延迟和内存使用。但是,只有 256 个可能的值,8 位量化不可避免地会引入舍入误差。如果只是简单地进行量化,会损害模型的准确性——因此需要使用校准和量化感知训练等技术来最小化损失。
- INT4【4位整数】:不是大多数框架中的标准数据类型,但它已成为模型压缩研究的热点领域【一个在 FP32 中为 32 GB 的模型,在 4 位整数形式中可能只有 4 GB——节省了大量的空间】,最近的研究表明,经过精心微调的 4 位模型几乎可以与 16 位模型相媲美——例如,QLoRA 方法能够将一个 650 亿参数的语言模型在 4 位精度下进行微调,与完整的 16 位相比,性能没有显著下降。
(3)混合精度
混合精度,这意味着在一个工作流程中使用多种数值精度。同时使用不同精度的数值格式(如 FP32、FP16、BF16、INT8 等)来表示和计算数据(包括模型权重、激活值、梯度等),以在保证模型精度基本不受影响的前提下,提升计算效率、降低内存占用和能耗。
2、什么是模型量化?
模型量化是指===将深度学习模型中的浮点数参数转换为位数较少的整数表示,以减少模型的存储空间和计算资源需求。 具体来说,模型量化通过将高精度浮点数(如FP32)转换为低精度整数(如INT8、INT4等),来降低模型的计算复杂度和内存占用。【即原来表示一个权重需要使用float32表示,量化后只需要使用int8来表示就可以啦,仅仅这一个操作,我们就可以获得接近4倍的网络加速!】这一过程虽然会带来一定的精度损失,但通常可以通过精心设计的映射方法和后处理技术来最小化这种损失,从而在保持模型性能的同时实现显著的效率提升。
3、why do?
大量的基于深度学习的网络模型。这些模型都有一个特点,即大而复杂、适合在N卡上面进行推理,并不适合应用在手机等嵌入式设备中,而客户们通常需要将这些复杂的模型部署在一些低成本的嵌入式设备中。所以模型量化主要是为了:
- 缩小模型体积: 低精度数值占用更少内存。
- 加速推理: 许多硬件加速器(CPU、GPU、NPU)对低精度数据的处理速度更快,因为定点运算相比浮点运算通常更简单、更快。
- 降低功耗: 由于量化后的数据占用的存储空间更小,计算量和内存访问减少,能耗随之降低。
- 实现边缘部署: 许多硬件设备(如专用的 AI 芯片、GPU 等)对低精度计算提供了专门的硬件优化,可以高效地处理量化后的神经网络运算,在资源受限的设备上运行大模型
一个拥有 1750 亿参数的模型(如 GPT-3),其在 FP32 中的大小约为 700 GB,理论上可以缩小到 INT8 中的约 175 GB,或者在 INT4 中的约 87 GB。
这是具有变革性的:_曾经需要多块高端 GPU 才能运行的模型,通过量化可以被压缩到单个 GPU 甚至 CPU 上运行_。例如,拥有 1760 亿参数的 BLOOM 模型需要 8 块 80GB 的 GPU 才能在全精度下运行,但通过 8 位量化,研究人员已经能够在单台机器上运行它。
二、量化原理及类型
1、量化原理

量化的核心原理是通过建立浮点数与定点数之间的映射关系,实现数据精度的压缩与恢复,其核心过程围绕量化(Quantize浮点->定点) 和反量化(Dequantize定点->浮点) 展开,具体如下:

R表示输入的浮点数据,Q表示量化之后的定点数据,Z表示Zero Point(与定点数 “0” 对应的浮点数,用于消除浮点数与定点数之间的偏移误差)的数值,S表示Scale(浮点数范围与定点数范围的比值)的数值,根据S和Z这两个量化参数来确定这个映射关系。
scale(缩放因子) 和zero-point(零点) 是建立浮点数与定点数映射关系的核心参数,不同的计算方式直接决定了量化精度和误差大小。


2、量化类型
(1)按量化位宽分类
根据存储一个权重元素所需的位数,可以分为8bit量化、4bit量化、2bit量化和1bit量化。
| 位宽 | 特点与适用场景 |
|---|---|
| 8-bit | 最常用,精度损失小,广泛支持(INT8/FP8)。 |
| 4-bit | 极限压缩,适合大模型部署(如 AWQ、GPTQ)。 |
| 2-bit | 极端压缩,精度损失大,需配合误差补偿机制。 |
| 1-bit | 极限压缩,仅限特定任务或研究使用(如 BNN)。 |
(2)按量化方法分类
量化方法决定了映射浮点数到低位宽的策略。
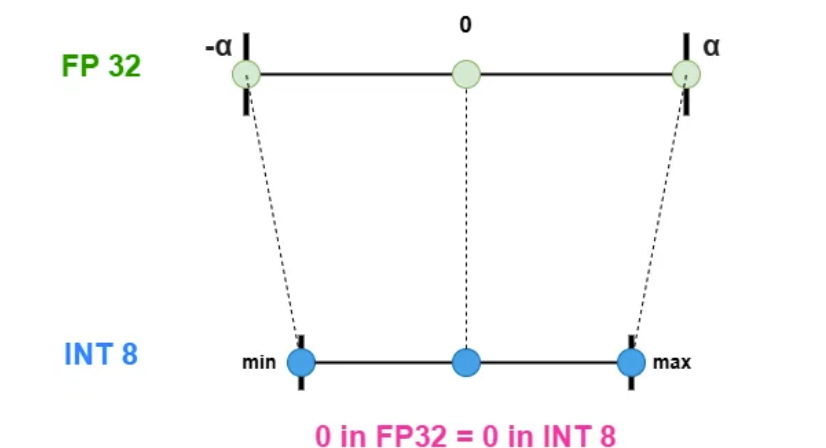
- 对称量化:零点对齐到 0,正负范围对称。也就是说,量化值的范围在正数和负数之间是平衡的,从(-α)到(α)。
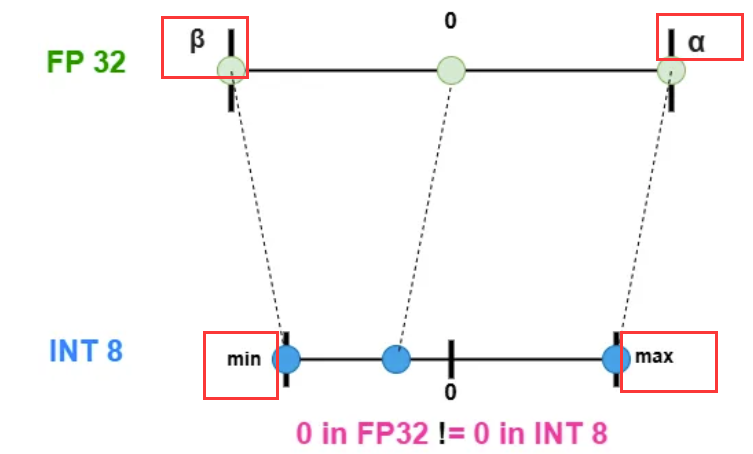
- 非对称量化:允许零点偏移,正负范围不对称,把浮点范围的最小值(β)和最大值(α),映射到量化范围的最小值和最大值
从训练视角来看,我们可以在模型的训练前或训练后进行量化,据此可以分为以下几种:
| 策略 | 阶段 | 是否需要重训练 | 精度 | 适用 |
|---|---|---|---|---|
| PTQ (Post-Training Quant.) | 训练后 | ❌ | 稍低 | 快速部署 |
| QAT (Quant.-Aware Training) | 训练中 | ✅ | 高 | 极致精度 |
| QAF (Quant.-Aware Fine-tuning) | 微调阶段 | ✅ | 中高 | 资源有限 |
训练后量化(PTQ) :在不重新训练的情况下,对已训练好的模型进行参数量化,只需准备少量校准数据,简单高效但会引入一定精度损失。
量化感知训练(QAT):在训练过程中模拟量化,并更新量化参数。通常比 PTQ 精度更高,特别适用于大型或复杂模型。但是计算开销更大,因为需要重新训练。
量化感知微调(QAF):从一个已训练好的 FP32 模型出发,在模拟量化的同时进行少量微调,使权重适应低比特表示。-----在 PTQ 与完整 QAT 之间取得折中:比从头训练快得多,但通常比 PTQ 恢复更多精度——尤其当原始 PTQ 出现明显下降时。
从推理视角来看,根据量化过程在推理前后,可以分为:
离线量化:上线前完成全部量化,即提前确定好激活值的量化数 S(scale) 和 Z(zero−point),在推理时直接使用。
- 比如之前我们提到PTQ,是离线量化里最常见的实现方式。在大多数情况下,离线量化指的就是PTQ。
离线量化 ≈ PTQ(Post-Training Quantization)
- 离线量化又可以细分为:
- 静态量化(Static Quantization):同时量化权重和激活值,推理前用校准数据集一次性算好量化参数。因为属于离线量化之PTQ,所以也叫静态离线量化(PTQ-Static)
- 动态量化(Dynamic Quantization):仅量化权重,激活值在推理时实时量化。因为属于离线量化之PTQ,所以也叫动态离线量化(PTQ-Dynamic)
- 静态量化(Static Quantization):同时量化权重和激活值,推理前用校准数据集一次性算好量化参数。因为属于离线量化之PTQ,所以也叫静态离线量化(PTQ-Static)
在线量化:推理时才量化,即在推理过程中动态计算量化参数
(3)按量化对象分类
根据量化的对象的不同,可以分为不同的层级:
- 权重量化(Weight Quantization): 仅量化模型权重。因为只量化权重,也称为weight-only quantization
- 激活量化(Activation Quantization): 也对各层输出(激活值)进行量化。
- 梯度量化(Gradient Quantization): 训练时对梯度进行量化以减少通信开销。
- KV缓存量化(KV Cache Quantization): 对注意力中的KV缓存进行量化以降低显存占用。
- 偏置量化(Bias Quantization): 有时也对偏置进行量化,但通常保持较高精度。
也就是说,在模型量化过程中,量化可以应用于模型的多个部分,包括:
- 模型参数(weights):如权重矩阵,这些是模型训练过程中学习到的参数。【通常而言,模型的参数分布较为稳定,因此对参数 weight 做量化较为容易。】
- 激活值(activations):如神经元的输出值,这些值在前向传播过程中动态生成。
- 梯度(gradient):如反向传播过程中计算的梯度值,用于更新模型参数。
- KV Cache:在 Transformer 的自回归解码阶段,KV Cache 用于缓存每一层的键(Key)和值(Value)张量,以避免重复计算,从而显著提升长序列生成的效率。
- 偏置(Bias):指模型中各层加性偏置项(如线性层、卷积层后的 bias)。由于偏置参数量远小于权重(百万级 vs 十亿级),其对整体模型大小的影响有限,因此通常不量化或仅使用较高精度(如 INT16或 FP16),仅在极端压缩需求下(如边缘设备部署),才考虑与权重一并量化至 INT8。
3、实现步骤
- 步骤1-在输入数据(通常是权重或者激活值)中统计出相应的min_value和max_value;
- 步骤2-选择合适的量化类型,对称量化(int8)还是非对称量化(uint8);
- 步骤3-根据量化类型、min_value和max_value来计算获得量化的参数Z/Zero point和S/Scale;
- 步骤4-根据标定数据对模型执行量化操作,即将其由FP32转换为INT8;
- 步骤5-验证量化后的模型性能,如果效果不好,尝试着使用不同的方式计算S和Z,重新执行上面的操
三、举例
1、对称量化 +FP32-->INT8

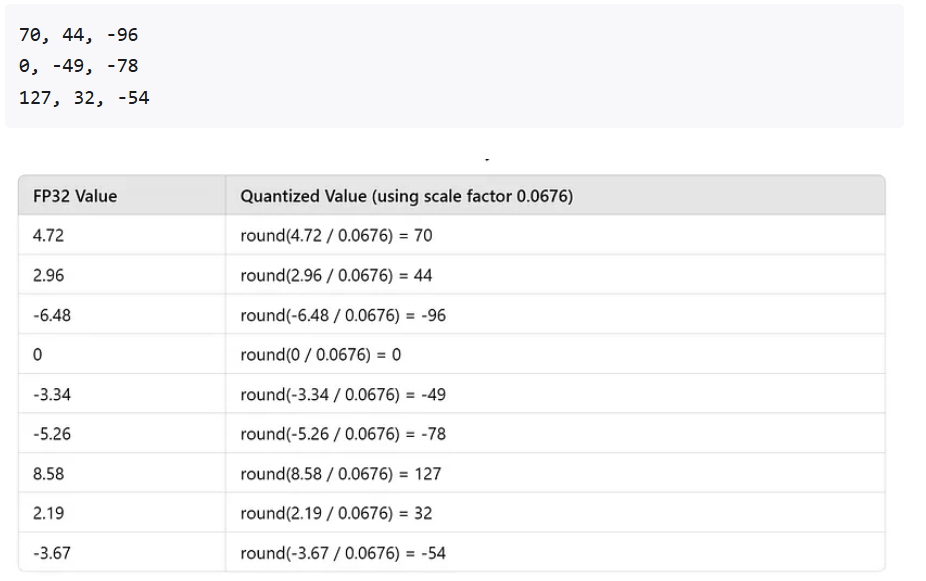
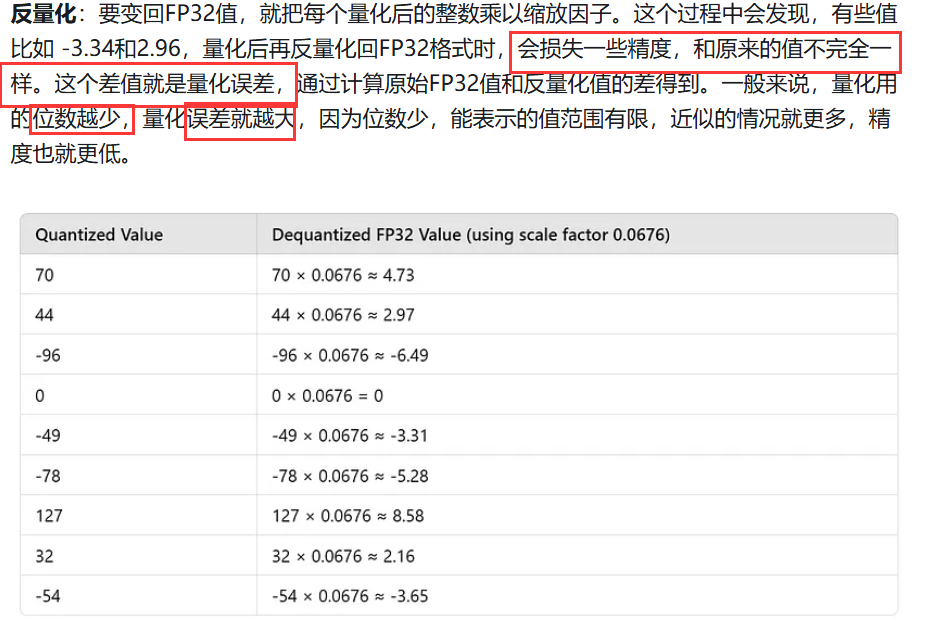
2、非对称量化 +FP32-->INT8

四、典型大模型量化方法
| 方法 | 发表时间 | 影响力 | 说明与评价 | 代表论文链接 |
|---|---|---|---|---|
| EasyQuant | 2020 | ★★★☆☆ | 简单高效的后训练量化,适用快速工程部署。 | EasyQuant论文 |
| GPTQ | 2022 | ★★★★★ | 基于梯度反向传播的PTQ,精度优异,广泛应用于大型Transformer模型量化。ICLR | GPTQ论文 |
| QLoRA | 2023 | ★★★★☆ | 结合低秩适配微调与INT4量化,适合低资源微调,提升训练与部署效率。ICLR | QLoRA论文 |
| AWQ | 2023 | ★★★★★ | 激活感知权重量化,保护关键权重,无需反向传播,速度快且精度高,适用大模型部署。被评为 MLSys 2024 最佳论文之一 | AWQ论文 |
| SmoothQuant | 2023 | ★★★★☆ | 通过激活权重平滑迁移实现激活与权重联合INT8量化,保证精度几乎无损,显著提升推理速度和效率。 | SmoothQuant论文 |
| QuIP | 2023 | ★★★★☆ | 利用不相干性处理实现极端低比特(2-bit)后训练量化,结合随机正交变换,理论分析支持,开创低比特高精度量化新高度。 | QuIP论文 |
| OmniQuant | 2023 | ★★★★☆ | 统一可微量化框架,采用Block-wise量化误差最小化和可学习参数,兼顾多精度与高效训练。ICLR | OmniQuant论文 |
-
PTQ 方法:EasyQuant, GPTQ, AWQ, SmoothQuant, QuIP, OmniQuant
-
QAT / 微调量化方法:QLoRA
ref:
模型量化详解-CSDN博客
深度学习中的模型量化入门 - 知乎
【模型压缩系列-1】一篇文章带你全面了解模型量化(Model Quantization)——全局篇 - 汤佘 - 博客园
2w字解析量化技术,全网最全的大模型量化技术解析 - 知乎
(33 封私信 / 2 条消息) 目前大模型量化方案有很多,有哪些比较SOTA的量化方案? - 知乎