[微服务]ELK Stack安装与配置全指南
目录
一、ELK相关介绍
1.1 什么是ELK Stack
1.2 ELK核心组件与功能
1.3 ELK优势
1.4 ES数据库结构对比SqlServer
二、安装ELK
2.1 window安装
2.2 Docker下环境搭建
2.2.1 安装7.16.3版本ElasticSearch
2.2.2 安装7.16.3版本Kibana :
2.2.3 安装8.0.0版本ElasticSearch
2.2.4 配置支持跨域
2.2.5 安装插件
2.3 集群构建
2.3.1 环境准备
2.3.2 集群构建思路
2.3.3 docker-Compose集群配置
三、文章总结
一、ELK相关介绍
1.1 什么是ELK Stack
ELK Stack是由Elasticsearch、Logstash和Kibana三个核心组件构成的日志管理与分析解决方案,支持日志的收集、存储、检索及可视化。Java开发的高性能分布式日志系统,支持亿级的查询。
官网:ELK Stack:Elasticsearch、Kibana、Beats 和 Logstash | Elastic
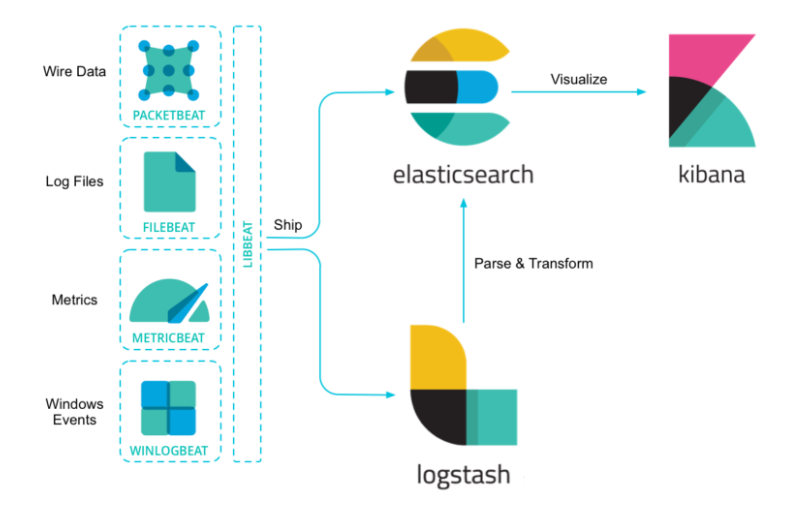
1.2 ELK核心组件与功能
-
Elasticsearch(ES)高性能的数据库引擎
- 分布式搜索与分析引擎,负责海量数据的实时存储、索引与检索,基于Lucene构建,支持水平扩展与高可用架构。
- 特点:自动分片、副本机制、RESTful API接口,适用于全文搜索和结构化数据分析。
-
Logstash 收集和保存数据的工具
- 数据收集与处理管道,分为输入(Input)、过滤(Filter)、输出(Output)三个阶段,支持200+插件,可解析非结构化数据(如日志文件)并进行格式转换。
- 资源消耗较高,常与轻量级工具(如Filebeat)配合使用。
-
Kibana。操作使用管理 ES数据库的客户端
- 数据可视化平台,提供交互式仪表盘、图表及DevTools工具,便于用户查询和分析Elasticsearch中的数据。
4.Beats: 高性能是数据工具.(可选组件)
Beats 不是一个单独的软件,而是一系列的数据采集器.每一个 Beat 都是一个独立的组件,负责采集特定类型的数据,并将这些数据发送到 Elasticsearch 或者 Logstash 进行后续处理。例如,Filebeat 专门用于收集和转发日志文件,Metricbeat 用于收集系统和服务的运行指标,Packetbeat 用于收集网络流量数据等。
1.3 ELK优势
- 支持分布式,支持集群部署,便于横向扩展和高可用。
- 大数据量支持,PB级数据查询---关系型数据库没法比
- 毫秒级响应
- 添加索引时性能稳定
- 支持频繁更新(数据)(不推荐)
- 添加索引,支持近时搜索(1秒延迟)
- 支持结构化查询:支持RESTful API,支持JSON数据结构通过 HTTP查询数据,关系型数据库中支持的各种操作,基本上都可以在这里完成;
1.4 ES数据库结构对比SqlServer
| SqlServer数据库 | ES数据库 |
| 数据库 | Index索引库:以索引为单位,内存保存,提高性能 |
| 数据库表 | type类型: ES在8.0版本去掉类型,但是默认有类型:_doc |
| 表-行 | document 文档: 一个文档就类似于一行数据 |
| 表-列 | field 字段 (非分词字段和分词字段) |
二、安装ELK
2.1 window安装
PS:ES是java开发,所以需要安装jdk,建议安装jdk --version 11 +
1.检查本地是否安装jdk
java -version 2.Jdk下载地址和安装:
https://download.oracle.com/java/17/latest/jdk-17_windows-x64_bin.exe ( sha256)
2.2 Docker下环境搭建
环境准备:
Linux-CentOS7
Docker version: Docker version 23.0.3,
elasticsearch官网:
https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html
2.2.1 安装7.16.3版本ElasticSearch
#拉取镜像
docker pull elasticsearch:7.16.3
#如果没有可用的镜像源,可以用官网自带的下载
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.16.3
#使用docker镜像启动容器 ElasticSearch单节点集群
docker run -p 9200:9200 -p 9300:9300 -d -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms512m -
Xmx512m" elasticsearch:7.16.3
#下面是通过镜像ID启动容器
docker run -p 9200:9200 -p 9300:9300 -d -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms512m -
Xmx512m" 镜像id
#支持跨域的启动
docker run -p 9200:9200 -p 9300:9300 -d -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms512m -
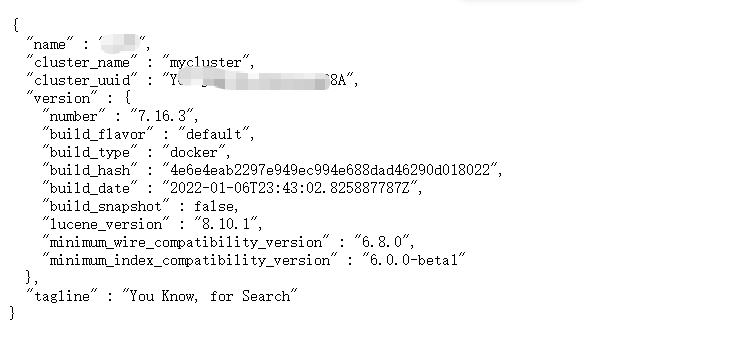
Xmx512m" -e"http.cors.enabled=true" -e "http.cors.allow-origin="*"" elasticsearch:7.16.3ElasticSearch 启动都是集群 无论是一个还是多个,一个就是单节点集群。浏览器访问 ip:9200 如果出现以下界面就是安装成功。
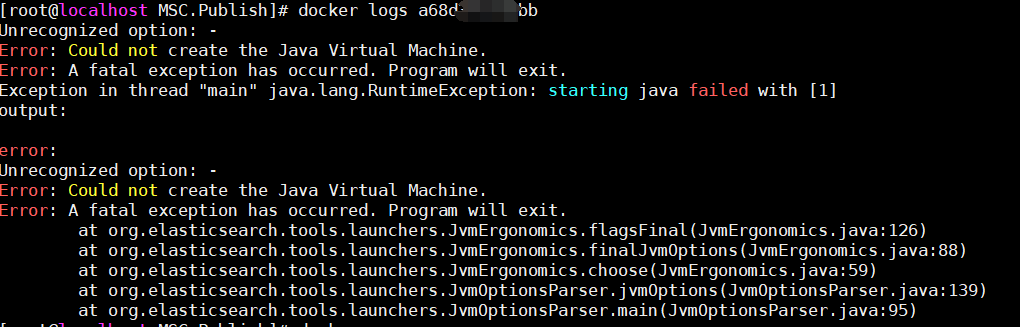
ps:在使用docker命令启动时,注意相关参数的正确写入,否则会出现如下异常“Unrecognized option: - ”
2.2.2 安装7.16.3版本Kibana :
#创建网络(两种都可以,一种是默认一种使用桥接网络)
#保证kibana可以访问es
docker network create elastic#拉取镜像
docker pull docker.elastic.co/kibana/kibana:7.16.3
#运行kibana
docker run --name kib01-test --net elastic -p 5601:5601 -e
"ELASTICSEARCH_HOSTS=http://ip:9200" kibana:7.16.3Kibana默认的端口监听: 5601
2.2.3 安装8.0.0版本ElasticSearch
8.0后的ES安装和以前版本会有不同。
# 拉取镜像
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.0.0
docker pull docker.elastic.co/kibana/kibana:8.0.0
# 创建网络
docker network create elastic
# 启动 Elastic Search 8.0.0
docker run -it --name elasticsearch --net elastic --restart=always -p 9200:9200 -p 9300:9300 -e
"discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:8.0.0
# 第一次的日志中会打印出默认用户elastic的初始密码,以及用于Kibana启动的enrollment token(半小时有效)注意保存密码记录:
Elasticsearch安全功能已自动配置!
身份验证已启用,群集连接已加密。
-> Password for the elastic user (reset with `bin/elasticsearch-reset-password -u elastic`):
aV3Fl5SeEk6TttXnMiSB
-> HTTP CA certificate SHA-256 fingerprint:
f8577d958c7845dd88edbfd1bc140e6618dc19c755607671e8330074de9ec36e
-> Configure Kibana to use this cluster:
* Run Kibana and click the configuration link in the terminal when Kibana starts.
* Copy the following enrollment token and paste it into Kibana in your browser (valid for the next 30
minutes):
eyJ2ZXIiOiI4LjAuMCIsImFkciI6WyIxNzIuMjAuMC4yOjkyMDAiXSwiZmdyIjoiZjg1NzdkOTU4Yzc4NDVkZDg4ZWRiZmQxYmMxNDB
lNjYxOGRjMTljNzU1NjA3NjcxZTgzMzAwNzRkZTllYzM2ZSIsImtleSI6Im9VZVdSWDhCMUw2ZFBhOGJ6SE81OjYyNDF1SVZSUWd5dk
s5ZDdXU1hZZlEifQ==
-> Configure other nodes to join this cluster:
* Copy the following enrollment token and start new Elasticsearch nodes with `bin/elasticsearch --
enrollment-token <token>` (valid for the next 30 minutes):
eyJ2ZXIiOiI4LjAuMCIsImFkciI6WyIxNzIuMjAuMC4yOjkyMDAiXSwiZmdyIjoiZjg1NzdkOTU4Yzc4NDVkZDg4ZWRiZmQxYmMxNDB
lNjYxOGRjMTljNzU1NjA3NjcxZTgzMzAwNzRkZTllYzM2ZSIsImtleSI6Im8wZVdSWDhCMUw2ZFBhOGJ6SFByOnU2RkR6cG5TUjVTS3
NmZzJVMUhrdncifQ==
If you're running in Docker, copy the enrollment token and run:
`docker run -e "ENROLLMENT_TOKEN=<token>" docker.elastic.co/elasticsearch/elasticsearch:8.0.0`
------------------------------------------------------------------------------------------------------
运行8.0.0Kibana
# 启动 Kibana 8.0.0
docker run --name kibana --net elastic -p 5601:5601 docker.elastic.co/kibana/kibana:8.0.0
# 第一次的日志中会打印出启动配置网址,在浏览器打开并输入enrollment token,等待完成配置
# 使用用户名elastic和之前保存的密码登录2.2.4 配置支持跨域
1、修改docker中elasticsearch的elasticsearch.yml文件--支持跨域
ps:修改了网络配置,重启网卡后,如果docker 容器链接不上,重启docker引擎
#进入到容器
docker exec -it elasticsearch /bin/bash
修改
vi config/elasticsearch.ym
增加配置信息
http.cors.enabled: true
http.cors.allow-origin:"*"
#重启容器2、在启动容器时写入环境变量
docker run -p 9200:9200 -p 9300:9300 -d -e "discovery.type=single-node" -e ES_JAVA_OPTS="-Xms512m -Xmx512m" -e"http.cors.enabled=true" -e "http.cors.allow-origin="*"" elasticsearch:7.16.32.2.5 安装插件
1、安装ik分词器
# 安装ik分词器
# 下载 https://github.com/medcl/elasticsearch-analysis-ik/releases
4、配置支持跨域
修改docker中elasticsearch的elasticsearch.yml文件--支持跨域
docker cp elasticsearch-analysis-ik-8.0.0.zip elasticsearch:/usr/share/elasticsearch/plugins
# 进入elasticsearch命令行
cd plugins/
mkdir ik
mv elasticsearch-analysis-ik-8.0.0.zip ik/
cd ik/
unzip elasticsearch-analysis-ik-8.0.0.zip
rm elasticsearch-analysis-ik-8.0.0.zip
# 重启es和kibana
docker restart elasticsearch
docker restart kibana# 在kibana中测试ik分词器
GET _analyze
{
"text" : "测试一下分词器",
"analyzer": "ik_max_word"
}
2、支持Sql查询:
1.获取elasticsearch容器的ID
docker ps
2.进入elasticsearch的docker容器
docker exec -it 容器ID /bin/bash
3.安装elasticsearch对应的elasticsearch-sql插件
./bin/elasticsearch-plugin install https://github.com/NLPchina/elasticsearch-
sql/releases/download/7.16.3.0/elasticsearch-sql-7.16.3.0.zip
4.Elasticsearch-sql默认支持查询最大记录数10000,更改最大查询值100000000
curl -X PUT --header 'Content-Type: application/json' --header 'Accept: application/json'
http://192.168.1.131:9200/logs*/_settings -d '{"index":{ "max_result_window":1000000000}}'
备注:http://192.168.1.131:9200替换成对应的elasticsearch服务器地址
5.退出容器3、浏览器插件
- Multi Elasticsearch Head
- Elasticsearch Tools
- 国人开发的浏览器插件:es-client
2.3 集群构建
官方提供的ElasticSearch 只会有32个G,ElasticSearch 号称百亿数据库,所以必须的支持扩容,支持集群.
一个ElasticSearch 服务器支持32个G,那么10个ElasticSearch 服务器就可以支持320个G。。。。。
ElasticSearch 生来就是集群的,前面Docker的启动的其实也是集群,叫单节点集群。
2.3.1 环境准备
Linux系统:CentOS7
Docker version: 26.1.4
2.3.2 集群构建思路
启动多个Docker,每一个Docker就是一个独立的系统,每个Dokcer中独立的有ElasticSearch的进
程;其实就是多个Docker 容器集群。每一个启动的Docker配置好配置文件即可;如果使用Docker
Compose来做,可以做到一键启动集群;
集群前环境准备:
1.挂载的目录必须设置完全权限: chmod 777 /root/elk/data01
2.调高vm线程数限制 (解决Elasticsearch启动时出现的vm.max_map_count不足问题,需要调整Linux系统的内核参数)
若集群时出现如下问题:

#进入配置文件
vim /etc/sysctl.conf
#调整vm线程数
vm.max_map_count=655360
#执行生效
sysctl –p3、或者直接执行下面代码 sysctl -w vm.max_map_count=655360
临时修改,重启后失效:
sudo sysctl -w vm.max_map_count=2621442.3.3 docker-Compose集群配置
1、配置ES集群所在文件夹结构
2、yml文件内容
version: '3.4'services:es01:image: "docker.elastic.co/elasticsearch/elasticsearch:7.16.3"container_name: es01ports:- "9200:9200"- "9300:9300"environment:node.name: es01discovery.seed_hosts: es01,es02,es03cluster.initial_master_nodes: es01,es02,es03cluster.name: myclusterES_JAVA_OPTS: -Xms512m -Xmx512mvolumes:- "./data01:/usr/share/elasticsearch/data"- "./plugins/ik:/usr/share/elasticsearch/plugins/ik" - "./plugins/sql:/usr/share/elasticsearch/plugins/sql"ulimits:memlock:soft: -1hard: -1es02:image: "docker.elastic.co/elasticsearch/elasticsearch:7.16.3"container_name: es02ports:- "9201:9200"- "9301:9300"environment:node.name: es02discovery.seed_hosts: es01,es02,es03cluster.initial_master_nodes: es01,es02,es03cluster.name: myclusterES_JAVA_OPTS: -Xms512m -Xmx512mvolumes:- "./data02:/usr/share/elasticsearch/data"- "./plugins/ik:/usr/share/elasticsearch/plugins/ik" - "./plugins/sql:/usr/share/elasticsearch/plugins/sql"ulimits:memlock:soft: -1hard: -1es03:image: "docker.elastic.co/elasticsearch/elasticsearch:7.16.3"container_name: es03ports:- "9202:9200"- "9302:9300"environment:node.name: es03discovery.seed_hosts: es01,es02,es03cluster.initial_master_nodes: es01,es02,es03cluster.name: myclusterES_JAVA_OPTS: -Xms512m -Xmx512mvolumes:- "./data03:/usr/share/elasticsearch/data"- "./plugins/ik:/usr/share/elasticsearch/plugins/ik" - "./plugins/sql:/usr/share/elasticsearch/plugins/sql"ulimits:memlock:soft: -1hard: -1kibana:image: docker.elastic.co/kibana/kibana:7.16.3container_name: kibanadepends_on:- es01- es02- es03ports:- "5601:5601"- "9600:9600"environment:SERVERNAME: kibanaELASTICSEARCH_HOSTS: '["http://es01:9200","http://es02:9200","http://es03:9200"]'ES_JAVA_OPTS: -Xmx512m -Xms512m三、文章总结
Elasticsearch (ES)是一个基于 Lucene 的开源搜索引擎,它不但稳定、可靠、快速,而且也具有良好的水平扩展能力,是专门为分布式环境设计的,Elasticsearch是面向文档型数据库。很多商城项目中会把商品订单信息存储到ES中。没有最好的技术只有最适合项目。