关系型数据库核心组件:视图、函数与存储引擎详解
在关系型数据库(RDBMS)的体系中,视图、函数和存储引擎是提升数据处理效率、简化操作流程的核心组件。视图为复杂查询提供抽象层,函数封装重复逻辑,存储引擎则决定数据的存储与访问方式。本文将深入解析这三者的原理、用法及实战场景,帮助开发者构建更高效的数据库应用。
目录
一、视图(View):查询结果的虚拟表
1.1 视图的核心作用
1.2 视图的创建与管理
1.2.1 创建视图
1.2.2 查询视图
1.2.3 修改与删除视图
1.3 视图的更新限制
1.4 实战场景:视图的典型应用
二、函数(Function):封装重复的计算逻辑
2.1 函数的分类
2.2 自定义函数的创建与使用
2.2.1 创建自定义函数
2.2.2 调用函数
2.2.3 删除函数
2.3 函数与存储过程的区别
2.4 实战场景:自定义函数的应用
三、存储引擎(Storage Engine):数据的存储与管理核心
3.1 MySQL 常见存储引擎及特性
3.1.1 InnoDB(默认引擎)
3.1.2 MyISAM
3.1.3 Memory(Heap)
3.1.4 Archive
3.2 存储引擎的选择与配置
3.2.1 指定表的存储引擎
3.2.2 查看与修改存储引擎
3.3 存储引擎的性能优化要点
四、总结
一、视图(View):查询结果的虚拟表
视图是基于 SQL 查询结果构建的虚拟表,本身不存储数据,仅保存查询逻辑。它像一个 “窗口”,让用户通过简化的方式访问复杂的数据集,同时增强数据安全性和查询复用性。
1.1 视图的核心作用
简化复杂查询:将多表关联、聚合计算等复杂逻辑封装为视图,用户无需重复编写 SQL。数据安全隔离:通过视图暴露部分字段(如隐藏敏感信息),限制用户对原始表的直接访问。逻辑抽象:当底层表结构变更时,可通过修改视图保持对外接口不变,降低系统耦合度。
1.2 视图的创建与管理
1.2.1 创建视图
实例:
select `prop`.`prop_name` AS `prop_name`,`area`.`mode` AS `mode` from (`area` join `prop` on((`area`.`id` = `prop`.`area_id`)))
1.2.2 查询视图
视图的使用与普通表一致,直接通过SELECT查询:
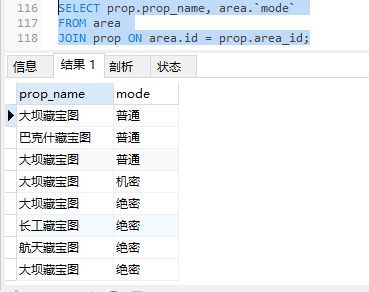
1.2.3 修改与删除视图
修改视图逻辑:使用CREATE OR REPLACE VIEW覆盖原有视图。
删除视图:
1.3 视图的更新限制
视图通常用于查询,若需通过视图修改数据(INSERT/UPDATE/DELETE),需满足以下条件:
视图基于单表创建,且未包含GROUP BY、DISTINCT、聚合函数(如SUM)等。
修改的字段必须是底层表中实际存在的字段,且无计算逻辑(如SELECT id+1 AS new_id不可更新)。
实例:可更新的简单视图:
-- 基于单表的视图,可直接更新
CREATE VIEW user_basic AS
SELECT id, name, email FROM users;
1.4 实战场景:视图的典型应用
报表生成:将月度销售报表、用户活跃度统计等固定逻辑封装为视图,简化报表工具的调用。
多租户隔离:在 SaaS 系统中,为每个租户创建视图,自动过滤其所属数据(如WHERE tenant_id = 1001)。
历史数据查询:通过视图关联 “当前表” 与 “历史归档表”,实现透明的数据访问。
二、函数(Function):封装重复的计算逻辑
数据库函数是预先定义的代码块,用于实现特定的计算或操作,可接收参数并返回结果。合理使用函数能减少重复代码,提升 SQL 的可读性和可维护性。
2.1 函数的分类
根据定义主体,函数分为两类:
内置函数:数据库自带的函数(如COUNT()、DATE_FORMAT()),直接调用即可。
自定义函数(UDF):用户根据业务需求编写的函数,需先创建再使用。
2.2 自定义函数的创建与使用
2.2.1 创建自定义函数
实例:创建求和函数:
CREATE DEFINER=`root`@`localhost` FUNCTION `my_add`(`a` int,`b` int) RETURNS intDETERMINISTIC BEGIN#Routine body goes here...RETURN a+b; END
2.2.2 调用函数
在SELECT、UPDATE等语句中直接调用:
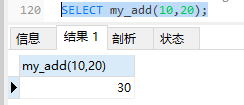
2.2.3 删除函数
DROP FUNCTION IF EXISTS my_add;
2.3 函数与存储过程的区别
| 特性 | 函数(Function) | 存储过程(Procedure) |
| 返回值 | 必须有返回值(单个) | 可无返回值,或通过 OUT 参数返回多个 |
| 调用场景 | 可在SELECT中直接调用 | 需通过CALL语句单独调用 |
| 事务支持 | 不支持事务操作 | 支持事务、异常处理 |
| 适用场景 | 简单计算(如格式转换、数值计算) | 复杂业务逻辑(如订单创建流程) |
2.4 实战场景:自定义函数的应用
数据格式转换:如将手机号中间 4 位替换为*(mask_phone('13812345678') → '138****5678')。
业务规则封装:如根据订单金额计算积分(满 100 元送 10 积分,满 200 元送 25 积分等阶梯规则)。
复杂查询简化:如通过函数封装多表关联的子查询,直接返回关联结果(如get_user_dept(100) → '研发部')。
三、存储引擎(Storage Engine):数据的存储与管理核心
存储引擎是数据库底层负责数据存储、索引管理、事务处理的组件。不同存储引擎有不同的特性,选择合适的引擎直接影响数据库的性能、安全性和功能支持。
3.1 MySQL 常见存储引擎及特性
3.1.1 InnoDB(默认引擎)
核心特性:
支持事务(ACID 特性)和行级锁,适合高并发写入场景(如电商订单表)。
支持外键约束,保证数据参照完整性。
采用聚簇索引(主键与数据物理存储在一起),查询效率高。
支持崩溃恢复(通过 redo 日志和 undo 日志)。
适用场景:订单表、用户表等需要事务支持和高并发读写的核心业务表。
3.1.2 MyISAM
核心特性:
不支持事务和行级锁,只支持表级锁,读性能优异但写入并发差。
占用存储空间小,适合读多写少的场景。
支持全文索引(MySQL 5.6 后 InnoDB 也支持)。
适用场景:日志表、静态数据报表(如历史订单归档表)。
3.1.3 Memory(Heap)
核心特性:
数据存储在内存中,读写速度极快,但重启后数据丢失。
支持哈希索引,适合临时数据缓存。
适用场景:会话缓存、临时计算结果存储(如高频访问的配置表)。
3.1.4 Archive
核心特性:
以压缩格式存储数据,适合归档大量历史数据(如日志归档)。
只支持INSERT和SELECT,不支持更新和删除。
适用场景:系统日志归档、用户行为历史记录等极少修改的数据。
3.2 存储引擎的选择与配置
3.2.1 指定表的存储引擎
创建表时通过ENGINE关键字指定:
-- 创建InnoDB引擎的订单表(支持事务)
CREATE TABLE orders (
id INT PRIMARY KEY AUTO_INCREMENT,
user_id INT,
amount DECIMAL(10,2),
create_time DATETIME
) ENGINE = InnoDB;
-- 创建MyISAM引擎的日志表(读性能优先)
CREATE TABLE access_logs (
id INT PRIMARY KEY AUTO_INCREMENT,
ip VARCHAR(20),
visit_time DATETIME
) ENGINE = MyISAM;
3.2.2 查看与修改存储引擎
- 查看表的存储引擎:
SHOW TABLE STATUS LIKE 'orders';
- 修改表的存储引擎(可能导致功能丢失,如 MyISAM 转 InnoDB 会丢失全文索引):
ALTER TABLE access_logs ENGINE = InnoDB;
3.3 存储引擎的性能优化要点
InnoDB 优化:
合理设计主键(避免过长,推荐自增 ID),提升聚簇索引效率。
开启innodb_buffer_pool_size(缓存池),减少磁盘 IO(建议设为物理内存的 50%)。
MyISAM 优化:
定期执行OPTIMIZE TABLE优化表碎片,提升查询速度。
适合读多写少场景,避免高并发写入(表级锁会导致阻塞)。
Memory 引擎:
限制表大小(max_heap_table_size),避免内存溢出。
不适合存储敏感数据(重启丢失)。
四、总结
视图、函数和存储引擎从不同层面赋能关系型数据库:
视图通过抽象查询逻辑简化操作,同时增强数据安全性;
函数封装重复计算逻辑,提升 SQL 的可读性和复用性;
存储引擎决定数据的存储方式和功能支持,是性能优化的核心。
在实际开发中,需根据业务场景灵活运用:用视图简化多表查询,用函数封装业务规则,用 InnoDB 处理事务核心表,用 MyISAM 存储静态数据。深入理解这三者的特性与适用场景,能显著提升数据库设计的合理性和系统性能。
后续可进一步学习存储过程、触发器等组件,构建更完善的数据库生态。