FastDeploy2.0:Prometheus3.5.0通过直接采集,进行性能指标分析
Prometheus的安装部署详见《大模型性能指标的监控系统(prometheus3.5.0)和可视化工具(grafana12.1.0)基础篇》
一、概述
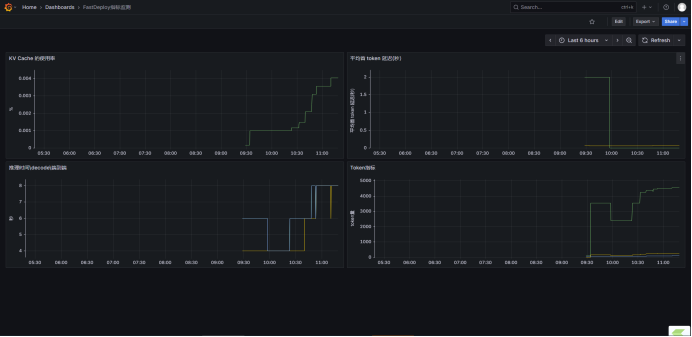
下图就是FastDeploy2.0的几个核心指标显示效果,后面详细介绍如何操作。
二、Prometheus的两种采集方式
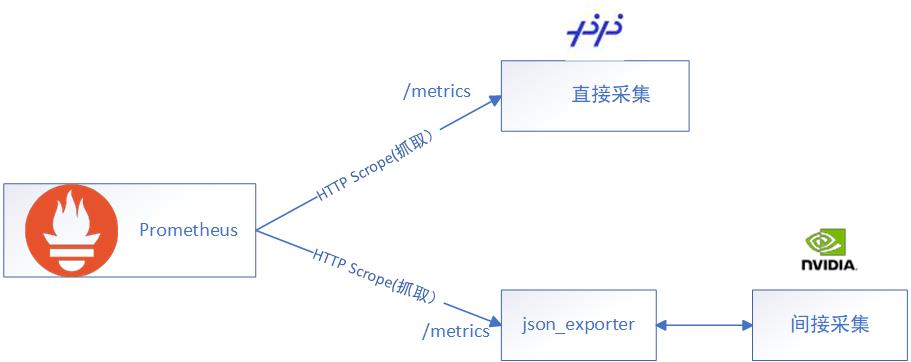
直接采集和间接采集
直接采集就是埋点式的,比如你自己的应用程序用 Prometheus 客户端的代码自己去埋点。比如FastDeploy就是直接采集,它已经将埋点埋好了,把 metrics 断点暴露出来了。
间接采集:虽然TensorRT-LLM也把metrics 断点暴露出来了,但格式不满足要求,我们就需要利用第三方工具(json_exporter)转换成Prometheus识别的指标。
可以使用的第三方Exporter,详见《第三方的Exporter列表》。
三、修改prometheus.yml
2.1进入容器里面:
docker exec -it prometheus /bin/sh
2.2增加数据来源
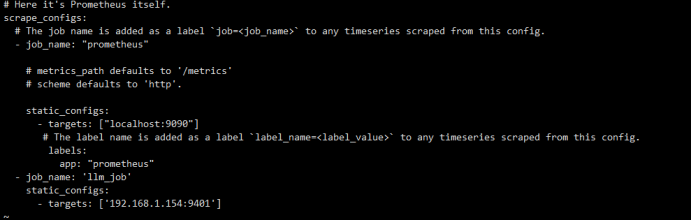
#vi /etc/prometheus/prometheus.yml
- job_name: "llm_job"
static_configs:
- targets: ["192.168.1.154:9401"]
2.3手动启动
使用 promtool 工具
promtool check config /etc/prometheus/prometheus.yml

使用 Prometheus 的 Web 接口发送一个 HTTP POST 请求到 /targets/-/reload 来重新加载配置
curl -X POST http://172.26.142.154:9090/-/reload
2.4查看抓取状态

Endpoint:端点,可以抓取的指标来源。
Target:目标,包含了端点地址,端口的状态等信息。
四、Grafana添加数据源Prometheus
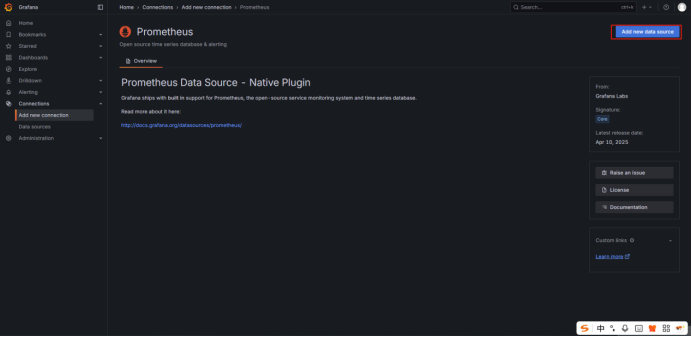
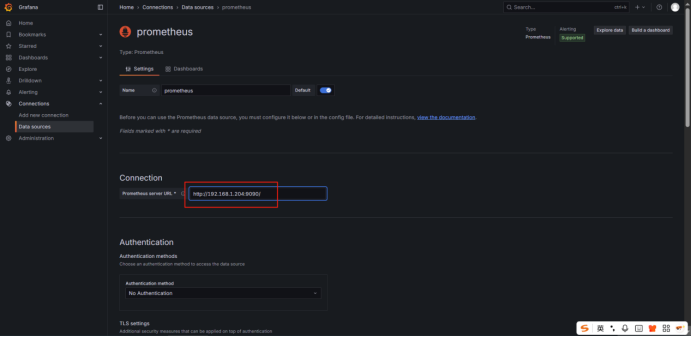
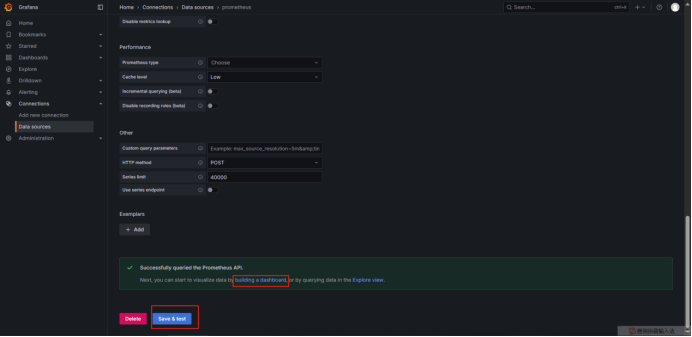
五、FastDeploy2.0性能指标说明
http://192.168.1.154:9401/metrics可以看到下面的具体指标。
5.1首次token时间(time_to_first_token_seconds)
fastdeploy:time_to_first_token_seconds_count 30.0
fastdeploy:time_to_first_token_seconds_sum 174.25801753997803
总请求数(count):30 个
总首 token 延迟时间(sum):约 174.26 秒
平均首 token 延迟(mean):174.26/30≈5.81 秒
首 token 延迟主要由 Prefill 阶段耗时 决定,因为:
Prefill = 输入编码 + KV Cache 构建
-
- 模型需要处理整个输入 prompt
- 并为每个 token 计算并缓存 Key/Value 向量
- 复杂度为 O(n²),n 是输入长度
5.2生成每个输出 token 所需的时间(time_per_output_token_seconds)
fastdeploy:time_per_output_token_seconds_count 6925.0
fastdeploy:time_per_output_token_seconds_sum 828.3923425674438
用 sum / count 得到 平均每个 token 的生成时间:
衡量大语言模型(LLM)在流式输出(streaming)过程中,生成每一个输出 token 的延迟性能。它反映了模型的“首 token 延迟之后的流畅度”,也就是常说的“吐字速度”。
5.3模型“持续输出”阶段的耗时request_decode_time_seconds(from first token to last token)
fastdeploy:request_decode_time_seconds_count 1.0
fastdeploy:request_decode_time_seconds_sum 4.071532964706421
在大模型推理中,整个过程可以分为两个主要阶段:
| 阶段 | 说明 |
| 1. Prefill / Encoding | 处理输入 prompt,计算 KV Cache,生成 第一个输出 token(首 token) |
| 2. Decode / Generation | 基于已生成的 token,逐个预测下一个 token,直到结束(EOS) |
request_decode_time_seconds 就是 第 2 阶段的耗时。
5.4模型推理时间request_inference_time_seconds
fastdeploy:request_inference_time_seconds_count 30.0
fastdeploy:request_inference_time_seconds_sum 1002.6503601074219

| fastdeploy:request_inference_time_seconds指从 “模型推理开始” 到 “生成最后一个 token” |
5.5端到端完整延迟request_latency_seconds
fastdeploy:e2e_request_latency_seconds_count 1.0
fastdeploy:e2e_request_latency_seconds_sum 5.990736722946167
e2e_request_latency_seconds 指从请求到达系统到最终响应返回(端到端完整延迟).
类比:
- request_inference_time ≈ 厨师炒菜的时间
- e2e_request_latency ≈ 顾客从点餐到上菜的总时间(含等位、下单、传菜)
注:e2e_request_latency ≥ request_inference_time
5.6请求在系统中排队等待处理的时间request_queue_time_seconds
含义:请求在 预处理完成后,到 推理开始前 所等待的时间。
也就是 排队时间(Queue Time),反映了系统调度能力和当前负载情况。
这段时间内,请求已经准备好(prompt 已解析、tokenized),但因资源不足或调度策略未能立即执行。
这个指标直接体现了系统的 资源紧张程度 和 调度效率。
| queue_time 值 | 可能原因 |
|---|---|
| ✅ 接近 0s | 系统空闲,资源充足,请求立即处理 |
| ⚠️ 几秒 ~ 十几秒 | 系统负载较高,有少量排队 |
| ❌ 数十秒或更高 | 系统过载,资源不足,可能出现雪崩 |
可以理解为 “我在排队,等系统有资源来处理我”。
5.7 GPU 缓存使用率gpu_cache_usage_perc
fastdeploy:gpu_cache_usage_perc 0.14959652389819988
当前 GPU 上用于存储 KV Cache(Key-Value Cache)的显存占用百分比。
(一)在大语言模型的 自回归生成(autoregressive decoding) 过程中:
1.每次生成一个 token,都需要依赖之前所有 token 的注意力(attention)计算。
2.为了避免重复计算历史 token 的 Key 和 Value 向量,系统会将它们缓存在 GPU 显存中,这就是 KV Cache。
(二)KV Cache 的作用:
避免重复计算,大幅提升生成速度(降低延迟)
支持流式输出(streaming)
是实现高效批处理(batching)和连续批处理(continuous batching)的基础
5.8生成的输出 token 数(request_generation_tokens)
fastdeploy:request_generation_tokens_count 1.0
fastdeploy:request_generation_tokens_sum 56.0
含义:每个请求实际生成的输出 token 数量(即 max_new_tokens 或 stream 结束前生成的 token 数)
这是衡量 响应长度 和 decode 负载 的关键指标。
作用:
| 用途 | 说明 |
|---|---|
| 🔢 吞吐量计算 | 结合时间指标可计算 tokens per second (TPS) |
| 💰 成本计量 | 输出 token 是 LLM 计费的主要依据(如 OpenAI) |
| 📊 性能归因 | 分析长输出是否导致延迟升高 |
| 🚫 防滥用 | 检测是否有异常长输出(如无限生成) |
5.9用户在请求中设置的 max_tokens 参数值request_params_max_tokens
fastdeploy:request_params_max_tokens_count 1.0
fastdeploy:request_params_max_tokens_sum 110.0
作用:
| 用途 | 说明 |
|---|---|
| 📏 资源预估 | 系统可根据此值预分配 KV Cache 显存 |
| ⏱️ 延迟预测 | 可预估最大生成时间(结合 TPOT) |
| 🔒 安全控制 | 防止用户请求过长输出导致服务过载 |
| 🆚 利用率分析 | 对比 generation_tokens 看实际使用率 |
5.10输入 prompt 的长度(token 数)request_prompt_tokens
fastdeploy:request_prompt_tokens_count 1.0
fastdeploy:request_prompt_tokens_sum 9.0
作用:
| 用途 | 说明 |
|---|---|
| ⏱️ 首 token 延迟分析 | prompt 越长,time_to_first_token 通常越长 |
| 💾 显存占用评估 | 长 prompt 占用更多 KV Cache(prefill 阶段) |
| 📈 上下文利用率 | 对比 max_model_len 看是否支持长文本 |
| 🤖 RAG/Agent 场景监控 | 检测是否传入了过长的知识库内容 |
5.11request_prefill_time
指标全是0,不知道为什么,有清楚的朋友,麻烦告知我。