网络通信全过程:sk_buff的关键作用
目录
一、sk_buff:连接所有缓冲区的纽带
二、数据发送全流程:从用户层到网卡的 skb 旅程
(1)阶段 1:用户层数据准备与系统调用(用户态→内核态)
(2)阶段 2:套接字发送队列与 skb 创建(传输层准备)
(3)阶段 3:传输层处理与协议封装(TCP/UDP 层)
(4)阶段 4:网络层处理与 IP 封装(IP 层)
(5)阶段 5:链路层处理与 qdisc 队列(以太网层)
(6)阶段 6:驱动发送队列与网卡硬件发送(驱动层→物理层)
三、总结
在上一篇文章中,我们讲到了socket套接字的底层数据结构:socket、sock。而在struct sock中有一个核心字段是“接收缓冲区队列”和“发送缓冲区队列”,他们是一个sk_buffer类型的队列,用于暂时存储还没来得及发送出去的数据或用户层还没有读取的数据。
本文将在此基础上重点解析sk_buffer与各类缓冲区的关系,通过流程图和源码细节,展现数据在网络中如何依托skb在各个数据队列中流转,帮助我们建立一个更加清晰的空间模型。
一、sk_buff:连接所有缓冲区的纽带
sk_buff 是 Linux 网络栈的核心数据结构,其设计巧妙之处在于用指针操作替代数据复制,通过 4 个关键指针实现协议头部的动态增减,同时用链表指针融入各类缓冲区队列。
sk_buff源码简化如下:
struct sk_buff {// 链表指针:实现skb在队列中的挂载struct sk_buff *next; // 下一个skbstruct sk_buff *prev; // 上一个skb// 核心指针:实现零复制的"动态缓冲区"__u8 *head; // 缓冲区起始(分配时固定)__u8 *data; // 当前数据起始(可移动)__u8 *tail; // 当前数据结束(可移动)__u8 *end; // 缓冲区结束(分配时固定)// 关联对象:决定skb的归属与流向struct sock *sk; // 目标套接字(传输层后赋值)struct net_device *dev; // 关联网卡设备__be16 protocol; // 上层协议类型(如ETH_P_IP)// 生命周期管理:确保队列操作安全atomic_t kref; // 引用计数(0时释放)unsigned int truesize; // 实际占用内存大小(用于缓冲区限制)
};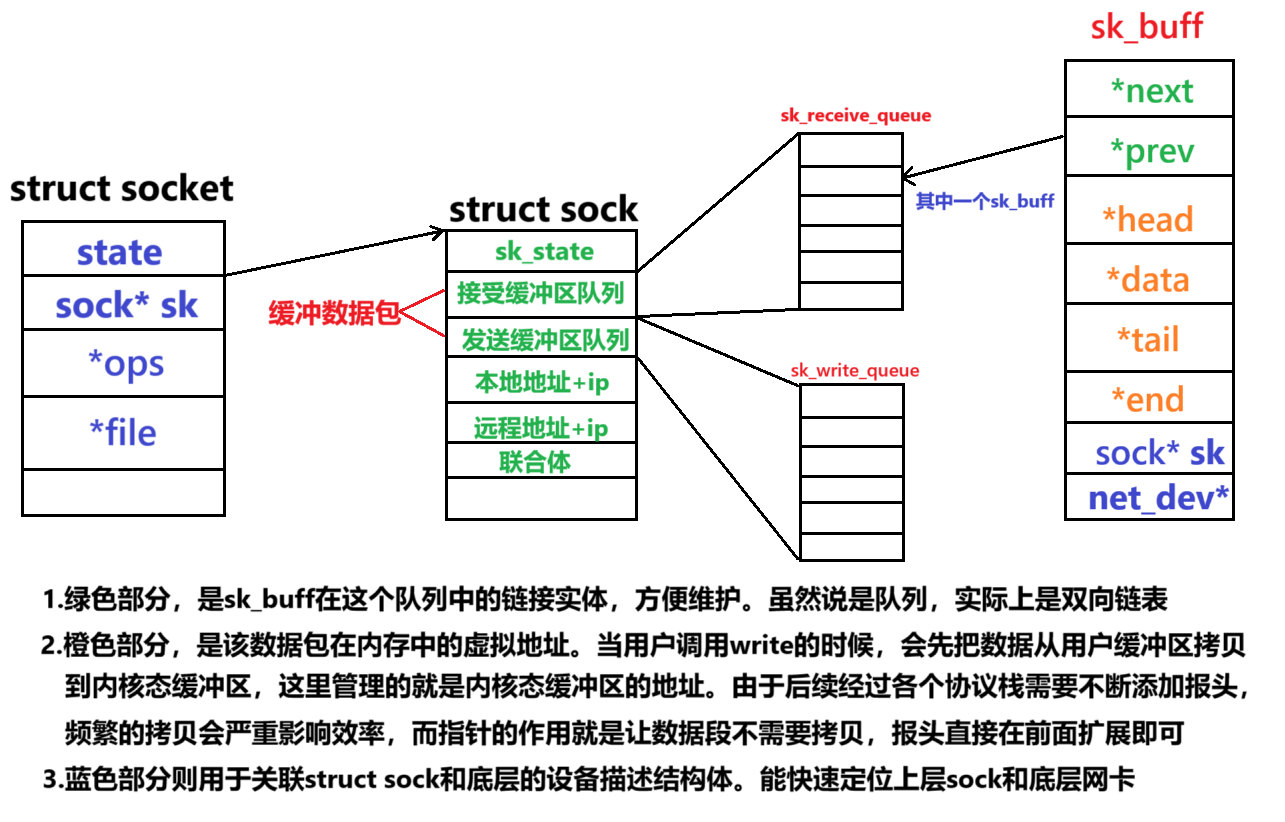 为什么需要这几个指针?
为什么需要这几个指针?
在发送流程中,sk_buff 的核心作用是承载用户数据并逐层添加协议头部,其指针操作方向与接收流程相反:通过skb_push在数据前添加头部(而非skb_pull移除头部),最终形成完整的网络帧。
例如,TCP 数据封装过程:
- 初始 skb 仅包含用户数据(
data指向数据起始,tail指向数据结束) - 调用
skb_push(skb, sizeof(struct tcphdr))添加 TCP 头部 - 调用
skb_push(skb, sizeof(struct iphdr))添加 IP 头部 - 调用
skb_push(skb, sizeof(struct ethhdr))添加以太网头部
无论添加什么报头,都只需要移动data指针即可。


二、数据发送全流程:从用户层到网卡的 skb 旅程
(1)阶段 1:用户层数据准备与系统调用(用户态→内核态)
处理流程:
- 应用程序在用户空间分配缓冲区(如
char buf[1024]),写入待发送数据;- 调用
send()/sendto()等系统调用,传入文件描述符(fd)、用户缓冲区指针、数据长度;- 系统调用陷入内核态,通过 fd 找到对应的
struct socket和struct sock结构。
ssize_t sys_send(int fd, const void __user *buf, size_t len, unsigned int flags) {struct file *file = fget(fd);struct socket *sock = file->private_data; // 从fd关联到socketstruct msghdr msg = {.msg_iov = ...}; // 封装用户数据信息// 调用套接字发送函数(如inet_sendmsg)return sock_sendmsg(sock, &msg, len);
}
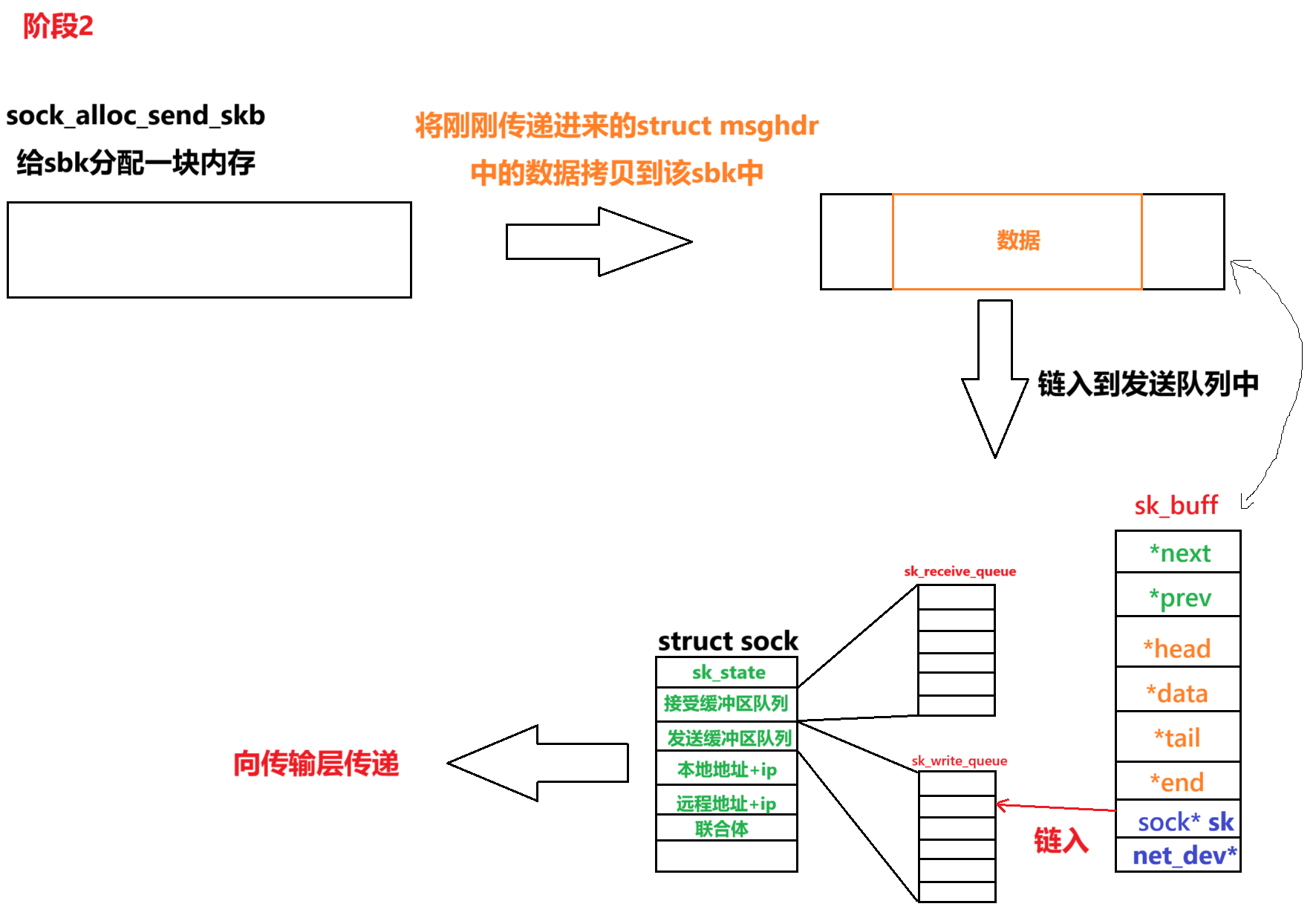
(2)阶段 2:套接字发送队列与 skb 创建(传输层准备)
处理流程:
- 内核从用户缓冲区复制数据到新创建的 skb(通过
copy_from_user);- 将 skb 加入套接字的发送队列(
sk->sk_write_queue);- 检查发送缓冲区是否溢出(
sk->sk_wmem_alloc≤sk->sk_sndbuf)。
int inet_sendmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg, size_t size) {struct sock *sk = sock->sk;struct sk_buff *skb;int len = size;// 分配skb(预留协议头部空间)skb = sock_alloc_send_skb(sk, len + 20 + 20 + 14, 0, &err); // 预留TCP+IP+以太网头部if (!skb)return err;// 从用户缓冲区复制数据到skbif (copy_from_user(skb_put(skb, len), msg->msg_iov[0].iov_base, len)) {kfree_skb(skb);return -EFAULT;}// 加入发送队列spin_lock_bh(&sk->sk_write_queue.lock);__skb_queue_tail(&sk->sk_write_queue, skb);atomic_add(skb->truesize, &sk->sk_wmem_alloc);spin_unlock_bh(&sk->sk_write_queue.lock);// 触发传输层处理(如TCP发送)sk->sk_prot->sendmsg(sk, skb); // 实际传递的是skbreturn len;
}
(3)阶段 3:传输层处理与协议封装(TCP/UDP 层)
处理流程:
- TCP:执行拥塞控制、滑动窗口检查,添加 TCP 头部(包含序列号、确认号等),将 skb 加入发送队列(
sk->tcp_send_queue)等待确认;- UDP:直接添加 UDP 头部(源端口、目的端口、长度、校验和),无需复杂控制。
static int tcp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, size_t size) {struct tcp_sock *tp = tcp_sk(sk);struct sk_buff *skb;// 从sk_write_queue取出skbskb = __skb_dequeue(&sk->sk_write_queue);// 添加TCP头部struct tcphdr *th = tcp_hdr(skb);th->source = htons(sk->sk_num); // 源端口th->dest = htons(inet->inet_dport); // 目的端口th->seq = htonl(tp->snd_nxt); // 序列号th->ack_seq = htonl(tp->rcv_nxt); // 确认号th->doff = sizeof(struct tcphdr)/4;th->syn = 0; th->ack = 1; // 控制位th->window = htons(tp->snd_wnd); // 窗口大小th->check = tcp_v4_check(skb->len, ...); // 校验和// 加入TCP发送队列,等待发送__skb_queue_tail(&tp->send_queue, skb);tp->snd_nxt += skb->len; // 更新下一个序列号// 触发发送(如调用tcp_transmit_skb)tcp_write_xmit(sk);return size;
}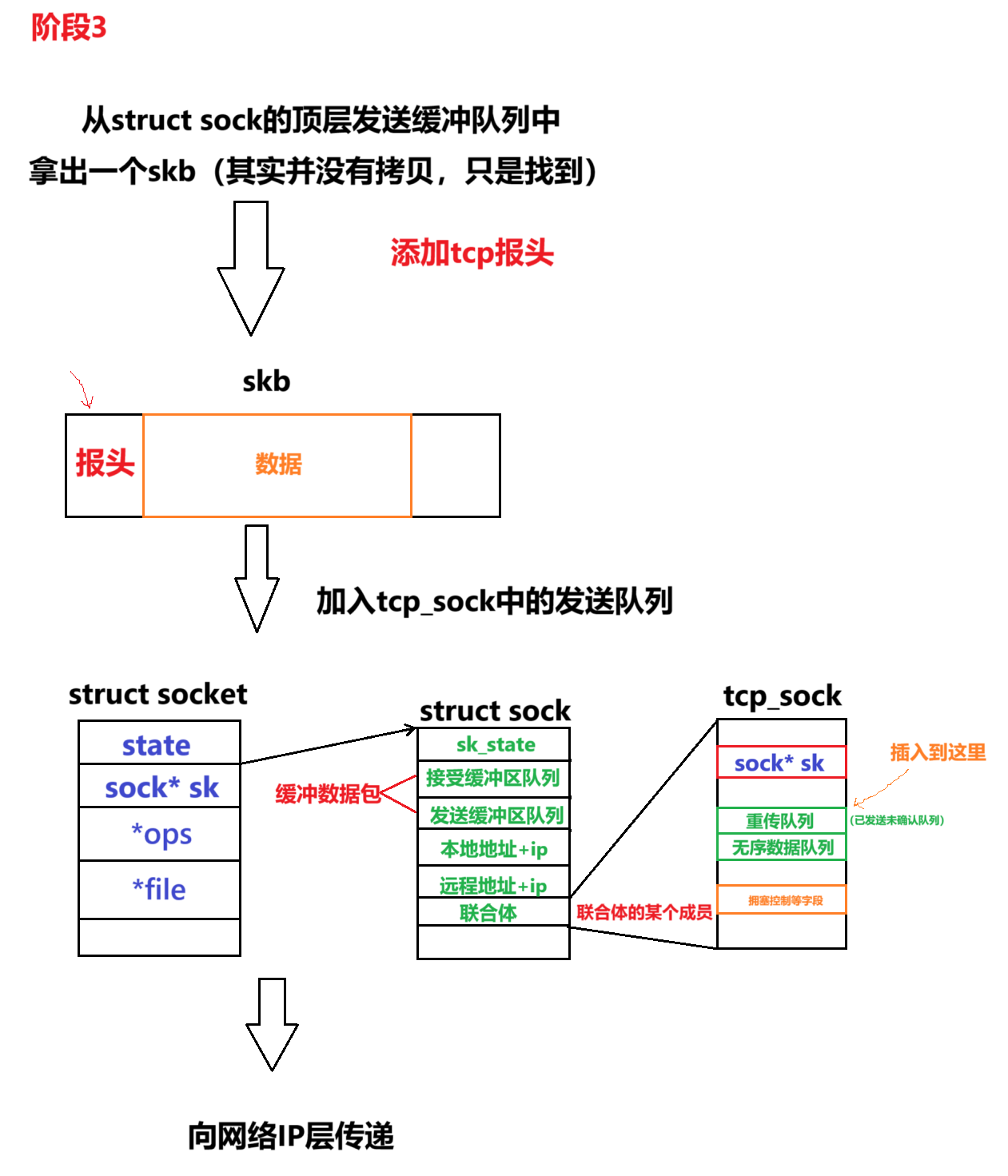
为什么有了struct sock中的缓冲区队列还不够,还需要在tcp_sock中设计一系列队列?

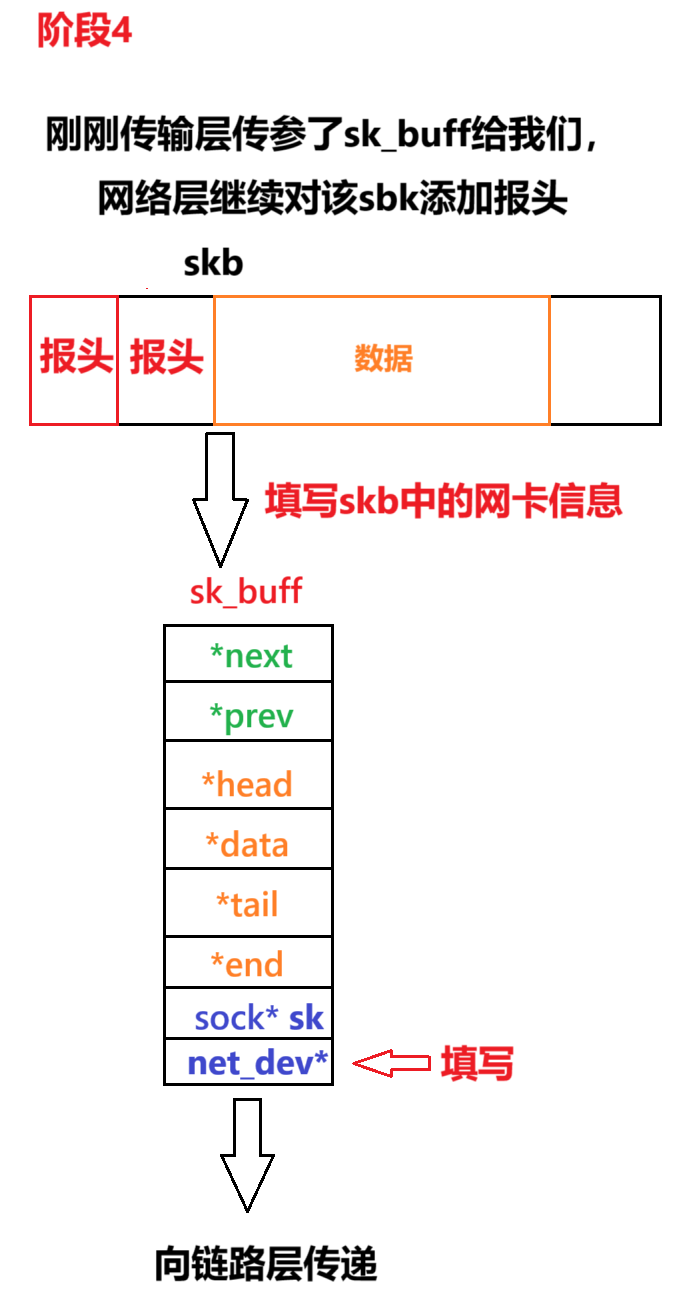
(4)阶段 4:网络层处理与 IP 封装(IP 层)
处理流程:
- 查找路由表,确定输出网卡(
skb->dev);- 添加 IP 头部(源 IP、目的 IP、协议类型、TTL 等);
- 计算 IP 校验和,若需要则进行分片(超过 MTU 时)。
int ip_queue_xmit(struct sk_buff *skb) {struct sock *sk = skb->sk;struct rtable *rt = skb_rtable(skb); // 获取路由信息struct iphdr *iph;// 预留IP头部空间并添加头部skb_push(skb, sizeof(struct iphdr));iph = ip_hdr(skb);iph->version = 4;iph->ihl = 5;iph->protocol = sk->sk_protocol; // 上层协议(如IPPROTO_TCP)iph->saddr = rt->rt_src; // 源IPiph->daddr = rt->rt_dst; // 目的IPiph->ttl = ip_select_ttl(sk, rt); // TTL值iph->check = ip_fast_csum(iph, iph->ihl); // 校验和// 设置输出网卡skb->dev = rt->dst.dev;// 提交到链路层return dst_output(skb);
}
(5)阶段 5:链路层处理与 qdisc 队列(以太网层)
处理流程:
- 添加以太网头部(源 MAC、目的 MAC、类型字段);
- 将 skb 送入网络设备的 qdisc(队列规则)进行流量控制;
- qdisc 根据调度策略(如 PFIFO、HTB)决定 skb 的发送顺序和时机。
int dev_queue_xmit(struct sk_buff *skb) {struct net_device *dev = skb->dev;struct Qdisc *q = dev->qdisc;int rc;// 添加以太网头部struct ethhdr *eth = eth_hdr(skb);eth->h_source[0..5] = dev->dev_addr; // 源MAC(本机网卡MAC)eth->h_dest[0..5] = rt->rt_gateway_mac; // 目的MAC(网关或目标主机)eth->h_proto = htons(ETH_P_IP); // 上层协议类型// 送入qdisc队列spin_lock(&q->lock);if (q->q.qlen < dev->tx_queue_len) {rc = q->enqueue(skb, q); // 入队(如pfifo_enqueue)q->q.qlen++;} else {// 队列满,丢弃skbkfree_skb(skb);rc = -ENOBUFS;}spin_unlock(&q->lock);// 触发队列发送if (!rc)qdisc_run(dev);return rc;
}
(6)阶段 6:驱动发送队列与网卡硬件发送(驱动层→物理层)
处理流程:
- 驱动从 qdisc 队列取出 skb(
qdisc_dequeue);- 将 skb 数据通过 DMA 映射到网卡可访问的物理内存;
- 将 skb 地址和长度写入发送描述符环(tx_ring);
- 通知网卡发送数据,发送完成后触发中断,释放 skb。
static void e1000_xmit_frame(struct sk_buff *skb, struct net_device *dev) {struct e1000_adapter *adapter = netdev_priv(dev);struct e1000_tx_ring *tx_ring = &adapter->tx_ring;struct e1000_tx_desc *desc;unsigned int i = tx_ring->next_to_use;// 获取当前描述符desc = &tx_ring->desc[i];// DMA映射skb数据区dma_addr_t dma = dma_map_single(&adapter->pdev->dev, skb->data, skb->len, DMA_TO_DEVICE);// 更新描述符desc->buffer_addr = cpu_to_le64(dma);desc->length = cpu_to_le16(skb->len);desc->cmd = cpu_to_le16(E1000_TXD_CMD_EOP | E1000_TXD_CMD_RS); // 帧结束+报告状态// 保存skb指针,用于发送完成后释放tx_ring->buffers[i] = skb;// 更新下一个可用描述符索引tx_ring->next_to_use = (i + 1) % tx_ring->count;// 通知网卡有数据待发送e1000_write_reg(adapter, E1000_TDT, i);
}// 发送完成中断处理(释放skb)
static void e1000_tx_complete(struct e1000_adapter *adapter) {struct e1000_tx_ring *tx_ring = &adapter->tx_ring;unsigned int i = tx_ring->next_to_clean;struct e1000_tx_desc *desc = &tx_ring->desc[i];// 检查描述符是否完成发送if (le32_to_cpu(desc->status) & E1000_TXD_STAT_DD) {struct sk_buff *skb = tx_ring->buffers[i];// 解除DMA映射dma_unmap_single(&adapter->pdev->dev, le64_to_cpu(desc->buffer_addr),skb->len, DMA_TO_DEVICE);// 释放skbkfree_skb(skb);tx_ring->buffers[i] = NULL;// 更新清理索引tx_ring->next_to_clean = (i + 1) % tx_ring->count;}
}三、总结
对于接收流程则完全反过来即可。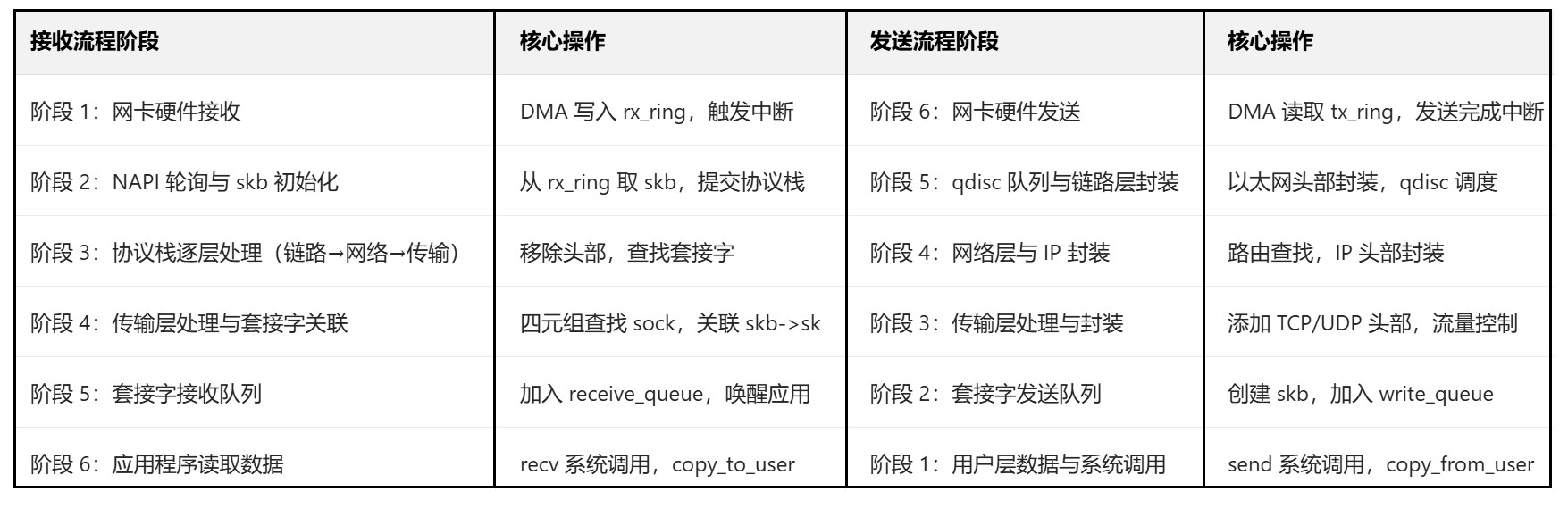 skb可以说是网络通信过程中最为重要的一个“包裹”,通过对这个包裹的“快递单”的层级修改、添加完成了整个网络协议栈报头的封装。而skb中的一些指针则保证了在协议栈不断修改的过程中,不会涉及到任何拷贝,只需要填充前面的报头即可,大大提高了效率。
skb可以说是网络通信过程中最为重要的一个“包裹”,通过对这个包裹的“快递单”的层级修改、添加完成了整个网络协议栈报头的封装。而skb中的一些指针则保证了在协议栈不断修改的过程中,不会涉及到任何拷贝,只需要填充前面的报头即可,大大提高了效率。